
O poder do MarkLogic: gerenciamento de big data e segurança em um só lugar
Publicados: 2023-01-29MarkLogic é um poderoso banco de dados Nosql que permite que as organizações armazenem, gerenciem e pesquisem grandes volumes de dados de maneira fácil e rápida. É altamente escalável e oferece alto desempenho, tornando-o ideal para aplicativos de big data. O MarkLogic também possui recursos de segurança integrados que protegem os dados contra acesso não autorizado e garantem a integridade dos dados.
Em resposta a uma demanda por uma forma mais flexível e eficiente de armazenar grandes quantidades de dados, nasceu um movimento conhecido como NoSQL. Este post pretende ser uma cartilha geral para qualquer pessoa interessada neste campo emergente. Esses esforços foram feitos para aliviar limitações específicas que existem no mundo RDBMS . As junções não são possíveis em algumas opções NoSQL, portanto, você deve manter várias cópias dos dados. É mais provável devido à falta de índices globais e ao fato de que os dados são particionados em servidores comuns usando uma chave usada para recuperação. Os usuários do NoSQL esperam mecanismos de pesquisa de texto completo como Lucene, Solr e Sphinx, mas eles não são os melhores. A solução de expansão MarkLogic provou ser implantável horizontalmente em hardware comum com capacidade de petabyte.
É um tipo de banco de dados muito diferente de outros bancos de dados por si só. O MarkLogic nunca foi criado para ser capaz de resolver um problema específico. Ele foi construído desde o início como uma plataforma para aplicativos de classe empresarial, independentemente do tamanho.
O Data Warehouse Operacional de Nova Geração da MarkLogic é uma ferramenta de software para conduzir análises operacionais.
Navegue até http://localhost:8000/appservices/ para encontrar a página Application Services. Com a seção Banco de dados no MarkLogic Server , você pode acessar todos os bancos de dados e excluir bancos de dados, bem como criar e configurar um banco de dados.
Qual banco de dados o Marklogic usa?
A maioria das organizações hoje requer um banco de dados para executar suas operações. Ele é usado para executar aplicativos transacionais, operacionais e analíticos do data center e gerenciar com segurança uma ampla variedade de fontes de dados.
A plataforma da MarkLogic permite carregamento, consulta, manipulação e renderização simultâneos de conteúdo. Você pode pesquisar conteúdo rapidamente se ele for convertido automaticamente em XML e indexado. A Big Publishing usou consulta de elemento XML, pesquisa de proximidade XML e pesquisa de texto completo para melhorar seus recursos de pesquisa. Em 4 a 5 meses, uma empresa pode implementar uma solução e começar a usá-la. O governo do condado de Quakezone quer facilitar o acesso de funcionários, desenvolvedores e residentes do condado a informações em tempo real, tornando-o mais fácil para eles. Eles exigem uma solução de infraestrutura de TI que será implementada de forma rápida e fácil. Com o MarkLogic, o município pode visualizar e correlacionar dados de várias maneiras, inclusive transformando-os e enriquecendo-os.
A Time Traders Services substituiu seu sistema legado pelo MarkLogic Server. A solução é bastante reduzida em termos de latência de alerta, ao mesmo tempo em que fornece informações imediatas e relevantes para o portal e e-mail do cliente. Os operadores financeiros obtêm uma vantagem no escritório e no pregão ao informar os clientes sobre novas pesquisas disponíveis. MarkLogic é usado para manter instalações secretas no governo federal. As trocas se beneficiam de um custo mais baixo do sistema de hardware quando o MarkLogic otimiza o hardware comum. Com alto desempenho, há menos servidores de hardware para enfrentar. Em vez de comprar servidores maiores e mais caros, um aumento na escalabilidade permite a instalação de mais servidores comuns.
Uma das principais vantagens do MarkLogic Data Hub é sua capacidade de integração com outras fontes de dados. O software pode se conectar facilmente a sistemas legados, como ERP e CRM, bem como a fontes mais recentes, como data warehouses de clientes e fontes de dados de streaming. Além disso, o MarkLogic Data Hub é capaz de processar uma ampla variedade de formatos de dados, simplificando a ingestão de dados. Finalmente, o MarkLogic Data Hub é extremamente fácil de usar. É um programa gratuito, então você não precisa pagar para usá-lo. Além disso, o programa é de código aberto, para que você possa personalizá-lo para atender às suas necessidades específicas.
