
Kafka: O alegere excelentă pentru brokerii de mesaje în microservicii
Publicat: 2022-11-19Kafka este o platformă de streaming distribuită. Este adesea folosit pentru agregarea jurnalelor, procesarea fluxului în timp real și aprovizionarea cu evenimente. Recent, Kafka a câștigat popularitate ca broker de mesaje pentru microservicii. Kafka nu este o coadă de mesaje tradițională precum ActiveMQ sau RabbitMQ. Nu are un server central care să stocheze toate mesajele. În schimb, folosește un model de publicare-abonare. Mesajele sunt stocate în subiecte și fiecare subiect poate avea mai multe partiții. Kafka este foarte disponibil și scalabil. Poate gestiona miliarde de mesaje pe zi. Kafka este, de asemenea, foarte rapid. Poate procesa mesaje în timp real. Kafka este o alegere excelentă pentru construirea unui broker de mesaje pentru microservicii. Este foarte disponibil, scalabil și rapid.
Kafka, care este un sistem de mesagerie în timp real, face acest lucru posibil. Fluxurile de date sunt protejate de interferențe și pot fi distribuite sau tolerante la erori. Kafka Data Integration Bus este un protocol de schimb de date care permite unei game largi de producători și consumatori să partajeze date. Capacitățile lui Kafka sunt similare cu cele ale MongoDB și RDS, care servesc ca buffer de date la sfârșitul aplicației dvs.
KSQL, un limbaj de scripting bazat pe SQL, este folosit pentru a analiza și procesa date de streaming în timp real în Apache Kafka . KSQL include un cadru interactiv pentru procesarea fluxului, care este destinat să vă permită să efectuați activități de procesare a fluxului, cum ar fi agregarea datelor, filtrarea, alăturarea, sesiunea, crearea de ferestre și așa mai departe.
Este mai mult decât un excelent broker de mesaje, așa cum a demonstrat Apache Kafka. Implementarea cadrului are o serie de caracteristici asemănătoare bazei de date care o fac potrivită pentru utilizare într-o bază de date. Ca rezultat, acum servește ca înregistrarea evenimentului de afaceri, mai degrabă decât să se bazeze pe baze de date relaționale.
Aplicația Kafka economisește timp și energie prin transmiterea datelor din MongoDB într-un mod simplu și eficient. MongoDB este necesar pentru ca întreprinderile să publice cantități mari de date altor abonați, precum și să gestioneze mai multe fluxuri de date. Serviciul Kafka MongoDB Connection le permite dezvoltatorilor să creeze mai multe fluxuri asincrone cu MongoDB, care este un instrument popular în industrie.
Într-o bază de date, Apache Kafka servește drept model. Sute de companii îl folosesc pentru a oferi garanții ACID și pentru a îndeplini sarcini critice. În majoritatea cazurilor, însă, Kafka nu este la fel de competitivă ca alte baze de date.
Ce tip de bază de date este Kafka?

Kafka este un tip de bază de date care este utilizat pentru stocarea și preluarea mesajelor. Este un sistem distribuit care este proiectat să fie scalabil și tolerant la erori.
Este o platformă open-source de procesare a fluxurilor scrisă în Scala și Java, care face parte din proiectul Kafka al Apache Software Foundation. Un flux în informatică este o colecție de elemente de informații care sunt puse la dispoziție în timp. Fluxurile pot fi definite ca articole dintr-o bandă transportoare care sunt procesate pe rând. Fluxurile, în forma lor cea mai de bază, pot fi o serie de evenimente aparent fără legătură. Conceptele de aprovizionare cu evenimente diferă de conceptele de depozitare și analiză a datelor cu care sunt obișnuiți dezvoltatorii. Cum folosesc Kafka ca bază de date? Blue este compania care spune da la înțelegere.
Potrivit Team Red, programatorii fac o mare greșeală atunci când trec de la bazele de date convenționale la Kafka. Potrivit lui Martin Kleppmann, mesajul echipei Red că Kafka este pentru toată lumea este favorizant. Problema pe care Team Red o are cu Kafka și streamuri este că au o problemă cu dezvoltatorii care aruncă RDMS-urile. Atunci când este prezentat un jurnal permanent al evenimentelor, acesta va avea întotdeauna contextul său istoric, ceea ce facilitează auditarea. Administrarea bazei de date are numeroase avantaje, dar este și unul dintre cele mai dificile aspecte ale sale. Baza de date tradițională funcționează în două moduri complet diferite: combină citirile și scrierile. Este esențial pentru programatori să mențină și să sincronizeze datele duplicate pe mai multe tabele.
