
MapReduce: Un model de programare pentru seturi mari de date
Publicat: 2023-01-08MapReduce este un model de programare și o implementare asociată pentru procesarea și generarea de seturi mari de date cu un algoritm paralel, distribuit pe un cluster.
Transformăm modul în care lucrăm cu cantități masive de date folosind noile tehnologii. Depozitele de date, cum ar fi Hadoop, NoSQL și Spark, sunt unii dintre cei mai importanți jucători din domeniu. DBA și inginerii/dezvoltatorii de infrastructură se numără printre noua generație de profesioniști care se specializează în gestionarea sistemelor cu un nivel ridicat de sofisticare. În loc de o bază de date, Hadoop este un ecosistem software care permite calculul paralel sub formă de fișiere masive. Această tehnologie a oferit beneficii semnificative în ceea ce privește susținerea nevoilor masive de procesare a datelor mari. Pentru o tranzacție mare de date, clusterul Hadoop mediu poate dura doar trei minute pentru a procesa o tranzacție mare care ar dura de obicei 20 de ore într-un sistem de baze de date relaționale centralizate.
Un cluster mapreduce este un cluster cu un algoritm paralel și un model de programare care procesează și generează seturi mari de date în același mod ca un cluster normal.
Ecosistemul Apache Hadoop este conceput pentru a sprijini calcularea distribuită și oferă un mediu de încredere, scalabil și gata de utilizare. Modulul MapReduce al acestui proiect este un model de programare folosit pentru a procesa seturi uriașe de date care se află pe Hadoop (un sistem de fișiere distribuit).
Acest modul este o componentă a ecosistemului open source Apache Hadoop și este utilizat pentru a interoga și selecta date în sistemul de fișiere distribuit Hadoop (HDFS). Datele pot fi selectate pentru o varietate de interogări folosind un algoritm MapReduce care este disponibil în scopul efectuării unor astfel de selecții.
Folosind MapReduce, este posibil să rulați sarcini mari de procesare a datelor. Puteți construi programe MapReduce în orice limbaj de programare, inclusiv C, Ruby, Java, Python și altele. Aceste programe pot fi folosite concomitent pentru a rula programe MapReduce, făcându-le foarte utile în analiza datelor la scară largă.
Pentru ce este folosit Mapreduce în Mongodb?
Hărțile din MongoDB sunt un model de programare a procesării datelor care le permite utilizatorilor să realizeze seturi mari de date și să genereze rezultate agregate din acestea. MapReduce este metoda folosită de MongoDB pentru a reduce hărțile. Această funcție este împărțită în două componente: o funcție de hartă și o funcție de reducere.
Folosind instrumentul MapReduce de la MongoDB, este posibil să organizați și să agregați seturi mari de date. Această comandă, în MongoDB, folosește cele două intrări primare din MongoDB: funcția map și funcția reduce, pentru a procesa o cantitate mare de date. Pentru exemple definitorii, urmați pașii de mai jos. Vom defini funcția map, funcția reduce și exemplele.
MapReduce va compara șirurile de caractere pentru a sorta rezultatul utilizând metoda de sortare implicită, indiferent dacă utilizați metoda implicită sau nu. Pentru a schimba modul în care sunt sortate datele, trebuie mai întâi să creați un algoritm de sortare și apoi să-l implementați folosind clasa mapper.
SpiderMonkey este un motor JavaScript utilizat pe scară largă. Este bun pentru aplicații la scară mică, dar are unele limitări. SpiderMonkey nu are un algoritm de sortare, de exemplu. Ca urmare, dacă doriți să utilizați Mapmapper pentru a sorta datele, trebuie mai întâi să vă creați propriul algoritm de sortare și să-l implementați în clasa Reduce.
În ciuda popularității sale, SpiderMonkey nu folosește un algoritm de sortare. Există și alte limitări pentru SpiderMonkey, dar aceasta este notabilă. SpiderMonkey, de exemplu, nu are un colector de gunoi bun, așa că dacă programul dvs. începe să încetinească, poate fi necesar să luați unele măsuri pentru a-l face mai rapid.
De ce să folosiți o funcție Mapreduce?
O funcție MapReduce poate fi utilă într-o varietate de situații. Această metodă poate fi utilizată pentru procesarea datelor în lot în unele cazuri. De asemenea, este util dacă aveți nevoie de o cantitate mare de date care să fie gestionată de o singură aplicație sau proces. O funcție MapReduce poate fi, de asemenea, utilizată pentru a procesa date care sunt răspândite pe mai multe noduri într-un sistem distribuit. Prin utilizarea funcției MapReduce, datele de la noduri pot fi combinate într-o singură ieșire. O aplicație MapReduce este utilizată de obicei pentru a procesa cantități mari de date, deși poate fi necesară pentru a gestiona cantități foarte mari.