Bancos de dados multimodelo: o melhor dos dois mundos
A tabela a seguir lista os tipos de banco de dados mais comuns para bancos de dados multimodelo. Um banco de dados multimodelo permitirá que você selecione modelos de dados que são mais baratos de manter. A indexação no estilo de pesquisa e o armazenamento de dados transacionais do MarkLogic permitem que ele combine e enriqueça os dados em seus sistemas. Como resultado, ele pode ser usado para executar processos ETL. Além disso, como o MarkLogic é um banco de dados de gráficos, ele é uma excelente opção de pilha tripla para quem procura um banco de dados de gráficos.
O Ldap é um Nosql?
Como cada banco de dados NoSQL vem com seu próprio protocolo, selecionar um é basicamente prendê-lo a esse tipo de banco de dados. Se você precisar alterar o servidor, também deverá alterar os clientes.
Quando estava sendo usado pela Pearson Education, o NoSql era usado para hospedar aulas online, registros de alunos e assim por diante. Nesse caso, todos na equipe precisavam começar a trabalhar rapidamente com o Mongo. É fácil esquecer o serviço Ldap, que é usado por centenas de milhares de servidores e desktops no mundo. Usando a ferramenta de console 389-ds, você pode criar facilmente novos objetos e atributos. Em termos de computação em nuvem, eu colocaria dois discos master em cada zona para garantir a replicação wan (multimasters). Você pode ajustar os níveis de replicação. Para modificar o esquema, você pode fazê-lo online.
O que é um exemplo de um Nosql?
A maioria dos setores em que os bancos de dados NoSQL são usados depende deles para uma variedade de propósitos. O tipo de banco de dados NoSQL utilizado em determinado caso terá impacto em seu funcionamento. Bancos de dados de documentos, como o MongoDB, são exemplos de bancos de dados de uso geral . Grandes quantidades de dados podem ser armazenadas em bancos de dados de valor-chave, simplificando as consultas de pesquisa.
Os benefícios dos bancos de dados Nosql
Ao contrário dos bancos de dados relacionais tradicionais, os bancos de dados NoSQL diferem deles porque rompem com o modelo tradicional de organização de dados em favor de uma estrutura mais flexível que permite armazenamentos de dados muito mais dinâmicos e vastos. Esta é uma vantagem quando se trata de escalar um armazenamento de dados para maior tráfego ou quando você precisa atender a diferentes necessidades do usuário. Devido ao conjunto exclusivo de benefícios disponíveis nos bancos de dados NoSQL, eles estão se tornando cada vez mais populares o tempo todo e nem todos os aplicativos se beneficiarão deles. Se você está procurando um armazenamento de dados mais flexível que possa lidar com uma ampla gama de demandas, os bancos de dados NoSQL são uma excelente escolha.
O Uber usa Sql ou Nosql?
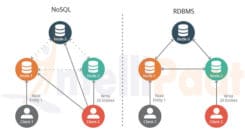
Quando um banco de dados sem algoritmos é usado para armazenar dados, ele é conhecido como banco de dados NoSQL. Como os bancos de dados NoSQL carecem de suporte de índice (devido à falta de transações distribuídas), a equipe de atendimento da Uber usa uma tabela separada para armazenar o índice.
O Uber publicou um artigo em seu site explicando por que o Uber mudou do PostgreSQL para o InnoDB. Este post foi feito a partir do artigo da Uber na tentativa de proporcionar um melhor entendimento. O PostgreSQL sempre precisa atualizar todos os índices em uma tabela ao atualizar as linhas ao indexar uma tabela, conforme descrito em detalhes neste artigo. Essa abordagem também resulta em um aumento nas E/S de disco para atualizações que alteram colunas não indexadas. Neste artigo, eles descrevem a penalidade de índice clusterizado como uma desvantagem leve, o que é significativo se você executar muitas consultas usando índices secundários. O artigo não menciona que essa penalidade se aplica a qualquer instrução com uma cláusula where, não apenas select. Uma varredura somente de índice do Postgres, por outro lado, é bastante inútil.
