
O banco de dados Oracle NoSQL
Publicados: 2022-12-17O Oracle NoSQL Database é um banco de dados de valor-chave distribuído. Ele foi projetado para fornecer gerenciamento de dados escalável e de alto desempenho, mantendo uma interface simples. O banco de dados Oracle NoSQL é construído sobre o Oracle Berkeley DB Java Edition, que fornece um mecanismo de banco de dados incorporável e de alto desempenho. O Oracle NoSQL Database está disponível como uma imagem de máquina virtual para download ou como um serviço de nuvem.
In-Memory emprega uma arquitetura única de formato duplo que permite que as tabelas sejam representadas simultaneamente na memória. Como o novo formato de coluna é um formato puramente na memória e não requer armazenamento em disco, não há custo adicional de armazenamento ou problemas de sincronização de armazenamento. A capacidade dos bancos de dados na memória para lidar com consultas na taxa surpreendente de bilhões de linhas por segundo em um núcleo de CPU é impressionante. A maioria desses índices analíticos pode ser eliminada com In-Memory usando o formato de coluna In-Memory, que reduz a quantidade de dados que precisam ser recuperados enquanto também fornece desempenho comparável a ter um índice em cada coluna. A remoção dos índices analíticos acelera as operações de OLTP, pois os índices não precisam mais ser mantidos a cada transação. Somente tabelas e partições com privilégios de memória podem ser inseridas na memória dos usuários.
O sistema de gerenciamento de banco de dados NoSQL in-memory, como MongoDB e Redis, armazena todos os dados na memória principal e os atualiza em disco indefinidamente. Para garantir a persistência, cada solicitação de modificação é salva em um log binário. Como o log é apenas anexado, raramente é um problema escrevê-lo com pressa.
O banco de dados Oracle está na memória?

Sim, o Oracle Database está na memória. O recurso de armazenamento de colunas na memória da Oracle permite que os dados sejam armazenados e acessados na memória, proporcionando um aumento significativo de desempenho para cargas de trabalho analíticas. Quando combinado com a tecnologia Real Application Clusters (RAC) da Oracle, o Oracle Database pode fornecer um nível ainda maior de escalabilidade e disponibilidade.
O Database In-Memory é um conjunto de recursos que melhora a análise em tempo real e cargas de trabalho mistas, fornecendo ganhos significativos de desempenho. O Column Store (armazenamento de coluna IM) foi adicionado ao Oracle Database 12c Release 1 (12.1.0.2) como um componente do Oracle Database 12c Release 1 (12.1.0.2). Em bancos de dados relacionais tradicionais, os dados podem ser armazenados em formato de linha ou colunar. A seleção de colunas em um banco de dados colunar corresponde à seleção de linhas em um banco de dados de linhas. O Database In-Memory inclui um armazenamento de colunas no banco de dados, otimizações avançadas de consulta e soluções de acesso. O armazenamento de coluna IM mantém cópias de todas as colunas, tabelas, partições e assim por diante em um formato colunar compactado projetado para verificação rápida. Ao usar o processamento paralelo, data warehouses e bancos de dados de uso misto podem lidar com ordens de magnitude mais rapidamente.
Como resultado do preenchimento, os dados baseados em linha no disco são transformados em dados colunares no armazenamento de coluna IM. Por exemplo, se você deseja dividir uma tabela ou exibição em partições particionadas, todas ou parte das partições podem ser configuradas para a população. Expressão em memória (IM expression) em DBMS_INMEMORY_ADMIN.IME_CAPTURE_EXPRESSIONS permite a identificação e seleção de hot expressions. Quando uma instância de banco de dados é reiniciada, o método Database In-Memory FastStart (IM FastStart) economiza tempo reduzindo a quantidade de dados que devem ser preenchidos no armazenamento de coluna de IM. O formato colunar é ideal para digitalização de dados devido ao seu alto rendimento. Você pode usar a análise de dados em tempo real para explorar novas possibilidades e iterações. É possível verificar os dados em seu formato compactado sem antes descompactá-los no banco de dados Oracle.
