
Por que o Apache HBase é a melhor escolha para seu próximo projeto de big data
Publicados: 2022-11-16O Apache HBase é um banco de dados distribuído, não relacional e de código aberto, modelado a partir do Bigtable do Google e escrito em Java. Ele é desenvolvido como parte do projeto Apache Hadoop da Apache Software Foundation e é executado em HDFS (Hadoop Distributed File System), fornecendo recursos semelhantes ao Bigtable para Hadoop. Assim como o Bigtable, o HBase foi projetado para lidar com grandes quantidades de dados com alta taxa de transferência e é adequado para aplicativos que exigem acesso de baixa latência aos dados.
HBase, um banco de dados NoSQL, é usado para armazenar e recuperar dados com acesso aleatório. O modelo de dados nele contido é dinâmico e flexível, permitindo armazenar qualquer tipo de dado sem ser restrito. O HBase pode ser integrado ao MapReduce do Apache Hadoop para executar operações em massa (por exemplo, indexação, análise e assim por diante). O HBase é um banco de dados esparso, multidimensional e classificado baseado em mapas com várias versões de um único registro. Com suporte Hadoop MapReduce integrado , ele pode lidar com grandes quantidades de dados na velocidade da luz e em paralelo. A Arquitetura HBase é composta de quatro componentes principais: HMaster, HRegion, Hlog e HBase. O ZooKeeper é um projeto de código aberto que fornece vários serviços essenciais, além de fornecer vários recursos essenciais.
O ZooKeeper inclui um recurso que permite a sincronização distribuída de dados de configuração. Quando um nó falha no HBase, o zkQuorum gera mensagens de erro e começa a repará-lo. Petróleo e petróleo, marketing e publicidade, bancos e mercado de ações são apenas alguns dos domínios em que o HBase é usado.
Como um sistema de arquivos distribuído, o uso do HDFS no HBase tem algumas vantagens. O banco de dados pode, portanto, armazenar grandes conjuntos de dados, até mesmo bilhões de linhas, em um curto período de tempo, permitindo uma análise rápida.
Ele emprega uma abordagem não relacional e orientada a colunas para gerenciamento de banco de dados. As informações são armazenadas em colunas individuais e indexadas usando uma chave de linha exclusiva para cada coluna. Essa arquitetura fornece uma recuperação rápida e eficiente de linhas e colunas individuais, bem como um processo de varredura eficiente para colunas individuais em uma tabela.
Apache HbaseNome da empresaWebsiteReceitaFacebookwww.Facebook.com$117 bilhõesHortonworks Incwww.hortonworks.com75 milhõesJP Morgan Chasewww.JPMorganChase.com130 bilhões Palo Alto Networks Incwww.palo Alto
No MongoDB, existem vários tipos de projeções, filtragem e funções agregadas para escolher. Ao contrário do Hbase, que combina dados com valores-chave, os valores-chave podem ser compartilhados com outros aplicativos. MongoDB permite que você execute pesquisa de texto fornecendo índices de texto nativos, bem como replicação de dados HBase .
O Hadoop é um banco de dados Nosql?

Hadoop é uma estrutura de software de código aberto para armazenamento e processamento de big data. Ele usa um sistema de arquivos distribuído (HDFS) e MapReduce para processar e analisar dados. O Hadoop não é um banco de dados relacional tradicional, mas pode ser usado para armazenar e processar dados de maneira semelhante.
No MongoDB, não há necessidade de documentos porque o banco de dados é baseado no modelo de dados JavaScript Object Notation (JSON). Destina-se a ser rápido e simples de usar, bem como ter um índice bem definido e recursos de pesquisa. Um algoritmo map/reduce é usado para processar grandes conjuntos de dados no Hadoop, um sistema de armazenamento distribuído. Este produto foi projetado para fornecer uma solução econômica para análise e arquivamento de dados.
O Hbase usa SQL?
