
Scalabilitate orizontală cu baze de date NoSQL
Publicat: 2022-11-20Bazele de date NoSQL sunt scalabile pe orizontală, ceea ce înseamnă că se pot scala prin adăugarea mai multor noduri la un sistem, spre deosebire de scalarea verticală, care se referă la adăugarea mai multor resurse la un singur nod. Aceasta înseamnă că o bază de date NoSQL poate fi fragmentată sau împărțită în mai multe bucăți, iar fiecare piesă poate fi stocată pe un server separat. Acest lucru permite scalarea orizontală a bazei de date, care este mult mai eficientă și scalabilă decât scalarea verticală.
Scalare este esențială pentru bazele de date SQL și NoSQL, iar conceptul de fragmentare a bazelor de date este o parte esențială a acestuia. Împărțim baza de date în bucăți (fragmente), așa cum sugerează și numele.
În plus, există o lipsă a capacității de operații dinamice în NoSQL. Nu există nicio garanție că compusul va avea proprietăți ACIDE. Bazele de date SQL sunt o opțiune în astfel de cazuri. În plus, dacă aplicația dvs. necesită flexibilitate în timpul rulării, evitați NoSQL.
Care sunt unele dezavantaje ale bazelor de date NoSQL? Unul dintre dezavantajele bazelor de date NoSQL este că le lipsește suportul pentru tranzacții ACID (atomicitate, consistență, izolare, durabilitate) necesar pentru tranzacțiile ACID în mai multe documente. Multe aplicații pot folosi atomicitatea cu o singură înregistrare cu un design adecvat al schemei.
Mongodb poate fi spart?
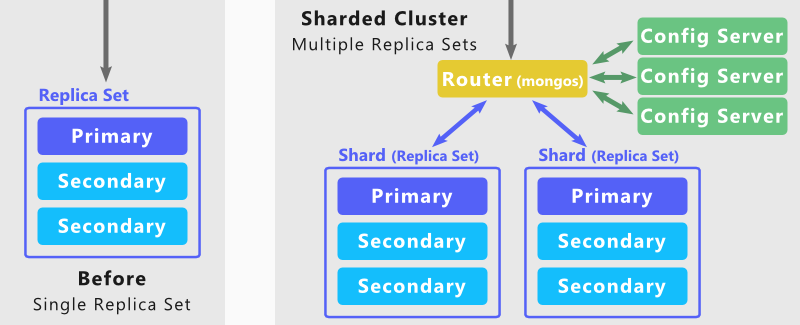
Backend-ul MongoDB este construit pe o arhitectură sharding pentru a suporta seturi de date extrem de mari și operațiuni cu un randament ridicat. Bazele de date mari cu cantități mari de date sau care rulează aplicații de mare viteză pot duce la compromiterea capacității serverului.
Folosind MongoDB Sharding, vă puteți scala baza de date pentru a gestiona un număr infinit de utilizatori concurenți. Acest lucru se realizează prin creșterea debitului de citiri și scrieri, precum și a capacității de stocare a sistemului. Există numeroase colecții din care puteți alege. Pentru a maximiza performanța clusterului, alegeți cu atenție cheia shard. Baza de date MongoDB NoSQL acceptă două tipuri de distribuție de date între clustere cu capabilități de fragmentare. Datele pot fi împărțite în intervale utilizând valoarea cheie de interval a unui fragment. Folosind hash hashing, valoarea unui Shard hash poate fi calculată.
Unele chei shard pot fi închise, dar este puțin probabil ca valorile lor hashing să fie pe aceeași bucată. Prin configurarea și pornirea setării Sharding, baza de date va putea fi accesată. Asigurați-vă că mongo-urile sunt conectate. Cioburile tale vor fi adăugate și la cluster. De fiecare dată când efectuați această procedură, veți fi finalizat o tranzacție pentru fiecare fragment. Este necesar să activați o setare de sharding în baza de date. Apoi, utilizați metoda sh.shardCollection() pentru a vă fragmenta colecția. Acum ați creat primul dvs. cluster fragmentat. Până acum, routerele (instanțele mongos) au fost folosite pentru interacțiunile aplicațiilor.
MongoDB este o bază de date NoSQL excelentă pentru întreprinderile mici și mijlocii care necesită scalabilitate și performanță. În plus, include caracteristici precum sharding, care permite distribuirea documentelor pe shard-uri pentru a îmbunătăți performanța. Dacă baza de date atinge 200 GB sau mai mult, procesele de backup și restaurare pot fi încetinite. Ca rezultat, ori de câte ori baza de date MongoDB crește peste o anumită dimensiune, ar trebui să consultați întotdeauna furnizorul dvs. MongoDB.
Ce baze de date acceptă Sharding?