Um predicado da cláusula WHERE é usado em dados compactados no banco de dados quando as colunas são compactadas usando algoritmos que permitem a compactação automática de colunas. Os filtros Bloom avançam nas junções convertendo predicados em tabelas de dimensão pequena em filtros em dimensões grandes. Quando os dados são armazenados no armazenamento de coluna IM, é mais fácil organizar e executar consultas complexas. A criação de estruturas de acesso é uma etapa crítica para melhorar o desempenho da consulta analítica. A abordagem mais comum é criar índices analíticos, visualizações materializadas e cubos OLAP. Uma linha deve ser inserida em uma tabela, o que requer a modificação de todos os índices. Os bancos de dados Oracle são armazenados no formato de armazenamento em disco da Oracle, que é idêntico ao formato colunar.
É totalmente compatível com RMAN, Oracle Data Guard e Oracle ASM. Não requer o uso de uma ferramenta de migração de dados gerenciada pelo usuário. Se você usar as funções analíticas do Oracle ou um código PL/SQL personalizado, terá acesso a uma gama mais ampla de consultas analíticas. As únicas tarefas necessárias são dimensionar o armazenamento de coluna IM e especificar valores de objeto para o preenchimento. Na tabela abaixo, você encontrará uma lista das tarefas de configuração mais básicas do IM Column Store. Você pode baixar o In-Memory Advisor para PL/SQL e usá-lo para analisar a carga de trabalho de processamento analítico do seu banco de dados. O processamento analítico difere de outras atividades de banco de dados com base na cardinalidade do plano, no uso de consultas paralelas e em outros fatores.
O In-Memory Advisor não está incluído nos pacotes PL/SQL armazenados no sistema. Você deve primeiro obter o pacote do Oracle Support. As estimativas do consultor indicam melhorias no desempenho do processamento analítico com base nos seguintes fatores. Os tempos de espera para E/S do usuário, transferências de cluster e eventos de travamento do cache do buffer podem ser eliminados. Dependendo do tipo de compactação, os custos de compactação incorrem em heurística.
O que está na memória no banco de dados?
Um banco de dados na memória, ao contrário de um banco de dados baseado em disco ou SSD, é projetado para armazenar dados na memória principalmente para fins de armazenamento de dados. Os armazenamentos de dados criados na memória usam um método de baixo custo para eliminar a necessidade de acessar discos para reduzir os tempos de resposta.
Vantagens dos bancos de dados na memória
Os bancos de dados na memória tornaram-se mais populares nos últimos anos porque oferecem muitas vantagens sobre os bancos de dados tradicionais. A primeira vantagem deles é que podem armazenar todos os tipos de dados em um mesmo sistema, tornando-os ideais para aplicações que precisam armazenar grandes quantidades de dados não estruturados. Além da velocidade e eficiência dos bancos de dados na memória, os usuários podem acessar os dados mais rapidamente. Além disso, os bancos de dados na memória podem ser usados por pequenas empresas e consumidores porque são simples de usar e gerenciáveis.
A Oracle tem um banco de dados Nosql?
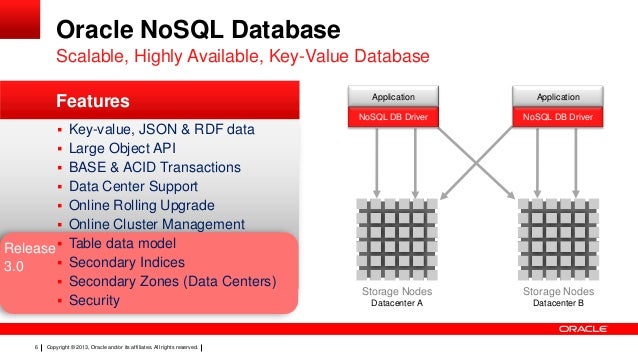
Sim, a Oracle possui um banco de dados nosql chamado Berkeley DB. O Berkeley DB é um banco de dados de código aberto escalável e de alto desempenho.
Onde os dados Nosql são armazenados?
