
Por que a consistência eventual é essencial para armazenamentos de dados
Publicados: 2022-11-17A consistência eventual é uma propriedade dos armazenamentos de dados em que os dados que foram gravados no armazenamento podem não estar imediatamente disponíveis para leitura. A loja pode eventualmente disponibilizar os dados para leitura, mas não é garantido que isso aconteça. Os sistemas de armazenamento de dados que exibem consistência eventual podem fazê-lo por vários motivos, incluindo a necessidade de melhorar o desempenho ou garantir a disponibilidade diante de partições de rede.
É muito mais difícil obter uma implementação de armazenamento de dados de documento do que um modelo relacional. Além disso, os dados de armazenamento em andamento são muito mais difíceis de converter do que os dados RDBMS. Essa oportunidade está faltando para desenvolvedores e arquitetos que temem ou desconhecem as consequências de seus erros. Eles vão dividir o que as transações atômicas devem consistir em partes lógicas, esquecendo que a replicação e a latência são coisas, bem como arrastando sistemas de terceiros para elas. Em algum momento, todo o sistema será terceirizado e outra pessoa assumirá quando o departamento for eventualmente dissolvido.
Como resultado, os bancos de dados NoSQL frequentemente suportam uma consistência gradual em vez de uma consistência constante. Não há exigência de consistência forte de dados porque eles não suportam transações de banco de dados. É sempre possível obter consistência eventual garantindo que todas as atualizações sejam entregues a todas as réplicas ao mesmo tempo.
O fato de que a consistência eventual se refere ao processo de replicação entre nós primários e secundários, e o fato de que seu aplicativo nem sempre está atualizado com os dados de leitura, torna as leituras primárias o caminho a seguir.
Quando os bancos de dados NoSQL usam o modelo de consistência eventual, eles não fornecem o mesmo nível de consistência de dados que os bancos de dados SQL. Se os dados não forem consistentes, isso os torna inadequados para transações como transações bancárias e em caixas eletrônicos, que exigem integridade imediata.
O que significa consistência eventual em Nosql?
A consistência eventual é uma garantia de que, se nenhuma nova atualização for feita em um dado, eventualmente todos os acessos a esse dado retornarão o último valor atualizado. Isso contrasta com a consistência forte , que exige que cada leitura receba a gravação mais atualizada.
O conceito de comportamento eventualmente consistente ganhou força no final dos anos 1970. A Amazon lançou o DynamoDB há uma década, o que despertou a popularidade do termo. O banco de dados NoSQL foi desenvolvido para alimentar mídias sociais e serviços de streaming. dados não estruturados, como fotos, vídeos e arquivos de áudio, podem ser gerenciados com facilidade. Usando o modelo Volt Active Data, é possível garantir que os dados sejam replicados em vários bancos de dados em tempo real. As plataformas de dados são imediatamente consistentes e evitam gravações e leituras inconsistentes. Como resultado, eles são extremamente capazes de atender aos requisitos de latência do 5G, lidando rapidamente com esse processo.
A consistência pode ser um recurso valioso de um sistema distribuído. Ele garante que os valores sejam armazenados e acessados por vários nós de forma consistente, independentemente de esses nós serem atualizados ao mesmo tempo. É fundamental que os sistemas, como o Domain Name System, sejam capazes de reter uma visão consistente dos dados.
A consistência que vem com a conclusão de um projeto pode ser difícil de alcançar às vezes. Pode ser difícil garantir que todos os nós recebam as mesmas atualizações devido à variedade de métodos disponíveis. O valor da consistência é inegável e os sistemas que a utilizam podem ser mais confiáveis a longo prazo.
O que é consistência eventual em Cassandra?

O Cassandra alcança todos esses recursos com um sistema de armazenamento consistente que pode atender aos requisitos de desempenho, confiabilidade, escalabilidade e disponibilidade na produção. Por fim, consistente significa que todas as atualizações são eventualmente compartilhadas com todas as réplicas.
Consistência é algo que o Cassandra pode alcançar com sua consistência ajustável. O resultado R=w <=N deve ser consistente se N for o número de nós. Para obter consistência, cada coluna e campo de cada coluna são copiados pelo Cassandra. Existe um mecanismo por trás desse estado que permite que ele seja consistente. R + W é um sólido se N for consistentemente sólido. O cliente deve selecionar o nível de consistência apropriado (zero, qualquer, um, quoram ou nenhum). A consistência não ocorrerá imediatamente porque as gravações são armazenadas em buffer no nó para o qual você as envia, apesar do fator de replicação de 1:1.