Scala schimbă modelul pe măsură ce mergi. Fluxurile se disting printr-o distincție clară între preocupările cititorilor și ale scriitorilor. Nu există nicio relație între cât de repede scrie Kafka într-un fișier și cât de repede poate trimite Elastic Search actualizările acestuia. Drept urmare, utilizatorii Kafka procesează jurnalele pentru a genera diverse vederi materializate. A face ca vizualizările materializate să funcționeze ca un mecanism convenabil de stocare în cache necesită anumite costuri inițiale. Vizualizările materializate, pe lângă stocarea propriilor date și scalarea, sunt componente importante ale infrastructurii. Pentru 99% dintre companii, SGBD-urile sunt cea mai bună bază.
Aplicația dvs. poate fi în această categorie și este posibil să aveți dreptul la o arhitectură nouă, bazată pe experiența dvs. Multe caracteristici critice se vor pierde dacă înlocuiți bazele de date cu jurnalele. Caracteristicile includ constrângeri de cheie străină, tranzacții atomice (totul sau nimic) și tehnici de izolare procedurală care ajută la problemele de concurență. Arjun presupune că integritatea aplicației dvs. este menținută în orice moment. Caracteristicile de bază pe care majoritatea oamenilor le consideră de la sine înțelese devin responsabilități suplimentare pe măsură ce lucrați la fluxuri. Este esențial să se separe intenția de declarația scrisă. O configurație comună este utilizarea Kafka împreună cu un sistem Change Data Capture.
Potrivit Team Red, caracteristicile de integritate a datelor ale bazelor de date sunt esențiale pentru a obține controlul datelor. Tranzacțiile trebuie izolate de bazele de date convenționale pentru ca acestea să fie luate în considerare. Ca rezultat, o singură bucată de scris poate fi costisitoare. Dacă aplicația dvs. se luptă să facă față volumului de scrieri costisitoare, este posibil să fiți forțat să migrați la o bază de date mai convențională. Team Red nu menționează că utilizarea unei baze de date în fața lui Kafka reduce cele mai bune caracteristici ale acesteia.
Avantajele acestui design sunt semnificative față de sistemele tradiționale de mesagerie. Primul avantaj al Kafka este că poate gestiona un număr mare de solicitări. În plus, deoarece datele sunt scrise pe disc numai atunci când este necesar, Kafka poate gestiona cantități masive de date.
SQL Server este un instrument de bază de date care se încadrează în categoria instrumentelor. Acest dispozitiv portabil este versatil și de încredere, dar poate fi dificil de utilizat uneori. Kafka și Azure sunt ambele platforme extrem de capabile, dar Kafka este extins în timp ce Azure este redus.
SQL Server este un instrument excelent pentru companiile care necesită cantități mari de stocare a datelor, dar poate să nu fie cea mai bună alegere pentru cei care necesită scalare rapidă sau debit mare. Pentru companiile care trebuie să proceseze cantități mari de date fără a compromite performanța, Kafka este o alegere mai bună decât SQL Server.
Kafka: Un sistem de stocare distribuit pentru telemetria serii temporale
Un sistem de stocare distribuit Kafka, care utilizează un model bazat pe subiecte, stochează date. Datele pot fi stocate într-un model bazat pe subiect al unei baze de date Kafka, mai degrabă decât într-o bază de date relațională. Se comportă în mod similar cu o coadă dintr-un subiect Kafka , deși nu în același mod în care o face o coadă. Poate stoca un număr mare de serii temporale în cadrul Kafka, mai degrabă decât într-o bază de date pentru serii temporale.
Care este diferența dintre Kafka și Mongodb?

Este un serviciu de jurnal de comitere distribuit, partiționat și replicat care se bazează pe un sistem distribuit. În ciuda designului său unic, este o componentă importantă a unui sistem de mesagerie. MongoDB, pe de altă parte, este descrisă ca „Baza de date pentru idei gigantice”.
