
Bigtable Google: cel mai utilizat magazin de date orientat pe coloane
Publicat: 2022-12-19Bigtable este un magazin de date orientat pe coloane creat de Google. Este conceput pentru a gestiona cantități mari de date cu un grad ridicat de flexibilitate. Bigtable a fost folosit de Google de peste un deceniu și este baza pentru multe dintre serviciile sale, inclusiv Gmail, Google Maps și YouTube. Deși Bigtable nu este primul magazin de date orientat pe coloane, este cu siguranță cel mai utilizat și cunoscut.
În acest articol, vom examina modelul tridimensional de stocare NoSQL dezvoltat de Bigtable. Pentru a verifica dacă este structurat corect, ne vom uita mai întâi la modul în care este implementat în termeni teoretici și apoi vom folosi clientul Node.js pentru a face acest lucru. Modelul de stocare din Bigtable diferă de modul în care l-ați putea găsi într-o bază de date similară. Mai multe celule dintr-o combinație de rând/coloană pot fi ordonate după un marcaj temporal per celulă. În loc să salveze celulele într-o ordine arbitrară, fiecare celulă are valoarea și o marca temporală pentru a se asigura că celulele sunt salvate într-o ordine ordonată. Pentru acest exemplu, vom folosi Node.js și JavaScript simplu pentru a construi Google Cloud Bigtable. În acest articol, vom analiza cum să creați o nouă instanță Bigtable folosind codul.
Începem prin a crea un mediu curat, citim și scriem pe el, apoi îl dărâmăm. Când rulați codul utilizând clientul Node.js Bigtable, clientul Node.js Bigtable poate cauza o eroare Permission Denied și poate genera un link pentru a activa API-ul Cloud Bigtable Admin. De asemenea, ar trebui să creați un cont de serviciu separat în proiectul dvs. GCP pentru a gestiona rolul de administrator Bigtable. Pentru a crea un tabel Bigtable, trebuie mai întâi să construim o instanță a bazei de date și un cluster de tabele. Pur și simplu definiți un ID de tabel și o familie de coloane în clientul Node.js pentru a face acest lucru și sunteți gata. Rândurile simple pot fi create utilizând Bigtable într-o bază de date. Singura modalitate de a interoga datele este să utilizați cheia de rând pentru a interoga un anumit rând sau un grup de rânduri.
Deși timpii de asimilare nu au nicio influență asupra ordinii în care sunt stocate versiunile, ei au un efect asupra modului în care sunt stocate. Nu este necesar să furnizați întreaga cheie de rând; este suficient doar un prefix. Când trebuie să interogați mai multe rânduri din Bigtable, vă sfătuiesc întotdeauna să utilizați streaming. Când utilizați streaming, Bigtable nu trebuie să memoreze datele de pe server înainte de a trimite rânduri, ceea ce duce la o performanță mai rapidă. Filtrele pot fi folosite pentru a limita versiunile de celule, returnând doar acele coloane cu nume de familie specifice sau coloane cu criterii de calificare specifice. Acest lucru este util mai ales dacă aveți multe versiuni de păstrat, dar numai cea mai recentă este necesară pentru anumite scopuri. Filtrele sunt folosite în primul rând pentru a reduce cantitatea de date interogate și trimise pentru a îmbunătăți performanța interogărilor.
Cu alte cuvinte, Cloud Bigtable este o bază de date NoSQL concepută pentru sarcini de lucru de analiză și operațiuni. Acest sistem de baze de date este un hibrid multiplatform care folosește Hadoop mai degrabă decât HBase, care folosește o bază de date coloană. Un cloud bigtable poate fi folosit pentru a alimenta aplicații cu un randament ridicat și scalabilitate, cu o capacitate mai mică de 10 MB.
Apache Cassandra, ScyllaDB, Apache HBase, Google BigTable și Microsoft Azure CosmosDB sunt exemple de magazine cu coloane largi.
Tabelele nu sunt la fel cu bazele de date relaționale în ceea ce privește stocarea cheie/valoare. Tranzacțiile pot fi efectuate o singură dată, iar alinările nu sunt acceptate.