Cassandra emprega hashing consistente, o que significa que quando um conjunto de chaves é hash usando o mesmo algoritmo e parâmetros de função hash, a função hash sempre produz o mesmo resultado.
Isso é crítico porque permite que você mantenha uma chave em vários depósitos sem se preocupar com a possibilidade de ela colidir com qualquer coisa.
Como resultado, acredita-se que o hashing consistente seja mais eficiente porque permite que o Cassandra armazene mais dados na mesma quantidade de espaço.
Você deve certificar-se de que suas contagens de gravação e leitura sejam consistentes se desejar obter uma consistência forte. A consistência do Cassandra é construída com base na suposição de que todas as leituras do cliente são sempre mantidas atualizadas, buscando automaticamente os dados gravados mais recentes. O hash consistente é usado para garantir que a função de hash sempre produza o mesmo resultado para duas chaves diferentes se elas forem agrupadas usando o mesmo algoritmo e parâmetros de função de hash. É fundamental manter uma chave em vários depósitos porque as colisões não são um problema. O Cassandra tem uma taxa de desempenho mais alta porque pode manter mais dados na mesma quantidade de espaço com hashing consistente.
Qual é o nível de consistência padrão no Cassandra?
Simplesmente chame o QUBEDBUILDER para usar o driver Java. Defina theConsistencyLevel para garantir que o nível de consistência para cada inserção seja definido em insertInto. Ao escrever e ler, um nível de consistência de um é atribuído a todas as operações.
Como garantir consistência de dados com Cassandra
A principal razão para isso é que as chaves não são armazenadas em depósitos até que sejam hash. Cassandra também armazena a chave e o ponteiro para o depósito na mesma linha da tabela. Cassandra compara a linha para a chave e o ponteiro para um valor acima de um valor de chave para determinar qual linha corresponde a qual chave. Se ambos forem verdadeiros, Cassandra pegará o valor do balde no ponteiro. O valor de uma chave é sempre armazenado na mesma linha, independentemente de quantas vezes for solicitado, desde que seja armazenado na mesma linha. Quando uma leitura é repetida várias vezes, os dados permanecem constantes. Se você quiser alterar o nível de consistência da sessão atual, basta usar o comando CONSISTENCY do shell cassandra (CQLSH). Se você quiser ver quanto tempo você está em seu nível de consistência, você pode usar CONSISTÊNCIA; da casca. [email protegido] | Consistência: consistência O nível de consistência atual é um.
O que é consistência de atualização em Nosql

A consistência de atualização no NoSQL é o processo de atualização de dados em vários nós em um banco de dados NoSQL . Esse processo garante que todos os nós no banco de dados tenham os mesmos dados e que os dados sejam consistentes em todos os nós.
O que é consistência de atualização no Nosql?
A consistência das cópias dos mesmos dados dentro do mesmo sistema de banco de dados replicado [1], ao contrário de como os dados mudam, é simplesmente uma questão de escolha. Isso ocorre quando as leituras em um determinado objeto de dados são inconsistentes com a atualização anterior.
O que é consistência de atualização no banco de dados?
O conceito de consistência em sistemas de banco de dados envolve a exigência de que qualquer transação de banco de dados permita apenas a modificação dos dados afetados da maneira permitida. Os dados que foram gravados no banco de dados devem aderir a todas as regras definidas, como restrições, cascatas, acionadores e qualquer combinação deles.

Mongodb de consistência eventual

Consistência eventual é um termo técnico que significa que os dados que você está lendo nem sempre são consistentes; ele irá, no entanto, melhorar com o passar do tempo. A única maneira de fazer isso é ler de secundários usando qualquer um dos readPreferences que podem ler de fontes secundárias.