Deoarece Kafka nu acceptă coada de așteptare, trebuie să îl piratați într-o versiune de consum a sistemului. Dacă este necesară o bază de date relațională, un alt instrument poate fi mai util. MongoDB este o alegere excelentă pentru o varietate de motive, inclusiv ușurința în utilizare și flexibilitatea. Asistența pentru utilizatori Apache este disponibilă. Confluent are un Kafka (dacă este dispus să plătească) care a fost creat la Linkedin în același timp cu proiectul Kafka. Este extrem de convenabil să ai un furnizor care efectuează backup-uri automate și scalează clusterul în mod automat. Dacă nu aveți un administrator de sistem sau DBA care să cunoască MongoDB, este o idee bună să folosiți o terță parte care este specializată în găzduirea MongoDB.
Kafka, în forma sa cea mai de bază, este menit să ne permită să punem în coadă mesaje. Motorul de stocare al Cassandrei asigură scrierea în timp constant a datelor dvs., indiferent cât de mari devin acestea. MongoDB oferă o implementare personalizată de hartă/reducere, precum și suport nativ Hadoop pentru analiză, în timp ce Cassandra nu o face. Nu contează dacă este găzduit de dvs. sau de un alt furnizor, deoarece costul este de obicei rezonabil.
Kafka vs. Sisteme tradiționale de baze de date
Este important de reținut că există mai multe diferențe între Kafka și un sistem tradițional de baze de date.
Deoarece Kafka este o platformă de streaming, poate gestiona o rată ridicată de asimilare a datelor fără a necesita o procesare prealabilă semnificativă.
Datele sunt consumate de citirile finale, mai degrabă decât de citirile de pe disc atunci când rulați Kafka.
Utilizarea memoriei cache a paginii reduce nevoia de vizite dus-întors la bazele de date pentru Kafka.
Pentru a trimite date în aval către clienții din aval, Kafka folosește mesagerie pub/sub.
Ce este baza de date Kafka
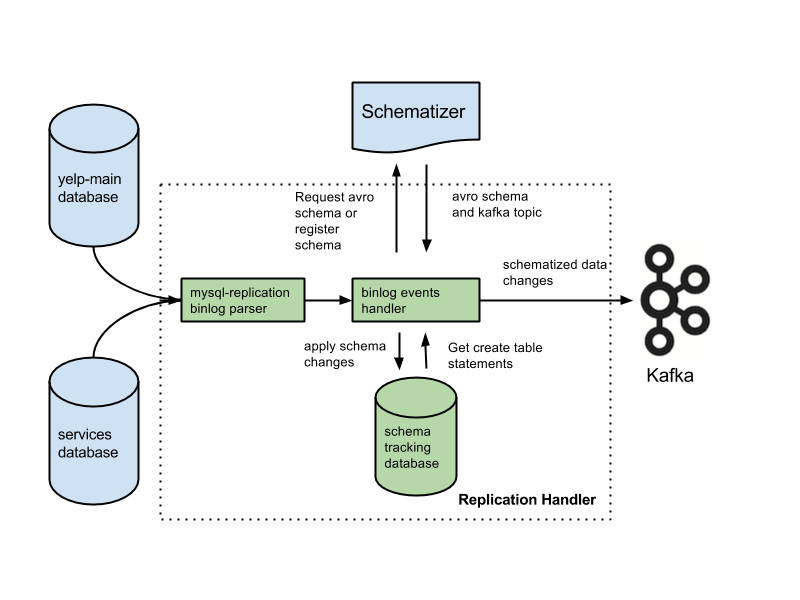
Kafka este o bază de date care este adesea folosită pentru stocarea datelor de streaming. Este un sistem distribuit care este proiectat să fie scalabil și tolerant la erori. Kafka este adesea folosit pentru a construi conducte de date în timp real și aplicații de streaming. Poate face față debitului mare și latenței scăzute.