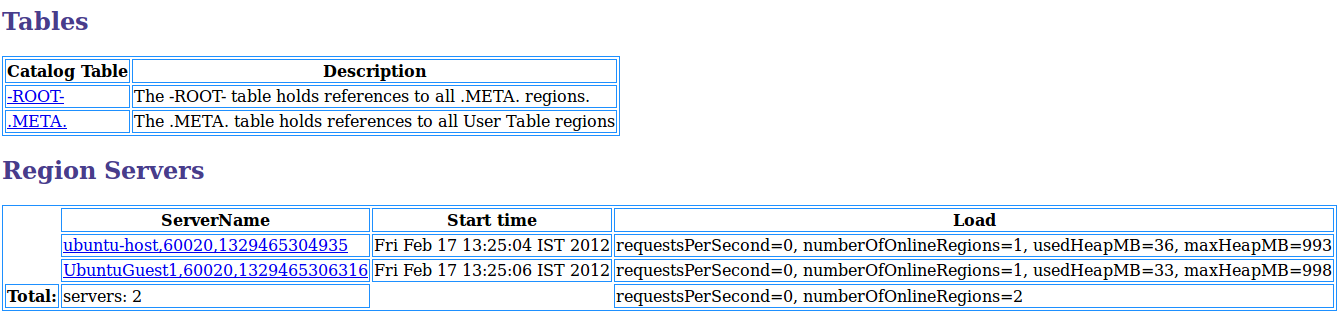
O HBase não é um banco de dados relacional e não usa SQL para consultar dados. O HBase usa um design de armazenamento de chave/valor que é otimizado para acesso rápido de leitura/gravação a grandes conjuntos de dados.
Devido à sua alta escalabilidade, suporte para programação de redução de mapa do Hadoop e implementação do conhecido white paper Google BigTable, o HBase é uma ótima opção para armazenamento de dados não estruturados. A facilidade de uso do HBase é um grande atrativo para aplicativos de warehouse que precisam processar grandes quantidades de dados rapidamente.
O que é a linguagem de consulta Hbase?
A Jaspersoft HBase Query Language, que é uma linguagem declarativa no estilo JSON, permite especificar quais dados recuperar do HBase. Ao usar a interface HBase REST Server, o conector converte a consulta em uma chamada API adequada, que é então executada na instância HBase .
Os benefícios de usar uma tabela Hbase
O que é família de colunas? Uma família de colunas pode se referir a uma coleção de colunas que compartilham um nome e tipo de dados comuns. Os nomes dos funcionários podem incluir as colunas id,name,hired_on,fired_on. Quais são os benefícios de usar tabelas HBase ? Uma tabela HBase oferece as seguintes vantagens: O design orientado a colunas do HBase facilita o armazenamento e o acesso a dados esparsos ou não estruturados. Devido à sua natureza tolerante a falhas, o HBase pode resistir à perda ou corrupção ocasional de dados. Como o HBase é tão simples de usar, você pode começar rapidamente a usar o armazenamento de big data. Como o HBase é escalabilidade, você pode adicionar mais servidores ao seu cluster para lidar com conjuntos de dados maiores.
Para que o Hbase não é bom?
Funções como SQL não podem ser executadas usando HBase HBase . Como não oferece suporte à estrutura SQL, não há otimização de consulta. O HBase usa CPU e memória intensivamente, com grande acesso sequencial de entrada ou saída, enquanto os trabalhos de Map Reduce normalmente são vinculados à entrada ou saída com memória fixa e consomem CPU e memória intensivamente.
Hbase: a melhor solução de armazenamento de dados para operações aleatórias de leitura e gravação
É ideal para aplicativos que executam operações de leitura e gravação aleatórias, bem como para aqueles que usam operações de leitura e gravação aleatórias. O HBase também é uma boa opção para aplicativos que requerem acesso a dados em tempo real.
Hbase é como Cassandra?

Ao contrário do Cassandra, que é executado em vários servidores e versões do mesmo arquivo, o Hbase é executado em um servidor de dados. Como resultado, as leituras do Hbase são mais fáceis de acessar do que as leituras do Cassandra. Os dados do Hbase são armazenados em HDFS, onde possui filtros bloom e caches de blocos que permitem realizar leituras mais rápidas.
Esses bancos de dados NoSQL, que podem lidar com grandes conjuntos de dados, foram criados por Cassandra e HBase. Eles compartilham muitas características em comum, incluindo seus traços comuns. Em face disso, ambos são distintos. Neste artigo, veremos como o HBase e o Cassandra diferem em termos dos fatores envolvidos. O Cassandra, como o HBase, possui infraestrutura Hadoop , mas também possui diferentes DBMSs e infraestrutura. Cassandra não requer nenhum poder de computação adicional. A indexação por meio de filtros bloom é o que o HBase faz.
