
Este Spark pentru Nosql
Publicat: 2023-02-05Spark este un instrument puternic pentru lucrul cu date, în special cu seturi mari de date. Este conceput pentru a fi rapid și eficient și acceptă o varietate de formate de date, inclusiv baze de date NoSQL . Bazele de date NoSQL devin din ce în ce mai populare, deoarece sunt potrivite pentru manipularea unor cantități mari de date. Spark vă poate ajuta să interogați și să manipulați eficient datele NoSQL.
Pentru a funcționa eficient, este esențial să gestionați bazele de date ale aplicației dvs. utilizând Apache Spark și NoSQL ( Apache Cassandra și MongoDB). Scopul acestui blog este de a oferi sfaturi pentru dezvoltarea aplicațiilor Apache Spark folosind backend-uri NoSQL. Este un parc tematic, iar TCP/IP SPark are plimbări atât în CassandraLand, cât și în MongoLand. Când am încercat să interogăm datele DOE, aplicația noastră Spark a început să se rotească în afara axei sale. Lecția de aici este că atunci când o interoghezi pe Cassandra, secvențele de taste sunt importante. CassandraLand oferă și roller coasterul Partitioner, care este una dintre cele mai populare atracții ale sale. În timp ce clienții se bucură de plimbare cu roller coaster, operatorii de călătorie pot urmări cine a mers pe el în fiecare zi, păstrând informațiile lor.
În lecția unu, vom trece peste gestionarea conexiunilor MongoDB. Când trebuie să actualizați informații despre un parc, cum ar fi noul statut de membru al unui parc al Departamentului de Energie, puteți utiliza indici mongo . MongoDB și Spark ar trebui să fie utilizate pentru a vă asigura că conexiunea dvs. este gestionată corect, precum și indexurile în cazuri specifice.
Apache Spark este un sistem de procesare distribuit popular, care este open-source și construit pentru a fi utilizat în sarcini mari de lucru de date. Această caracteristică, pe lângă stocarea în cache în memorie și execuția optimizată a interogărilor, permite interogări analitice rapide pentru cantități mari de date.
Cu aproape același cod, este mai eficient și versatil, permițându-i să proceseze date în lot și în timp real în același timp. Ca urmare, instrumentele mai vechi de date Big Data devin din ce în ce mai învechite din cauza lipsei acestei funcționalități.
Ce tip de bază de date este Spark?
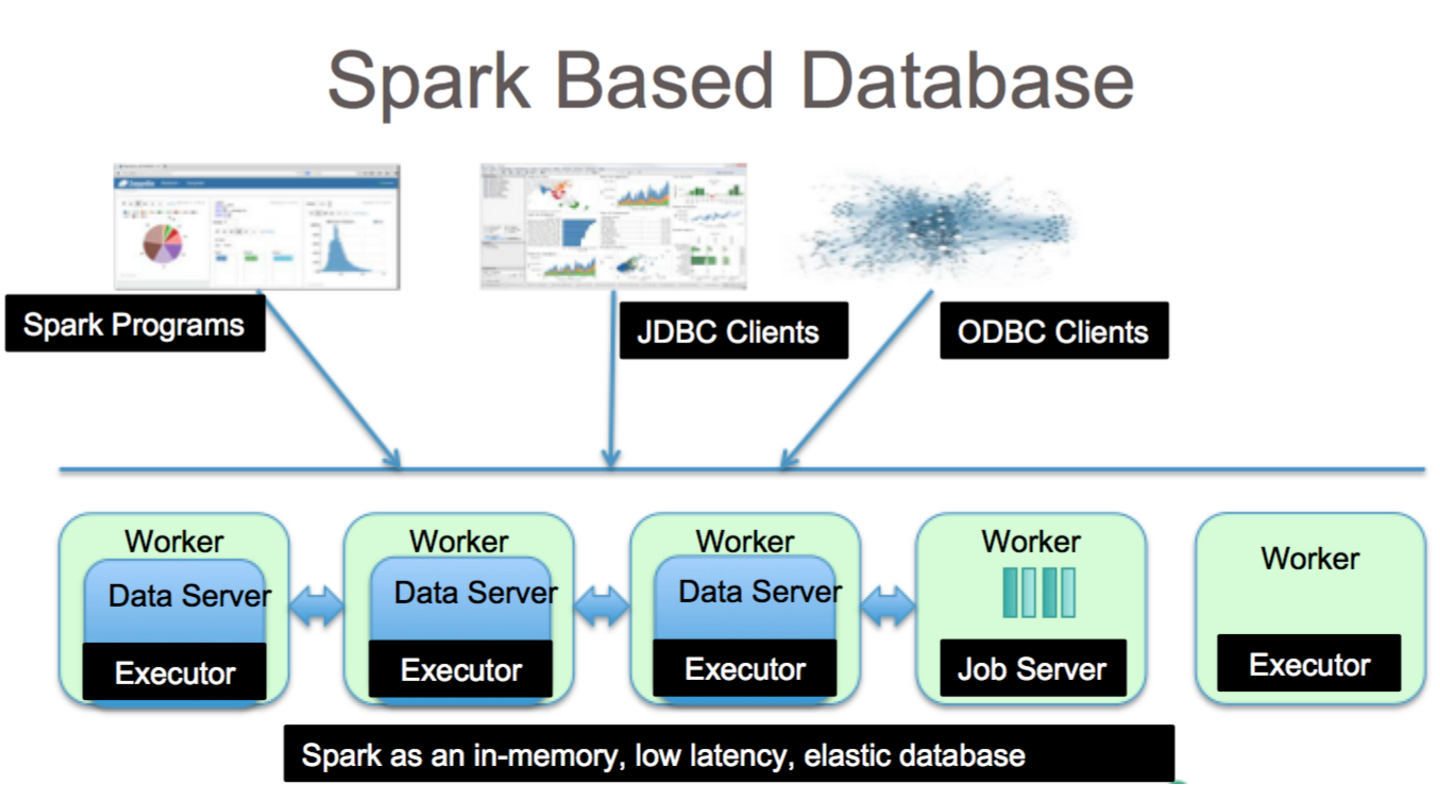