De ce se numește Mapreduce?
Există câteva teorii despre motivul pentru care se numește MapReduce. Unul este că este un joc de cuvinte, deoarece algoritmii de reducere a hărții implică împărțirea unei probleme în bucăți mai mici (cartare), apoi rezolvarea acelor piese și repunerea lor împreună (reducerea). O altă teorie este că este o referire la o lucrare scrisă de angajații Google în 2004, numită „MapReduce: Procesarea simplificată a datelor pe clustere mari”. În lucrare, autorii folosesc termenul „hartă” și „reduce” pentru a descrie cele două faze principale ale modelului lor de procesare propus.
Cu toate acestea, este important de reținut că modelul MapReduce este utilizat doar pe o bază limitată. Nu este potrivit pentru seturi mari de date și trebuie să fie paralelizat pentru a funcționa corect. Când vine vorba de abordarea acestor probleme, Apache Spark are o alternativă puternică la MapReduce. Sistemul de calcul cluster Spark se bazează pe Hadoop și funcționează ca o platformă de calcul de uz general. Acest instrument poate fi folosit pentru a accelera sarcinile tradiționale de analiză a datelor, cum ar fi data mining și învățarea automată, precum și sarcini mai complexe de procesare a datelor, cum ar fi depozitarea datelor și analiza datelor mari. Acest software este construit folosind Erlang, un limbaj de programare care este atât scalabil, cât și tolerant la erori. Poate gestiona cantități mari de date și poate fi rulat pe mai multe mașini în același timp. În plus, Spark folosește paralelismul, permițând mai multor noduri să îndeplinească aceeași sarcină în același timp. În general, are potențialul de a automatiza sarcinile de analiză a datelor la scară largă și de a le face mai scalabile. Dacă aveți nevoie să vă paralelizați procesarea și să gestionați seturi mari de date, este o alternativă excelentă la MapReduce.
Care este diferența dintre Mapreduce și agregare?
Când lucrați cu Big Data, mapreduce este o metodă importantă pentru extragerea datelor dintr-o cantitate mare de date. MongoDB 2.2, de acum, include noul cadru de agregare. În ceea ce privește funcționalitatea, agregarea este similară cu mapreduce, dar pe hârtie, pare a fi mai rapidă.
În acest scenariu, MongoDB Aggregation și MapReduce sunt rulate pe containere Docker într-o configurare Sharded. Performanța conductei agregatorului este superioară mapreduce, deoarece permite o navigare mai rapidă și mai ușoară. Iată cum funcționează problema: tweet numără pronumele suedezi precum „den,” „denne”, „denna”, „det”, „han”, „hon” și „hen” (sensibil la majuscule și minuscule) într-un hashtag Twitter. Câte handle de twitter are un utilizator? Peste 4 milioane de tweet-uri au fost trimise. În acest experiment, vom crea mai întâi o bază de date MongoDB și vom activa sharding. Fluxurile Twitter au fost importate în baza de date și au fost executate interogări folosind MapReduce și Aggregation Pipeline.
Mapreduce: Instrumentul suprem de agregare a datelor
Un program mapReduce citește o listă de documente dintr-o colecție și le procesează folosind un set de funcții predefinite. Operația mapReduce generează un flux de documente gata de procesare care vor fi procesate în etapa de reducere. Este posibilă combinarea hărților reducere și agregare într-o varietate de situații. Operatorul de agregare $group este un instrument care poate fi folosit pentru a grupa documente într-un singur câmp. Când mai multe documente sunt îmbinate folosind operatorul de agregare $merge, poate fi creat un nou document. Operatorul de agregare $accumulator poate fi folosit pentru a reprezenta rezultatele mai multor operațiuni de reducere a hărții într-un singur document.
Mapreduce în Mongodb
Mongodb mapreduce este o tehnologie de procesare a datelor pentru seturi mari de date. Este un instrument puternic pentru analiza datelor și oferă o modalitate de procesare și agregare a datelor în mod paralel și distribuit. MapReduce a fost utilizat pe scară largă pentru analiza datelor într-o varietate de domenii, inclusiv analiza traficului web, analiza jurnalelor și analiza rețelelor sociale.

Când utilizați comanda mapReduce , puteți rula operațiuni de agregare map-reduce pe o colecție. Funcția de hartă poate converti orice document în zero sau în multe altele. În versiunile MongoDB care variază de la 4.2 până la anterioare, fiecare emisie poate conține doar jumătate din dimensiunea maximă a documentului BSON. Codul JavaScript de tip BSON depreciat folosit în MapReduce nu mai este acceptat, iar codul nu mai poate fi utilizat pentru funcțiile sale. MongoDB 4.4 nu mai include acum codul JavaScript de tip BSON depreciat cu domeniul de aplicare (BSON tip 15). Parametrul scope specifică ce variabile pot fi accesate de funcția reduce. Pentru a reduce intrările, MongoDB limitează dimensiunea documentului BSON la jumătate din dimensiunea maximă.