Eles parecem funcionar bem em um importante caso de uso de armazenamento de chaves no futuro. Pacotes destinados a trabalhar com front-ends SQL (mas com poucas funções) estão disponíveis. A Uber criou seu próprio banco de dados (Schemaless), além de usar InnoDB e MariaDB. Uma divisão de nó é uma operação importante em uma árvore B. Uma divisão de nó ocorre quando um ou mais nós não conseguem hospedar uma nova entrada. Na pior das hipóteses, a divisão aumentará até o nó raiz, que também será dividido e substituído por um novo nó. Como resultado, toda a árvore cai, fazendo com que o saldo do índice permaneça constante.
Um bug no processo de replicação pode deixar grandes partes da árvore completamente irreparáveis. É possível que o mestre não consiga determinar o que as réplicas estão tentando fazer e exclua os dados que ainda são necessários para a conclusão da consulta. Esse problema pode ser resolvido atrasando o aplicativo do fluxo de replicação por um tempo limite configurável, permitindo que a transação de leitura tenha sua vez. Existem alguns engenheiros que não são especialistas em banco de dados e nem sempre entendem esse problema, principalmente ao usar um ORM que obscurece detalhes de baixo nível, como transações abertas. A maioria dos desenvolvedores está ciente de que as transações podem ser usadas para reverter a gravação. Se mais pessoas forem contratadas por uma empresa, sua qualificação estará mais próxima da média. O aumento no tamanho da amostra é impulsionado pela contratação de mais pessoas.
Os casos de uso do Uber exigiram o uso do Schemaless, um novo banco de dados NoSQL . O artigo deles sugere que o Postgres foi substituído pelo MySQL, mas não é o caso; em vez disso, sua solução personalizada é apoiada pelo MySQL. Não há menção de como seus requisitos mudaram quando eles mudaram para PostgreSQL do MySQL neste artigo, então não há como dizer. Há apenas uma coisa que se destaca na mente do leitor: Postgres é terrível.
Por que os bancos de dados Nosql são perfeitos para o Uber
O banco de dados MySQL da Uber é construído sobre um banco de dados NoSQL, portanto, pode-se deduzir do texto que eles usam esse banco de dados. Além disso, pode-se inferir dos dados que esse banco de dados NoSQL está sendo usado para armazenar em cache e enfileirar dados. A Amazon é outra empresa de banco de dados NoSQL, pois fornece um conjunto abrangente de ferramentas para o desenvolvimento de aplicativos orientados a banco de dados.
Marklogic Nosql
O MarkLogic é um poderoso banco de dados NoSQL que permite aos desenvolvedores criar de maneira rápida e fácil aplicativos que lidam com grandes volumes de dados. O MarkLogic é fácil de usar e dimensionar, tornando-o a escolha ideal para organizações que precisam gerenciar grandes quantidades de dados.
O MarkLogic Server é um banco de dados que foi criado desde o início para simplificar a pesquisa de grandes quantidades de dados heterogêneos pelos usuários. O MarkLogic incorpora bases de dados internas, índices de estilo de pesquisa e comportamentos de servidor de aplicativos em um sistema unificado que pode ser executado simultaneamente. Documentos XML e JSON são usados como modelos de dados e seus dados transacionais são armazenados em um repositório de dados transacionais . Os dados do documento podem começar como XML ou JSON, mas também podem ser transformados depois de ingeridos. Os modelos de dados do documento geralmente contêm todos os dados relacionados no mesmo documento, portanto, os dados são desnormalizados antes de serem tornados públicos. O conteúdo XML pode ser definido como esquemas para representar uma classe de modelos de conteúdo de documentos. Quando um documento específico deve ser estruturado de uma maneira específica, é fundamental ter um identificador para o documento.