Em vez de armazenar dados em um banco de dados relacional, os bancos de dados NoSQL armazenam dados em documentos. Em outras palavras, nós os dividimos em SQL e uma variedade de modelos de dados flexíveis para classificá-los. Um banco de dados NoSQL pode ser um banco de dados de documentos puro, um banco de dados de armazenamento de chave-valor, um banco de dados de colunas largas ou um banco de dados de grafos.
Um dos usos mais comuns dos bancos de dados NoSQL é o armazenamento rápido de grandes quantidades de dados não relacionados. NoSQL é um tipo de banco de dados que não compartilha dados relacionais. Durante a década de 1970, os bancos de dados relacionais ganharam popularidade como padrão para armazenamento de dados. De acordo com Ben Finkel, um instrutor CBT, NoSQL está preocupado com velocidade e flexibilidade ao invés de consistência e eficiência. Apesar de sua velocidade e eficiência, os bancos de dados construídos com tecnologia relacional não são tão simples quanto parecem. O banco de dados NoSQL não exige o design ou planejamento das estruturas de dados. Isso permite que os desenvolvedores criem, criem protótipos e implementem aplicativos com muito mais rapidez.
Eles funcionam de forma semelhante ao desenvolvimento ágil de software, que também é popular. Os bancos de dados NoSQL podem armazenar uma variedade de tipos de dados, tornando-os simples de configurar. Os bancos de dados NoSQL exigem mais capacidade de computação para serem executados do que os bancos de dados relacionais. O Raspberry Pi tem a capacidade de executar pequenos bancos de dados NoSQL , mas os servidores da Web serão significativamente mais exigentes. Os gráficos, ao contrário dos pares chave:valor ou documentos, são abstratos. Nós e arestas são os dois componentes dos grafos. Os nós podem conter informações sobre um objeto (pessoa, lugar, coisa, ideia, etc.). A relação entre um nó e suas arestas é explicada por arestas. O modelo de dados de coluna larga é semelhante às linhas e colunas em um banco de dados relacional.
Vários fatores contribuem para o aumento da popularidade dos bancos de dados NoSQL. Os bancos de dados relacionais tradicionais são ineficientes, demorados e propensos à corrupção de dados, enquanto os bancos de dados baseados em microsserviços têm melhor desempenho. Por um bom motivo, JSON é o formato preferido para bancos de dados NoSQL. Simplificando, os documentos JSON são mais compactos e legíveis do que outros tipos de documentos. JSON é um formato de representação de dados criado em JavaScript.
JSON é mais legível e compacto do que o formato de texto padrão.
Os bancos de dados NoSQL são mais eficientes que os bancos de dados relacionais tradicionais em termos de velocidade e desempenho.
Eles facilitam o uso.
Eles são mais resistentes à corrupção de dados do que outros animais.

Os vários tipos de bancos de dados Nosql
Os bancos de dados NoSQL, como o MongoDB, são populares devido à sua simplicidade no armazenamento de dados, que é muito mais fácil de entender do que os tipos de modelos de dados usados nos bancos de dados SQL. Os desenvolvedores frequentemente têm acesso direto à estrutura de um banco de dados NoSQL.
Um banco de dados NoSQL é um banco de dados não tabular que armazena dados de maneira diferente de um banco de dados relacional (também conhecido como SQL). Os vários tipos de bancos de dados NoSQL são baseados em seus modelos de dados. Os principais tipos de documentos são gráficos, tabelas e declarações de valor-chave.
Como instalo o Nosql para armazenar dados de forma estruturada?
Os dados podem ser estruturados, semiestruturados ou não estruturados em um banco de dados NoSQL, permitindo que sejam acessados por vários mecanismos. A grande vantagem de seu software é que ele é semiestruturado (JSON, XML, mas nem todos os campos são conhecidos), o que leva a dados não estruturados.
Como os dados podem ser armazenados em um banco de dados não relacional?
Como um banco de dados não relacional não usa o esquema tabular da maioria dos bancos de dados tradicionais, não há linhas ou colunas. Os bancos de dados não relacionais, por outro lado, usam um modelo de armazenamento otimizado para o tipo de dados que precisam ser armazenados.
