
Baze de date NoSQL: Big Table
Publicat: 2023-01-04Bazele de date NoSQL devin din ce în ce mai populare datorită flexibilității, scalabilității și performanței lor. O bază de date NoSQL nu necesită o schemă predefinită și poate stoca date în orice format. Acest lucru îl face ideal pentru aplicațiile care trebuie să stocheze cantități mari de date care se schimbă constant. Big Table este un tip de bază de date NoSQL care este concepută pentru a stoca cantități mari de date. Masa mare este folosită de multe organizații mari, cum ar fi Google, Facebook și Amazon. Tabelul mare este foarte scalabil și poate gestiona miliarde de rânduri și milioane de coloane. Masa mare este, de asemenea, foarte rapidă și poate oferi acces în timp real la date.
Google a lansat o serie de actualizări disponibile în general pentru serviciul său de baze de date Cloud Bigtable . Ca urmare a noilor actualizări, este acum disponibil până la cinci ori mai mult spațiu de stocare per nod. Google a adăugat, de asemenea, capabilități îmbunătățite de autoscaling care permit unui cluster de baze de date să crească sau să se micșoreze automat în funcție de nevoile sale. O nouă măsurătoare de utilizare a procesorului și rutarea grupului de clustere permit o mai mare vizibilitate asupra modului în care sunt utilizate resursele unei aplicații. Datorită separării de calcul și stocare, fiecare tip de resursă poate fi scalat singur la Bigtable. Utilizatorii pot acum gestiona cu ușurință implementările cu disponibilitate ridicată și pot îmbunătăți gestionarea volumului de lucru datorită noilor capabilități.
NoSQL este o alegere populară pentru stocarea unor cantități mari de date. Acest tip de bază de date devine din ce în ce mai popular în rândul companiilor web astăzi. Susținătorii soluțiilor NoSQL spun că acestea oferă o scalabilitate mai simplă și o performanță crescută decât bazele de date tradiționale.
Bigtable este un tip de serviciu de baze de date NoSQL care poate fi utilizat atât de dezvoltatori, cât și de administratorii de baze de date. BigQuery este un hibrid, deoarece folosește dialecte SQL și se bazează pe tehnologia de procesare a datelor Google, Dremel.
Este Bigtable Sql sau Nosql?
Nu există un răspuns definitiv la această întrebare, deoarece depinde de modul în care definiți fiecare termen. Cu toate acestea, dacă luăm o definiție largă a SQL ca orice bază de date care utilizează un limbaj de interogare structurat și NoSQL ca orice bază de date care nu utilizează un limbaj de interogare structurat, atunci Bigtable ar fi considerată o bază de date NoSQL.
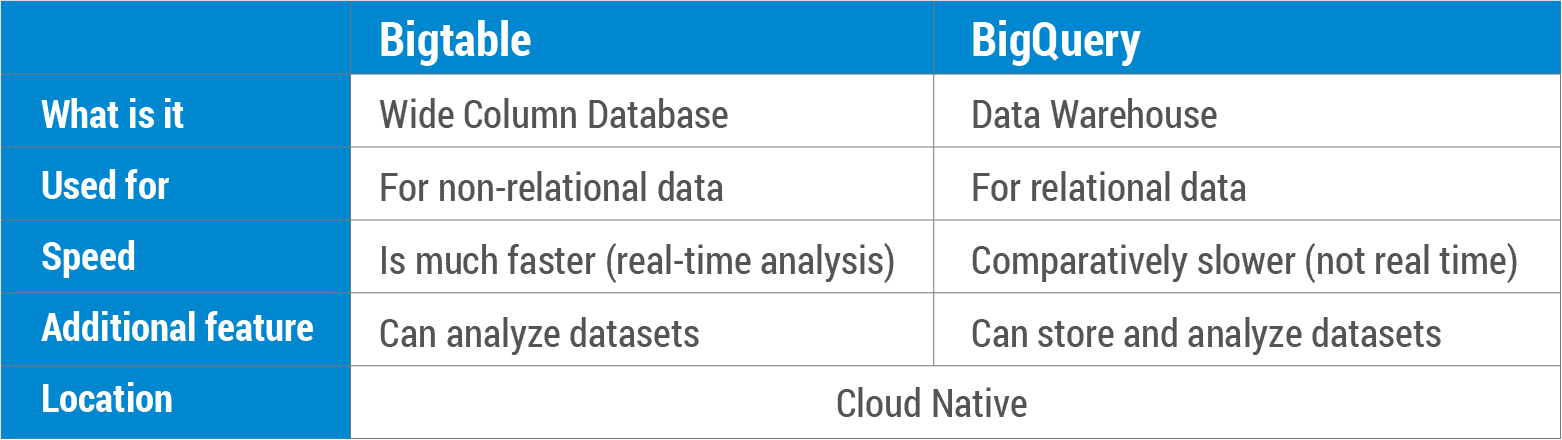
