
Hadoop HDFS și NoSQL: O combinație puternică pentru Big Data
Publicat: 2023-01-05Hadoop este un cadru open source care permite procesarea distribuită de seturi mari de date pe grupuri de computere folosind un model de programare simplu. HDFS este sistemul de fișiere distribuit Hadoop care oferă o modalitate scalabilă și tolerantă la erori de stocare a datelor. Bazele de date NoSQL sunt o nouă clasă de baze de date care sunt concepute pentru a oferi o alternativă scalabilă, flexibilă și de înaltă performanță la bazele de date relaționale tradiționale.
Distincția principală dintre Hadoop și HDFS este că Hadoop este un cadru open source pentru stocarea, procesarea și analiza datelor, în timp ce HDFS este un sistem de fișiere care permite utilizatorilor să acceseze datele Hadoop. Ca rezultat, HDFS este un modul Hadoop .
SQL și Hadoop pot gestiona datele în diferite moduri. Un cadru Hadoop este folosit pentru a asambla componente software, în timp ce un cadru SQL este folosit pentru a asambla baze de date. Pentru datele mari, este esențial să luați în considerare avantajele și dezavantajele fiecărui instrument. Platforma Hadoop stochează date o singură dată, în timp ce Hadoop stochează un număr mult mai mare de seturi de date.
Hadoop nu este o bază de date, ci mai degrabă o bucată de software care permite calcule paralele masive. Această tehnologie permite bazelor de date NoSQL (cum ar fi HBase) să răspândească date pe mii de servere cu o mică degradare a performanței.
Hadoop nu stochează date în același mod în care o face stocarea relațională. Un server distribuit este una dintre aplicațiile care îl utilizează cel mai mult. Deși este o bază de date Hadoop , nu se califică drept bază de date relațională deoarece stochează fișiere în HDFS (sistem de fișiere distribuite).
Care este diferența dintre Nosql și Hdfs?
Este un sistem de fișiere și este denumit și sistem de fișiere. Este deja clar că această aplicație oferă o serie de funcții. De unde iei chestiile astea NOSQL? Vom fi capabili să procesăm cantități mari de date în timp real folosindu-l, deoarece nu ne necesită să folosim baze de date relaționale sau alte caracteristici.
Managerul de stocare HBase, care rulează în Hadoop, oferă citiri și scrieri aleatorii cu latență scăzută. Sistemul HBase folosește o caracteristică de auto-sharding în care tabelele mari sunt distribuite dinamic. Fiecare server de regiune este responsabil pentru deservirea unui set de regiuni și există un singur server de regiune capabil să deservească o regiune (adică HMaster și HRegion sunt două dintre principalele servicii furnizate de HBase. Componenta HRegion a tabelului HBase este responsabilă pentru gestionarea subseturi de date ale tabelului. Când un server de regiune este lansat, acesta este alocat fiecărei regiuni. Ca urmare, masterul nu este implicat în operațiunile de citire și scriere.
Când vine vorba de tratarea datelor nestructurate și voluminoase, bazele de date NoSQL precum MongoDB și Cassandra se remarcă față de bazele de date relaționale tradiționale. Companiile cu încărcături mari de date, cum ar fi Big Data, preferă să folosească aceste instrumente pentru a procesa și analiza rapid cantități masive de date variate și nestructurate. MongoDB stochează date în colecții, în timp ce Hadoop stochează datele într-un sistem de fișiere diferit, cunoscut sub numele de HDFS. Este avantajos să existe o arhitectură diferită ca urmare a acestei diferențe. De asemenea, este mult mai rapid să interoghezi datele în MongoDB decât să cauți prin fișiere individuale. În plus, deoarece mongodb este proiectat pentru medii cu volum mare, este foarte potrivit pentru a gestiona volume mari de date la un cost relativ scăzut. Se recomandă ca întreprinderile care necesită soluții Big Data să utilizeze baze de date NoSQL. Au numeroase avantaje față de bazele de date tradiționale în ceea ce privește viteza de procesare și analiză și sunt potrivite pentru analiza și gestionarea datelor la scară largă.
Este Hadoop o bază de date Nosql?
Hadoop nu este un sistem tradițional de gestionare a bazelor de date relaționale. Este un sistem de fișiere distribuit care ajută la stocarea și procesarea unor seturi mari de date pe un cluster de servere de mărfuri. Hadoop este proiectat să se extindă de la un singur server la mii de mașini, fiecare oferind calcul și stocare locală.