Apache Spark este un cadru de procesare a datelor care poate gestiona date dintr-o varietate de depozite de date, inclusiv (HDFS), baze de date NoSQL și baze de date relaționale.
Deși au existat numeroase cicluri de hype pentru bazele de date relaționale, acestea vor continua să fie populare, indiferent de cele mai recente progrese și de creșterea bazelor de date NoSQL. De-a lungul timpului, a devenit din ce în ce mai dificilă stocarea datelor în baze de date relaționale. În acest articol, vom analiza câteva dintre progresele semnificative în a profita de puterea bazei de date relaționale la scară globală. Când a fost lansat pentru prima dată, interfața dintre Spark și Big Data Analysis a fost minimă. Mulți oameni au scris mult cod pentru a rula acest program, care a fost puternic, dar relativ lent. Utilizatorii vor putea combina cu ușurință aceste două modele în baza de date Spark SQL . De asemenea, acceptă o gamă largă de formate de date dintr-o varietate de surse.
Proiectul open source Apache Spark este cel mai activ, cu sute de colaboratori contribuind la el. Pe lângă faptul că este un proiect open source gratuit, Spark SQL a început să câștige popularitate în industriile mainstream. Pe lângă Spark SQL, aproximativ două treimi dintre clienții Databricks Cloud (serviciul găzduit care rulează Spark) folosesc alte limbaje de programare. După încheierea primului nostru studiu de caz, vom demonstra cum să aplicăm databricks la caz în acest studiu de caz practic. Un Spark DataFrame este un set de rânduri (tipuri de rând) care sunt distribuite cu aceeași schemă. Fiecare coloană din setul de date este etichetată cu un nume. API-ul DataFrame permite dezvoltatorilor să integreze codul procedural și relațional.

Spark poate gestiona și funcții avansate, cum ar fi UDF-urile. Un tabel dintr-o bază de date relațională este analog cu un cadru de date dintr-o bază de date cadru de date, dar sunt implicate mai multe optimizări. Ele pot fi manipulate în același mod în care sunt colecțiile native distribuite (RDD) ale Spark. În general, interogarea Spark SQL este mai rapidă decât interogarea Shark și este mai competitivă cu Impulsa. În Interogarea 3a, unde selectivitatea interogării face ca unul dintre tabele să fie foarte mic, există o diferență semnificativă între Impala și Impala.
