
Por que os bancos de dados Nosql são melhores para big data
Publicados: 2022-11-19Os bancos de dados Nosql são melhores para big data por vários motivos. Eles são projetados para serem escalonáveis horizontalmente, o que significa que podem lidar com mais dados adicionando mais servidores. Eles também são projetados para serem altamente disponíveis, o que significa que podem continuar funcionando mesmo se alguns servidores falharem. E eles podem lidar com alta taxa de transferência, o que significa que podem lidar com muitas leituras e gravações.
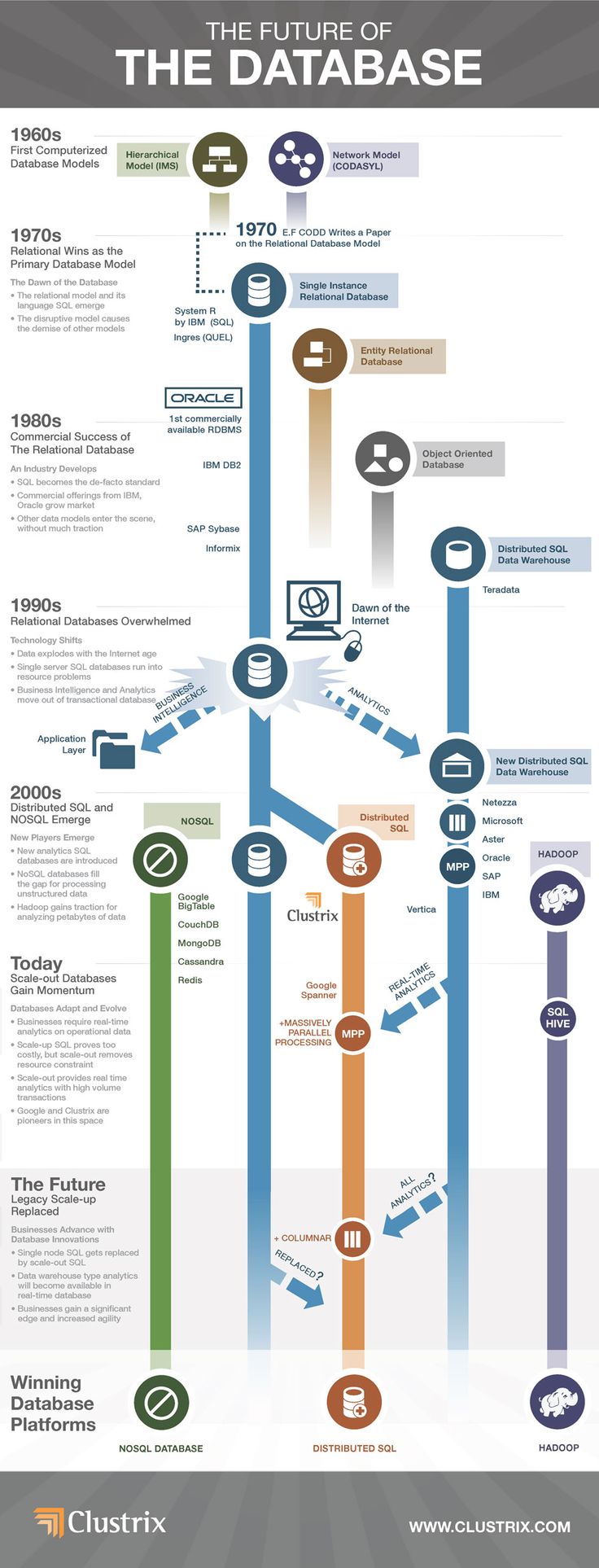
O uso de bancos de dados NoSQL era popular entre empresas de internet como Amazon, Google, LinkedIn e Facebook em resposta às desvantagens do RDBMS. À medida que os requisitos de processamento de dados aumentam, o NoSQL é uma solução adaptável e baseada em nuvem para gerenciar dados não estruturados. De acordo com Esprdo de Oliveira, Diretor de Desenvolvimento de Negócios da FairCom, existem alguns problemas com o NoSQL que um banco de dados tradicional não consegue resolver. Ele é usado para conduzir a tecnologia de banco de dados na nuvem, na Web, em big data e nos grandes usuários. Os bancos de dados NoSQL são um subconjunto de bancos de dados que armazenam dados de várias maneiras. Os tipos mais populares são gráficos, pares chave-valor, colunas e documentos. As empresas que dependem fortemente de dados, como Amazon, eBay e assim por diante, exigiam um banco de dados como NoSQL ou SQL que melhor correspondesse ao modelo de dados em mudança, permitindo-lhes gerenciar suas operações com mais eficiência.
