
Os fatores diferenciadores do Hadoop: escalabilidade de código aberto e tolerância a falhas
Publicados: 2022-11-18Hadoop é uma estrutura de software de código aberto para armazenamento distribuído e processamento de grandes conjuntos de dados em clusters de computadores. Ele foi projetado para escalar de um único servidor para milhares de máquinas, cada uma oferecendo computação e armazenamento locais. Em vez de depender de hardware para fornecer alta disponibilidade, a estrutura é projetada para detectar e lidar com falhas na camada do aplicativo. O Hadoop é um banco de dados nosql porque usa uma arquitetura completamente diferente de um banco de dados relacional tradicional. O Hadoop foi projetado para escalar horizontalmente, o que significa que ele pode escalar para acomodar mais dados adicionando mais servidores comuns ao cluster. O Hadoop também foi projetado para ser tolerante a falhas, o que significa que, se um servidor do cluster cair, o sistema pode continuar funcionando sem esse servidor.
Hadoop não é usado para armazenar dados, nem requer o uso de armazenamento relacional; em vez disso, é usado para armazenar grandes quantidades de dados em servidores distribuídos. Um banco de dados Hadoop é um tipo de dados em vez de um sistema de software que permite a computação paralela massiva. É um tipo de vinculação de banco de dados NoSQL (como HBase) que permite aos usuários consultar e pesquisar bancos de dados em uma variedade vinculada. O RDBMS, em sua forma atual, seria incapaz de competir com o Hadoop porque é capaz de gerenciar dados relativos e transacionais. O Hadoop tem a capacidade de lidar com qualquer tipo de dados, sejam eles estruturados, semiestruturados ou não estruturados, e oferece suporte a uma ampla variedade de métodos. A análise de big data está dando às empresas uma vantagem competitiva no mundo real, fornecendo insights mais profundos. O Hadoop, como serviço, suporta o uso de processamento analítico online (OLAP) no processamento de dados. É importante lembrar que a velocidade do processamento de dados é determinada pelo número de solicitações de dados. Você pode usar o Hadoop se não quiser transações ACID ou suporte OLAP, por exemplo.
Hadoop e bancos de dados em memória são duas tecnologias completamente diferentes que se sobrepõem. Eles não são os mesmos, mas concordam em algumas coisas.
Os aplicativos analíticos que usam SQL-on-Hadoop combinam métodos de consulta de estilo SQL estabelecidos com elementos de estrutura de dados Hadoop mais recentes . O SQL-on-Hadoop permite que desenvolvedores corporativos e analistas de negócios colaborem em clusters Hadoop com consultas SQL familiares.
É um banco de dados NoSQL que fornece um meio para armazenar e recuperar dados. Não relacional/não SQL é um dos termos comumente usados neste espaço.
Os dados são gerenciados de várias maneiras por Hadoop e SQL. SQL é uma linguagem de programação, enquanto Hadoop é uma estrutura de componentes de software. Ambas as ferramentas são úteis para big data, mas têm desvantagens. A plataforma Hadoop pode lidar com um conjunto muito maior de dados, mas grava os dados apenas uma vez.
Qual é a diferença entre Hadoop e Nosql?
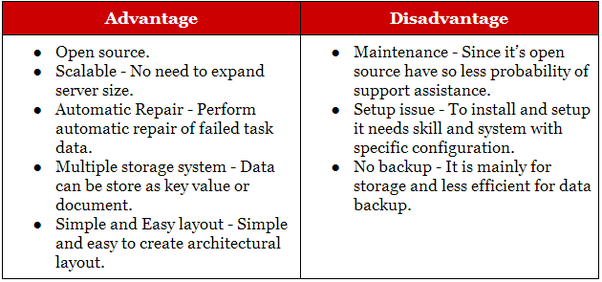
O Hadoop é adequado para aplicativos de arquivamento analítico e histórico, enquanto o NoSQL é ideal para cargas de trabalho operacionais que complementam suas contrapartes relacionais. Os bancos de dados NoSQL começaram como bancos de dados de armazenamento de valor- chave, mas, posteriormente, bancos de dados de documentos/json e gráficos se juntaram a eles.
Processamento em tempo real, dados grandes e dados não estruturados são apenas alguns dos cenários em que a tecnologia NoSQL pode ser usada. Como resultado, alguns desses desafios, como escalabilidade e disponibilidade, podem ser superados. O banco de dados NoSQL tem várias vantagens sobre o banco de dados relacional tradicional. Eles podem processar conjuntos de dados de maneira muito mais rápida e escalável do que anteriormente. Os sistemas de administração de banco de dados também utilizam menos conhecimento e experiência do que os bancos de dados tradicionais , o que os torna mais fáceis de usar. Um banco de dados NoSQL tem várias vantagens sobre um banco de dados relacional tradicional. A coisa mais importante a considerar é se você precisa deles para processamento em tempo real e grandes conjuntos de dados.