Documentele mari returnate la server pot fi returnate și apoi îmbinate în reduceri ulterioare, potențial încălcând cerința. MongoDB 4.2 este cea mai recentă versiune. Această opțiune poate fi folosită pentru a crea o nouă colecție fragmentată, precum și pentru a reduce harta pentru a crea o nouă colecție cu același nume de colecție. Funcția finalize primește ca argumente o valoare cheie și valoarea redusă de la funcția reduce. Există trei opțiuni pentru configurarea parametrului out. Această opțiune, pe lângă crearea unei noi colecții, nu funcționează pe membrii secundari ai seturilor de replici. NonAtomic: opțiunea false poate fi furnizată numai dacă colecția există deja pentru a trece și are specificația explicită.
Utilizarea funcției de reducere atât pe documentul nou, cât și pe cel existent rezultă dacă cheia de pe noul document este aceeași cu cheia de pe documentul existent. O reducere a hărții nu funcționează atunci când collectionName este o colecție existentă neharded care a fost configurată. În acest caz, MongoDB este împiedicat să-și blocheze baza de date dacă nonAtomic este adevărat. Numai membrii secundari ai seturilor de replici care folosesc această opțiune pot fi în afara setului. Nu sunt necesare funcții personalizate pentru a rescrie operația de reducere a hărții. Cust_id este folosit pentru a calcula câmpul de valoare al grupului $group stage prin metoda cust_id. Etapa $merge combină rezultatele etapei $merge în colecția de ieșiri folosind operatorii pipeline de agregare disponibili.
Ca exemplu, etapa $out poate fi folosită pentru a scrie rezultatul colecției agg_alternative_1. Fiecare document de intrare poate fi procesat cu funcția de hartă. Fiecare articol din comandă este asociat cu o nouă valoare a obiectului care conține atât numărul de 1, cât și cantitatea de articole din comandă. În reducedVal, câmpul count reprezintă suma câmpurilor count generate de elementele matricei. Dacă funcția finalize modifică obiectul reducedVal pentru a include un câmp calculat numit avg, obiectul modificat este returnat utilizatorului. Etapa $unwind descompune documentul într-un document pentru fiecare element de matrice folosind câmpul de matrice itemi. Etapa $project remodelează documentul de ieșire pentru a oglindi rezultatul mapreduce prin includerea a două câmpuri -id și value.
Este suprascrie documentul existent dacă nu există un document existent cu aceeași cheie ca noul rezultat. Dacă specificați parametrul out, mapReduce returnează un document ca rezultat în următorul format dacă doriți să scrieți rezultate într-o colecție. O matrice de documente rezultate este returnată dacă rezultatul este scris în linie. Fiecare document conține două câmpuri: numele documentului sursă și numele documentului destinatar. Când valoarea cheii este introdusă în câmpul -id, este creat un câmp de valoare pentru reducerea sau finalizarea valorilor pentru cheie.
Ce este Emit în Mongodb?
Ca funcție de hartă, funcția de hartă poate apela emisii (cheie, valoare) în orice moment pentru a genera un document de ieșire care include cheia și valoarea. O singură emisiune în MongoDB 4.2 și versiunile anterioare poate conține doar jumătate din dimensiunea maximă a fișierelor BSON MongoDB. Începând cu versiunea 4.4 a MongoDB, restricția este eliminată.
De ce Mongodb este cea mai bună alegere pentru date flexibile și scalabile
Din cauza lipsei unei scheme rigide, MongoDB este frecvent asociat cu NoSQL. Din cauza lipsei schemei rigide, datele pot fi stocate în orice format care este convenabil pentru aplicație. Flexibilitatea bazei de date oferă un avantaj important atunci când o scalați în sus sau în jos, deoarece înseamnă că datele pot fi stocate într-un mod care este adaptat nevoilor aplicației.
O diagramă de date cu diagrame ER poate fi utilizată pentru a vizualiza relațiile dintre diferitele date. Diagrama ER ilustrează o serie de noduri reprezentând o colecție de date, iar conexiunile dintre ele servesc drept identificator.
Relațiile nu sunt impuse în MongoDB deoarece nu este o bază de date relațională. Diagrama ER ilustrează relațiile care există în cadrul datelor și, de asemenea, ajută la vizualizarea acestora.
MongoDB este o alegere excelentă pentru date flexibile și scalabile. Flexibilitatea sa îi permite să stocheze date într-un mod care are sens pentru o aplicație, iar scalabilitatea îi permite să gestioneze seturi mari de date rapid și ușor.