Google Bigtable este o bază de date Nosql?
Google Bigtable este o bază de date NoSQL concepută pentru stocarea și gestionarea unor cantități mari de date. Bigtable este o bază de date orientată pe coloane, ceea ce înseamnă că datele sunt organizate în coloane în loc de rânduri. Acest lucru îl face foarte potrivit pentru stocarea datelor care se schimbă constant, cum ar fi jurnalele web sau datele rețelelor sociale. Bigtable este, de asemenea, foarte scalabil, ceea ce înseamnă că poate gestiona cu ușurință cantități mari de date.
Această bază de date NoSQL poate stoca o gamă largă de tipuri de date și este extrem de stabilă. De asemenea, se ocupă atât de fragmentare, cât și de replicare, asigurându-se că baza de date este foarte disponibilă și de încredere. Multe aplicații Google îl folosesc, inclusiv Google Analytics, indexarea web, MapReduce și Google Maps, Google Books, My Search History, Google Earth, Blogger.com, Google Code Hosting și Google pentru aplicații care necesită o bază de date capabilă să gestioneze un mare numărul de elemente de date, Datastore este o alegere excelentă.
În ce ordine sunt stocate datele în Bigtable?
Nu există o ordine specifică în care datele sunt stocate în bigtable. Datele sunt stocate într-o ordine aleatorie, ceea ce face dificilă accesarea anumitor date.
Bigtable Google: nu doar pentru stocarea datelor
Datele nu pot fi plasate într-o anumită ordine în cadrul igtable. Deoarece Bigtable este o bază de date orientată pe rând, toate datele dintr-un rând sunt organizate în coloane, urmate de o coloană. Deoarece datele sunt stocate în ordine cronologică inversă, este simplu și rapid să solicitați cea mai recentă valoare, dar este dificil și consumatoare de timp să solicitați cea mai veche.
Datele dvs. sunt păstrate pe Colossus, sistemul de fișiere intern al Google, de lungă durată, care este găzduit în centrele de date Google, ca urmare a utilizării Colossus de către Bigtable. Bigtable este gratuit de utilizat și nu trebuie să utilizați un cluster HDFS sau orice alt sistem de fișiere.
O interogare către o sursă de date externă poate fi efectuată fără a crea un tabel permanent cu comanda combine: Un fișier de definire a tabelului cu o interogare. Există o definiție de schemă în linie, precum și o interogare. Un fișier de definire a schemei JSON cu o interogare.
Bigtable vs Datastore
Există câteva diferențe cheie între Bigtable și Datastore. În primul rând, Bigtable este un depozit de date orientat pe coloane, în timp ce Datastore este orientat pe rând. Aceasta înseamnă că în Bigtable, datele sunt organizate în coloane, în timp ce în Datastore sunt organizate în rânduri. În al doilea rând, Bigtable nu are un concept de tranzacții, în timp ce Datastore are. Aceasta înseamnă că în Bigtable, nu puteți anula modificările la o stare anterioară, în timp ce în Datastore puteți. În cele din urmă, Bigtable este proiectat pentru un randament ridicat și o latență scăzută, în timp ce Datastore este proiectat pentru disponibilitate și scalabilitate ridicate.
Ce magazin de date în cloud poate fi folosit pentru a construi baze de date în cloud Google? Deoarece Bigtable acceptă sarcini mari de lucru cu sarcini complexe de back-end, este destinat organizațiilor și întreprinderilor mai mari. Spre deosebire de SQL, care utilizează limbajul de interogare mai restrictiv GQL, depozitele de date efectuează tranzacții ACID pe subseturi de date cunoscute sub numele de grupuri de entități (deși limbajul de interogare GQL este mult mai deschis). Google Cloud Datastore și Google Cloud Bigtable sunt două servicii distincte care au o serie de caracteristici distincte. În plus, informațiile din imaginea de mai jos vă pot ajuta să selectați furnizorul de servicii potrivit pentru dvs. Răspunsurile de mai sus, precum și ceea ce este discutat în manualul Coursea Google Cloud Platform Big Data și Machine Learning Fundamentals, vor servi drept ghid pentru acest articol.