Utilizarea datelor la scară super-masivă este revoluționată de noile tehnologii. Infrastructura de date mari are numeroși jucători, inclusiv Hadoop, NoSQL și Spark. DBA și inginerii/dezvoltatorii de infrastructură lucrează acum pentru ei pentru a gestiona sisteme complexe într-o nouă generație de DBA și ingineri de infrastructură. Deoarece Hadoop este mai degrabă un ecosistem software decât o bază de date, permite calcularea unor cantități masive de date la o rată care este atât eficientă, cât și eficientă. Beneficiile pe care le oferă pentru cantitățile masive de date pe care le gestionează au schimbat jocul pentru procesarea datelor mari. O tranzacție mare de date, cum ar fi una care durează 20 de ore pentru a fi finalizată pe un sistem centralizat de baze de date relaționale, poate fi finalizată în doar trei minute pe un cluster Hadoop.
Există mai mult de un limbaj SQL din care să alegeți. MongoDB, o bază de date de documente pură, este un tip de bază de date NoSQL; Cassandra, o bază de date cu coloane largi, este alta; iar Neo4j, o bază de date grafică, este alta. Această caracteristică a fost creată de SQL- on-Hadoop . SQL-on-Hadoop este o nouă clasă de instrumente analitice care combină interogări SQL consacrate cu cadre de date Hadoop. SQL-on- Hadoop permite dezvoltatorilor de întreprinderi și analiștilor de afaceri să colaboreze cu Hadoop pe clustere de calcul de mărfuri, permițând rularea interogărilor familiare SQL. Avantajele SQL-on-hadoop. Numeroasele avantaje ale SQL-on- Hadoop, pe lângă ușurința sa de utilizare, merită din plin timpul și resursele dezvoltatorilor și analiștilor de date pentru întreprinderi. Pentru început, aceștia pot lucra cu Hadoop pe clustere de calcul de mărfuri, ceea ce le va permite să înceapă rapid și ușor cu analiza datelor mari. SQL-on-Hadoop le permite, de asemenea, să utilizeze interogări SQL familiare, făcându-le mai ușor să învețe analiza Big Data. În plus, SQL-on-Hadoop oferă funcționalitatea de hărți/reducere a lui Hadoop, precum și capabilitățile bogate de analiză a datelor pe care le oferă.
Baze de date Nosql în ascensiune
Ca urmare, bazele de date NoSQL devin din ce în ce mai populare datorită scalabilității, performanței de citire/scriere și flexibilității datelor. Există mai multe exemple bune de baze de date NoSQL pe piață, inclusiv DynamoDB, Riak și Redis.
Hive este o bază de date NoSQL ușoară și modulară, cu valori excelente de performanță. Este scris în limbajul de programare Dart pur și este popular în rândul dezvoltatorilor datorită simplității sale.
Care este diferența dintre Hadoop și baza de date?

În timp ce RDBMS nu stochează și procesează date, Hadoop stochează și procesează mai degrabă datele ca un sistem de fișiere distribuit. Un RDBMS, pe de altă parte, este o bază de date structurată care stochează date în rânduri și coloane și poate fi actualizată cu SQL și prezentată într-o varietate de tabele.
Adoptarea tehnologiilor și instrumentelor Big Data a crescut într-un ritm rapid. O distribuție Hadoop open-source rulează pe un sistem de fișiere distribuit și permite schimbul și procesarea de seturi mari de date. Un RDB este un sistem de bază de gestionare a bazelor de date care este utilizat în cea mai simplă formă de către toate sistemele de gestionare a bazelor de date, cum ar fi Microsoft SQL Server, Oracle și MySQL. În ciuda faptului că este clasificat ca o evoluție, un RDBMS seamănă mai mult cu orice altă bază de date standard decât cu o întreprindere majoră. Nu este o bază de date, ci mai degrabă un sistem de fișiere distribuit care poate găzdui și procesa colecții mari de fișiere de date. Deși sisteme precum Hadoop pot oferi performanțe mai bune, există unele dezavantaje care sunt rareori discutate. Trebuie să vă gândiți cum să vă gestionați clusterul Hadoop, securitatea, Presto sau orice altă interfață pe care o utilizați.
