
5 moduri de a vă optimiza baza de date NoSQL
Publicat: 2023-01-12Bazele de date NoSQL devin din ce în ce mai populare deoarece sunt considerate mai scalabile și mai flexibile decât bazele de date relaționale tradiționale . Există mai multe modalități de optimizare a unei baze de date NoSQL, care includ: 1. Proiectarea cu atenție a schemei: Acest lucru este important deoarece o schemă bine concepută poate ajuta la îmbunătățirea performanței și poate face datele mai ușor de gestionat. 2. Indexarea datelor: aceasta poate ajuta la îmbunătățirea performanței interogărilor. 3. Utilizarea memoriei cache: Memorarea în cache poate ajuta la îmbunătățirea performanței prin stocarea în memorie a datelor accesate frecvent. 4. Partiționarea datelor: Acest lucru poate ajuta la îmbunătățirea performanței și scalabilității prin distribuirea datelor pe mai multe servere. 5. Monitorizarea performanței: Acest lucru este important pentru a identifica orice blocaje și pentru a lua măsuri corective.
Jay Patel, un arhitect eBay, a publicat recent un articol despre modelarea datelor folosind magazinul de date Cassandra. El explică cum și-au proiectat modelul de date folosind Cassandra, cum au folosit coloanele și familiile de coloane și cum au optimizat rezultatele interogărilor folosind optimizarea interogărilor. Una dintre perspectivele mele preferate din abordarea lor este că poate fi aplicată oricărei baze de date NoSQL. Înainte de a vă putea optimiza modelul de date, trebuie mai întâi să înțelegeți cum va fi accesat. Când începi să observi că interogările tale durează mai mult, realizezi că baza de date relațională se confruntă cu probleme de performanță. Când datele sunt normalizate, este mai puțin probabil să aibă ca rezultat îmbinări inutile sau n+1 interogări. Chiar dacă denormalizarea este posibilă cu depozitele de date NoSQL, există costuri asociate cu aceasta.
Ce este optimizarea interogărilor în Nosql?
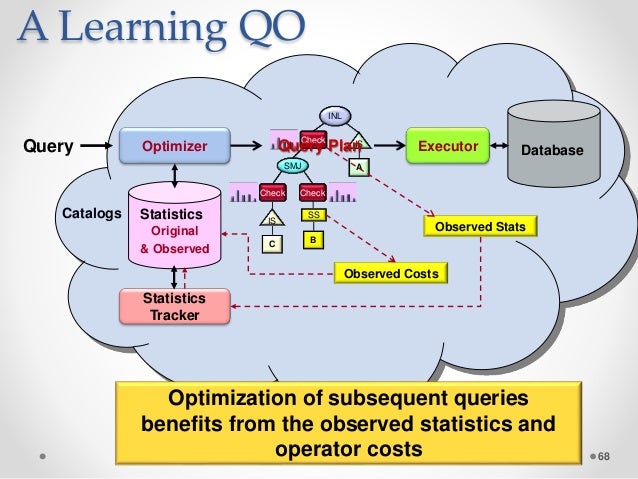
Scopul optimizării interogărilor este de a găsi cel mai eficient plan. La măsurarea eficienței, se utilizează latența și debitul. O optimizare bazată pe costuri costă la fel ca și costul memoriei, al procesorului și al spațiului pe disc. În lumea NoSQL, majoritatea bazelor de date oferă acum suport pentru limbajul de interogare asemănător SQL.
O bază de date MongoDB este o bază de date NoSQL cunoscută și ca bază de date de documente. Această bază de date a fost concepută în așa fel încât să fie mai ușor de dezvoltat decât alte baze de date relaționale. Folosind explic() putem vedea cum funcționează interogarea noastră. Puteți utiliza Explain pentru a crea un document care include planuri de interogare, etape de interogare și multe altele. Ca rezultat al acestui articol, putem înțelege modul în care indexul poate modifica etapele de scanare ale unei anumite colecții. Scopul acestui articol este de a trece peste elementele fundamentale ale optimizării. Detaliile detaliate ale optimizării etapei de agregare vor fi tratate în articolele următoare. Oamenii de culoare excelează în domeniul tehnologiei. Această colecție de resurse evidențiază câteva dintre lucrurile pe care ar trebui să le știm.
Ce face ca Nosql să fie rapid?
Bazele de date Nosql sunt concepute pentru a fi rapide și scalabile. Ei folosesc o varietate de tehnici pentru a realiza acest lucru, cum ar fi scalarea orizontală, fragmentarea și denormalizarea.