Os esquemas XML podem ser importados para o banco de dados Schemas ou colocados no diretório Config. Depois disso, você pode especificar um conjunto de esquemas para um App Server específico ou um grupo de servidores. O MarkLogic também oferece suporte a esquemas SQL virtuais que fornecem o contexto para exibições SQL, conforme definido no SQL Data Modeling Guide. O MarkLogic Server pode pesquisar, armazenar e gerenciar dados semânticos em triplos RDF, que são armazenados na memória. Semântica é um conjunto de padrões W3C que permite a troca de dados legíveis por máquina (e informações sobre relacionamentos entre dados). O MarkLogic permite armazenar, pesquisar e gerenciar esse tipo de dados usando SPARQL e SPARQL Update nativos, bem como JavaScript, XQuery e REST. Você pode otimizar o gerenciamento de dados binários com o conjunto de mecanismos do MarkLogic Server.

Um documento binário pode ser armazenado com base em seu tamanho, que é determinado por um conjunto de limites. MarkLogic é um aplicativo de thread único projetado para vários processadores ao mesmo tempo. Existem inúmeras portas de soquete que podem ser usadas para comunicação externa. A plataforma MarkLogic destina-se a fornecer velocidade e escala. As consultas avançadas no MarkLogic são gravadas em terabytes de dados. As maiores implantações ao vivo já ultrapassaram 200 terabytes e um bilhão de documentos. Quando clusters são usados, um alto nível de disponibilidade é alcançado.
Esse tipo de servidor geralmente é alojado em uma caixa de 4 ou 8 núcleos, 64 ou 128 Gb ou maior capacidade. Elastic load balancers (ELBs) são integrados ao Amazon Elastic Compute Cloud (EC2), o que permite que os clusters MarkLogic distribuam e equilibrem o tráfego de aplicativos automaticamente. Para melhorar a disponibilidade do ambiente EC2, os D-Nodes podem ser agrupados no mesmo local.
O que é banco de dados Marklogic
O MarkLogic é um poderoso banco de dados NoSQL que permite aos desenvolvedores criar aplicativos mais rapidamente, fornecendo as ferramentas necessárias para trabalhar com todos os tipos de dados. O MarkLogic é o único banco de dados NoSQL que combina o poder de um banco de dados orientado a documentos com a flexibilidade de um armazenamento de valor-chave, tornando-o a plataforma ideal para os aplicativos modernos de hoje.
É uma poderosa plataforma de gerenciamento de dados que fornece um sistema unificado para gerenciamento de dados. São utilizados modelos de dados de documentos em XML e JSON, que armazena os documentos em um repositório transacional. O Data Hub está localizado no topo do data lake e contém dados de alta qualidade, curados, seguros, desduplicados, indexados e que podem ser consultados. Além disso, o MarkLogic Data Hub foi projetado para gerenciar grandes conjuntos de dados com camadas de dados automatizadas que armazenam e recuperam dados de um data lake com segurança.
Por que os bancos de dados gráficos estão assumindo o controle
Os bancos de dados gráficos estão rapidamente se tornando a opção ideal para armazenar dados em uma ampla variedade de formatos que são difíceis de gerenciar manualmente. Os bancos de dados SQL tradicionais não podem lidar com esse tipo de consulta e podem ser muito benéficos ao lidar com esse tipo de consulta. Se você precisar consultar dados de maneira que os bancos de dados SQL possam manipular, bem como se precisar armazenar dados em gráficos, o MarkLogic é uma boa opção.
Banco de Dados Marklogic Vs Mongodb
O banco de dados corporativo NoSQL da MarkLogic inclui todos os recursos necessários em uma plataforma. O MongoDB, por outro lado, é usado para organizar grandes ideias. MongoDB é um serviço MongoDB que armazena dados em documentos semelhantes a JSON que podem ser estruturados de várias maneiras.
Se você tiver dados META, poderá usar o MarkLogic porque ele recupera tudo muito rapidamente. Existem alternativas melhores para usar um banco de dados relacional no caso de uma necessidade. O MongoDB é uma ferramenta incrível para uma variedade de aplicações devido à sua incrível flexibilidade e facilidade de uso. Apesar do código aberto ser usado em quase tudo, o banco de dados de back-end é extremamente importante. O suporte ao cliente da MarkLogic é extremamente responsivo e profissional. Eles são rápidos em responder a questões importantes e problemas de qualidade de produção. Estou ansioso para usar os recursos do MongoDB para aproveitar um pouco de seu poder.