Ce este o comparație Bigtable vs. BigQuery? Bigtable este o bază de date NoSQL care vă permite să stocați date într-un mod sigur și scalabil. BigQuery este un depozit de date relațional care stochează cantități masive de date într-o bază de date SQL. Bigtable a fost integrat în produsele Google, cum ar fi Analytics, Finance, Personalized Search, Earth și Writely pentru operațiunile lor de zi cu zi. Bigtable, o bază de date NoSQL cu date mutabile , funcționează bine cu scenariile OLTP. BigQuery este un depozit de date SQL relațional care poate fi utilizat pentru aplicații OLAP. Atât Bigtable, cât și BigQuery sunt native din cloud, cu acorduri de nivel de servicii de vârf în domeniu. În plus, oferă backup automat (cu replicare), precum și scalabilitate infinită, fragmentare automată și recuperare automată a erorilor (cu replicare).
BigQuery, mai degrabă decât o bază de date NoSQL, nu face acest lucru.
Ce tip de bază de date Nosql este Bigtable?
Cloud Bigtable este o bază de date NoSQL care poate fi utilizată pentru a analiza date și a rula operațiuni. Este o alternativă la HBase, care este un sistem de baze de date coloană care utilizează HDFS. Aplicațiile cu o lățime de bandă mai mică de 10 MB sunt potrivite pentru Cloud Bigtable, care poate suporta un nivel ridicat de debit și scalabilitate.
Bazele de date Big Table, așa cum sunt cunoscute, sunt un subset de baze de date NoSQL. Bigtable, o aplicație de la Google, este similară cu Kleenex. Bazele de date Bigtable sunt standardul industriei pentru imitație și inspirație. În timp ce articolul se referă în primul rând la Bigtable, se uită și la alte baze de date NoSQL. Bigtable a fost conceput în principal pentru uz intern de către Google, fără acces extern. Bigtable a fost introdus pe Google în 2004 și de atunci a fost folosit de peste 60 de aplicații Google. O implementare Bigtable necesită un server principal pentru a urmări tabletele pe un cluster de alte servere.
Apache Software Foundation a contribuit la o serie de inițiative tehnice excelente, în special în domeniul bazelor de date. Accumulo și HBase folosesc aceleași principii de design ca Google Bigtable, dar într-un format care este disponibil comercial. În prezent, Apache HBase rulează sistemul de mesagerie al Facebook și este strâns integrat cu Hadoop, permițându-i să proceseze seturi mari de date. Baza de date Hypertable se bazează pe Bigtable, care este o bază de date tabelară simplă. Hypertable rulează în același mod în care funcționează Hadoop și HFS. Baidu, unul dintre cele mai mari motoare de căutare din China, este unul dintre sponsorii majori ai Hypertable. Clienții includ site-uri de licitații online precum eBay, Groupon și Rediff.com, precum și retaileri offline precum Lowe's și TJ Maxx.
Hadoop este o platformă software open-source care permite utilizatorilor să stocheze și să proceseze cantități masive de date într-un mod eficient. Acest lucru permite bazele de date NoSQL, care pot reduce cantitatea de date necesară pentru stocarea pe servere individuale. O bază de date NoSQL, pe de altă parte, nu necesită o schemă fixă, deoarece este bazată pe scalabilitate. Din acest motiv, sunt o alegere excelentă pentru stocarea cantităților masive de date într-o manieră distribuită.