Un broker de mesaje precum Kafka a crescut în popularitate în ultimii ani. Potrivit susținătorilor, Kafka este o schimbare de paradigmă în managementul datelor. Este esențial să rețineți că utilizarea Kafka ca depozit de date principal nu vă asigură izolarea. Fiecare problemă întâlnită de sistemele de baze de date va fi rezolvată în viitor. Hackerii pot fura date prin exploatarea defectelor din arhitecturile autonome. Dacă doi utilizatori încearcă să cumpere același articol în același timp, ambii vor reuși și vom rămâne fără inventar pentru amândoi. Aceste arhitecturi, care folosesc caracteristici de călătorie în timp atunci când rulează aparate cu gaz, se bazează pe arhitecturi bazate pe evenimente.
Gestionarea unor volume mari de date este o utilizare excelentă a Kafka. Tranzacțiile ar trebui în continuare izolate folosind un SGBD tradițional. Utilizați bazele de date OLTP pentru controlul admiterii, CDC pentru generarea de evenimente și modelați copii în aval pe măsură ce apar vizualizări, pentru a vă transforma baza de date pe dos.
Kafka poate fi folosit și pentru a stoca cantități mari de date și a le procesa zilnic. Capacitatea de a procesa date mari în modul lot sau streaming este un avantaj față de alte metode. Procesul Kafka poate fi folosit pentru a prelua fișiere jurnal de pe mai multe servere și a le stoca într-o bază de date sau într-un index de căutare, de exemplu. De asemenea, este disponibil un API de streaming care poate fi folosit pentru a procesa date în timp real.
Kafka vs Sql
În general, Kafka și MySQL sunt clasificate în două tipuri: Cozi de mesaje și Aplicații de baze de date. Majoritatea dezvoltatorilor consideră Kafka ca o soluție de mare capacitate, distribuită și scalabilă, în timp ce MySQL este văzută ca cea mai populară datorită simplității, performanței și ușurinței sale de utilizare.
Mesageria Pub-sub de pe Kafka este un sistem distribuit, tolerant la erori, de mare capacitate, care poate gestiona volume mari de date. MySQL este cea mai populară bază de date open source din lume, care este destinată utilizării în sistemele de producție critice și cu sarcini grele. Evoluțiile consideră Kafka ca fiind mai puternic decât MySQL datorită debitului său ridicat, arhitecturii distribuite și scalabilității; întrucât SQL, Free și Easy sunt motivele principale pentru care utilizatorii MySQL îl preferă. Recomand PostgreSQL dacă doriți să obțineți o experiență practică cu sistemele de gestionare a bazelor de date (DBMS). La Vital Beats, folosim în primul rând Postgres, deoarece ne permite să atingem echilibrul dorit între gestionarea eficientă a datelor și backup, susținând totuși linia de comandă. Dacă intenționați să vă găzduiți baza de date la nivel local sau în cloud, primul punct de contact este bazele de date PaaS (Platform as a Service). Deoarece MongoDB scrie datele la același nivel ca un document, coerența este dificilă fără tranzacții.
Magazinele de documente, precum cele găsite în Amazon DynamoDB și AWS RedShift, sunt foarte diferite de perechile cheie-valoare (sau depozitele de coloane) găsite în MongoDB. Este mai rapid și mai ușor de interogat folosind baza de date #Nosql, deoarece timpul de dezvoltare este redus. În calitate de angajat pentru prima dată în industria imobiliară, aș dori să selectez o bază de date care va fi foarte productivă în timp. Dacă rulați Aurora Postgres pe AWS cu o implementare într-o singură regiune, este una dintre cele mai bune platforme pe care le recomand. Dacă utilizați PostgreSQL în trei medii cloud, veți experimenta o replicare mai bună în mai multe regiuni. Dacă le configurați corect, oricare dintre aceste trei baze de date va funcționa eficient, scalabil și fiabil pe termen lung. Uber a trecut de la Postgres la MySql dintr-o varietate de motive, inclusiv necesitatea unui sistem de transmisie a datelor mai agil și mai fiabil.