Marea majoritate a sistemelor noSQL sunt pur și simplu stocări persistente de chei sau valori (cum ar fi Project Voldemort). Dacă interogările dvs. sunt de tipul care necesită să căutați o anumită valoare cheie, un sistem care poate face acest lucru la fel de repede cum ar trebui un RDBMS. Bazele de date de documente (cum ar fi CouchDB) sunt, de asemenea, sisteme nosql populare. Denormalizarea este utilizată intens în aceste baze de date pentru a structura structura datelor. De fapt, cred că performanța unei aplicații poate fi măsurată prin numărul de piese de care are nevoie pentru a îndeplini o singură cerință. Când se utilizează NoSQL, performanța unei baze de date NoSQL precum djondb poate fi de zece ori mai rapidă dacă aveți nevoie doar de o simplă inserare. Dezvoltatorul va putea lucra mai eficient, deoarece NoSQL le permite să consume mai puține date.
Scopul principal al bazelor de date NoSQL (fără limite) este menținerea unui nivel ridicat de scalabilitate. Trebuie să luați în considerare ce tipuri de interogări efectuați, ce coloane utilizați în tabel și ce implementare a serverului dvs. utilizați. Dacă introduceți mai multe noduri la 1000000rpm stabil 2 ms și utilizați mai puțin cod, veți obține un nod mai rapid, cu o rată și performanță stabilă mai mare.
Ce face Nosql mai rapid decât Sql?
Această metodă implică colectarea, consolidarea și împărțirea diferitelor entități de date. Ca rezultat, o bază de date NoSQL efectuează operațiuni de citire și scriere mai rapid decât o bază de date SQL.
De ce bazele de date Nosql preiau controlul
Pe lângă o varietate de factori, bazele de date NoSQL devin din ce în ce mai populare. Sunt simplu de utilizat, capabile să gestioneze cantități mari de date și pot fi adaptate pentru a îndeplini cerințele specifice ale aplicației dumneavoastră. Au multe avantaje pe lângă faptul că sunt flexibile și personalizabile, ceea ce este imposibil de găsit în alte tipuri de baze de date.
Reglarea performanței Nosql

Reglarea performanței Nosql se referă la a vă asigura că baza de date nosql rulează cât mai eficient posibil. Există câteva domenii cheie asupra cărora să vă concentrați atunci când vă reglați baza de date nosql: 1. Asigurați-vă că baza de date este indexată corect. 2. Asigurați-vă că interogările dvs. sunt optimizate. 3. Asigurați-vă că datele dvs. sunt normalizate corespunzător. 4. Asigurați-vă că baza de date este configurată corect. Concentrându-vă pe aceste domenii cheie, vă puteți asigura că baza de date nosql rulează la performanță maximă.
Când Mango este la o încărcare mare, scriptul MangoNoSql efectuează scrieri în fundal în fundal. Funcția Batch Write Behind vă permite să scrieți în culise. Fiecare sarcină va fi executată în paralel cu celelalte, aducând în atenție valorile punctului dintr-un pool. Dacă ați observat evenimente de pierdere a datelor NoSQL în sistemul dvs., este o idee bună să vă schimbați setările de performanță. Când apăsați butonul Backup acum, va fi creată o coadă de joburi pentru a face backup la sistem acum. Toate valorile de puncte care sunt gata pentru a fi scrise într-o listă de memorie ca parte a modulelor NoSQL sunt stocate în mango. După aceea, selectează până la „Scrie în loturi în spatele inserărilor per sarcină” din listă și începe un fir pentru a insera inserările.
Avantajele și dezavantajele lui Nosql
Când dezvoltați baze de date NoSQL, este esențial să le mențineți flexibile și rapide. Are mai puțină suprasarcină, deoarece are mai puține constrângeri decât SQL. Stocarea NoSQL superficială este flexibilă, permițându-i să fie distribuită într-o varietate de obiecte (documente sau perechi cheie-valoare). O bază de date NoSQL este considerată pe scară largă ca având un nivel scăzut de dificultate în ceea ce privește dezvoltarea, funcționalitatea și performanța. Este simplu de învățat și este folosit de persoanele care preferă să stocheze date care nu sunt conforme cu modelele tradiționale de baze de date.