În ce tip de depozit de date Nosql se încadrează Bigtable?
Una dintre puținele caracteristici care sunt disponibile pe piața generice. La nivelul său cel mai de bază, Bigtable este o bază de date NoSQL care se întinde pe o gamă largă de coloane.
Este Bigtable Columnar Database?
Magazinele cu coloane largi, cum ar fi Bigtable și Apache Cassandra, nu sunt coloane în sensul tradițional al termenului, deoarece nu folosesc deloc structuri de date în coloane la cele două niveluri.
Este Bigtable o bază de date non-relațională?
Nu există un răspuns definitiv la această întrebare, deoarece depinde de modul în care definiți o „bază de date non-relațională”. Bigtable este un depozit de date orientat pe coloane, pe care unii oameni îl consideră a fi un tip de bază de date NoSQL. Cu toate acestea, are suport pentru tranzacții și indexare, care sunt de obicei asociate cu bazele de date relaționale. Deci, depinde cu adevărat de modul în care definiți o bază de date non-relațională.
Instrucțiunea CREATE EXTERNAL TABLE poate fi utilizată pentru a crea un tabel în BigQuery, specificând un tabel din care să extragă date. Opțiunea uri poate fi folosită pentru a specifica un tabel din care să extragă datele. Schema tabelului include numele tabelului, tipul tabelului, numele coloanelor și tipurile de date, precum și schema tabelului opțiunii bigtable_options.
Dacă utilizați MySQL, instrumentul de import BigQuery poate fi folosit pentru a importa automat date dintr-un tabel MySQL în BigQuery. Un nume de tabel și o familie de coloane sunt introduse în instrument, care importă datele într-un tabel BigQuery.
Când utilizați consola Google Cloud, trebuie să introduceți manual numele tabelului și parametrii de calificare a familiei de coloane. Importarea datelor dintr-o varietate de surse este posibilă pe platforma Google Cloud, inclusiv MySQL, PostgreSQL, MongoDB și Redis.
Caracteristici cheie ale Bigtable
Care sunt unele caracteristici ale Bigtable?
Viteza lui Bigtable la citire și scriere, scalabilitatea sa masivă și capacitatea de a gestiona cantități mari de date sunt doar câteva dintre numeroasele sale caracteristici. În plus, deoarece Bigtable este o bază de date NoSQL, interogările SQL nu sunt acceptate. Acest lucru elimină necesitatea ca operațiunile SQL să fie efectuate în baze de date separate.
Bigtable este o bază de date?
Bigtable nu este o bază de date relațională. Este un sistem de stocare distribuit pentru gestionarea datelor structurate care este proiectat să se extindă la o dimensiune foarte mare: petaocteți de date pe mii de servere de mărfuri. Google folosește Bigtable pentru a alimenta multe dintre serviciile sale pe scară largă, cum ar fi Google Analytics și Google Maps.
Cloud BigTable oferă un set unic de caracteristici, permițându-i să se extindă la peste 100.000 de coloane și miliarde de rânduri. Acceptă stocarea a aproximativ petabytes și terabytes de date. În comparație cu BigTable, are o latență foarte scăzută, dar are și potențialul de a stoca o cantitate mare de date. BigTable poate stoca date structurate în coloane, permițându-i să gestioneze serviciile web și datele de căutare pe internet ale companiei. Algoritmii de compresie sunt, de asemenea, utilizați pentru a crește capacitatea sistemului. BigTable are servere back-end de impact care oferă avantaje mai bune decât instalarea HBase autogestionată care este inclusă cu BigTable. Rândurile de pe BigTable au aceeași margine, așa că sunt denumite și blocuri.
