
Baza de date NoSQL: Impala
Publicat: 2023-03-03NoSQL este un termen folosit pentru a descrie o bază de date care nu utilizează structura tradițională a bazei de date relaționale. În schimb, bazele de date NoSQL sunt adesea concepute pentru a oferi o soluție mai simplă, mai scalabilă.
Impala este o bază de date NoSQL care a fost concepută pentru a oferi o soluție rapidă și scalabilă pentru gestionarea seturilor mari de date. Impala se bazează pe modelul de date Google Bigtable și folosește un format de stocare în coloană. Impala este disponibil ca proiect open source și este susținut de Cloudera.
Apache Impala este un motor de interogare SQL open source care este instalat pe un cluster Hadoop și efectuează procesare paralelă masivă (MPP) pentru datele stocate în sistem. Dezvoltat inițial în 2012, proiectul open-source este cunoscut sub numele de „Microsoft Formula 1”.
Platforma Impala permite utilizatorilor să efectueze interogări SQL cu latență scăzută la datele Hadoop stocate în HDFS și Apache HBase fără a fi nevoiți să mute sau să transforme datele.
Este Impala Sql bazat?
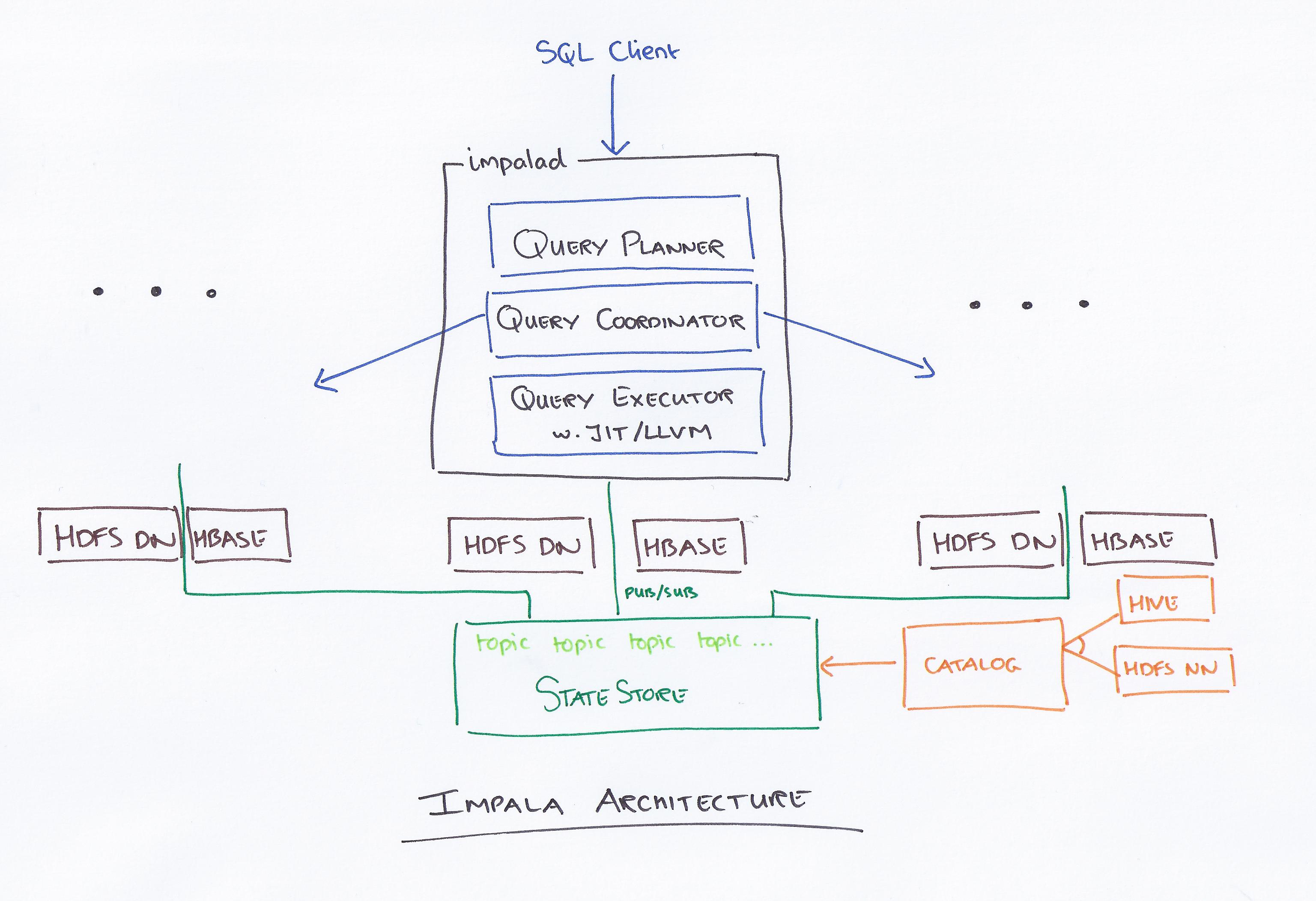
Impala este un motor de interogare bazat pe SQL care rulează pe Apache Hadoop. Permite utilizatorilor să interogheze datele stocate în HDFS și HBase folosind SQL. Impala oferă performanță ridicată și latență scăzută în comparație cu alte motoare de interogare Hadoop, cum ar fi Hive și Pig.