O armazenamento e o processamento de dados em tempo real podem ser realizados por bancos de dados NoSQL, que são muito mais sofisticados do que os bancos de dados relacionais. Devido à crescente velocidade e variedade de dados, o cenário dos bancos de dados é inundado com maior velocidade de dados, uma variedade de dados em expansão e um volume explosivo de dados, todos exigidos pelos aplicativos de Big Data. Bancos de dados NoSQL como HBase, Cassandra e Couchbase são o conceito de prioridades CAP (Consistência-Disponibilidade-Tolerância de Partição) é um conceito de banco de dados NoSQL.
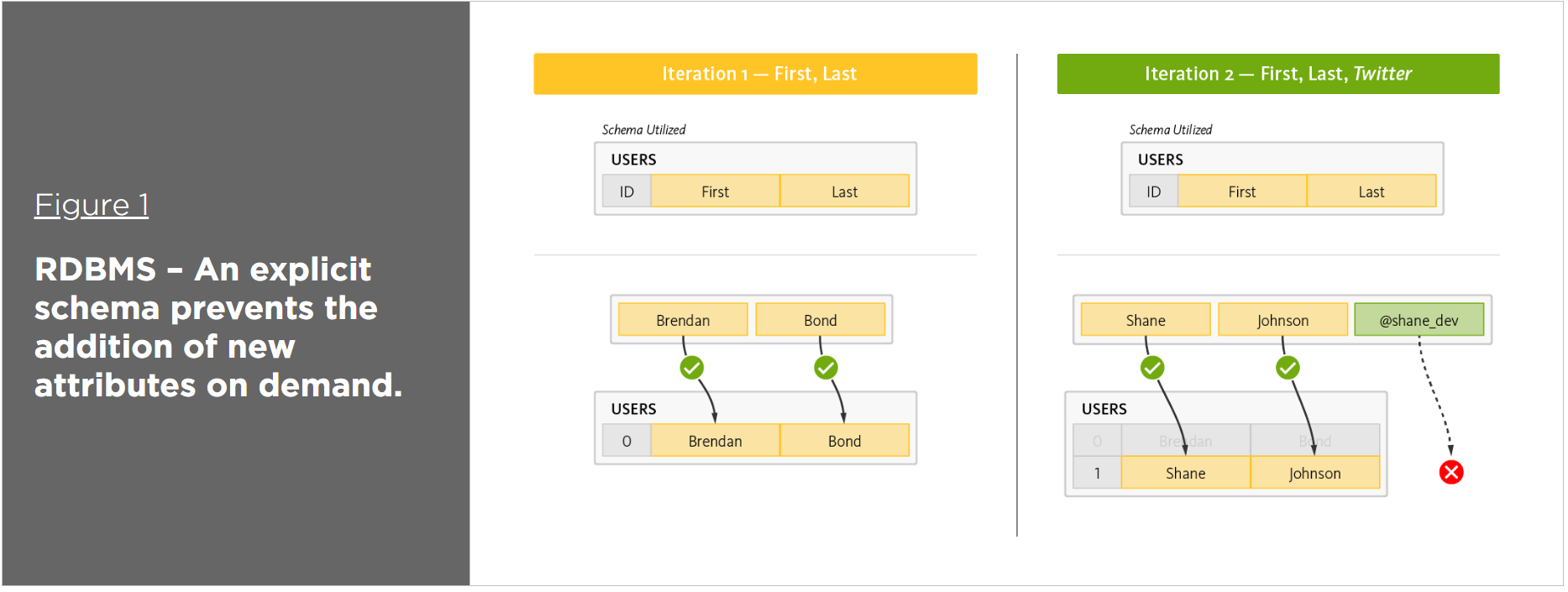
O esquema do banco de dados é fixo em bancos de dados relacionais. Não há consistência nos bancos de dados NoSQL. Não há transações em bancos de dados NoSQL (eles suportam apenas transações simples). Em um banco de dados relacional , as transações (assim como transações complexas com junções) são suportadas.