Optimizarea performanței Mongodb
MongoDB este un puternic sistem de baze de date open-source orientat spre documente. Are o funcție de căutare bazată pe index care face recuperarea datelor rapidă și ușoară. Cu toate acestea, ca orice alt sistem de baze de date, performanța MongoDB poate fi optimizată pentru a se asigura că funcționează fără probleme și eficient. Există câteva lucruri de bază care pot fi făcute pentru a optimiza performanța MongoDB. În primul rând, este important să vă asigurați că sunt aplicați indicii corecti. Acest lucru va asigura că datele pot fi recuperate rapid și ușor. În al doilea rând, este important să păstrați baza de date bine organizată. Acest lucru va ajuta la menținerea dimensiunii datelor reduse și va facilita interogarea. În cele din urmă, este important să monitorizați în mod regulat baza de date pentru a vă asigura că funcționează fără probleme. Urmând aceste sfaturi simple, este posibil ca MongoDB să funcționeze fără probleme și eficient.

Guy Harrison explică cum să utilizați noua agregare de ferestre și conductă de agregare în MongoDB 5.0 în această postare de blog. Data Lake a fost creat ca urmare a exploziei de interes pentru Big Data și Hadoop. A fost dezvoltat Data Lake, o alternativă modernă și mai eficientă la Enterprise Data Warehouse (EDW). Blogul de săptămâna aceasta se concentrează pe indexurile din arborele MongoDB B și despre cum să creați indecși concatenați pentru a optimiza căutările cu mai multe chei. În plus, atunci când luăm în considerare – sau folosim – indici, luăm în considerare unele compromisuri.
Care este îmbunătățirea performanței în Mongodb?
Dacă vă cunoașteți modelele de interogare MongoDB, vă puteți îmbunătăți performanța MongoDB prin: stocarea rezultatelor subinterogărilor frecvente pentru a reduce sarcina de citire; și detectarea modelelor de interogare MongoDB. Asigurați-vă că aveți indici pentru fiecare câmp pe care îl interogați în mod regulat. Dacă observați interogări lente, puteți utiliza jurnalele pentru a le identifica.
Are Mongodb nevoie de o mulțime de ram?
MongoDB necesită 1 GB de RAM pentru a rula pe un singur activ. Dacă sistemul trebuie să înceapă să schimbe memoria pe disc, va avea un impact grav asupra performanței și ar trebui evitat.
Mongodb are Optimizator de interogări?
Când un index este disponibil în MongoDB, optimizatorul de interogări determină care plan de interogare este cel mai eficient și îl memorează în cache. Numărul de „unități de lucru” (lucrări) efectuate de planul de execuție a interogării este utilizat pentru a determina cel mai eficient plan de interogare atunci când planificatorul de interogări examinează planurile candidate.
Instrumentul de optimizare a interogărilor Mongodb
Mongodb oferă un instrument de optimizare a interogărilor care permite utilizatorilor să îmbunătățească performanța interogărilor lor. Acest instrument oferă o modalitate de a vizualiza planul de execuție a interogării și de a optimiza interogarea pe baza rezultatelor. Instrumentul permite, de asemenea, utilizatorilor să vizualizeze planul de execuție a interogărilor într-o varietate de formate, inclusiv JSON, BSON și CSV.
MongoDB oferă statistici de execuție a interogărilor ca parte a unui sistem de inspecție. Aceste informații pot fi folosite de un dezvoltator pentru a optimiza o interogare. Fila Explicați plan, de exemplu, permite utilizatorilor să ilustreze grafic statisticile planului. În plus față de queryPlanner, executionStats și allExecutionPlans, modurile de verbozitate pot fi folosite pentru a explica. Indexurile unice, parțiale, rare (nu indexați documentele fără câmpul de index), ascunse (nu vedeți rezultatele planificatorului de interogări) și indecșii cu mai multe chei sunt toate acceptate de MongoDB. În loc să folosiți chei de prefixe de index sau ordine de sortare variate, pentru indexări este folosit un index compus. MongoDB optimizează performanța interogărilor utilizând doi indecși sau prefixe separate atunci când conectează doi indici sau prefixele acestora.
Conducta lui Mongod conține o etapă care se potrivește pe un câmp care nu este indexat. Este o soluție simplă de a rescrie etapa de potrivire pentru a utiliza un câmp deja existent și indexat. Optimizatorul caută unități de lucru care trebuie efectuate la realizarea fiecărui plan candidat. Când rulați aplicații cu citire grea, dimensiunea seturilor de replică ar trebui să fie mărită și efectuată sharding. Starea și durata replicării trebuie monitorizate. Adevărat: actualizați toate documentele care se potrivesc cât mai eficient posibil atunci când utilizați multi. Examinați valorile de blocare într-o anumită ordine.