Care este diferența dintre Bigtable și Datastore?
Care este diferența dintre depozitul de date și baza de date? Bigtable și datastore sunt ambele concepute pentru procesarea datelor de mare volum și, respectiv, analiză, în timp ce datastore-ul este conceput pentru date tranzacționale de mare valoare. Magazinul de date este cunoscut și ca baza de date NoSQL deoarece nu aderă la standardul tradițional SQL, permițându-i să rețină datele într-un mod mai flexibil și mai scalabil. Ce fel de depozit de date este Google Bigtable? Modelul de stocare Bigtable stochează date în tabele scalabile masiv, care sunt sortate după hărți de cheie și valori. Un tabel este format din rânduri, fiecare dintre acestea descriind o singură entitate, și coloane, fiecare cu propria sa valoare. Depozitul de date este depreciat? Deoarece API-ul Cloud Datastore v1beta3 a fost lansat, acesta nu mai este disponibil. Cu toate acestea, produsul Cloud Datastore este complet funcțional și acceptat.
Baza de date Bigtable
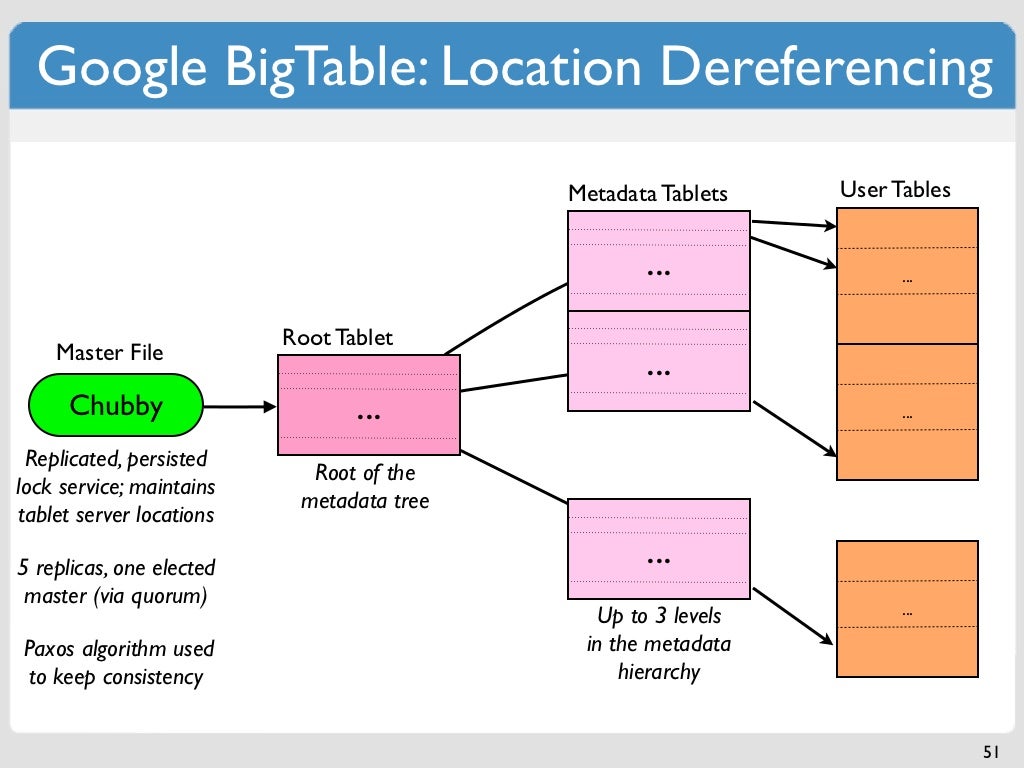
Un Bigtable este un sistem de stocare distribuit pentru gestionarea datelor structurate, care este proiectat să se extindă la o dimensiune foarte mare: petaocteți de date pe mii de servere de mărfuri. Bigtable este o bază de date orientată pe coloane, ceea ce înseamnă că datele sunt stocate mai degrabă pe coloană decât pe rând.