Há uma razão pela qual os bancos de dados NoSQL cresceram em popularidade nos últimos anos: eles são simples de entender e não requerem modelos de dados complexos como os bancos de dados SQL. Além disso, os bancos de dados NoSQL frequentemente permitem que os desenvolvedores modifiquem diretamente a estrutura de dados.
Os desenvolvedores podem se beneficiar dos bancos de dados NoSQL de várias maneiras, incluindo resultados de consulta mais rápidos, modelos de dados flexíveis, dimensionamento horizontal e um processo de desenvolvimento simplificado. Bancos de dados de documentos, bancos de dados de valores-chave, armazenamentos de colunas largas e bancos de dados de gráficos são apenas alguns exemplos de bancos de dados NoSQL.
O Nosql é bom para grandes volumes de dados?
É fundamental que as soluções de armazenamento de big data sejam capazes de processar e armazenar grandes quantidades de dados para poder processá-los e analisá-los. Um banco de dados NoSQL, também conhecido como banco de dados não relacional, é criado para lidar com uma grande quantidade de dados enquanto é dimensionado horizontalmente.
Conforme demonstrado pelo MongoDB e Apache Cassandra e HBase, os bancos de dados NoSQL experimentaram um crescimento sem precedentes ao longo do tempo. Em comparação com o software de código aberto, o NoSQL é a melhor escolha para empresas que exigem processamento e análise rápidos de grandes quantidades de dados diversos e não estruturados. Esses bancos de dados são altamente responsivos, com escalabilidade e vantagens de disponibilidade em relação aos produtos RDBMS tradicionais. Um banco de dados NoSQL é preferido por organizações que desejam armazenar e analisar grandes quantidades de arquivos e conjuntos de dados estruturados, semiestruturados e não estruturados, principalmente em tempo real. Mais servidores físicos serão necessários à medida que os dados crescem no cluster. Os bancos de dados NoSQL usam uma arquitetura de dimensionamento horizontal que os torna eficientes. Os bancos de dados NoSQL têm um custo por transação menor do que os bancos de dados tradicionais devido à sua natureza de código aberto. NoSQL e RDBMS, bem como seus pontos fortes, podem ser usados juntos para criar um sistema de gerenciamento de dados eficiente.
Qual banco de dados é melhor para dados grandes?
Não há uma resposta definitiva para essa pergunta, pois depende de vários fatores, como as necessidades específicas do usuário, o tipo de dados armazenados e o orçamento. No entanto, alguns bancos de dados amplamente usados para grandes conjuntos de dados incluem Apache Hadoop, Apache Cassandra e MongoDB.
Por que o Nosql é melhor

Existem muitas razões pelas quais o NoSQL é visto como uma escolha melhor para o gerenciamento de dados moderno. Em primeiro lugar, os bancos de dados NoSQL são muito bons para lidar com dados de grande escala devido a seus recursos de dimensionamento horizontal. Eles também podem ser facilmente integrados a soluções de big data. Em segundo lugar, os bancos de dados NoSQL oferecem um modelo de dados muito mais rico do que os bancos de dados relacionais tradicionais , o que os torna mais adequados para lidar com dados complexos. Por fim, os bancos de dados NoSQL geralmente são muito mais fáceis de usar e exigem menos manutenção do que os bancos de dados relacionais.
Os dados são um componente chave de todos os subcampos da ciência de dados. É mais provável que você precise armazenar dados em um sistema de gerenciamento de banco de dados (DBMS). Ao interagir e se comunicar com o DBMS, seu idioma é necessário. SQL (Structured Query Language) é a linguagem usada para interagir com SGBDs. Outro termo que surgiu recentemente no campo dos bancos de dados são os bancos de dados NoSQL. Bancos de dados NoSQL, como bancos de dados não relacionais, não armazenam dados em tabelas ou registros. A estrutura de armazenamento de dados é configurada para atender a requisitos específicos.