Directorul de tehnologie la OPS Platform a declarat că Postgres a fost cea mai eficientă alegere pe termen lung pentru produsul lor datorită vitezei și ușurinței de utilizare. În comparație cu MySQL 7.x, tranzacțiile sunt gestionate mai rapid în MySQL 8.0. Este o bază de date mai sigură? Este posibil să schimbați cheia de criptare la întâmplare? MySQL și MongoDB sunt cele mai populare două baze de date open source. Pe lângă ușurința cu care datele pot fi stocate, MongoDB poate fi folosit pentru a stoca cantități mari de date primite prin intermediul rețelei de distribuție a conținutului (CDN). Avantajul principal al Postgres față de alte baze de date obiect-relaționale este accentul pe extensibilitate și conformarea standardelor.
Pot fi creați indici B-tree și hash obișnuiți, precum și indici de expresie și indici parțiali (cei care afectează doar o parte a tabelului). Cea mai de bază distincție între Redis și Kafka este utilizarea de către acestea a cadrelor de mesagerie pentru întreprinderi. Caut o tehnologie care este cloud-native atunci când aleg una. Pe lângă descoperirea serviciilor, NATS poate fi utilizat pentru a înlocui echilibrarea sarcinii, multiclustere globale și alte operațiuni. Singurul lucru pe care Redis nu îl face este să servească drept broker de mesaje pur (în momentul scrierii). Ca rezultat, este mai mult un magazin general de valori-cheie în memorie. În ciuda faptului că au o bibliotecă muzicală extinsă, melodiile mele durează frecvent mai mult de două ore.

Problema cu stocarea fișierelor audio într-un rând de bază de date timp de câteva ore este că nu pot fi căutate ușor. Dacă preferați, luați în considerare stocarea fișierelor audio într-un serviciu de stocare în cloud, cum ar fi Backblaze b2 sau AWS S3. Există o soluție care folosește MQTT Broker pe IoT World? Este găzduit într-unul dintre centrele de date. În prezent, îl procesăm în scopuri legate de alertă și alarmă. Scopul nostru principal este să folosim produse mai ușoare care reduc complexitatea operațională și costurile de întreținere. Ar fi ideal dacă am putea integra Apache Kafka cu aceste apeluri suplimentare API terțe.
Aplicația RabbitMQ este o alegere excelentă atât pentru reîncercare, cât și pentru coadă. Dacă nu aveți nevoie ca fiecare mesaj să fie procesat de mai mult de un utilizator, puteți utiliza RabbitMQ. Nu are sens să folosiți Kafka pentru a livra sistemul cu confirmări. Managerul de stare a evenimentelor Kafka, ca un manager de stare de eveniment persistent, vă permite să transformați și să interogați diferite surse de date folosind un API de flux. Cadrul RabbitMQ este ideal pentru un editor sau abonat (sau consumator) unu-la-unu și cred că un schimb de fanout poate fi configurat pentru a permite mai mulți consumatori. Proiectul Pushnami demonstrează cum se migrează datele live de la o bază de date la alta. Deoarece fiecare frontend (Angular), backend (Node.js) și frontend (MongoDB) este nativ, schimbul de date a fost mult mai ușor.
Pentru a evita stratul de traducere, am sărit peste porțiunea relațională cu cea ierarhică. Este esențial să păstrați o dimensiune finită în obiectele MongoDB și să folosiți indecși corecti. Încă din anii 1960, unele dintre cele mai vechi înregistrări medicale electronice (EMR) foloseau MUMPS, o bază de date orientată spre documente. MongoDB, care stochează până la 40% din toate înregistrările spitalelor, este considerată o bază de date medicală robustă. Cu toate acestea, au existat câteva metode foarte inteligente pentru a efectua interogări geografice neacceptate nativ, care este extrem de lentă pe termen lung. Amazon Kinesis procesează sute de mii de fișiere de date pe secundă din sute de mii de surse. RabbitMQ simplifică trimiterea și primirea mesajelor din orice aplicație. Apache ActiveMQ este rapid, acceptă o gamă largă de clienți multi-limbi și este un limbaj de scripting robust. Datele Hadoop sunt procesate folosind un motor de procesare rapid și de uz general numit Spark.
Kafka vs Mongodb
Mongodb este o bază de date puternică orientată spre documente, care are multe caracteristici care o fac o alegere bună pentru o varietate de aplicații. Kafka este o platformă de streaming de înaltă performanță care poate fi utilizată pentru a construi conducte de date în timp real și aplicații de streaming.