Tabelul este o structură rară, dens populată, cu rânduri și coloane care pot ajunge la miliarde de rânduri. Un bigtable este o alegere excelentă pentru stocarea unor cantități mari de date cu latență scăzută. Deoarece acceptă un debit mare de citire și scriere la latență scăzută, este o sursă de date potrivită pentru operațiunile MapReduce. Când utilizați un tabel Bigtable, acesta este împărțit în blocuri de rânduri învecinate cunoscute sub numele de tablete, pentru a ușura interogările. Într-un sistem de fișiere numit Colossus, pe care îl folosește Google, tabletele sunt stocate în format SSTable. Un nod Bigtable este un subset al fiecărei tablete, care face parte din instanța Bigtable. Adăugarea de noduri la un cluster poate crește numărul de solicitări simultane pe care le poate gestiona.

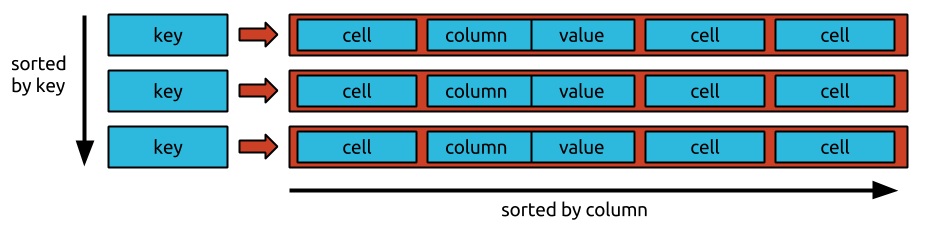
Un rând conține un set de intrări de cheie sau valoare, care sunt o combinație a familiei de coloane, marcaj de timp al coloanei și cheie. Bigtable tratează toate datele în același mod: ca șiruri brute de octeți. Deoarece Bigtable stochează mutațiile secvenţial și le compactează în mod regulat, numărul de mutaţii care pot fi stocate la un moment dat necesită mai mult spațiu de stocare. Bigtable vă comprimă datele utilizând un algoritm sofisticat care este automatizat. Deoarece ștergerile sunt de fapt noi tipuri de mutații, necesită mai mult spațiu de stocare pe termen scurt. Metodele de stocare proprietare Google îi permit să obțină o durabilitate a datelor care o depășește pe cea obținută prin replicarea standard HDFS în trei căi. Pe lângă gestionarea accesului la tabelele Bigtable, puteți gestiona accesul la alte servicii Google Cloud prin atribuirea de roluri utilizatorilor în secțiunea Identity and Access Management (IAM) a proiectului dvs. Google Cloud. Conform politicii de criptare implicite a Google Cloud, toate datele din cloud sunt criptate în repaus folosind aceleași sisteme de gestionare a cheilor consolidate pe care le folosim pentru datele noastre criptate. Folosind o copie de rezervă, puteți salva o copie a schemei și a datelor unui tabel, apoi puteți restaura acea copie a datelor într-un tabel nou în viitor.
Bigtable Vs Cassandra
Cassandra și Bigtable folosesc metode diferite pentru a determina ce nod de procesare ar trebui să efectueze operațiuni de citire și scriere. În Cassandra, cheia de partiție este denumită o cheie, în timp ce în Bigtable, cheia de rând este denumită o cheie. Politica de echilibrare a sarcinii pentru Cassandra trebuie revizuită de client ca parte a procesului.
O bază de date distribuită este una care este partajată de mai multe persoane. Această companie încorporează în sistemul său magazine multidimensionale cheie-valoare, permițându-i să proceseze zeci de mii de interogări pe secundă (QPS). Scopul acestui document este de a compara și contrasta cele două sisteme de baze de date. Caracteristicile cheie ale Bigtable includ: A fost creat un sistem de stocare distribuit pentru hârtie de date structurate. Dacă Bigtable stabilește că reechilibrarea intervalului este necesară pentru un set de date, este simplu pentru un nod de procesare să modifice intervalele de date, deoarece stratul de stocare este separat de stratul de procesare. Bigtable poate fi, de asemenea, utilizat pentru a sprijini replicarea asincronă în clustere distribuite geografic de până la patru clustere în topologii. Toleranța la greșeală a Cassandrei este legată de nivelul său de consistență reglabilă.