Usando o Cassandra, várias linhas podem ser replicadas de um único endereço WAN com partições aleatórias. É preferível ter uma única fonte de dados em vez de várias fontes de dados no Cassandra. Além disso, a instalação do Cassandra Cluster é mais fácil do que a do HBase Cluster .
Hbase Vs Cassandra: Qual é melhor?
Cassandra e HBase podem ser lidos e gravados ao mesmo tempo, mas Cassandra é mais rápido. Além disso, o Cassandra é mais rápido que o HBase.
Hbase x Mongodb
Não há um vencedor claro ao comparar HBase e MongoDB. Ambos os sistemas têm seus próprios pontos fortes e fracos. O HBase é mais adequado para lidar com grandes quantidades de dados, enquanto o MongoDB é mais flexível e fácil de usar.
Após 4 anos com couchbase, mudamos para MongoDB e a transição foi perfeita. Apesar de receber suporte empresarial, tivemos uma experiência terrível com o Couchbase. Na pesquisa de texto completo, vários tipos de resultados são freqüentemente retornados se você executar uma variedade de consultas. Não há como configurar índices corretamente no Windows. Um servidor de produção pode suportar até seis usuários. Além de lidar com o cache na memória, uma instância menor do Memcached está incluída no Couchbase. Cada um dos 5.000 documentos ocupa 8 GB de RAM. Não há dúvidas sobre isso! Havia menos de 5.000 documentos em uma instância do Couchbase, menos de 20 índices e o consumo de RAM sempre foi superior a 8 GB.
A principal diferença entre o Amazon DynamoDB e o Apache HBase é que o Amazon DynamoDB é construído sobre o HDFS, que fornece pesquisas rápidas de registros (e atualizações) para tabelas grandes. Um sistema de arquivos distribuído, como o HDFS, é ideal para armazenar arquivos grandes. O HBase, por outro lado, é construído sobre o HDFS e pode realizar pesquisas de registro (e atualizações) para tabelas grandes com facilidade.
Além disso, o Amazon DynamoDB é uma chave/valor e um armazenamento de documentos, ao contrário do Apache HBase, que é uma chave/valor e um armazenamento de documentos. Para obter uma comparação mais completa do Amazon DynamoDB e do Apache HBase como armazenamentos de dados NoSQL, considere o modelo de dados chave/valor do Amazon DynamoDB.

Hbase Vs Mongodb: Qual é o melhor banco de dados?
Com o HBase, é fácil armazenar e consultar grandes quantidades de dados. Este sistema baseado em nuvem é adaptável, durável e possui vários recursos exclusivos que o tornam a escolha ideal para uma ampla gama de negócios. O MongoDB é um excelente banco de dados NoSQL para aplicativos com uso intensivo de memória, mas o Hadoop oferece melhor gerenciamento de espaço.
Hbase x Cassandra
A plataforma Hbase é utilizada para armazenamento de dados em grandes bancos de dados, enquanto a plataforma Cassandra pode ser utilizada para ingestão e armazenamento de dados de grandes quantidades. Em tempo real, é melhor usar o Cassandra para dados interativos e processamento de transações.
(Armazenamento) Cassandra vs Hbase – Qual é a diferença? O Apache Cassandra é considerado uma classe de sistema NoSQL porque foi projetado para criar os repositórios de matriz de dados mais estáveis e escaláveis. Os usuários do Cassandra puderam contribuir com a comunidade usando seu componente de código aberto, o que lhes permitiu discutir todos os problemas e dúvidas. O sistema de gerenciamento de banco de dados do Cassandra é extremamente eficiente. Os desenvolvedores poderão aproveitar os recursos de várias máquinas com vários núcleos. A coluna de Cassandra contém o peso da preferência do usuário em linhas. A infraestrutura Hadoop, que inclui Zookeeper, Hbase master, nós de dados e nós de nome, é usada para executar o Hbase.