O que é banco de dados Oracle Nosql
Um banco de dados Oracle NoSQL é um armazenamento de chave-valor distribuído e escalável, projetado para fornecer alto desempenho, escalabilidade horizontal e fácil disponibilidade. O Oracle NoSQL Database é um banco de dados compatível com NoSQL que fornece armazenamento de dados de par chave-valor. O banco de dados Oracle NoSQL é executado em um cluster de servidores comuns e fornece uma API Java simples para acessar o banco de dados.
O SDK Oracle NoSQL para Spring Data inclui um módulo de implementação Spring Data. Esse recurso pode ser usado para conectar-se a um cluster Oracle NoQL Database ou ao Oracle NoQL Cloud Service. Adicione a dependência maven ao XML do seu projeto para uso com o SDK. Para ter acesso a essas informações, deve-se usar o seguinte. Nosql.spring é um cliente da Oracle. Usando um método NosqlDbConfig para configurar um banco de dados. Defina uma classe de entidade da seguinte maneira.
Recomenda-se a criação de um repositório para a extensão Nosql . A classe do aplicativo deve ser escrita. Ao adicionar arquivos de dependência a org.springframework.boot:spring-boot, você pode começar a usar o Spring Framework.
Exemplo de Memória Oracle
Um exemplo de memória Oracle seria uma empresa usando um banco de dados Oracle para armazenar e processar seus dados na memória. Isso permitiria processamento e recuperação de dados mais rápidos, além de reduzir a necessidade de armazenamento em disco.
Sem alterações na base de código, os tipos de consulta, como grupo por operações (consultas analíticas), melhoraram de 4 a 27 vezes. Uma consulta de análise on-line que requer 11 segundos para ser concluída leva 399 milissegundos para ser concluída usando o OIM. Manter as partições consultadas com mais frequência na memória para grandes tabelas particionadas é uma boa ideia. Quando uma tabela possui colunas muito largas, é recomendável excluir as colunas que são consultadas com pouca frequência. Como cada coluna não é um componente na memória de uma consulta, o Oracle define o cache do buffer como 0. A taxa de compactação é aumentada para que menos processamento seja necessário para processá-la, economizando espaço. Quanto mais específica a consulta, maior o aumento de velocidade fornecido pelo OIM. Uma consulta que retornou 75 linhas de uma tabela de 20 milhões de linhas executando o Oracle In-Memory levou 69 vezes mais tempo do que usando o DBMS padrão . Como resultado, pode fornecer ganhos de desempenho até 67 vezes mais rápidos (em consultas altamente seletivas).
Por que a área Pl/sql merece mais memória
Para PL/SQL e seus objetos associados, procedimentos PL/SQL e objetos globais são armazenados na memória de área PL/SQL. Todos esses objetos possuem funções definidas pelo usuário, são vinculados a um pacote PL/SQL e possuem privilégios de objeto. A execução paralela do Oracle Database usando a memória de área PL/SQL também é possível.
A recomendação geral da Oracle é alocar 95% da memória total para o SGA e 5% para a área PL/SQL.
Oracle Nosql x Cassandra
Existem algumas diferenças importantes entre o Oracle NoSQL e o Cassandra. Por um lado, o Cassandra é um projeto de código aberto, enquanto o Oracle NoSQL é um sistema proprietário. O Cassandra também é um banco de dados orientado a colunas, enquanto o Oracle NoSQL é um banco de dados orientado a linhas. Por fim, o Cassandra se concentra na alta disponibilidade e na escalabilidade horizontal, enquanto o Oracle NoSQL se concentra na facilidade de uso e no gerenciamento de dados hierárquicos.