Como primeiro passo, examinarei alguns exemplos reais de código do MongoDB que violam a Garantia de Consistência Causal . O método de leitura e gravação da maioria será usado na primeira tentativa de resolver isso. Como resultado, veremos relógios lógicos e sessões correlacionadas no Mongo. Estaremos usando o driver Mongo C# para este aplicativo, mas gostaria de deixá-lo sozinho. A maioria dos membros do conjunto de réplicas deve assinar uma leitura majoritária se os dados de uma consulta tiverem sido confirmados. Quando usamos uma leitura majoritária seguida por uma gravação majoritária, pode parecer que podemos resolver nosso problema de “Read Your Write”. Um servidor secundário mantém um instantâneo na memória da gravação principal mais recente.
Configuração Readconcern do Mongodb
Um cliente deve determinar quantos dados deve ser permitido ler para que readConcern seja satisfeito antes de começar a satisfazer readConcern. No MongoDB, é preferível que readConcern seja definido como maxRead.
Consistência eventual x consistência forte
Ele fornece dados atualizados em uma latência menor do que outras tecnologias, mas também requer um alto grau de persistência. Como o banco de dados pode não ter dados atualizados em todos os nós, a consistência eventual pode fornecer baixa latência, mas nem sempre responder a solicitações de leitura com dados obsoletos.
Em geral, a consistência refere-se à capacidade de um banco de dados de processar transações, ao mesmo tempo em que preserva a integridade dos dados. Os sistemas de banco de dados que estão em conformidade com os regulamentos ACID são normalmente lentos, difíceis de dimensionar e proibitivamente caros para manter e operar. Alguns sistemas RDBMS aliviam as garantias ACID. As garantias básicas de um banco de dados NoSQL são conhecidas como seus algoritmos NoSQL. Como resultado, a base pode ser usada para aumentar a disponibilidade e, ao mesmo tempo, permitir o relaxamento de padrões rígidos. Como resultado, os bancos de dados NoSQL exigem uma quantidade significativa de consistência para serem mais estáveis. Quando a consistência eventual do DynamoDB é determinada por uma topologia em anel, ele se torna Cassandra.
Para lidar com resultados consistentes, uma topologia mestre-escravo é usada no Redis. A ScyllaDB é uma empresa de banco de dados de big data em tempo real com sede na Holanda. Além disso, pode ser usado para especificar um nível de consistência para cada operação (leitura ou gravação). Como os dados podem ter mudado em um nó coordenador, mas ainda não foram registrados e armazenados em todas as réplicas necessárias, os clusters ScyllaDB fornecem resultados consistentes.
Um dos aspectos mais importantes da consistência do sistema de computador é sua consistência. Os dados podem ser tratados dessa maneira, independentemente de como são armazenados, pois garantem a consistência. Como resultado, as instituições financeiras, por exemplo, frequentemente adotam sistemas que serão consistentes ao longo do tempo. A maioria das transações será concluída o mais rápido possível como resultado desse processo. Uma transação pode levar até 24 horas para ser processada, embora isso não seja garantido. Esse fenômeno é causado por um padrão geral de sistemas consistentes que eventualmente existirão.
Consistência de dados: como escolher o tipo certo para suas necessidades
Quando se trata de dados, existem dois tipos: fortes e fracos.
Como todos os dados em um nó são consistentes, independentemente de onde residam, eles são sempre os mesmos. Este método é o método mais confiável de consistência de dados, mas pode ser difícil de implementar.
A falta de consistência indica que não há garantia de que todos os nós tenham os mesmos dados ao mesmo tempo. Essa consistência é mais propensa a corrupção, mas também pode ser mais eficiente às vezes.
Consistência eventual Cassandra
A consistência eventual é um modelo de consistência usado em sistemas distribuídos. Em um sistema eventualmente consistente, as operações podem levar algum tempo para se propagar e se tornar visíveis em todos os nós. Uma operação de gravação é considerada bem-sucedida quando é durável no nó em que foi emitida. Uma operação de leitura é considerada bem-sucedida quando retorna a operação de gravação mais recente. A consistência eventual é frequentemente usada em sistemas distribuídos em vários datacenters. Nesses sistemas, não é prático manter uma consistência forte por causa do aumento da latência e do potencial de falhas. A consistência eventual permite que o sistema continue operando mesmo diante de falhas. Cassandra é um banco de dados distribuído que usa consistência eventual. O Cassandra foi projetado para lidar com grandes quantidades de dados com alta disponibilidade. Cassandra é usado por algumas das maiores empresas do mundo, incluindo Facebook, Netflix e Instagram.