Apenas alguns aspectos podem ser melhorados ou simplificados. Se você ainda não tem um DBA ou administrador de sistema que conheça o MongoDB, você deve procurar um provedor de hospedagem do MongoDB especializado na área. Quando seu conjunto de dados aumenta, você pode usar o mecanismo de armazenamento do Cassandra para criar gravações em tempo constante. O MongoDB pode ser usado para análises usando o suporte nativo do Hadoop.
banco de dados Marklogic Graph
MarkLogic é um banco de dados gráfico. Ele usa um modelo de dados de gráfico para armazenar e consultar dados. Um banco de dados gráfico é um banco de dados que usa um modelo de dados gráfico para armazenar e consultar dados.
O Semantic Graph Developer's Guide é uma leitura obrigatória para qualquer pessoa interessada no campo de gráficos semânticos. Os tópicos incluídos neste guia incluem: Os dados podem ser baixados. Usando a amostra completa de Persondata do DBPedia (tanto em Turtle quanto em inglês), você pode mostrar a eles como usar uma palavra em Turtle ou em inglês. O banco de dados Documentos possui um índice triplo e um léxico de coleção que pode ser ativado por padrão. Antes de usar um banco de dados para triplos, certifique-se de que ambas as opções estejam habilitadas. mlcp é um método ideal para triplos de carregamento em massa em um ambiente de área de trabalho do Windows. A função SPARQL nativa ou a função integrada sem:sparQL são métodos aceitáveis para executar consultas MarkLogic . A seção Downloading Dataset assume que você carregou o conjunto de dados de amostra.
Marklogic Data Hub
O Data Hub da MarkLogic é uma interface de software gratuita e de código aberto que ingere dados de várias fontes, harmoniza-os, domina-os e depois os pesquisa e analisa. A solução é executada no MarkLogic Server e destina-se a fornecer uma plataforma unificada para aplicativos de missão crítica.
Para que serve o Marklogic
MarkLogic é um poderoso banco de dados que permite armazenar, gerenciar e pesquisar dados com mais eficiência. Ele é usado por organizações em uma variedade de setores para alimentar seus aplicativos e sites. O MarkLogic é especialmente adequado para lidar com grandes quantidades de dados e consultas complexas.
Servidor Marklogic
O MarkLogic Server é uma poderosa plataforma de banco de dados NoSQL que permite aos desenvolvedores criar de maneira rápida e fácil aplicativos sofisticados que aproveitam todos os seus dados, independentemente de sua estrutura ou localização. O MarkLogic Server é construído em uma arquitetura única que combina o melhor dos mundos relacional e NoSQL, dando aos desenvolvedores a flexibilidade de trabalhar com seus dados da maneira que melhor atenda às suas necessidades.
DocumentManager, uma instância de DatabaseClient criada especificamente para gerenciamento de documentos, pode ser usada para gerenciar documentos. Para demonstrar como ler um documento XML, use o ReadXMLDocument.java baseado em Java da Marklogic. A biblioteca Java ReadMetadata mostra como detectar o tipo de documento que você recebeu, bem como manipulá-lo adequadamente. Inserir um documento de texto é semelhante a inserir um documento PDF, mas você deve usar um StringHandle ou fornecer o formato conforme mostrado no exemplo anterior. A API Java pode ser usada para acessar documentos e metadados de várias maneiras. O método DeleteDocument.java pode ser usado para excluir vários documentos de uma vez. Downloads de documentos de grandes proporções.