Cassandra emprega uma linguagem de consulta específica e CQL modelado após SQL. O protocolo Zookeeper é usado para coletar dados por outros nós. O Cassandra, por outro lado, é mais adequado para ingestão e armazenamento de dados em larga escala do que o Hbase, que é usado para armazenar pequenas informações em grandes bancos de dados.
Por que Cassandra é a melhor solução Nosql para Netflix
No mundo do Cassandra e do HBase, eles são muito diferentes. A arquitetura do HBase destina-se apenas ao gerenciamento de dados, enquanto a arquitetura do Cassandra destina-se ao armazenamento e gerenciamento de dados sem depender de nenhum outro sistema.
O HBase é usado atualmente por várias organizações e é usado internamente por todos. Quando precisamos de uma loja NoSQL, ela pode resolver uma ampla gama de problemas e fornecer uma variedade de soluções exclusivas. As soluções de armazenamento NoSQL da HBase são as melhores do mercado.
Cassandra, além de ser um componente de infraestrutura para o serviço de streaming distribuído globalmente da Netflix, também está disponível no Amazon Web Services.
Apache HbaseName
O HBase é uma loja de código aberto, distribuída e orientada a colunas, modelada após o Bigtable do Google. Assim como o Bigtable aproveita o armazenamento distribuído de dados fornecido pelo Google File System, o HBase fornece recursos semelhantes ao Bigtable sobre Hadoop e HDFS. Os recursos do HBase incluem escalabilidade linear e modular, leituras e gravações consistentes de baixa latência e fragmentação automática e configurável de tabelas.
O Hadoop armazena e processa grandes quantidades de dados usando o sistema de arquivos distribuído e o MapReduce. O HBase, que é um banco de dados distribuído orientado a colunas, é construído sobre o Hadoop. O projeto é de código aberto e escalável horizontalmente. A grande tabela do Google, que é semelhante à do Google, permite acesso aleatório a dados estruturados. O HBase, por outro lado, está localizado no topo do Hadoop File System e fornece acesso de leitura e gravação ao sistema de arquivos. O sistema de arquivos HDFS pode ser usado para armazenar dados, diretamente ou por meio do HBase. HBase, um banco de dados orientado a colunas, é estruturado de forma que as linhas sejam classificadas. Uma tabela pode ter mais de uma família de colunas e cada família de colunas pode ter mais de uma coluna.
Hadoop Vs. Hbase
Conjuntos de dados grandes e esparsos são tratados com mais eficiência pelo Hadoop. Quando os dados são manipulados em tempo real, os recursos de manipulação do HBase são superiores aos de outras plataformas.
Hbase Vs Hive
Hive e HBase são duas tecnologias diferentes que funcionam no Hadoop, sendo o Hive um mecanismo semelhante ao SQL que executa tarefas MapReduce e o HBase sendo um banco de dados de chave/valor NoSQL. O Hive é um mecanismo de consulta robusto que permite consultar em tempo real, enquanto o HBase é um mecanismo de consulta robusto que permite consultar em tempo real.
Apache Hadoop e Apache HBase são duas tecnologias distintas de Big Data que podem servir a vários propósitos, em quase todos os casos. Toda tecnologia, aos olhos dos sistemas de big data, deve ser combinada entre si. Quais são as diferenças entre Hive e HBase? Apache Hadoop MapReduce e HBase podem ser combinados para criar um banco de dados NoSQL. Uma das maiores brechas do HBase é a falta de serviços, o que permite a possibilidade de acesso aleatório. Também é conhecido por escalar horizontalmente usando servidores de região prontos para uso, para ser altamente disponível, consistente e apenas na extremidade inferior do espectro de banco de dados sem latência SQL. O Hadoop é usado de duas maneiras distintas: Hive e HBase. O Hive é um mecanismo semelhante ao SQL que executa tarefas MapReduce, enquanto o HBase é um banco de dados NoSQL com chaves e valores. Ao invés de ter um concorrente, essas duas tecnologias devem colaborar.
Hive ou Hbase para seu próximo projeto de dados?
O Hive existe há muito tempo. Há algumas vantagens em usar o HBase em relação a outros data warehouses no mercado, mas ele ainda está engatinhando. O Hive é uma escolha popular para implantações de data warehouse entre muitas organizações. É uma escolha excelente para situações em que você não precisa de todos os recursos de um banco de dados NoSQL, mas ainda precisa de um repositório NoSQL. As soluções de armazenamento NoSQL da HBase são as melhores do mercado.