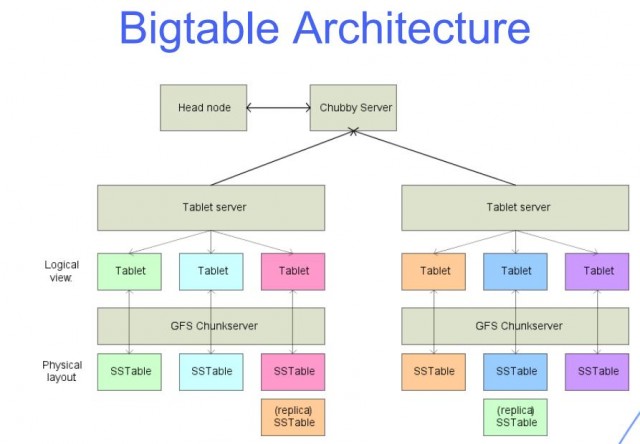
Aceste dispozitive, care sunt denumite „tablete”, vă ajută să vă gestionați volumul de lucru al interogărilor. Sistemul de fișiere bazat pe cloud de la Google, Colossus, este folosit pentru a stoca toate tabletele. Toate operațiunile de scriere din BigTable sunt stocate în jurnalul partajat al lui Colossus, la fel ca și fișierele SSTable. Cele șapte capabilități cheie ale BigTable sunt esențiale pentru succesul unei afaceri. BigTable are potențialul de a vă personaliza, accelera și automatiza viața într-o varietate de moduri. rândurile și coloanele sunt cele două dimensiuni ale datelor din BigTable. Fiecare rând conține un identificator sau index unic care poate fi accesat utilizând cheia de un singur rând.
Fiecare dintre coloanele dintr-o familie are o coloană de calificare. Utilizarea unităților de calificare a coloanelor, cum ar fi cheile de rând, ajută la identificarea coloanei. Când vine vorba de baze de date, BigTable este cunoscut ca unul rar. Fiecare dintre versiunile de marcaj de timp ale BigTable este reprezentată de o celulă, care este una dintre dimensiunile din structura hărții 3D. Această bază de date puternică, care poate fi personalizată și sensibilă la viteză, poate fi utilizată pentru a alimenta site-urile și aplicațiile mobile. Dacă vă gândiți la trecut, vă puteți da seama care interacțiuni au dat cele mai bune rezultate. Vă va ajuta să implementați mai multe analize de date și va duce la un serviciu mai bun pentru clienți.
Google Cloud Bigtable, o bază de date NoSQL open-source, este integrată cu Google Cloud. Faptul că este compatibil cu atât de multe ecosisteme de date mari și Hadoop existente înseamnă că poate fi folosit pentru date nestructurate sau date care necesită o latență scăzută.
Bigtable: O alegere excelentă pentru aplicațiile cu consum mare de date
Bigtable, un serviciu de baze de date NoSQL, este utilizat pentru sarcini mari de lucru analitice și operaționale. Ca rezultat, este o alegere excelentă pentru aplicațiile care folosesc intens date și în timp real. În plus, deoarece este orientat pe coloane, este ideal pentru stocarea datelor în trei dimensiuni.
Bigtable Vs Mongodb
Există câteva diferențe cheie între Bigtable și MongoDB. În primul rând, Bigtable este o bază de date orientată pe coloane, în timp ce MongoDB este o bază de date orientată pe documente. Aceasta înseamnă că în Bigtable, datele sunt stocate în coloane, în timp ce în MongoDB, datele sunt stocate în documente. În al doilea rând, Bigtable nu acceptă indecși secundari, în timp ce MongoDB acceptă. Aceasta înseamnă că, dacă doriți să interogați date în Bigtable, trebuie să cunoașteți coloana specifică pe care doriți să o interogați. În MongoDB, puteți interoga orice câmp dintr-un document. În cele din urmă, Bigtable este proiectat pentru a scala orizontal, în timp ce MongoDB este proiectat pentru a scala pe verticală. Aceasta înseamnă că în Bigtable, puteți adăuga mai multe mașini la cluster pentru a crește capacitatea, în timp ce în MongoDB, puteți adăuga mai multă RAM și CPU la serverul dvs. pentru a crește capacitatea.
Cloud Bigtable de la Google: nu doar pentru Big Data
Bigtable este încă o componentă a infrastructurii Google, fiind creată în 2007. Deși Cloud Bigtable este ideal pentru stocarea unor cantități mari de date cu latență scăzută, nu este ideal pentru datele care nu necesită acces frecvent. Cloud Bigtable, de exemplu, nu ar fi potrivit pentru un lac de date.