Os bancos de dados Nosql são a melhor escolha para empresas com cargas de trabalho de Big Data
Se suas cargas de trabalho de dados estiverem mais focadas na análise e processamento de grandes quantidades de dados variados e não estruturados, como Big Data, os bancos de dados NoSQL são uma escolha melhor. Ao contrário dos bancos de dados relacionais , os bancos de dados NoSQL não dependem de um modelo de esquema fixo. O RDBMS é mais flexível do que os RDBMSs tradicionais em termos de armazenamento, processamento e gerenciamento de dados, tornando-o uma opção melhor para empresas que exigem a capacidade de acessar rapidamente grandes quantidades de dados e precisam armazená-los indefinidamente.
Big Data é Sql ou Nosql?

Se suas cargas de trabalho de dados se preocupam principalmente com o processamento e a análise rápida de grandes quantidades de dados diversos e não estruturados, como Big Data, o NoSQL é sua melhor aposta. O modelo de banco de dados NoSQL é único porque não depende da mesma estrutura de esquema de um banco de dados relacional.
Não é mais uma questão de saber se o big data irá melhorar a manufatura; é uma questão de quando. Em big data, existem quantidades vastas, diversas e complexas de dados estruturados e não estruturados disponíveis. Sensores, câmeras no chão de fábrica e dispositivos de consumo podem ser usados para coletar big data na fabricação. Como a maioria dos dados na fabricação não é estruturada, as arquiteturas NoSQL não podem competir com abordagens rígidas como SQL. Um banco de dados NoSQL não requer esquemas para armazenar dados na mesma tabela de banco de dados, permitindo que os usuários armazenem dados em várias estruturas. A linha de separação de uma empresa pode ser determinada pela quantidade de dados que ela pretende usar. As transações devem aderir a quatro princípios operacionais fundamentais para serem consideradas uma transação de banco de dados relacional.
Como os sistemas NoSQL e os sistemas em nuvem podem ser integrados, é uma boa ideia usar estruturas de computação em nuvem para oferecer suporte a sistemas NoSQL. A otimização do processo de fabricação em tempo real via NoSQL pode ser realizada por meio da integração com os Sistemas de Execução de Manufatura (MES). Esse sucesso foi possível graças ao uso da análise de big data para produzir respostas mais rápidas às mudanças nas condições. O MongoDB é um bom banco de dados NoSQL porque é simples de configurar e pode ser usado para análises. O uso de arquiteturas de banco de dados de resposta mais rápida, como NoSQL, permite que o gerenciamento realize melhores simulações, permitindo que eles tomem melhores decisões de produtos no mundo real. Bancos de dados B2B são vulneráveis a ataques entre sites, bem como ataques de injeção e ataques de força bruta. Um ataque de injeção ocorre quando um invasor adiciona dados a comandos de consulta NoSQL ou instruções de armazenamento.

O setor de manufatura está particularmente preocupado com a segurança da arquitetura NoSQL. Se um ataque de negação de serviço ou ataque de injeção for realizado com sucesso, um fabricante poderá modificar as especificações. Por causa disso, os concorrentes podem obter uma vantagem em um mercado altamente competitivo.
Os processos de negócios que dependem de dados em tempo real estão se tornando mais comuns à medida que as empresas buscam maneiras de melhorar sua eficiência e capacidade de resposta às necessidades dos clientes. Bancos de dados NoSQL baseados em nuvem, como Cloud Bigtable, fornecem uma maneira rápida e eficiente de armazenar e acessar grandes conjuntos de dados, tornando-os uma excelente solução para esses tipos de aplicativos.
O Cloud Bigtable é um serviço de banco de dados NoSQL totalmente gerenciado e oferece 99,999% de tempo de atividade. É ideal para cargas de trabalho analíticas e operacionais porque tem altas velocidades de alimentação de dados e é simples de aumentar e diminuir. Como resultado, é uma excelente escolha para processamento de dados em tempo real em aplicativos como jogos móveis e análise de varejo.
O Nosql é o melhor banco de dados para grandes volumes de dados?
