
O formato de dados HDF5: uma opção atraente para armazenar e gerenciar grandes coleções de dados
Publicados: 2023-02-13HDF5 é um formato de dados projetado para armazenar e gerenciar grandes e complexas coleções de dados. É frequentemente usado em aplicações científicas e de engenharia, e sua popularidade tem aumentado nos últimos anos. O HDF5 não é um banco de dados, mas pode ser usado para armazenar dados em um formato hierárquico semelhante a um sistema de arquivos. Isso torna o HDF5 uma opção atraente para aplicativos que precisam armazenar e gerenciar grandes quantidades de dados.
Você pode extrair metadados e dados brutos de arquivos HDF5 e netCDF4 e usar streaming Hadoop para analisar dados Hadoop usando o Hadoop Distributed File System (HDFS) HDF5 Connector Virtual File Driver (VFD).
Hdf5 é um banco de dados?
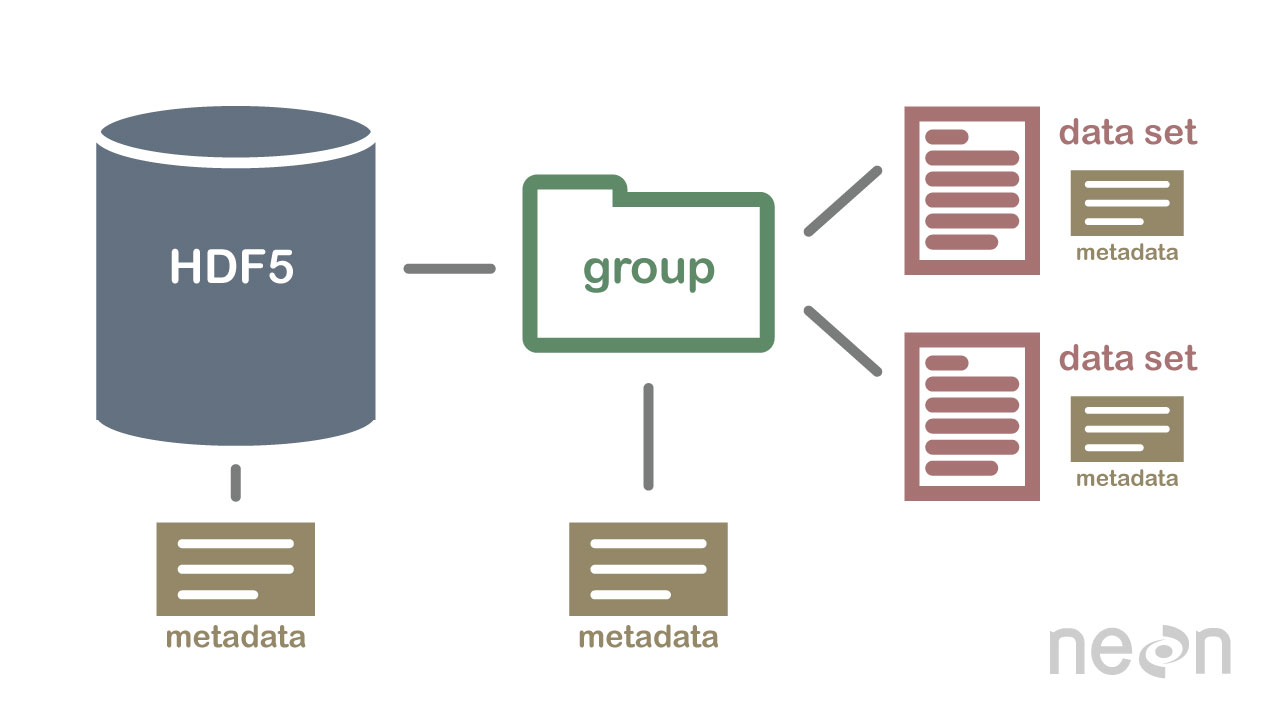
O HDF5 não é um banco de dados, mas pode ser usado para armazenar dados em uma estrutura hierárquica, semelhante a um sistema de arquivos. O HDF5 pode ser usado para armazenar dados em vários formatos, incluindo texto, imagens e dados binários .
Dados no formato hierárquico (HDF5) são extremamente úteis em pesquisas científicas. O sistema de arquivos HDF5, por ser semelhante a um sistema de arquivos na medida em que é muito eficiente, é um excelente formato. Quando se trata de dados codificados neste formato, pode ser difícil acessá-los. Este guia orientará você sobre como o Apache Drill pode ajudá-lo a acessar e consultar facilmente conjuntos de dados HDf5. O Drill tem acesso a arquivos HDF5 individuais por meio da opção defaultPath. Isso é feito executando diretamente a função table() durante o tempo de consulta ou por meio da configuração. Os resultados desta consulta podem ser encontrados na tabela abaixo. O Drill pode então selecionar as colunas e filtrá-las individualmente, filtradas, agregadas ou combinadas com outros dados que podem ser consultados.