Prin configurarea unei strategii de topologie de replicare a datelor, puteți defini replicarea geografică. În general, se utilizează setarea aQUORUM (sau LOCAL_QUORUM în unele centre de date). Pentru a fi considerată reușită, setarea nivelului de consistență a unei operațiuni trebuie să fie îndeplinită cu o majoritate a nodurilor replica care să răspundă la nodul coordonator. Folosind configurații pentru centre de date și rack, replicile Cassandrei sunt capabile să reziste la mai mult stres în comparație cu replicile tradiționale. Când se efectuează operațiuni de citire și scriere, topologia determină care noduri sunt necesare pentru a garanta consistența. O instanță Bigtable poate conține un singur cluster sau un grup de până la patru replici mari. Bigtable și Cassandra sunt depozite de date NoSQL care sunt depozite de coloane largi.
Cheia de rând a lui Bigtable este folosită pentru a sorta datele globale dintr-un tabel în funcție de ordine. Nodurile Bigtable echilibrează automat responsabilitatea nodală pentru intervalele cheie, cunoscute și sub numele de tablete, ca parte a funcției Noduri Bigtable. Serviciul Bigtable al unui client nu impune tipurile de date pe coloană pe care le trimite. În Bigtable, fiecărei coloane dintr-un tabel i se atribuie un nume de familie. În ciuda faptului că tabelele au în mod frecvent mai multe familii de coloane (numărul maxim de coloane per tabel este de 100), fiecare tabel necesită cel puțin o familie de coloane. O intersecție a cheilor de rând este alcătuită din două celule (o familie de coloane combinată cu un calificator de coloană). În Cassandra și Bigtable, există o metodă de selectare a nodului de procesare pentru operațiunile de citire și scriere.
În Cassandra, cheia de partiție este identificată, în timp ce în Bigtable, este folosită cheia de rând. O politică de echilibrare a încărcăturii care ține seama de centrele de date, cum ar fi o politică cu mai multe clustere, oferă potențialul de failover. Ambele baze de date folosesc o metodă similară pentru a finaliza o scriere și au fost optimizate pentru viteză. Datele sunt stocate în cele două baze de date prin fișiere SSTable care sunt imuabile. În Cassandra, coordonatorul trebuie să notifice clientul că scrierea este completă înainte ca mai multe replici să răspundă. O scriere reușită în Bigtable poate fi confirmată doar printr-un răspuns de la un singur nod, deoarece fiecare cheie de rând este atribuită doar unui singur nod. Celulele din oricare bază de date pot să nu fie incluse în SSTable îmbinat.
Din cauza clauzei WHERE dintr-o interogare CQL, este imposibil să returnați mai mult de un rând în Cassandra. Doar nodul responsabil cu gama de chei este necesar să fie consultat în Bigtable. La nodul de procesare, este posibilă limitarea cantității de date care pot fi citite. În timpul unei faze de compactare, SSTables sunt îmbinate în mod regulat, iar datele stocate în Bigtable și Cassandra sunt stocate în ele. Nu există reguli care să reglementeze numărul de versiuni de marcaj temporal pentru fiecare celulă, dar pot exista și alte limite de dimensiune de rând. Garanțiile de durabilitate a datelor sunt oferite de sistemul de replicare al lui Colossus. Bigtable, ca și Cassandra, are o interfață de linie de comandă și biblioteci client pentru multe limbaje de programare comune.