Majoritatea sistemelor de baze de date relaționale, cum ar fi SQL Server și Oracle, sunt mult mai ușor de utilizat. Majoritatea organizațiilor se confruntă cu o problemă majoră de a nu avea suficienti oameni calificați care să poată opera eficient Hadoop, precum și un cost semnificativ al talentului. Dacă aveți 10.000 de angajați, veți avea nevoie de o mulțime de date pentru a le urmări pe toți. Aceste informații pot fi stocate într-o varietate de moduri cu Presto. O partiție de dată poate fi folosită pentru a stoca poziția unei persoane în fiecare zi. RDBMS, pe de altă parte, poate fi folosit ca exemplu de model de date. Singura modalitate de a utiliza această metodă este dacă aveți deja acces la datele din ziua precedentă.
Care este diferența cheie între bazele de date relaționale și Big Data?
Distincția principală dintre bazele de date relaționale și date mari este că bazele de date relaționale sunt optimizate pentru stocarea datelor structurate, în timp ce datele mari sunt optimizate pentru stocarea datelor nestructurate și semi-structurate. O bază de date relațională este modelată după modelul relațional, în timp ce o bază de date mari este modelată după modelul distribuit. Datele structurate pot fi stocate și procesate în baze de date relaționale într-un mod eficient. Tabelul conține date și permite accesul și preluarea în limbajul de interogare structurat (SQL). Big data este definită ca orice date care sunt nestructurate sau semi-structurate.

Care este diferența dintre Hadoop și Mongodb?
Deoarece MongoDB rulează în C, este mai bun la gestionarea memoriei decât orice altă bază de date. Hadoop este un set de software bazat pe Java care oferă un cadru pentru stocarea, preluarea și procesarea datelor. Hadoop optimizează spațiul mai eficient decât MongoDB.
MongoDB a fost o bază de date NoSQL (Nu numai SQL) creată în C. Hadoop este o platformă software open-source compusă în principal din Java, care permite procesarea unor cantități mari de date. În plus, MongoDB Atlas include căutare în text complet, analiză avansată și un limbaj de interogare intuitiv. Hadoop este eficient în stocarea și procesarea unei cantități mari de date, dar face acest lucru în loturi mici. Există o varietate de instrumente încorporate de procesare a datelor în timp real disponibile în MongoDB. Datorită conectorilor săi pentru instrumente externe, cum ar fi Kafka și Spark, MongoDB simplifică asimilarea și procesarea datelor. Avantajele Hadoop și MongoDB față de bazele de date tradiționale în domeniul big data sunt numeroase. Hadoop, un sistem de fișiere distribuit, poate fi folosit pentru a trata fișiere enorme. MongoDB este singura bază de date capabilă să înlocuiască o bază de date tradițională în ceea ce privește performanța.
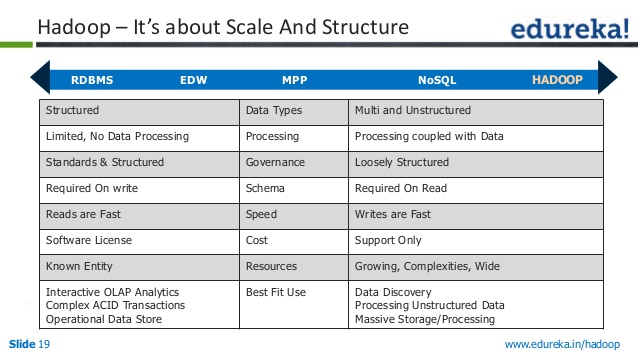
Rdbms Vs Nosql Vs Hadoop
Există trei tipuri principale de depozite de date - RDBMS, NoSQL și Hadoop. Fiecare are propriile puncte forte și puncte slabe, așa că este important să-l alegi pe cel potrivit nevoilor tale.
RDBMS (Relational Database Management System) este cel mai comun tip de depozit de date. Este ușor de utilizat și ușor de scalat. Cu toate acestea, nu este la fel de flexibil ca NoSQL sau Hadoop și poate fi mai costisitor de întreținut.
NoSQL (Nu numai SQL) este un tip mai nou de depozit de date care devine din ce în ce mai popular. Este mai flexibil decât RDBMS și poate fi mai scalabil. Cu toate acestea, nu este la fel de ușor de utilizat și poate fi mai scump de întreținut.