Baza de date Bigtable
O bază de date bigtable este o bază de date care utilizează o structură de date bigtable . Un bigtable este un sistem de stocare distribuit pentru date structurate care este proiectat pentru a se scala la o dimensiune foarte mare.
Un tabel mare este unul care are multe rânduri și coloane și este de obicei puțin populat. Bigtable este ideal pentru seturi mari de date datorită latenței scăzute și a densității mari. Această sursă de date este ideală pentru operațiunile MapReduce, deoarece acceptă un randament ridicat de citire-scriere la latență scăzută și este ideală pentru seturi mari de date. Datele unui tabel Bigtable sunt împărțite în blocuri de rânduri învecinate, fiecare dintre acestea fiind denumit tabletă, pentru a reduce încărcarea interogărilor. Formatul SSTable este folosit pentru a stoca tabletele Google în Colossus, sistemul de fișiere al companiei. Fiecare tabletă este conectată la un anumit nod în instanța Bigtable, care este cunoscut și ca nod. Adăugarea de noduri la un cluster poate crește capacitatea clusterului de a gestiona mai multe cereri concurente.
Fiecare rând conține o combinație a familiei de coloane, a identificatorului coloanei și a marcajului de timp, în esență o serie de intrări de chei/valoare. În marea majoritate a timpului, Bigtable convertește toate datele în șiruri brute de octeți. Deoarece Bigtable stochează mutațiile succesiv și le compactează doar o dată la câteva luni, mutațiile ocupă mai mult spațiu de stocare atunci când sunt schimbate într-un rând. Bigtable comprimă datele folosind un algoritm inteligent și folosește tehnologia de compresie. Deoarece ștergerile sunt un tip specializat de mutație, ele necesită spațiu de stocare suplimentar pe termen scurt. Metodele de stocare proprietare Google îi permit să reziste testului timpului pentru date dincolo de intervalul de replicare standard HDFS în trei căi. Utilizatorii pot accesa tabelele dvs. Bigtable folosind rolurile atribuite de proiectul dvs. Google Cloud și Identity and Access Management (IAM). Majoritatea datelor Google Cloud sunt criptate în repaus folosind aceleași sisteme de gestionare a cheilor consolidate pe care le folosim pentru datele noastre criptate. O copie de rezervă poate fi utilizată pentru a salva o copie a schemei și a datelor tabelului, precum și pentru a restabili ulterior copia de rezervă într-un nou tabel.
Bigtable este un sistem de stocare bine conceput, distribuit, capabil să stocheze până la petabytes de date. Deoarece este simplu de utilizat, este o alegere excelentă pentru stocarea datelor la scară largă.

Puterea Cloud Bigtable
Baza de date Cloud Bigtable are capacitatea de a stoca zeci de mii de rânduri și coloane și poate fi accesată de oriunde în lume. Ca rezultat, este foarte potrivit pentru stocarea datelor la scară largă. Cloud Bigtable este acum disponibil pe Google Cloud începând cu 6 mai 2015. Acest lucru a dus la deservirea a peste 10 EXAbyte de date și la procesarea a peste 5 miliarde de solicitări pe secundă de atunci. Ca rezultat, Cloud Bigtable este încă în uz și este un instrument valoros pentru stocarea datelor.
Bigtable Vs Cassandra
Fiecare nod este ales pentru operațiile de citire și scriere prin utilizarea propriei metode. În Cassandra, este identificată o cheie de partiție, în timp ce în Bigtable, este folosită o cheie de rând. Politica de echilibrare a sarcinii a Cassandrei este mai întâi inspectată de client.
Sunt distribuite sisteme de baze de date precum Bigtable și Cassandra. Ei creează depozite multidimensionale cheie-valoare care pot procesa zeci de mii de interogări pe secundă (QPS). Scopul acestui document este de a explica diferențele și asemănările dintre cele două sisteme de baze de date. Bigtable conține multe dintre caracteristicile principale descrise în Bigtable. Lucrarea descrie un sistem de stocare distribuit pentru date structurate. Când Bigtable identifică alocarea intervalului ca fiind necesară pentru un set de date, intervalele de date pentru un nod de procesare sunt ușor de modificat, deoarece stratul de stocare este separat de stratul de procesare. În plus, Bigtable permite replicarea asincronă între clustere distribuite geografic în topologii de până la patru.