Este un instrument fantastic pentru analiza datelor cu Spark SQL. Sintaxa HiveQL, Hive SerDes și HiveDF-uri pot fi accesate prin sintaxa HiveQL, precum și Hive SerDes și HiveDF-uri. Metamagazinele Hive , SerDes și UDF-urile au fost deja implementate. În ciuda faptului că Spark este o bază de date, este și o bază de date NoSQL. Ca rezultat, atunci când creați un tabel gestionat în Spark, veți putea folosi o varietate de instrumente compatibile cu SQL pentru a vă stoca datele. Expresiile SQL pot fi folosite pentru a accesa tabelele din Spark prin conectarea la JDBC prin conectori de la jdbc.org. Drept urmare, puteți utiliza și instrumente terțe, cum ar fi Tableau, Talend și Power BI. Capacitatea de a utiliza Spark este ideală pentru analiza datelor și este un instrument util pentru o gamă largă de industrii.
Spark Sql: Cel mai bun din ambele lumi
Ea realizează o punte între cele două modele menționate mai devreme, modelul procedural și cel relațional, prin includerea a două componente primare. Ca rezultat, puteți rula operațiuni relaționale la scară largă pe surse de date externe și colecții distribuite încorporate ale lui Spark, folosind un API DataFrame.
Ce este spark în baza de date? Este un cadru open-source care utilizează învățarea automată, procesarea interactivă a interogărilor și încărcături de lucru în timp real. Această companie nu are propriul sistem de stocare; mai degrabă, folosește analize pe alte sisteme de stocare, cum ar fi HDFS, Amazon Redshift, Amazon S3, Couchbase și altele, pe lângă propriile sale. Când vine vorba de prelucrarea structurată a datelor, Spark SQL nu este doar o bază de date; este si un modul. Marea majoritate este scrisă pe DataFrames, care sunt abstracții de programare care funcționează împreună cu interogări SQL.
Care este tipul de SQL SQL pentru „sparksql”? Hive SQL acceptă sintaxa HiveQL, precum și Hive SerDes și UDF-uri, permițându-vă să accesați depozitele Hive care au fost create anterior. Utilizarea metastorelor Hive, SerDes și UDF-uri existente în Spark SQL nu este dificilă.
Poate Mongodb să ruleze Spark?
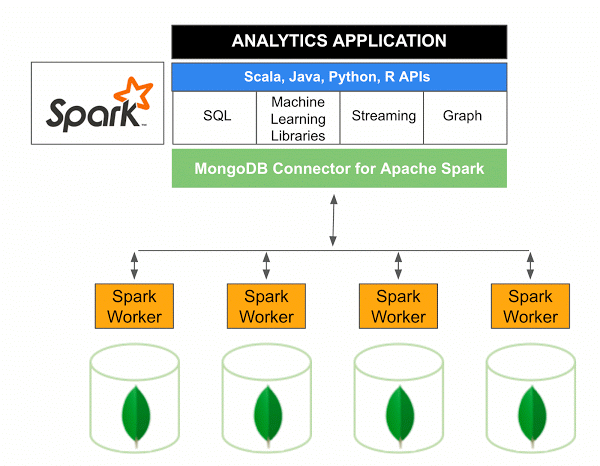
Versiunea 10.0 a MongoDB Connector pentru Apache Spark include suport pentru Spark Structured Streaming prin noul Spark Data Sources API V2 , precum și implementarea noului Spark Data Sources API V2.
Conectorul MongoDB pentru Spark este un proiect open source care vă permite să scrieți date din MongoDB și să le citiți din MongoDB folosind Scala. Datorită metodelor utilitare ale conectorilor, interacțiunile dintre Spark și MongoDB sunt simplificate, făcându-l o combinație puternică pentru crearea de aplicații analitice sofisticate. Folosind caracteristicile de replicare și sharding încorporate, Spark poate fi implementat într-o varietate de sarcini de lucru care utilizează baze de date MongoDB .
Spark: Calea rapidă de a construi aplicații bogate în date
Cu ajutorul Spark, un instrument puternic, puteți dezvolta rapid aplicații mai funcționale. Prin încorporarea MongoDB, dezvoltatorii pot accelera procesul de dezvoltare utilizând o singură tehnologie de bază de date. În plus, Spark este nativ din cloud și include suport pentru depozitele de date NoSQL , făcându-l ideal pentru aplicațiile cu consum intens de date.