Hadoop este un tip de depozit de date conceput pentru date mari. Este foarte scalabil și poate gestiona o mulțime de date. Cu toate acestea, nu este la fel de ușor de utilizat ca RDBMS sau NoSQL și poate fi mai costisitor de întreținut.
Abordarea unei întreprinderi în ceea ce privește stocarea, procesarea și analiza datelor poate fi mult îmbunătățită cu platforma Apache Hadoop . Un lac de date poate rula mai multe tipuri de sarcini de lucru analitice pe același hardware și software, precum și poate gestiona volume de date la scară largă. Analiștii pot interacționa acum eficient cu datele din mers, folosind instrumente precum Apache Impala și Apache Spark. Hadoop, spre deosebire de Sistemul de management al bazelor de date relaționale (RDBMS), nu are aceleași capacități ca o bază de date, ci este mai mult un sistem de fișiere distribuit capabil să proceseze cantități masive de date. Cantitatea de date care poate fi procesată ușor și eficient este denumită volumul de date. Cu alte cuvinte, procesul de volum total de date într-o anumită perioadă de timp poate fi optimizat. Are capacitatea de a stoca și procesa date dintr-o gamă largă de surse și de a le pregăti pentru analiză.
Într-o cantitate mică, RDBMS ar putea gestiona doar date structurate și semi-structurate. Hadoop este incapabil să gestioneze date dintr-o varietate de surse sau din orice structură structurată. Timpul de răspuns, scalabilitatea și costul sunt câțiva dintre alți factori importanți de luat în considerare.
De ce Rdbms este încă cel mai popular sistem de gestionare a bazelor de date
Cel mai utilizat sistem de gestionare a bazelor de date din lume este RDBMS. Oferă o gamă largă de funcții, precum și extrem de fiabil. Baza de date relațională este cea mai potrivită pentru stocarea datelor care sunt necesare pentru accesarea mai multor utilizatori.
Bazele de date NoSQL câștigă popularitate în parte datorită avantajelor lor de performanță față de bazele de date relaționale. De asemenea, vă permit să stocați cantități mari de date pe care nu trebuie să le partajați cu mai mulți utilizatori.
Hadoop Nosql
Pe un cluster hardware de mărfuri, Hadoop stochează Big Data. Aveți opțiunea de a schimba orice funcție care nu funcționează sau care corespunde nevoilor dumneavoastră dacă este necesar. În schimb, un sistem de gestionare a bazelor de date NoSQL este un tip de sistem de gestionare a bazelor de date care este utilizat pentru a stoca date structurate, semi-structurate și nestructurate.
Hdfs este o bază de date
Sistemul de fișiere HDFS este un sistem de fișiere distribuit care rulează pe hardware de bază. Un singur cluster Apache Hadoop poate fi configurat pentru a suporta sute (și chiar mii) de noduri folosind această caracteristică. Apache Hadoop, care include și MapReduce și YARN, este alcătuit din mai multe componente majore.
Accesul de înaltă performanță la date este oferit de Hadoop Distributed File System (HDFS), care este o componentă a sistemului de operare Hadoop . Nodul de nume primar al unui cluster este responsabil pentru ținerea evidenței unde sunt stocate datele fișierului clusterului. Pe lângă gestionarea accesului la fișiere, nodul Nume gestionează accesul la fișiere, cum ar fi citirea, scrierea, crearea, ștergerea și așa mai departe. Yahoo a introdus sistemul de fișiere distribuit Hadoop ca parte a cerințelor pentru plasarea anunțurilor online și pentru motoarele de căutare. Protocolul HDFS expune un spațiu de nume de sistem de fișiere pentru a stoca datele utilizatorului. DataNodes pot comunica între ele în timpul operațiunilor normale de fișiere, deoarece comunică între ele. Sistemul de fișiere distribuit Hadoop (HDFS) este o componentă a multor lacuri de date open source. HDFS este folosit de eBay, Facebook, LinkedIn și Twitter pentru a analiza cantități mari de date. În cazul unei defecțiuni nod sau hardware, este necesară replicarea datelor pentru ca HDFS să funcționeze corect.
Exemplu de bază de date Hadoop
O bază de date Hadoop este o bază de date care utilizează sistemul de fișiere distribuit Hadoop (HDFS) pentru stocarea de bază. Bazele de date Hadoop sunt utilizate de obicei pentru stocarea unor cantități mari de date care sunt prea mari pentru a încăpea pe un singur server.