Fiecărui nod i se atribuie un SSTable în Bigtable, iar datele stocate în acesta sunt servite de acel nod. Când dimensionați un cluster Cassandra, nu trebuie să luați în considerare replicile de stocare, așa cum faceți cu Bigtable. Unitățile cu stare solidă (SSD) sau unitățile hard disk (HDD) sunt cele mai frecvent utilizate tipuri de stocare pentru instanțele Bigtable . După cum a demonstrat Cassandra, nu există nicio pierdere a densității de stocare pentru atingerea toleranței la erori. Este posibil să scalați o instanță Bigtable pentru a îndeplini cerințele de încărcare de lucru cu efort minim și timp de nefuncționare minim. Deși există doar patru clustere, fiecare cluster poate fi creat în orice regiune de cloud acceptată din întreaga lume. Google vă recomandă să testați performanța Bigtable cu date și interogări reprezentative pentru a genera o valoare QPS per nod.
Cassandra realizează un număr mare de funcții de administrare folosind componente gestionate Bigtable. Backup-urile de tabel mare creează copii restaurabile ale tabelului, care sunt stocate ca obiecte în cluster. Backup-urile consumă mai puține resurse de nod și sunt mai puțin costisitoare decât stocarea în cloud. O altă metodă pentru a face backup pentru Bigtable este să utilizați un export de date gestionat în Cloud Storage. Sarcinile de întreținere internă, cum ar fi corecția sistemului de operare, recuperarea nodurilor, repararea nodurilor, monitorizarea compactării stocării și rotația certificatelor SSL sunt toate gestionate fără probleme de serviciul Bigtable. Tablourile de bord sunt disponibile pentru monitorizarea valorilor de debit și utilizare la niveluri de instanțe, clustere și tabel în pagina consolei Bigtable Google Cloud . Puteți utiliza tabloul de bord de monitorizare pentru a efectua reglarea avansată a performanței.
Lucrarea Bigtable descrie un sistem de stocare a datelor care acceptă extinderea masivă. Fiecare tabel din date este împărțit într-un număr de partiții. Puteți interoga tabelul utilizând o cheie de rând sau folosind o serie de chei de rând. Lucrarea Bigtable descrie, de asemenea, o metodă de distribuire a muncii tabelului într-un grup de noduri. Apache Cassandra, o bază de date open source, se bazează pe unele dintre conceptele din lucrarea Bigtable. Centrele de date folosesc o arhitectură de noduri distribuite, în care stocarea este partajată între serverele care servesc datele. Accesul la sistemul de stocare a datelor Bigtable este oferit prin utilizarea interfeței de linie de comandă cbt și a bibliotecilor client. Bigtable include o serie de limbaje de programare în plus față de Python, ceea ce facilitează integrarea cu aplicațiile.
Datastax Astra Cassandra de la Google ca serviciu: ușor de implementat și de scalat
DataStax Astra Cassandra ca serviciu de la Google este o alegere excelentă pentru a afla despre Cassandra. Interfața de utilizator a operatorului Kubernetes simplifică configurarea, gestionarea și scalarea implementării Cassandra.
Documentație Bigtable
Documentația Bigtable este o resursă excelentă pentru a afla despre acest instrument puternic. Oferă o privire de ansamblu asupra caracteristicilor și capabilităților Bigtable, precum și informații detaliate despre cum să-l folosești. Documentația este bine organizată și ușor de urmărit, ceea ce o face o resursă valoroasă pentru oricine este interesat să învețe despre acest instrument puternic.
Google Cloud Platform este responsabilă pentru găzduirea bazei de date Bigtable Google. Este ușor să utilizați OpenTSDB 2.1 și versiunile ulterioare atunci când este utilizat împreună cu backend-ul Google. Tot ce trebuie să faceți este să creați o instanță Bigtable, să vă configurați tabelele TSDB folosind shell-ul Bigtable HBase și să porniți TSD-urile. Clienții Bigtable sunt în prezent în versiune beta și suferă o varietate de modificări.
Aspectul eficient al datelor Bigtable
Bigtable este, de asemenea, potrivit pentru operațiunile MapReduce. Datorită aspectului său eficient de date, MapReduce poate gestiona volume mari de date într-o perioadă scurtă de timp.