Toleranța la erori este asigurată de Cassandra, care este corelată cu nivelul de consistență. Folosind o strategie configurabilă de topologie de replicare a datelor, puteți defini replicarea geografică. În majoritatea topologiilor cu mai multe centre de date, QUORUM (sau LOCAL_QUORUM) este setarea implicită. Majoritatea răspunsurilor unui nod replica la nodul coordonator este necesară pentru ca această setare de nivel să fie considerată reușită. Replicile de date din Cassandra pot fi îmbunătățite în ceea ce privește toleranța la erori prin utilizarea centrelor de date și a configurațiilor de rack. Topologia determină care noduri sunt necesare pentru a garanta consistența în timpul operațiilor de citire și scriere. Instanța Bigtable poate avea unul sau mai multe clustere sau poate avea o colecție de până la patru clustere replicate.
Bigtable și Cassandra funcționează ambele ca magazine cu coloane late NoSQL. Cheia de rând determină ordinea în care sortarea globală a datelor unui tabel este afișată în Bigtable. În Bigtable, nodurile sunt folosite pentru a echilibra responsabilitatea pentru intervalele cheie, care sunt denumite în mod obișnuit tablete. Serviciul Bigtable nu impune tipurile de date pe coloană pe care le trimite clientul. Familia de coloane Bigtable selectează ce coloane dintr-un tabel ar trebui să fie stocate și preluate de la una la alta. Fiecare tabel trebuie să aibă cel puțin o familie de coloane, dar tabelele au adesea mai multe (numărul maxim de coloane pe care un tabel poate avea este de 100). O cheie de rând este situată într-o celulă, iar un nume de coloană este situat în cealaltă.
Cassandra și Bigtable folosesc metode diferite pentru a alege nodul de procesare atât pentru operațiunile de citire, cât și pentru cele de scriere. În Cassandra, se distinge cheia de partiție, în timp ce în Bigtable se folosește cheia de rând. Prin crearea unei politici multi-cluster, o politică de echilibrare a încărcăturii care este conștientă de centrele de date oferă beneficiile failoverului. Ambele baze de date au fost optimizate pentru scriere rapidă și folosesc un proces similar pentru a face acest lucru. Ambele baze de date stochează date în fișiere SSTable, care sunt fișiere imuabile. În Cassandra, mai multe replici trebuie contactate înainte ca coordonatorul să informeze clientul că scrierea a fost finalizată. Deoarece fiecare cheie de rând din Bigtable este atribuită doar unui nod, este necesar un răspuns de la acel nod pentru a confirma că o scriere a avut succes.
Ca rezultat al fuziunii SSTable, ambele baze de date pot exclude celule. Când returnați date către Cassandra, clauza WHERE dintr-o interogare CQL restricționează numărul de rânduri. Atunci când utilizați Bigtable, trebuie consultat doar nodul responsabil cu gama de chei. Rezultatele citirii unui nod pot fi limitate într-o varietate de moduri. În timpul unei faze de compactare, Bigtable și Cassandra stochează date în SSTables, care sunt îmbinate în mod regulat. Bigtable nu limitează numărul de versiuni de marcaj de timp pentru fiecare celulă, dar pot fi posibile alte dimensiuni de rând. Replicarea oferită de Colossus garantează o durabilitate ridicată a datelor.