Baza de date analitică Impala MPP oferă cel mai rapid timp până la perspectivă din industrie. Este integrat cu CDH și poate fi accesat prin Cloudera Enterprise. Bazele de date MPP pentru Apache Hadoop, cum ar fi Impala, folosesc HDFS pentru a oferi o perspectivă mai rapidă.
Impala este o bază de date
Este o bază de date în care cred.
Impala este un instrument Etl?
Impala nu este un instrument ETL, este un motor de interogări SQL care poate fi folosit pentru a efectua interogări SQL după ce datele au fost curățate printr-un proces.
Pentru ce este folosit Apache Impala?
Folosind interogări asemănătoare SQL, putem citi date dintr-o varietate de surse folosind Impala. Apache Impala are performanțe mai bune decât Hive și alte motoare SQL când vine vorba de acces la datele stocate în sistemul de fișiere distribuit Hadoop . Folosim Impala pentru a stoca date în Hadoop HBase, HDFS și Amazon S3.
19 companii care folosesc Apache Impala în stack-urile lor tehnice
Apache Impala este un motor popular de procesare a datelor pentru o varietate de companii mari. Potrivit rapoartelor, 19 companii de tehnologie, inclusiv Stripe, Agoda și Expedia.com, folosesc Apache Impala. Platforma Impala este flexibilă și eficientă, capabilă să gestioneze seturi mari de date rapid și eficient. Utilizarea pe scară largă a acestui instrument demonstrează cât de util este și cât de util este în procesarea datelor.
Care sunt diferențele dintre Sql Hive și Impala?
Scopul lui Hive este de a gestiona interogări de lungă durată care necesită transformări și îmbinări multiple. Datorită latenței scăzute și a capacității de a gestiona interogări mai mici, motorul de procesare a interogărilor Impala este ideal pentru calculul interactiv. Spark acceptă atât interogări pe termen scurt, cât și pe termen lung, pe lângă interogările pe termen scurt și lung.
Hive este mai potrivit pentru lucrări pe lot de lungă durată
Scopul principal al instrumentelor nu este procesarea loturilor. Hive este mai potrivit pentru lucrul pe loturi pe termen lung decât Impulsa, care poate gestiona seturi de date mai mici.
Impala este o bază de date
Un impala este o bază de date care stochează date într-un format de coloană. Este conceput pentru a fi scalabil și pentru a oferi performanțe ridicate pentru seturi mari de date.
În versiunea inițială Impala, sunt acceptate următoarele tipuri de date de coloană de bază: STRING, VARCHAR, VARCHar2, INT și FLOAT, mai degrabă decât număr, și nu este acceptat niciun tip BLOB. Impala SQL-92 include unele îmbunătățiri ale standardelor SQL, dar nu le încorporează pe toate. Atunci când datele sunt prea mari pentru a fi produse, manipulate și analizate pe un singur server, Impala are performanțe mai bune decât alte depozite de date și are o scalabilitate mai mare. Nu este nevoie să eliminați locația originală a fișierelor de date atunci când încărcați Impala, deoarece este ușor. Primul pas în învățarea despre testarea performanței, scalabilitatea și configurațiile cluster-ului cu mai multe noduri este de obicei adunarea unor cantități mari de date. Cloudera Impala este optimizat pentru încărcarea datelor și citirea în bloc în seturi mari de date, permițându-vă să faceți mai mult cu mai puțin. Dimensiunea blocului de multimegabyte a HDFS îi permite lui Impala să proceseze cantități masive de date în paralel pe mai multe servere din rețea.