É um banco de dados NoSQL de código aberto com uma arquitetura altamente disponível e escalável. A replicação de dados entre clusters é necessária para obter alta disponibilidade no Cassandra. Existem duas estratégias de replicação disponíveis: SimpleStrategy e NetworkTopology. A consistência de como cada linha de dados é representada por réplicas reflete o quão recentes e sincronizadas elas são. O nível de consistência indica quantos nós de réplica devem responder aos dados consistentes mais recentes antes que o coordenador possa enviar os dados de volta ao cliente com sucesso. Dependendo do nível de consistência especificado pelo cliente, podemos definir o nível de consistência para cada consulta de gravação ou o nível de consistência para cada consulta global. Ao escrever, tenha em mente o Nível de Consistência (CL).
Em 5.1, apenas um nó de réplica retorna dados, enquanto em 5.2, 51% dos nós de réplica em todos os datacenters retornam dados. Começamos definindo um nível de consistência desejado (CL) para gravações e leituras do Cassandra. Como resultado, independentemente de quanto tempo leva entre a gravação mais recente e a próxima, você está lendo os dados gravados mais recentemente no cluster. Para garantir a consistência, podemos especificar um nível de consistência de consulta global ou de gravação . Aqui estão vários exemplos de CL na leitura que você pode ver no diagrama abaixo.
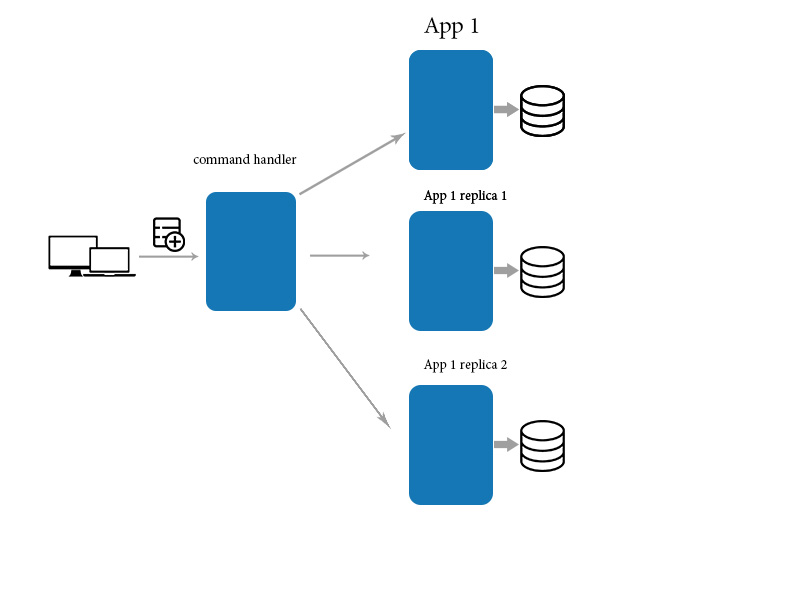
O que é consistência eventual em microsserviços
Na verdade, a consistência eventual é um método para manter a consistência e a disponibilidade dos dados por meio de comunicação assíncrona, além de garantir que erros em um determinado processo sejam resolvidos sem a necessidade de voltar ao estado anterior do processo.
Na maioria dos casos, encontramos problemas com inconsistência de dados em um sistema de software. Baseia-se numa abordagem descentralizada e é inspirada na natureza. Com a computação em nuvem, a computação elástica e o armazenamento se tornando mais populares, e a tecnologia e a orquestração de contêineres se tornando mais populares, uma quantidade significativa de novos aplicativos está sendo criada usando o estilo de arquitetura de microsserviços. Quando as transações atômicas abrangem vários serviços, elas são vistas como uma cadeia de transações locais atômicas simples em cada nível de serviço. Quando uma transação falha nessa cadeia como resultado de uma circunstância específica, ela basicamente aciona uma operação de desfazer. Uma chamada ou transação de compensação também pode falhar. A consistência e a integração de dados são duas das abordagens mais comuns para o gerenciamento de dados, que são Kafka e CDC.
O CDC é adequado para grandes arquiteturas distribuídas porque não é excessivamente orientado para o desempenho. A inflexibilidade do CDC quando se trata de mudanças nos esquemas é uma das desvantagens mais significativas. Isso limita muito a evolução do esquema de banco de dados de serviço.