O MongoDB, por exemplo, é uma excelente escolha para armazenar grandes quantidades de dados. Eles permitem uma ampla variedade de cenários de processamento ágil e de alto desempenho. Além disso, os dados não estruturados são armazenados em bancos de dados NoSQL em vários nós de processamento e em vários servidores. Como resultado, os bancos de dados NoSQL têm sido a escolha padrão de alguns dos maiores data warehouses do mundo. Qual banco de dados é o melhor para dados grandes? Quando se trata dessa questão, não é possível prever qual banco de dados é o melhor para grandes volumes de dados devido às diversas necessidades da organização. Amazon Redshift, Azure Synapse Analytics, Microsoft SQL Server, Oracle Database, MySQL, IBM DB2 e muitos outros bancos de dados estão entre as opções mais populares para armazenamento de dados grandes.
O Hadoop é um banco de dados
O Hadoop é um sistema de arquivos distribuído e uma estrutura para executar aplicativos em grandes clusters de hardware comum. Hadoop não é um banco de dados.
O Hadoop, uma estrutura de código aberto, permite o armazenamento e o processamento eficientes de conjuntos de dados massivos. As tabelas Hive e Imperative podem ser criadas usando arquivos de texto no HDFS. Ele oferece suporte aos três principais formatos de arquivo: arquivos de sequência, arquivos de dados Avro e arquivos Parquet. Uma série de bytes é representada pela serialização de dados como uma unidade de memória. Avro, uma estrutura eficiente de serialização de dados, é amplamente suportada pelo Hadoop e seu ecossistema.
O uso de arquivos de texto como formato de armazenamento para tabelas Hive e Implicit simplifica o gerenciamento e a manipulação de dados. Como resultado, é uma boa escolha para processamento em lote ou armazenamento de dados em diversos formatos. Além disso, a serialização de dados via Avro permite o armazenamento e recuperação de dados de forma eficiente e conveniente. Como resultado, é uma boa opção para armazenar dados em diversos formatos ou realizar processamento paralelo.
Hadoop x Nosql
O Hadoop lida com big data para um cluster de hardware comum. Se a funcionalidade não atender às suas necessidades ou não for funcional, ela poderá ser alterada. Isso é conhecido como NoSQL e é um tipo de sistema de gerenciamento de banco de dados que armazena dados estruturados, semiestruturados e não estruturados.
O MongoDB, como um banco de dados NoSQL (Not Only SQL), foi criado em 2007 como resultado do desenvolvimento do C++. Um Hadoop é uma coleção de programas de software de código aberto que são escritos principalmente em Java para processamento de grandes dados. Essa plataforma também inclui pesquisa de texto completo, ferramentas de análise avançada e uma linguagem de consulta fácil de usar. Embora o Hadoop seja mais conhecido por sua capacidade de armazenar e processar grandes quantidades de dados, ele também o faz em pequenos lotes. O MongoDB fornece uma variedade de ferramentas de processamento de dados em tempo real. Os conectores do MongoDB para ferramentas externas, como Kafka e Spark, simplificam a ingestão e o processamento de dados. Quando se trata de manipulação de dados, o Hadoop e o MongoDB oferecem uma ampla gama de vantagens sobre os bancos de dados tradicionais. O Hadoop é uma excelente ferramenta para lidar com grandes estruturas de dados devido ao seu sistema de arquivos distribuído. O MongoDB é o único banco de dados que pode ser usado como substituto dos bancos de dados tradicionais.
Spark é um banco de dados Nosql
Na documentação, afirma-se que um NoSQL DataFrame é um Spark DataFrame baseado no formato Spark para armazenamento de dados. Em contraste com as fontes de dados anteriores, esta oferece suporte à remoção e filtragem de dados (pushdown de predicado), permitindo que as consultas do Spark consultem menos dados e carreguem apenas os dados necessários, conforme necessário.
É fundamental manter a consciência tática ao usar os bancos de dados Apache Spark e NoSQL ( Apache Cassandra e MongoDB) juntos em um aplicativo. Este blog se concentra em como usar o Apache Spark em um aplicativo NoSQL. CassandraLand e MongoLand no TCP/IP sPark são dois dos passeios mais populares, e é um ótimo lugar para visitar se você gosta de parques temáticos. Ao procurar dados do Departamento de Energia, nosso aplicativo Spark começou a girar. Aqui está uma lição rápida sobre a importância da sequência de teclas do Cassandra quando se trata de consultas. Há também a montanha-russa Partitioner em CassandraLand. Os clientes que gostam de montanhas-russas podem compartilhar suas informações com os operadores de passeios para que eles possam rastrear quem os montou diariamente.
A primeira lição da Lição 1 do MongoDB é gerenciar adequadamente as conexões do MongoDB. Quando você precisa atualizar as informações sobre o novo status de associação ao parque do Departamento de Energia, os índices do Mongo são extremamente úteis. Como cliente MongoDB ou Spark, você deve manter uma conexão e índices adequados em caso de atualizações do sistema.