Exemplu Mongodb de reducere a hărții
În MongoDB, map-reduce este o paradigmă de procesare a datelor pentru agregarea datelor din colecții. Este similar cu harta și reduce funcțiile în programarea funcțională.
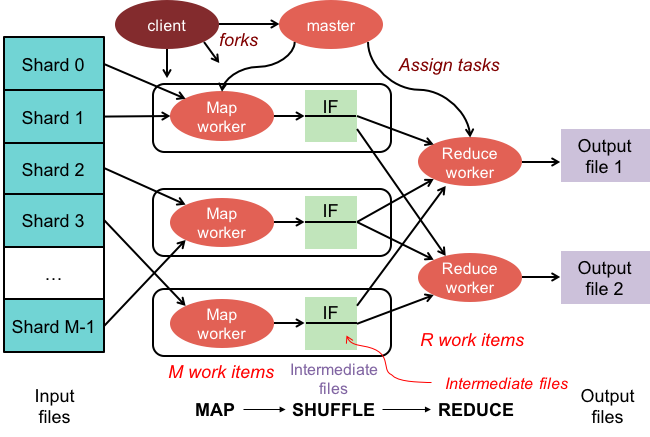
Operațiunile de reducere a hărții au două faze:
1. Faza hărții aplică o funcție de mapare fiecărui document din colecție. Funcția de mapare emite unul sau mai multe obiecte pentru fiecare document de intrare.
2. Faza de reducere aplică o funcție de reducere documentelor emise de faza de hartă. Funcția reduce agregează obiectele și produce un singur obiect ca ieșire.
De exemplu, luați în considerare o colecție de articole. Putem folosi map-reduce pentru a calcula numărul de cuvinte din fiecare articol.
În primul rând, definim o funcție de mapare care emite o pereche cheie-valoare pentru fiecare document, unde cheia este id-ul articolului și valoarea este numărul de cuvinte din articol.
În continuare, definim o funcție de reducere care însumează valorile pentru fiecare cheie.
În cele din urmă, executăm operația de reducere a hărții pe colecție. Rezultatul este un document care conține datele agregate.
În mongosh, există o bază de date. Metoda mapReduce() este un înveliș în jurul comenzii mapReduce. Sunt furnizate mai multe exemple în această secțiune, cum ar fi o alternativă a conductei de agregare fără o expresie de agregare personalizată. Hărțile pot fi traduse cu expresii personalizate utilizând Exemple de traducere Map-Reduce la Aggregation Pipeline. Operația de reducere a hărții poate fi modificată fără a fi nevoie să definiți funcții personalizate folosind operatorii de conducte de agregare disponibili. Funcția de hartă poate fi utilizată pentru a procesa fiecare document din intrare. Fiecare articol are propria sa valoare de obiect asociată cu o nouă valoare care conține numărul 1, numărul de cantitate pentru comandă și o listă de articole.
Dacă cheia din documentul curent este aceeași cu cheia din noul document, operația suprascrie acel document. Puteți rescrie operația de reducere a hărții utilizând operatori de conducte de agregare, în loc să definiți funcții personalizate. Etapa $unwind descompune documentul după câmpul matrice de elemente, rezultând un document pentru fiecare element de matrice. Când etapa $project remodelează documentul de ieșire, rezultatul de reducere a hărții este oglindit. O operație suprascrie un document existent care are aceeași cheie cu noul rezultat.
Ce este funcția Mapper în Hadoop?
Ca reductor, trebuie să combinați datele din cartografii pentru a genera un răspuns unificat. Ieșirea de reducere este produsă atunci când un set de ieșiri ale hărții sunt acceptate ca intrare, fiecare dintre acestea reprezentând un subset al rezultatului generat.
Maperii sunt folosiți pentru a împărți datele în bucăți gestionabile, apoi alocați fiecare bucată unei sarcini în funcție de dimensiunea acesteia. Datele de intrare sunt primite de funcția de cartografiere, unde există parametrii care indică sarcina de efectuat.
O serie de elemente corespunde bucăților de date care au fost mapate de către mapper în ieșire. Ca rezultat, ieșirea hărții este redirecționată către reductor, care o transformă într-o ieșire de reducere.
Erorile sunt gestionate și de funcția de cartografiere. Un mapator va returna o ieșire de eroare în acest caz, care nu este o ieșire de hartă. Deoarece reductorul nu poate procesa aceste date, mapatorul va returna un mesaj de eroare.
Ecosistemul Hadoop
Ecosistemul Hadoop este o platformă pentru procesarea și stocarea datelor mari. Este format dintr-un număr de componente, fiecare având un rol specific în procesarea și stocarea datelor. Cele mai importante componente ale ecosistemului sunt Hadoop Distributed File System (HDFS), cadrul MapReduce și biblioteca Hadoop Common .