O Apache Cassandra é um banco de dados NoSQL adequado para alto desempenho, escalabilidade linear, consistência ajustável e cargas de trabalho de baixa latência em diversas cargas de trabalho. Na maioria dos casos, o Apache Cassandra não será a melhor escolha para o seu caso de uso porque carece de semântica consistente entre seu banco de dados relacional e os bancos de dados NoSQL com transações ACID. Se você precisar de redundância de dados reduzida e conformidade com ACID, considere usar bancos de dados SQL em vez de Oracle. O HBase não é comumente usado por desenvolvedores da Web ou móveis porque foi projetado para funcionar com casos de uso de data lake frios ou históricos. Um aplicativo Cassandra é, por outro lado, mais prontamente disponível e capaz de lidar com ambientes altamente exigentes.
Qual é a diferença entre Cassandra e Oracle?
O Oracle Database Management System (ODMS) é um sistema de gerenciamento de banco de dados relacional (RDBMS) disponível em dois formatos: S.NO.ORACLE CASSANDRA1. Foi desenvolvido pela Oracle Corporation em 1980 e criado pela Apache Software Foundation em 2008; 2. Foi escrito O software de código aberto pode ser acessado executando mais sete linhas.
O Oracle é um banco de dados Nosql?
O Oracle NoSQL Database Cloud Service simplifica para os desenvolvedores a criação de aplicativos usando modelos de banco de dados de documentos, colunas e valores-chave, fornecendo tempos de resposta previsíveis em milissegundos, replicação de dados para alta disponibilidade e aplicativos baseados em documentos.
Cassandra e Nosql são iguais?
O Cassandra é um sistema de gerenciamento de banco de dados de armazenamento de coluna ampla , distribuído e de código aberto, gratuito e baseado no projeto Cassandra de código aberto.
A Netflix usa Cassandra?
O Cassandra no Amazon Web Services serve como um componente chave da infraestrutura do serviço de streaming global da Netflix.
Oracle Nosql Database Vs Mongodb
Existem muitas diferenças entre o Oracle NoSQL Database e o MongoDB. Primeiro, o MongoDB é um banco de dados orientado a documentos, enquanto o Oracle NoSQL Database é um armazenamento de chave-valor. Isso significa que o MongoDB armazena dados em documentos semelhantes a JSON, enquanto o Oracle NoSQL Database armazena dados em pares chave-valor. Em segundo lugar, o MongoDB oferece suporte a índices secundários, enquanto o Oracle NoSQL Database não. Em terceiro lugar, o MongoDB tem uma linguagem de consulta mais rica do que o Oracle NoSQL Database. Quarto, o MongoDB suporta fragmentação automática, enquanto o Oracle NoSQL Database não. Por fim, o MongoDB é de código aberto, enquanto o Oracle NoSQL Database não é.
O MongoDB é simples de configurar e oferece flexibilidade incrível em termos de flexibilidade de design. Se seus formatos de dados não forem consistentes, um banco de dados NoSQL como o Oracle NoSQL Database é uma boa escolha. Se você precisar de menos redundância de dados e conformidade ACID, usar um banco de dados SQL pode ser a melhor opção para você. Como os bancos de dados NoSQL, como o MongoDB, carecem de interfaces gráficas, eles normalmente não devem ser usados em conjunto com bancos de dados tradicionais. Para melhorar a usabilidade, você deve instalar aplicativos de terceiros que permitem visualizar visualmente os esquemas e documentos armazenados. Se você não conhece um DBA ou um administrador de sistema como usar o MongoDB, é uma boa ideia usar um provedor de hospedagem MongoDB terceirizado.
Principais diferenças entre Mongodb e Oracle
Existem várias diferenças significativas entre MongoDB e Oracle que devem ser levadas em consideração ao decidir qual software comprar. A plataforma MongoDB é conhecida por sua capacidade de lidar com grandes quantidades de dados, enquanto o Oracle é mais comumente usado para criar aplicativos corporativos. Além disso, o MongoDB inclui recursos avançados para pesquisar qualquer campo ou intervalo de consultas, enquanto os recursos do Oracle são menos limitados. O Oracle escala verticalmente porque é baseado em sharding, enquanto o MongoDB escala horizontalmente porque é baseado em sharding. Além disso, o MongoDB é construído em uma arquitetura de sistema distribuído, em vez de um design monolítico de nó único, tornando-o distinto do Oracle em termos de arquitetura.