Transferurile de la MongoDB ca sursă către alte surse MongoDB sau alte surse MongoDB pot fi fără probleme cu aplicația Kafka către MongoDB. Cu ajutorul MongoDB Kafka Connector, veți învăța cum să transferați eficient datele. Cu această caracteristică, puteți crea o conductă ETL complet nouă pentru organizația dvs. Confluent oferă o varietate de conectori care acționează ca sursă și receptor, permițând utilizatorilor să transfere date între cele două. Conectorii Debezium MongoDB sunt un astfel de mecanism de conectivitate care permite utilizatorilor Kafka MongoDB să se conecteze la baza de date MongoDB. Înainte de a putea porni Confluent Kafka, trebuie mai întâi să vă asigurați că rulează pe sistemul dvs. Folosind funcționalități precum KStream, KSQL sau orice alt instrument, cum ar fi Spark Streaming, puteți analiza datele în Kafka.
Introducerea datelor în depozit necesită scripturi manuale, precum și cod personalizat. Platforma de conducte de date fără cod a Hevo vă permite să creați sisteme simple de conducte de date fără codare. Platforma transparentă de prețuri a Hevo vă permite să vedeți fiecare detaliu al cheltuielilor dvs. ELT în timp real. Perioada de probă durează 14 zile și include asistență 24×7. Criptarea end-to-end se face prin utilizarea celor mai stricte certificări de securitate. Hevo poate fi folosit pentru a transfera în siguranță datele Kafka și MongoDB în 150 de surse de date diferite (inclusiv 40 de surse gratuite).
Ce este Kafka și Mongodb?
Conectorul MongoDB Kafka este un conector verificat de Confluent care păstrează datele din subiectele Kafka ca un rezervor de date în MongoDB și publică modificările la aceste subiecte ca sursă de date.
Avantajele și dezavantajele utilizării Kafka ca bază de date
Ce bază de date este bună pentru Kafka? În principiu, Kafka poate fi folosit pentru a crea o bază de date. Rezultatul va fi o examinare a fiecărei probleme majore care a afectat sistemele de gestionare a bazelor de date de zeci de ani. Un sistem de management al bazelor de date (DBMS) este un tip de software care organizează și interogează datele. Acestea sunt necesare pentru aplicațiile la scară largă și pentru stocarea datelor care trebuie accesate de mai mulți utilizatori. Un SGBD este clasificat în două tipuri: relațional și non-relațional. Modelul relațional este o metodă standard de reprezentare a informațiilor într-un SGBD relațional. Sunt populare deoarece sunt simplu de utilizat și pot fi folosite pentru a stoca date care sunt organizate în tabele. Un SGBD care nu utilizează modele relaționale nu este la fel de puternic ca unul care utilizează alte modele. Datele sunt stocate și în alte formate decât tabelele pentru a le organiza mai eficient, cum ar fi fluxurile de date. Modelul Kafka este folosit pentru a crea o bază de date, care poate fi folosită pentru o varietate de scopuri. Procesarea fluxului este în centrul Kafka, un nou model de reprezentare a datelor. Sistemele de management al datelor (DMS) sunt o componentă crucială a managementului datelor. Cu toate acestea, utilizarea Kafka ca bază de date poate fi uneori dificilă. Unele dintre cele mai frecvente probleme pe care le întâmpină SGBD-urile sunt performanța, scalabilitatea și fiabilitatea. George Fraser, CEO Fivetran, și Arjun Narayan, CEO Materialize, au co-scris postarea.
Baza de date Kafka persistență
Bazele de date de persistență Kafka oferă o modalitate de a stoca date într-un cluster kafka într-un mod foarte disponibil și scalabil. În mod implicit, kafka va folosi o bază de date în memorie pentru a stoca date, dar aceasta nu este potrivită pentru implementările de producție. O bază de date de persistență kafka poate fi utilizată pentru a oferi o opțiune de stocare mai fiabilă pentru datele kafka.