Un timp lung de blocare poate indica faptul că structura interogării sau arhitectura sistemului nu funcționează corect. Loturile îmbunătățesc eficiența resurselor. Evenimentele din Kafka, de exemplu, pot fi consumate mai degrabă în loturi decât în bucăți. Este imposibil să indexați o interogare pe o colecție fragmentată dacă indexul nu conține cheia colecției. Folosind $planCacheStats, puteți obține o mai bună înțelegere a informațiilor din cache în etapa de agregare. De asemenea, înseamnă că memoria cache a planului va avea doar o limită de dimensiune de 0,5 GB, care este aceeași limită de dimensiune ca și versiunea anterioară.
Magazine de date Nosql
În loc să stocheze date în tabele, bazele de date NoSQL stochează date în documente. Drept urmare, le etichetăm ca „nu numai SQL” și pot fi astfel clasificate ca modele de date flexibile prin utilizarea unei varietăți de metode diferite. Bazele de date NoSQL sunt împărțite în patru tipuri: baze de date pure de documente, depozite cheie-valoare, baze de date cu coloane largi și baze de date grafice.
Magazinul de date Redis este un magazin de perechi cheie-valoare în memorie open source dezvoltat de IBM. Poate fi folosit pentru a stoca datele de sesiune pentru un acces mai rapid, în plus față de memorarea în cache, coadă și coadă și este mai puțin costisitor decât bazele de date tradiționale . O bază de date NoSQL este frecvent utilizată ca o mărire, mai degrabă decât un înlocuitor pentru o bază de date relațională. Un tip de persistență care stă la baza are un set diferit de caracteristici decât unul care este stocat într-o bază de date relațională. PyMongo, care este construit folosind codul Python, vă permite să interacționați cu una sau mai multe instanțe MongoDB folosind o interfață comună. ORM-ul Python construit în jurul PyMongoEngine este conceput special pentru MongoDB. Scopul bazelor de date Graph este de a oferi o imagine de ansamblu cuprinzătoare a depozitelor de date NoSQL și de a le compara cu alte tipuri de depozite de date. Următoarea este o scurtă descriere a NoSQL și a utilizărilor sale, precum și o descriere a Teoremei de consistență, disponibilitate și toleranță la partiții (CAP). datele de sesiune pot fi stocate în memorie mai repede decât pot fi stocate într-o bază de date tradițională cu stocare persistentă.
Bazele de date NoSQL beneficiază de următoarele caracteristici: scalare ușoară, disponibilitate ridicată și latență scăzută a accesului la date. Aplicațiile de baze de date sunt concepute pentru a procesa mai multe tipuri de date decât bazele de date tradiționale. Face stocarea datelor mai simplă cu un model simplificat, permițând o procesare mai rapidă și mai eficientă. În plus, ele sunt adecvate pentru analiza datelor la scară largă. Bazele de date NoSQL au o serie de avantaje față de bazele de date convenționale . Avantajele de a le avea sunt că se pot scala, oferă niveluri ridicate de disponibilitate și niveluri scăzute de latență pentru accesul la date.
De ce bazele de date Nosql preiau controlul
Există numeroase avantaje în utilizarea bazelor de date NoSQL față de bazele de date relaționale tradiționale și acestea devin din ce în ce mai populare. Designul ObjectStore, care permite o utilizare mai eficientă a tehnicilor de programare orientată pe obiecte, este unul dintre motivele principale pentru aceasta. Bazele de date NoSQL, pe lângă scalabilitatea lor, oferă și o varietate de alte avantaje. Datele pot fi gestionate cu ușurință deoarece sunt mari și pot fi tratate într-o perioadă scurtă de timp. Pentru orice companie care caută o bază de date de documente fiabilă și scalabilă , MongoDB este o alegere excelentă. În plus, este gratuit de utilizat și este o alegere populară pentru companiile de toate dimensiunile.
Indexul textului Mongodb
Indecșii de text MongoDB acceptă procesarea textului specific limbii, inclusiv tokenizarea, stemming și cuvintele stop specifice limbii. Ele pot fi utilizate cu orice câmp care conține text bazat pe limbă.
Crearea indexurilor de text în MongoDB este la fel de simplă ca și utilizarea metodei createIndex(). Funcția principală a unui index de text este de a identifica orice element dintr-un șir sau o matrice de elemente dintr-un text. Indecșii compuși conțin atât chei de index crescătoare, cât și descrescătoare, în plus față de cheia de index text. În acest caz, să căutăm în colecția de postări ale studenților creând un index de text în câmpul titlu. MongoDB însumează rezultatele fiecărui câmp index din document înmulțind ponderea acestuia cu numărul total de potriviri. Greutatea implicită a unui câmp index este una, așa că o puteți modifica folosind metoda createIndex(). Puteți crea mai mulți indexuri de text folosind specificatorul wildcard ($**).