Um documento por vez pode ser caro ao usar esquemas de autenticação Digest porque um documento é necessário para carregar. Usamos termos como pesquisa e consulta da mesma forma no MarkLogic, independentemente do contexto em que os usamos. Se você deseja expressar uma ampla variedade de resultados de pesquisa, uma sintaxe de consulta é uma maneira simples e poderosa de fazer isso. O texto de pesquisa é especificado usando o método setCriteria de nosso gerenciador de consultas depois de obter uma instância de consulta de string inicial de nosso gerenciador de consultas. É verdade que mesmo uma pesquisa simples pode ser muito poderosa se usada na configuração de pesquisa padrão do MarkLogic. Conforme especificado na definição da consulta, três métodos são usados para implementar cada consulta. As duas primeiras opções permitem especificar um local de consulta ou um conjunto de coleta.
O último permite associar uma consulta a um conjunto de opções de pesquisa personalizadas que são armazenadas no servidor. A seguir está uma lista dos resultados da pesquisa. Ao executar o programa e inspecionar o console, você pode ver como MarkLogic representa seus resultados de pesquisa em XML. O projeto do tutorial inclui um script Java chamado Search ResultsAsJSON. Java. Se você executar o programa, verá os resultados brutos da pesquisa JSON que foram recuperados do servidor. Getsearch resulta no formato POJO chamando seu método getMatchResults().
Você pode obter uma matriz de objetos MatchDocumentSummary passando uma string. Quando um documento contém um resultado de pesquisa, ele pode ser representado por um objeto MatchLocation. Uma opção padrão nomeada é usada se você não especificar explicitamente um nome. Por causa de sua importância em Mark Logic, a restrição é frequentemente usada. A configuração de um conjunto de opções inteiro é armazenada em src/main/ml-options/options ao criar ou substituir um conjunto de opções. As restrições listadas aqui estão disponíveis em uma variedade de formas. Faça um programa.
Este método deve retornar os mesmos resultados que CollectionSearch java. Como resultado dessa nova string de pesquisa, o critério de coleta Shakepeare agora é fornecido como parte da string de pesquisa pela restrição de tag. Como você pode ver, usamos o seguinte comando para implantar nossa configuração. Você poderia, em vez disso, abrir um novo prompt de comando e navegar para mlwatch, onde as alterações em seu script serão enviadas para Mark Logic. O contexto de uma palavra é testado em vez de sua chave ou elemento em termos de uma restrição de palavra, que é semelhante a uma restrição de valor. As palavras correspondentes também são formadas por hastes, o que significa que palavras semelhantes serão usadas, como estratégias e estratégias. Devemos criar/modificar os seguintes arquivos para habilitar o stemming:src/main/ml-config/databases/content-database.
A execução do comando abaixo ajudará na compreensão do procedimento. O módulo gradle mlUpdateIndexes é usado para atualizar tabelas de índice no módulo gradle mlReindexDatabase. Usando a restrição de propriedades, podemos pesquisar as propriedades de um documento por metadados. Usamos nossos metadados extraídos durante a ingestão e armazenados como propriedades do documento para gerar nossas imagens. Quando inserimos uma pesquisa por palavra para 'propriedades', ela será aplicada apenas a essa propriedade do documento. O método search() é usado no gerenciador de consultas para executar a consulta.
Para que serve o Marklogic?
MarkLogic Server é uma ferramenta de software que armazena e gerencia uma variedade de dados para executar aplicativos transacionais, operacionais e analíticos.
The Data Hub: sua solução completa para gerenciamento de dados
Os Data Hubs oferecem controle total sobre como os dados são gerenciados e acessados a partir de um data lake. No MarkLogic, a classificação automatizada de dados garante que os dados sejam armazenados e acessados com segurança a partir de um data lake e simplifica a integração de dados.
Como me conecto ao Marklogic?
Após a instalação e inicialização do MarkLogic, navegue até a interface administrativa baseada em navegador (em http://localhost:8001/), onde você aprenderá como obter uma licença de desenvolvedor e configurar um administrador.
Marklogic: o servidor de aplicativos com uma API Rest
O uso de aplicativos cliente da API REST para interagir com o MarkLogic Server usando uma instância da API REST está se tornando mais comum. A MarkLogic emprega 500 pessoas e é um dos maiores fornecedores de servidores de aplicativos do mercado. De acordo com suas projeções de receita, eles terão um pico de receita de $ 100,0 milhões em 2021, com uma receita média por funcionário de $ 200.000.