Os quatro tipos mais comuns são bancos de dados gráficos, bancos de dados orientados a colunas, bancos de dados orientados a documentos e pares chave-valor. Bancos de dados orientados a documentos, como o MongoDB, são um exemplo de banco de dados Python. Ao usar um banco de dados NoSQL, você poderá criar uma estrutura de dados com mais facilidade. Os bancos de dados SQL, por outro lado, possuem uma estrutura mais rígida e um tipo de dados menor. Se você quiser aprender SQL como iniciante, comece com SQL e depois vá para NoSQL. Existem inúmeras vantagens e desvantagens para cada um desses programas, e você deve considerar seus benefícios e desvantagens com base em seus dados, aplicativo e o que facilita o desenvolvimento. Não há dúvida de que o SQL é superior ao NoSQL ou à maneira como é escrito. Se você ouvir seus dados, tomará a melhor decisão para você.
Sql Vs Nosql para Big Data
O SQL também tem melhor desempenho ao lidar com consultas complexas porque oferece maior velocidade e recuperação. No entanto, se você deseja expandir a estrutura padrão do RDBMS ou criar um esquema flexível, os bancos de dados NoSQL são a melhor escolha.

É fundamental selecionar um banco de dados relacional (SQL) ou um banco de dados não relacional (Nosql) para aproveitar ao máximo seus investimentos em banco de dados. Para tomar uma decisão informada sobre o tipo de banco de dados necessário para um projeto, você deve primeiro entender as diferenças entre os dois. Elasticidade é um requisito crítico para bancos de dados NoSQL, e é por isso que eles são mais adequados para big data. Dependendo do requisito, eles podem ser pares chave-valor, baseados em documentos, bancos de dados gráficos ou armazenamentos de colunas largas. Como resultado, cada documento pode ter uma estrutura distinta, possibilitando a criação de documentos sem uma estrutura definida. Em termos de NoSQL, existem inúmeras questões, principalmente no contexto de big data e análise de dados. Alguns bancos de dados NoSQL exigem experiência interna para serem configurados e gerenciados, enquanto outros dependem fortemente do suporte da comunidade.
A regra geral é que o NoSQL não é mais rápido que o SQL, assim como é mais rápido para executar operações de leitura ou gravação em uma única entidade de dados. Como os bancos de dados NoSQL permitem grandes quantidades de dados, eles são ideais para Google, Yahoo e Amazon. Os bancos de dados relacionais existentes não conseguiam atender à crescente demanda por processamento de dados. Um banco de dados NoSQL tem potencial para crescer e se tornar mais poderoso conforme necessário. Esse tipo de aplicativo é ideal para aplicativos sem definições de esquema específicas, como sistemas de gerenciamento de conteúdo, aplicativos de big data e análises em tempo real.
O Nosql é bom para grandes conjuntos de dados?
É sua responsabilidade converter dados não estruturados e semiestruturados em um formato que possa ser usado por ferramentas analíticas. Esses requisitos distintos tornaram os bancos de dados NoSQL (não relacionais), como o MongoDB, uma escolha poderosa para armazenar grandes quantidades de dados.
Sql é bom para Big Data?
Os mecanismos SQL-on-Hadoop baseados em Hadoop podem ser usados para lidar com grandes bancos de dados. O mito de que big data é muito grande para sistemas SQL agora é refutado e não é verdade. Na verdade, é um mito. O SQL é uma excelente estrutura para a construção de sistemas de big data.
Como os bancos de dados Big Data e Nosql são idênticos?
Não há uma resposta única para essa pergunta, pois os dois termos podem significar coisas diferentes para pessoas diferentes. Em geral, no entanto, os bancos de dados big data e nosql são frequentemente usados de forma intercambiável para se referir a armazenamentos de dados projetados para armazenar grandes quantidades de dados e que não são baseados no modelo tradicional de banco de dados relacional.
O banco de dados NoSQL , também conhecido como código aberto, é baseado em um banco de dados de código aberto. As categorias de bancos de dados NoSQL são determinadas pelo modelo de dados do banco de dados. Cada um dos modelos de dados é composto por um armazenamento de valor-chave, um documento, uma coluna – entrada e um modelo de dados de gráfico. Um banco de dados móvel pode ser acessado em uma variedade de dispositivos e locais. Há também uma tendência a multitarefa em geral. A flexibilidade dos bancos de dados NoSQL, bem como a falta de um esquema fixo, permite que eles sejam mais flexíveis do que os bancos de dados tradicionais quando se trata de abordar a variedade de características de dados pelas quais o big data é conhecido. Devido às propriedades ACID dos bancos de dados, eles não estão altamente disponíveis devido à falta de conclusão total ou completa da transação.