Interfața de linie de comandă a lui Bigtable, precum și bibliotecile sale client pentru o varietate de limbaje de programare comune, completează capacitățile Cassandrei. Fiecare nod al Bigtable trebuie să servească o serie de SSTable care conțin date stocate pe acele tabele. Nu mai trebuie să calculați replicile de stocare în Bigtable așa cum ați face în Cassandra atunci când determinați dimensiunea clusterului. Instanțele Bigtable stochează în mod obișnuit date pe unități cu stare solidă (SSD) sau hard disk (HDD-uri). Spre deosebire de Cassandra, care se bazează pe teoria conform căreia nu există nicio pierdere a densității de stocare pentru a obține toleranța la erori, volumul de muncă nu pierde densitatea. Este simplu să scalați o instanță Bigtable în sus sau în jos, după cum este necesar, pentru a îndeplini cerințele de sarcină de lucru, menținând în același timp efort și timp de nefuncționare minim. O instanță poate avea doar patru clustere, dar acestea pot fi grupate în orice regiune de nor acceptată de pe planetă.
Pentru a crea o valoare pentru pernodul QPS, Google recomandă utilizarea performanței Bigtable cu date și interogări reprezentative. Bigtable include componente gestionate pentru funcțiile comune de administrare Cassandra. Un tabel care face parte din cluster este creat ca o copie restaurabilă a tabelului într-o copie de rezervă Bigtable. Prețul unui backup este mai mic decât cel al Cloud Storage sau nu consumă resursele nodului. O altă opțiune este să utilizați un export de date gestionat în Cloud Storage pentru a face backup pentru Bigtable. Bigtable gestionează cu ușurință sarcinile obișnuite de întreținere internă Cassandra, cum ar fi corecția sistemului de operare, recuperarea nodurilor, repararea nodurilor, monitorizarea compactării stocării și rotația certificatelor SSL. Tablourile de bord sunt prefabricate pentru urmărirea valorilor de debit și utilizare la nivel de instanță, cluster și tabel pe pagina consolei Bigtable Google Cloud. Puteți utiliza tabloul de bord de monitorizare pentru a efectua reglarea avansată a performanței.
SQL este utilizat în Bigtable, la fel ca și accesul cu chei de rând la datele dintr-o bază de date NoSQL. Nodurile sunt distribuite în rețea, iar bârfa este folosită pentru a menține consistența rețelei. Cu acest sistem, capacitatea de stocare a datelor este crescută și disponibilitatea este menținută fără un singur punct de defecțiune.
Bigtable, pe de altă parte, este mai scalabil și oferă un nivel mai mare de disponibilitate decât Cassandra. Bigtable este, de asemenea, mai ușor de utilizat decât alte limbaje de programare, ceea ce îl face o alegere excelentă pentru seturi de date cu mai puține resurse.
Google încă mai folosește Bigtable?
Google Analytics, indexarea web, MapReduce și multe alte aplicații Google, cum ar fi Google Maps, Google Books, My Search History, Google Earth, Blogger.com, Google Code hosting, îl folosesc pentru generarea și modificarea datelor stocate în Bigtable, Google Maps , Google Cărți, Căutarea mea
Google folosește Cassandra?
Topologia DataStax Astra Cassandra ca serviciu a fost implementată pe Google Cloud utilizând sistemul de operare TensorFlow, precum și folosind sistemul de operare Apache Cassandra în trei zone Google Cloud.
Bigtable este la fel cu Hbase?
Un timestamp Bigtable este stocat în microsecunde, în timp ce un timestamp HBase este stocat în milisecunde. Această distincție poate fi utilă atunci când se utilizează biblioteca client HBase pentru Bigtable și se analizează marcajele de timp inversate.
La ce este bun Bigtable?
Baza de date NoSQL Bigtable este o bază de date cu coloane largi, ideală pentru utilizare într-o bază de date NoSQL. Sistemul este optimizat pentru a oferi o latență scăzută, un număr mare de citiri și scrieri și performanță ridicată la scară. Utilizarea cazurilor de tabel este de obicei limitată la o scară specifică sau la o anumită debit care necesită o latență ridicată, cum ar fi Internetul lucrurilor (IoT), AdTech, FinTech și așa mai departe.
Bigtable vs Bigquery
Există câteva diferențe cheie între bigtable și bigquery. Bigtable este conceput pentru a fi o bază de date scalabilă, orientată pe coloane, în timp ce bigquery este concepută pentru a fi o bază de date scalabilă, relațională. Bigtable nu acceptă SQL, în timp ce bigquery acceptă. Bigtable nu este la fel de utilizat ca bigquery, dar are unele avantaje față de bigquery, cum ar fi posibilitatea de a scala la un număr mai mare de coloane și rânduri.