În loc să planificați indici normalizați și timpul și efortul necesar pentru a le crea, o veți face în Impala. Motorul de interogări Impala poate gestiona cantități mari de date care provin din depozitele de date. Analizează un cluster și distribuie sarcini între noduri pentru a reduce cantitatea de resurse consumate. Partiționarea unui depozit de date este un concept familiar în Impala. Partiționarea reduce I/O pe disc și crește scalabilitatea interogărilor în Impala. Fișierele de date sunt necesare deoarece nu veți putea accesa niciun tabel încorporat în Impala. INSERT este una dintre opțiunile disponibile.
Pentru a construi două mese de jucărie, utilizați o declarație de valoare. Dacă ați folosit software orientat pe loturi, îl puteți încerca. Puteți încorpora tehnologia SQL-on-hadoop în configurația Apache Hive. Tabelele Hive din Impala nu sunt încărcate sau convertite într-un mod consumator de timp.
Impala: un instrument puternic de gestionare a datelor pentru Hadoop
Sintaxa SQL este familiară utilizatorilor Impala, care pot interoga datele stocate în HDFS și Apache HBase. În acest fel, Hadoop și Impulsa pot fi utilizate mai degrabă decât bazele de date relaționale tradiționale . În plus, este un instrument puternic de gestionare a datelor datorită caracteristicilor sale. În plus, capacitățile sale pentru seturi mari de date sunt impresionante și le poate gestiona cu mare ușurință.
Impala în Big Data
Impala este un motor de interogare SQL MPP cu sursă deschisă, care rulează pe Apache Hadoop. Oferă interogări SQL rapide și interactive asupra datelor stocate în HDFS și HBase. Impala este proiectat pentru a îmbunătăți performanța Apache Hadoop, oferind o interfață SQL rapidă și interactivă pentru datele stocate în HDFS și HBase.
Impala, condus de Cloudera, este un nou sistem de interogare. Hadoop are HDFS și HBase, astfel încât poate interoga datele mari la nivel PB stocate acolo. Această tehnologie se bazează pe stup și memorie pentru calcul, precum și ținând cont de depozitul de date și oferă procesare lot în timp real și procesare simultană multiplă. Un client trimite o cerere de interogare către un nod dintr-o rețea impalad, unde un ID de interogare este returnat pentru operațiunile ulterioare ale clientului. În timpul primului pas al procesului de creare a analizorului, este generat un plan de execuție de sine stătător (plan unic de mașină, plan de execuție distribuit) și va fi, de asemenea, executat SQL, cum ar fi modificări de ordine de unire, împingere predicate și așa mai departe. Toate nodurile păstrează o copie a celor mai recente informații despre metadate pentru a vă asigura că nu sunteți lăsat în afara buclei. Înainte de a utiliza Hadoop, Hive sau Impurbia, trebuie mai întâi să instalați software-ul necesar de procesare a datelor.

Fișierul de configurare al lui Impala poate fi schimbat. Fiecare nod efectuează o schimbare de configurație în Impala. Toate nodurile sunt responsabile pentru conectarea pachetului de driver MySQL la o bază de date. Nodurile schimbă calea Java a lui Bigtop.
O comparație între stup și impala
Există și câteva diferențe minore, pe lângă aceste trei majore. În Hive, există un subset de HiveQL, în timp ce în Implicit, există un subset de HiveQL. Hive și Impala sunt folosite pentru depozitarea datelor și, respectiv, interogare interactivă. Hive, spre deosebire de Impala, nu este destinat calculului interactiv.
Ce este Impala în Hadoop
Impala este un motor de interogare SQL open source pentru datele stocate într-un cluster Hadoop. Este conceput pentru a oferi interogări SQL rapide și interactive asupra datelor stocate în HDFS, HBase sau orice altă sursă de date Hadoop .
Impala folosește o gamă largă de componente Hadoop familiare . INSERT poate scrie doar date care sunt de tipul pe care Impala le poate citi, în timp ce SELECT poate citi date care sunt de tipul pe care Impala le poate citi. Când utilizați un format de fișier Avro, RCFile sau SequenceFile, datele sunt încărcate în Hive. Statisticile de tabel și statisticile de coloană pot fi utilizate în plus față de statisticile de tabel și coloană. Toate instrucțiunile DDL și DML sunt actualizate automat folosind demonul catalogat din Impala 1.2 și versiuni ulterioare dacă sunt trimise prin demonul catalogat. Metoda INVALIDATE METADATA returnează metadate pentru toate tabelele din metamagazin care au fost accesate. Fișierele de date sunt stocate în directoare pentru un nou tabel și sunt citite indiferent de numele fișierului atunci când Impala rulează.