A especificação HDF5 define um formato de arquivo para armazenar matrizes de dados. Uma matriz de dados pode ser composta de qualquer tipo de dados, incluindo string, flutuante, complexo e dados inteiros. Uma matriz pode conter dados de qualquer tamanho e pode ter qualquer forma. No HDF5, deve-se primeiro criar um arquivo de cabeçalho para criar um conjunto de dados. O arquivo de cabeçalho inclui informações sobre o conjunto de dados, bem como metadados. O arquivo de cabeçalho inclui duas informações importantes: o nome do conjunto de dados e o número da versão do conjunto de dados. Uma matriz de dados é usada para armazenar os dados de um conjunto de dados. Os blocos são compostos de dados em uma matriz de dados. Na matriz de dados, cada bloco de dados contém um conjunto contíguo de dados. O número de blocos de um conjunto de dados é determinado pelo número de bytes nele. Os dados podem ser acessados por vários métodos de acordo com a especificação HDF5. métodos de indexação são mais comumente usados para obter dados em um conjunto de dados. Ao usar esses métodos, você pode acessar os dados inserindo o nome de um bloco na matriz de dados que deseja acessar. O método de estrutura pode ser usado para acessar dados em um conjunto de dados. Ao empregar esses métodos, você pode acessar os dados usando a estrutura de uma matriz de dados. No exemplo a seguir, você pode acessar os dados em uma matriz de dados usando os valores de deslocamento e comprimento do método de estrutura. Outra maneira de obter dados de um conjunto de dados é por meio do uso de métodos de função. Você pode obter dados usando um dos métodos selecionando a função no arquivo de cabeçalho para os dados. O método para acessar uma matriz de dados pode ser usado definindo o valor no arquivo de cabeçalho como o elemento da matriz de dados da matriz. Por fim, você pode acessar os dados em um conjunto de dados usando o método de acesso. Ao empregar esses métodos, você pode acessar os dados usando os privilégios de acesso definidos no arquivo de cabeçalho. Em outras palavras, usar o privilégio de leitura pode acessar dados em uma matriz de dados por meio do método de acesso. Os dados podem ser criados e usados de várias maneiras usando a especificação HDF5. O método create é o método mais comum para criar um conjunto de dados. Usando o método create, você pode criar um conjunto de dados inserindo o nome do conjunto de dados e o número da versão do conjunto de dados. Além da especificação HDF5, o uso de conjuntos de dados pode ser realizado de várias maneiras. O método mais comumente usado.

Hdf5 é um banco de dados relacional?
HDF5 não é um banco de dados relacional.
Graphql é Nosql ou Sql?
O objetivo principal do GraphQL é usar um sistema de tipos para retornar dados de forma mais rápida e eficiente. SQL (linguagem de consulta estruturada) é uma linguagem mais antiga e amplamente usada para armazenar dados em sistemas de banco de dados tabulares ou relacionais . Se você deseja que sua API seja construída sobre um banco de dados NoSQL, seria uma boa ideia trabalhar com GraphQL.
O Type Mismatch é um banco de dados GraphQL e NoSQL criado por Herman Camarena e Roger Cochrane. O uso do GraphQL pode resultar na introdução de um sistema de tipos em vez de um sistema NoSQL, eliminando a flexibilidade criada pelos sistemas NoSQL. Uma coleção GraphQL contém uma ampla variedade de documentos que são consistentes em estrutura e contêm algumas exceções. Como o GraphQL possui um conjunto integrado de tipos de dados que correspondem aos tipos de back-ends, os desenvolvedores podem escolher quais tipos de dados criar. O GraphQL deve abordar a questão das incompatibilidades de tipo para realizar plenamente o seu potencial. Em termos de recursos, ele fornece uma solução de incompatibilidade de nível inferior devido às suas muitas vantagens. O trabalho é cada vez mais automatizado com ferramentas como JSON2SDL da StepZen.
É uma ferramenta poderosa que pode ser usada para criar aplicativos mais resilientes e eficientes, mas o SQL não é um substituto. Em termos de manutenção, isso pode ter um impacto negativo, pois dificulta algumas tarefas.
Graphql: uma linguagem de consulta para qualquer banco de dados
A linguagem de consulta GraphQL permite que clientes e servidores se comuniquem entre si. Uma instância do GraphQL pode recuperar e manter alterações de uma fonte de dados ou de um estado persistente. Um resolvedor é um conjunto de funções arbitrárias usadas para acessar e manipular dados. A API está disponível em vários bancos de dados e o GraphQL pode ser usado com qualquer um. O banco de dados MongoDB é um banco de dados de fonte de dados popular que é independente de vários tipos de dados.
O Nosql usa árvores B?
Os bancos de dados NOSQL não usam árvores B porque não são baseados no modelo relacional. Os bancos de dados NOSQL geralmente são baseados em pares chave-valor, armazenamentos de documentos ou bancos de dados gráficos.
As árvores B são a estrutura de indexação padrão no MongoDB. No armazenamento de dados , uma árvore B é um método mais eficiente. Os dados podem ser organizados usando números inteiros e strings se forem usados juntos. Como resultado, bancos de dados com alto volume de dados devem considerar seu uso. Como as árvores B podem ocupar muito espaço, elas são um modelo eficiente. Isso é benéfico para bancos de dados que precisam manter uma grande quantidade de dados. As árvores B também são uma boa opção para bancos de dados que precisam organizar os dados de uma maneira específica.
Qual banco de dados usa B-tree?
Já existe há muito tempo e pode ser usado em uma ampla variedade de bancos de dados. Os bancos de dados NoSQL podem ser construídos sobre mecanismos de árvore B, além dos mecanismos de árvore B. O MongoDB, por exemplo, indexa dados em árvores B. O algoritmo é o mesmo para o DBMS e para um banco de dados relacional, embora existam algumas exceções. Strings e inteiros podem ser usados para organizar dados na árvore B.
Qual banco de dados usa B-tree? Mysql, no artigo a seguir, emprega Btree e B+tree. O SQL Server armazena índices com base em dados persistentes baseados em chave na forma de um BTree. Como resultado, cada nó dessa árvore aparece como uma única página.