Cassandra NosqlName
Cassandra é um poderoso banco de dados NoSQL, perfeito para aplicativos que exigem alta disponibilidade e escalabilidade horizontal. O Cassandra é fácil de usar e oferece um conjunto robusto de recursos que o tornam a escolha ideal para uma ampla variedade de aplicativos.
Apache Cassandra é um projeto da comunidade Apache amplamente disponível que está disponível gratuitamente. O Apache Cassandra permite o armazenamento e o gerenciamento de dados estruturados e não estruturados de alta velocidade em vários servidores comuns. O Cassandra, que funciona em conjunto com o Google Bigtable e o Amazon Dynamo, permite que os usuários gerenciem bancos de dados de qualquer local. Ele oferece um alto nível de disponibilidade e é desprovido de grandes problemas. O Cassandra foi implantado por algumas das maiores empresas de TI. Todos os dias, o Instagram carrega aproximadamente 80 milhões de fotos no banco de dados Cassandra. É composto de Apache Cassandra e MongoDB. Um cluster Cassandra de vários nós é uma maneira muito simples de dimensionar facilmente o Cassandra para atender a um aumento repentino na demanda.
Cassandra é Nosql?
Um banco de dados NoSQL como o Cassandra pode ser distribuído. Os bancos de dados NoSQL são leves, de código aberto, não relacionais e bastante distribuídos em seu design. Eles se distinguem por sua capacidade de escalar horizontalmente, bem como por sua capacidade de definir esquemas de maneira flexível.
Mongodb NosqlName
Os modelos de documento no MongoDB não são relacionais, tornando-os um banco de dados. Ele se distingue dos bancos de dados relacionais tradicionais, como Oracle, MySQL e Microsoft SQL Server, por ser o chamado banco de dados NoSQL (NoSQL = Not-only-SQL).
O MongoDB é um dos bancos de dados NoSQL mais usados e pode armazenar dados no formato JSON. O desempenho, a escalabilidade e a disponibilidade do MongoDB são semelhantes aos de outras linguagens de script/analítica de banco de dados, como SQL, Oracle e Oracle. O objetivo deste capítulo é explicar os conceitos e tipos fundamentais de NoSQL.
Que tipo de Nosql é o Mongodb?
Um banco de dados de documentos é composto de várias chaves vinculadas por uma estrutura de dados complexa. Um documento pode ser aninhado, bem como conter uma variedade de pares chave-valor, pares chave-matriz e assim por diante. O MongoDB, como banco de dados de documentos, é muito semelhante ao Google Docs.
O Mongodb é o melhor Nosql?
O terceiro melhor banco de dados NoSQL é o MongoDB, projetado para servir como um banco de dados de documentos de uso geral. Por ser orientado a documentos, ele pode organizar todas as suas informações em um único local, facilitando o acesso a todas elas em um único tópico.
Qual banco de dados é melhor para você?
No final, não há um vencedor claro entre os dois bancos de dados, cada um com seus pontos fortes e fracos. O banco de dados deve ser adaptado para atender às suas necessidades e preferências específicas.
Como funciona o Mongodb Nosql?
O MongoDB é um banco de dados NoSQL disponível gratuitamente. Como um banco de dados não relacional, ele pode lidar com dados estruturados, semiestruturados e não estruturados e pode lidar com qualquer formato de arquivo. Um modelo de dados orientado a documentos e uma linguagem de consulta não estruturada são usados. O MongoDB, que é extremamente flexível, pode armazenar e combinar vários tipos de dados.
Mongodb: a escolha certa para empresas grandes e pequenas
O MongoDB é uma excelente escolha para aplicativos de missão crítica porque pode ser dimensionado e tem excelente desempenho. Como resultado, Netflix, Uber e Airbnb estão entre as empresas que o utilizam para alimentar seus maiores e mais exigentes aplicativos há anos.
A plataforma MongoDB simplifica o uso para startups e pequenas empresas. Além disso, é adequado para armazenamento em nuvem, permitindo que as empresas aumentem ou diminuam conforme necessário.