În general, Apache Hive funcționează bine ca platformă de depozitare a datelor, în timp ce Impala este mai potrivit pentru procesarea paralelă. Stupul este tolerant la greșeli, în timp ce Impulsa nu este.
Apache Impala
Apache Impala este un motor de interogare SQL rapid și interactiv pentru Apache Hadoop. Permite utilizatorilor să emită interogări SQL cu latență scăzută pentru datele stocate în HDFS și Apache HBase fără a necesita mutarea sau transformarea datelor.
Conceptul de arhitectură Impala îi permite să gestioneze interogări interactive folosind HDFS mai eficient decât orice alt motor de interogare. Hive este mult mai lent datorită operațiunilor sale I/O pe disc, dar Apache este mult mai rapid, deoarece este un motor complet diferit. Nu există nicio distincție între Impulsa și Presto, deoarece Impulsa folosește o tehnologie mult mai rapidă, iar Presto folosește o arhitectură similară. Când vine vorba de fișiere cu parchet, Impala are cele mai bune performanțe. Stabiliți ce date ar trebui să partiți pe baza interogărilor analiștilor dvs. Cu statistici Compute Statistics, interogările dvs. vor fi mult mai ușoare, mai ales dacă implică mai multe tabele (asocieri). Am avut o blocare a serverului de catalog Impala de patru ori pe săptămână, iar interogările noastre au durat mult prea mult pentru a fi finalizate.
În plus, cantitatea de fișiere pe care le creăm afectează foarte mult performanța interogărilor noastre. Ca rezultat, am început să ne gestionăm partițiile și să le îmbinam în dimensiunea optimă a fișierului de aproximativ 256 MB. Se afirmă că fiecare partiție are un singur fișier (cu excepția cazului în care dimensiunea sa este > 256MB). Cel mai potrivit tip de coloană ar trebui să fie ales dintre toate tipurile de date acceptate de Implicit. Pentru a limita numărul de interogări simultane sau de memorie Y accesată de un utilizator, utilizați Controlul de admitere Impala. Dacă o interogare durează mai mult de 30 de minute, este considerată moartă.
Cel mai bun motor pentru Big Data: Impala
Motorul Impala este un motor de procesare a datelor Hadoop conceput special pentru clustere mari. Utilizează mult mai puțină energie și consumă mult mai puține resurse decât motorul standard MapReduce al Hadoop. Implicit folosește sistemul de fișiere distribuit HDFS ca mediu principal de stocare a datelor, bazându-se pe redundanța HDFS pentru a preveni întreruperile hardware sau rețelei nod cu nod. Fișierele de date care reprezintă date de tabel sunt reprezentate fizic de formate de fișiere HDFS familiare și codecuri de compresie.
Motor de interogări de procesare paralelă
Un motor de interogări de procesare paralelă este un tip de motor de bază de date conceput pentru a procesa interogări în paralel. Acest lucru se poate face folosind mai multe procesoare, mai multe nuclee sau mai multe mașini. Procesarea în paralel poate îmbunătăți considerabil performanța unui motor de interogări, în special pentru interogările complexe.
Un computer multiprocesor este folosit pentru a transforma interogări complexe în planuri de execuție care pot fi executate concomitent, permițându-i să proceseze cantități mari de date simultan. Pentru o performanță ridicată este necesară o execuție eficientă, cum ar fi un timp bun de răspuns la interogare sau un debit mare de interogare. Se realizează prin utilizarea unor tehnici eficiente de execuție paralelă și optimizarea interogărilor.
Procesare paralelă: viitorul Etl?
O interogare de nivel înalt poate fi transformată într-un plan de execuție care poate fi executat eficient de un computer multiprocesor utilizând procesarea paralelă a interogărilor. Procesarea paralelă folosește tehnica combinării datelor paralele și distribuite, precum și diferitele tehnici de execuție oferite de sistemul de baze de date paralele . Procesarea paralelă a interogărilor este implementată în ETL prin împărțirea setului de înregistrări din fiecare tabel sursă atribuit transferului în bucăți de aceeași dimensiune, apoi efectuând procesul de transformare a datelor pentru fiecare tabel sursă într-un ciclu, selectând datele consecutiv, bucată cu bucată .