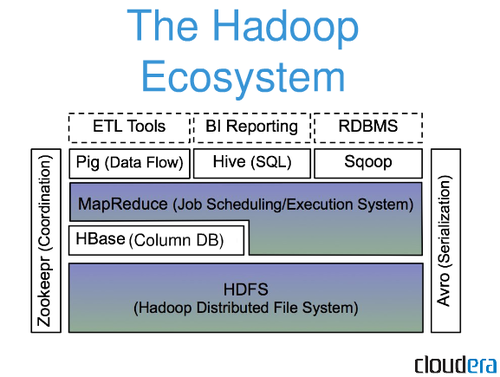
Apache Hadoop, un cadru open source pentru stocarea și procesarea de seturi mari de date într-un mod distribuit pe hardware de bază, este utilizat într-o varietate de aplicații. Este o versiune open source a paradigmei Google care a fost folosită în lucrarea MapReduce din 2004. Vom trece peste câteva dintre cele mai frecvente întrebări de către începătorii în ecosistemul Big Data în acest articol. Platforma Apache Hadoop se concentrează mai degrabă pe procesarea distribuită a datelor decât pe stocarea bazelor de date sau pe stocarea relațională. În ciuda prezenței unei componente de stocare cunoscută sub numele de HDFS (Hadoop Distributed File System), care stochează fișierele utilizate pentru procesare, HDFS se încadrează în categoria unei baze de date relaționale. Hive, precum și HiveQL, pot fi folosite pentru a interoga stocarea HDFS a HDFS, care este încorporată în HDFS.
Care este un exemplu de Hadoop?
Hadoop poate fi folosit de companiile de servicii financiare pentru a evalua riscul, pentru a construi modele de investiții și pentru a crea algoritmi de tranzacționare; Hadoop a fost, de asemenea, folosit pentru a ajuta la crearea și gestionarea acelor aplicații. Această tehnologie este folosită de comercianții cu amănuntul pentru a-i ajuta să înțeleagă și să-și servească mai bine clienții prin analiza datelor structurate și nestructurate.
Multe utilizări ale Hadoop
Hadoop poate fi utilizat pentru a gestiona date în aplicații de date mari, cum ar fi analiza datelor mari, analiza datelor în timp real, cercetarea științifică și depozitarea datelor. Drept urmare, este o platformă versatilă și adaptabilă ideală pentru o gamă largă de aplicații.
Este Spark o bază de date Nosql
Un NoSQL DataFrame, conform documentației, este un format de sursă de date pentru Spark DataFrame. DataPruning și filtrarea (push-down de predicat) sunt disponibile în această sursă de date, ceea ce permite interogărilor Spark să ruleze pe cantități mai mici de date și doar datele necesare pentru jobul activ sunt încărcate.
Este nevoie de mult efort tactic pentru a conecta o bază de date Apache Spark și NoSQL (Apache Cassandra și MongoDB) una la alta. Acest blog este despre cum să creați aplicații Apache Spark pe backend-uri NoSQL. TCP/IP sPark este o destinație populară de parc tematic, cu un număr mare de curse în binecunoscutele sale secțiuni CassandraLand și MongoLand. Când aplicația noastră Spark căuta date de la DOE, acesta s-a rotit și a devenit frustrat. Lecția de aici este că secvența cheie a lui Cassandra este critică în procesul de preluare a datelor. CassandraLand are, de asemenea, un roller coaster popular numit Partitioner. Clienții care se deplasează cu roller coaster sunt încurajați să țină evidența istoricului călătoriilor, astfel încât operatorii să poată urmări cine a mers pe el în fiecare zi. Lecția 1 Mongo – Gestionați corect conexiunile MongoDB Când actualizați datele, cum ar fi starea noului membru al parcului al Departamentului de Energie, indexurile Mongo pot fi de mare ajutor. În cazul unor actualizări specifice, MongoDB și Spark ar trebui să asigure o gestionare și indexare adecvată a conexiunii.
Spark: Viitorul Big Data
Apache Spark, un sistem de procesare distribuită dezvoltat în colaborare cu Apache Software Foundation, este un sistem de procesare a datelor mari bazat pe Hadoop. Un cadru open source care poate fi folosit pentru a optimiza seturi mari de date și pentru a reduce decalajul dintre modelele procedurale și relaționale. În plus, Spark acceptă MongoDB, permițându-i să fie utilizat pentru analiză în timp real și învățare automată.