LinkedIn a creat Apache kaffef cu sursă deschisă în 2011. Această platformă permite furnizarea datelor în timp real la o latență și un debit extrem de scăzute. În cele mai multe cazuri, datele pot fi importate și exportate prin Kafka Connect din sisteme externe. Noile soluții pot ajuta cu probleme precum performanța ineficientă a stocării și subutilizarea unităților. În ciuda provocărilor arhitecturii, flash-ul local este o alegere excelentă pentru sistemele Kafka. Deoarece fiecare subiect din Kakfa poate fi accesat doar pe o singură unitate, va exista o creștere a subutilizarii. Sincronizarea poate fi, de asemenea, dificilă, ceea ce duce la probleme de cost și eficiență.
Când un SSD eșuează, datele de pe acesta trebuie să fie complet reconstruite. Această procedură consumatoare de timp reduce performanța clusterului. Kafka este cel mai potrivit pentru stocarea bazată pe NVMe/TCP, deoarece aplatizează compromisul dintre fiabilitate și performanță.
Kafka este un sistem de mesagerie fantastic, dar nu o soluție perfectă pentru stocarea datelor
Kafka este un excelent sistem de mesagerie care poate fi folosit pentru a stoca date. Una dintre opțiunile de reținere ale lui Kafka este un timp de reținere de -1, care se referă la o reținere pe viață. Cu toate acestea, fiabilitatea lui Kafka este cu mult sub cea a unei baze de date tradiționale. Este important de reținut că Kafka stochează datele pe disc, sumă de control și sunt replicate pentru toleranță la erori, astfel încât acumularea mai multor date stocate nu o încetinește. Kafka poate fi folosit pentru a trimite și primi mesaje, dar nu este cea mai bună alegere pentru stocarea datelor.
Ce este Kafka
Kafka este un sistem de mesagerie rapid, scalabil, durabil și tolerant la erori. Kafka este folosit în producție de companii precum LinkedIn, Twitter, Netflix și Airbnb.
Kafka are un design simplu și direct. Este un sistem distribuit care rulează pe un grup de mașini și poate fi scalat pe orizontală. Kafka este conceput pentru a gestiona un randament ridicat și o latență scăzută.
Kafka este folosit pentru a construi conducte și aplicații de date în flux în timp real. Poate fi folosit pentru a procesa și agrega date în timp real. Kafka poate fi folosit și pentru procesarea evenimentelor, înregistrarea în jurnal și auditarea.
LinkedIn a lansat Kafka în 2011 pentru a gestiona fluxurile de date în timp real. Kafka este folosit astăzi de peste 80% din Fortune 100. O API Kafka Streams este o bibliotecă puternică, ușoară, proiectată pentru a permite procesarea din mers. Pe lângă bazele de date distribuite populare, Kafka include o abstractizare a unui jurnal de comitere distribuit. Spre deosebire de cozile de mesagerie, Kafka este un sistem distribuit foarte adaptabil, tolerant la erori, cu scalabilitate ridicată. De exemplu, ar putea fi folosit pentru a gestiona potrivirea pasagerilor și șoferilor la Uber sau pentru a oferi analize în timp real la British Gas. Multe microservicii se bazează pe Kafka. Serviciul Confluent nativ, complet și complet gestionat din cloud este superior celui al Kafka. Confluent simplifică construirea unei categorii complet noi de aplicații moderne, bazate pe evenimente, combinând datele istorice și în timp real într-o singură sursă unificată de adevăr.
Cu ajutorul Kinesis, puteți gestiona o gamă largă de fluxuri de date, făcându-l o platformă puternică și versatilă de procesare a fluxurilor. Este o platformă populară datorită vitezei, simplității și compatibilității cu o gamă largă de dispozitive. Datorită fiabilității sale, este una dintre cele mai populare platforme de streaming. Poate gestiona un volum mare de date fără a întâmpina probleme datorită durabilității sale. În plus, deoarece este o platformă bine-cunoscută care este utilizată și susținută pe scară largă, este simplu să găsiți un partener sau un integrator care să vă ajute să începeți cu ea. Dacă sunteți în căutarea unei platforme de streaming care este atât puternică, cât și de încredere, Kinesis este o alegere excelentă.