Como o NoSQL é de código aberto, isso significa que é economicamente viável. Devido a todas essas vantagens e ao crescimento da indústria, haverá um aumento no número de pessoas que podem trabalhar em bancos de dados NoSQL. Craigslist é um site de classificados e anúncios de emprego que atende 570 cidades em 50 países ao redor do mundo. Coursera6, uma plataforma educacional online fundada em 2001, oferece oportunidades educacionais para universidades de todo o mundo. Ele cresceu para 10 milhões de alunos na última década, com o uso de NoSQL, bancos de dados Cassandra e um banco de dados tradicional.
Bancos de dados Nosql: por que eles estão ganhando popularidade
As características de um banco de dados NoSQL são as seguintes: Seu design permite lidar com grandes quantidades de dados. Eles são conhecidos como “escamas”. Os dados podem ser processados de várias maneiras usando-os. A quantidade de dados nesses bancos de dados é maior do que nos bancos de dados tradicionais.
Análise de Dados Nosql
É fácil entender por que NoSQL significa “Not Only SQL”. Nesse caso, os dados não são divididos em várias tabelas porque permite que todo o conjunto de dados esteja contido em uma única estrutura. Ao trabalhar com grandes quantidades de dados, o desempenho da consulta em um banco de dados NoSQL não será um problema.
Nosql Vs Sql: Qual é o melhor banco de dados para Big Data?
A análise de big data requer bancos de dados NoSQL porque eles oferecem benefícios superiores. Os bancos de dados SQL, por outro lado, têm sido usados para análise de dados há muito tempo. Como a maioria das ferramentas de BI, como o Looker, não oferece suporte à funcionalidade de consulta para bancos de dados NoSQL, essa não é uma opção.
Se seus dados são muito estruturados e a conformidade com ACID é necessária, o SQL é uma ótima opção para você. Embora o NoSQL possa ser benéfico para quem não conhece seus requisitos de dados ou possui dados não estruturados, também pode ser benéfico para quem conhece. Um banco de dados NoSQL não requer esquemas predefinidos como os bancos de dados SQL.
Essa flexibilidade é necessária para o bom funcionamento de conjuntos de dados complexos e para facilitar a tomada de decisões flexível. Além disso, o MongoDB oferece suporte a recursos de consulta poderosos que permitem analisar e recuperar grandes quantidades de dados rapidamente. Podemos realizar análises avançadas de dados rapidamente com nossas conexões R.
Por que o Rdbms não é adequado para big data
Não é possível eliminar a normalização. A fragmentação automática de dados é quase impossível sob quaisquer circunstâncias (pesadelo). Um sistema de alta disponibilidade é difícil de implementar.
Toda e qualquer ferramenta interna de RDBMS (Relational Database Management System) explicará sua importância em Big Data. Por que escalar é tão difícil de fazer? Existem várias razões para isso, mas a principal é que estamos insatisfeitos. Não podemos determinar a complexidade exata da consulta necessária para extrair os resultados desejados do banco de dados. Se os dados forem maiores que o tamanho da memória do nosso sistema, não seremos capazes de lidar com eles. Em big data, uma quantidade significativa de dados deve ser mesclada para gerar um insight. Os dados estão sendo armazenados em vários locais, portanto, as ferramentas RDBMS são ineficientes e incapazes de lidar com essa situação.
A capacidade de ingressar é impossível devido ao sharding. Depois de executar um procedimento de sharding, um único quadro de dados pode ser dividido em vários nós. Um serviço é considerado de “alta disponibilidade” se estiver sempre disponível, e se alguma de suas características não for atendida, seu desempenho será corrigido por conta própria. Há uma variedade de razões pelas quais a alta disponibilidade é extremamente difícil de alcançar, nas seções a seguir.
Por que Rdbmss não pode lidar com Big Data
Big data não é suportado pelo RDBMS tradicional. Os sistemas são lentos e incapazes de lidar com as flutuações nos dados. O Hadoop pode ser usado para armazenar grandes quantidades de dados, mas não foi projetado especificamente para essa finalidade.