Bazele de date care acceptă sharding sunt de obicei concepute pentru a rula pe mai multe servere, fiecare server găzduind o parte a bazei de date. Acest lucru permite ca baza de date să fie răspândită pe mai multe servere, ceea ce poate îmbunătăți performanța și scalabilitatea.
Sharding în Nosql

Tiparele de partiționare bazate pe tehnologiile NoSQL includ hashing. Partiționarea implică plasarea fiecărei partiții pe un server potențial separat – posibil în toată lumea. Utilizatorii din întreaga lume pot beneficia de acest scale out, care le permite să acceseze diferite părți ale setului de date în același timp.
Un set de date este distribuit prin stocarea lui în mai multe baze de date pentru a obține rezultatul dorit. Deoarece această abordare permite împărțirea seturilor de date mai mari în bucăți mai mici, mai multe noduri de date pot fi folosite pentru a le stoca. Deoarece datele sunt distribuite pe mai multe mașini, o bază de date fragmentată poate gestiona mai multe solicitări decât poate gestiona o singură mașină. Folosind Sharding pentru a gestiona sarcina crescută într-o măsură nelimitată, puteți crește debitul, capacitatea de stocare și disponibilitatea în baza de date. Atunci când volumul de lucru este scris în primul rând pentru a citi, replicarea datelor vă va oferi câștiguri semnificative de performanță și este posibil să nu aveți nevoie deloc să utilizați fragmentarea. Este necesară o arhitectură diferită pentru o sarcină de lucru bazată în principal pe scriere sau una care este amestecată cu citire-scriere. Există multe tipuri și arhitecturi diferite de sharding.

Utilizarea fragmentării bazate pe intervale este o metodă simplă și directă de partiție orizontală; cu toate acestea, eficacitatea acestuia va fi determinată de disponibilitatea cheilor adecvate și de alegerea intervalelor adecvate. O înregistrare hash sau algoritmică sharding este aplicată ca intrare, unde funcția hash sau algoritmul este utilizat pentru a genera o valoare de ieșire sau hash. Datele pot fi păstrate într-un singur spațiu fizic prin utilizarea fragmentării bazate pe hash. Într-o bază de date relațională , datele asociate cu un anumit tabel pot fi distribuite în alte tabele. Chiar dacă nu poate fi obținută o cheie adecvată, hashing-ul intrărilor permite o distribuție uniformă a datelor între fragmente. Poate ajuta la reducerea operațiunilor de difuzare, precum și la creșterea performanței. Un serviciu de fragmentare bazat pe geografie păstrează, de asemenea, datele aferente într-un singur loc pe un singur server. Un shard ranged este unul care este distribuit geografic, în care cheia pentru cheie este o cheie localizată geografic pentru cioburi. Există o serie de alte opțiuni care nu sunt acoperite în acest articol pentru alocarea geoshard-urilor.
Ce este Sharding în Sql?
Un depozit de date poate fi distribuit în mai multe baze de date prin metoda hashing și apoi stocat pe mai multe mașini. Acest lucru permite ca seturi de date mai mari să fie împărțite în bucăți mai mici și stocate în mai multe noduri de date, crescând capacitatea generală a sistemului.
Acest algoritm nu garantează date partiționate uniform
Acest algoritm, conform acestui algoritm, garantează că datele vor fi distribuite uniform între fragmente, dar nu garantează că vor fi distribuite uniform între fragmente. Un rând din coloana partiției cu numele de date user_id va fi distribuit în mod egal între cele cinci fragmente; cu toate acestea, valorile datelor pentru cele cinci fragmente nu vor fi împărțite în mod egal.
Mongodb folosește Sharding?
Folosind o combinație de tehnici, mai multe mașini pot partaja date printr-o metodă Sharding. Când implementează seturi mari de date și efectuează operațiuni de mare volum, MongoDB folosește sharding. Sistemele de baze de date cu o cantitate mare de date sau aplicații care necesită un randament ridicat pot necesita o cantitate semnificativă de capacitate de stocare.
Viitorul Sharding: Postgresql
Faceți un plan pentru viitor. Nu este doar posibilă implementarea unei soluții de sharding, dar este și un pas necesar. Ca parte a procesului, reglarea și optimizarea sunt necesare în mod regulat. Ar trebui să fiți conștienți de faptul că soluțiile de sharding de astăzi evoluează rapid și ar trebui să fiți la curent. PostgreSQL a făcut progrese semnificative în spațiul de fragmentare în ultimii ani, așa că dacă doriți o soluție care să poată fi utilizată pe mai multe platforme, ar trebui să vă gândiți serios să o utilizați.
Nosql Sharding vs Partitioning
Partiționarea și algoritmii pentru sortarea unui set mare de date în secțiuni mai mici sunt analoge. Datele sunt partiționate astfel încât să poată fi răspândite pe mai multe computere, în timp ce fragmentarea le permite să fie distribuite pe mai multe computere. În general, datele partiționate sunt împărțite în subseturi bazate pe o singură instanță a bazei de date.
Partiționarea prin scădere este un tip de partiție, pe lângă partiționarea orizontală. O altă metodă este partiția verticală, în care împărțiți un tabel în bucăți mai mici. Când replicați o partiție verticală, aceasta este denumită partiție verticală. Pentru a împărți datele, copiați schema și apoi utilizați o cheie shard. Iată câteva exemple de când este potrivit să împărțiți un tabel. Când datele sunt partiționate, este adesea mai ușor să efectuați interogări. Să presupunem că o aplicație conține un tabel de comenzi care conține o înregistrare istorică a comenzilor și că acest tabel este partiționat în fiecare săptămână. Când solicitați comenzi pentru o singură săptămână, veți putea accesa doar o singură partiție a tabelului Comenzi. O procedură de tăiere a partiției pentru această interogare ar putea, teoretic, să îi permită să ruleze de 100 de ori mai rapid.