Kafka: Sistemul de mesagerie care înlocuiește bazele de date
Fluxurile de date în timp real pot fi adaptate la mediul de date în schimbare, folosind Kafka, un sistem de mesagerie pentru construirea conductei și aplicațiilor de date în flux în timp real. Datele mari sunt procesate prin fluxuri de evenimente în timp real prin utilizarea Kafka, care este scris în Scala și Java. O conexiune Kafka poate fi extinsă de la un punct la altul și poate fi folosită și pentru a trimite date între surse. Platforma de streaming de evenimente este destinată să ofere streaming live de evenimente. Este nedrept să comparăm bazele de date cu soluții de mesagerie precum Kafka. Datorită caracteristicilor din Kafka, bazele de date nu mai sunt necesare.
Kafka nu este o bază de date
Kafka nu este o bază de date, dar este adesea folosită împreună cu una. Este un broker de mesaje care poate fi folosit pentru a trimite mesaje între diferite componente ale unui sistem. Este adesea folosit pentru a decupla diferite părți ale unui sistem, astfel încât acestea să poată scala independent.
Este posibil să înlocuiți Apache Kafka cu o bază de date, dar nu faceți acest lucru de dragul confortului. Episodul Top Gear în care protagoniștii au primit 10.000 de dolari fiecare pentru achiziționarea unui supermașină italian uzat, cu motor central, mi-a amintit de un episod vechi Top Gear în care protagoniștii au primit 10.000 de dolari fiecare. În 2011, LinkedIn a lansat Kafka, iar acest episod a fost difuzat în același an. Vă permite să faceți minimumul de mesagerie persistentă fără a investi într-o platformă de mesagerie cu funcții complete. Premisa fundamentală este că există o regulă de bază. Creați un tabel (sau găleată, colecție, index, orice) pentru fiecare eveniment care a fost înregistrat în timpul procesului de producție. Interogați baza de date în mod regulat de la o instanță de consum, actualizând starea consumatorului pe măsură ce este procesată.
Pentru ca modelul să funcționeze corect, producătorii și consumatorii ar trebui să poată lucra concomitent. Luați în considerare utilizarea cărții lui Kafka ca ghid și stocarea înregistrărilor pe termen nelimitat, în loc să le citiți pur și simplu. Pe de altă parte, grupurile disjunse de consumatori ar putea fi implementate prin duplicarea înregistrărilor la inserare, apoi ștergerea înregistrărilor după consum. Kafka folosește compensații persistente pentru a permite ventilarea datelor definite de utilizator și pentru a sprijini mai mulți consumatori disjunși. Pentru a întrerupe această funcționalitate, trebuie să dezvoltați un serviciu de la zero. Nu este dificil să implementezi conceptul de epurare bazată pe timp, dar este necesar să găzduiești logica scavengers. Pe Kafka, există controale precise asupra tuturor actorilor (consumatori, producători și administratori).
Poate procesa milioane de înregistrări pe secundă pe serverele de mărfuri și cloud fără probleme. Kafka este optimizat pentru niveluri ridicate de producție atât la nivel de producător, cât și de consumator, într-un sens nefuncțional. Folosind Kafka, este un jurnal distribuit, numai pentru adăugare, care nu are rival în acest domeniu. Spre deosebire de brokerii tradiționali de mesaje care elimină mesajele în faza de consum, Kafka nu șterge mesajele după ce sunt consumate. Debitul și latența unei baze de date vor trebui aproape sigur îmbunătățite semnificativ prin utilizarea hardware-ului specializat și reglarea performanței foarte concentrată. Renunțarea la un broker poate fi atrăgătoare la prima vedere. Când utilizați o platformă de evenimente de streaming, cum ar fi Kafka, profitați de efortul de inginerie enorm care a fost implicat în construcția acesteia.
Pentru a vă asigura că orice soluție pe care alegeți să o implementați astăzi poate fi menținută, trebuie să fiți sigur că poate fi menținută la un standard ridicat. Majoritatea funcțiilor dintr-un magazin de evenimente pot fi implementate numai prin utilizarea unei baze de date. Nu există un magazin de evenimente universal; orice magazin de evenimente non-trivial, în cele mai multe cazuri, este aproape sigur o implementare personalizată susținută de una sau mai multe baze de date disponibile. Puteți utiliza baze de date în domeniul organizării datelor pentru o regăsire eficientă, dar ar trebui să evitați să le folosiți pentru a distribui date (aproape) în timp real.