Google a făcut progrese semnificative în stocarea în cloud a datelor masive de-a lungul anilor. Bigtable este un serviciu de baze de date NoSQL la scară petabyte, complet gestionat, care se bazează pe Administrarea bazelor de date orientate pe obiecte (OOPA). BigQuery este creat folosind Bigtable și Google Cloud Platform, precum și sistemul de baze de date Dremel de la Google. Există trei diferențe majore între BigQuery și Bigtable. O soluție Big Data as a Service (BaaS) este una oferită de Google Cloud BigQuery. BigQuery este utilizat de produsele Google precum Analytics, Finance, Personalized Search, Earth, Orkut și Writely. Când se utilizează procesarea rapidă a datelor de la BigQuery, 35 de miliarde de rânduri pot fi procesate în câteva secunde.
O bază de date NoSQL este un acronim pentru un serviciu de baze de date; cu alte cuvinte, nu este o bază de date relațională. Coloanele de chei pot avea dimensiuni multiple, iar barele de taste pot fi derulate pe orizontală. Elementele de date individuale cu o capacitate de stocare mai mare de 10 megaocteți pot afecta performanța. Dacă aveți nevoie de o soluție cuprinzătoare de stocare pentru obiecte nestructurate (de exemplu, fișiere video), stocarea în cloud este probabil o opțiune mai bună. Este o alegere excelentă pentru interogările care necesită o scanare a unui tabel sau pentru a căuta o bază de date mare într-o singură fotografie. Este imposibil ca un obiect încărcat să se modifice pe durata de viață în BigQuery, iar datele sale sunt întotdeauna imuabile. Tabelele dintr-un bigtable stochează date scalabile care au fost sortate în chei/hărți de valori sortate după cheie, rând și marcaj temporal.
Cu Integrate.io, puteți automatiza un proces ETL și de integrare a datelor pentru a vă conecta sursele de date și depozitele de date din cloud. Platforma de integrare include peste 100 de integrări prefabricate, inclusiv BigQuery, și o interfață de tip drag-and-drop care face gestionarea proceselor de integrare mai ușoară ca niciodată. Contactați echipa noastră de experți în date pentru a discuta situația dvs. sau pentru a începe un pilot de 14 zile al platformei Integrate.
Google BigQuery iese pe primul loc în ceea ce privește funcțiile, în ciuda faptului că MySQL este încă utilizat pe scară largă. Acest lucru este valabil mai ales pentru caracteristicile care sunt utilizate în mod obișnuit în aplicațiile de afaceri, cum ar fi importul și exportul de date, analiza datelor și federarea datelor. MySQL, pe de altă parte, are doar 28 de caracteristici, ceea ce înseamnă că este posibil să nu poată satisface nevoile multor afaceri. Google BigQuery este bazat pe cloud, permițându-i să fie accesat din orice locație cu o conexiune la internet. MySQL, pe de altă parte, rulează pe o arhitectură client-server și nu este disponibil în cloud.
Care este diferența dintre Bigquery și Bigtable?
Bigtable este o bază de date NoSQL cu coloane largi, care este optimizată pentru citiri și scrieri grele. Spre deosebire de BigQuery, care este un depozit de date pentru întreprinderi pentru cantități mari de date relaționale, Oracle Data Warehouse servește ca un serviciu de deduplicare.
Bigquery este construit pe Bigtable?
În curând au urmat Bigtable, un serviciu de interogări bazat pe cloud dezvoltat în colaborare cu Google și Microsoft și, respectiv, sistemul Google Dremel pentru interogări ad-hoc.
Când ar trebui să folosesc Bigtable?
Bigtable este ideal pentru aplicațiile care necesită un randament ridicat și scalabilitate atunci când manipulează datele cheie/valoare, cu cel mult 10 MB de date per valoare. Punctele forte ale Bigtable sunt operațiunile MapReduce în loturi, procesarea/analitica fluxului și învățarea automată.
Serviciu de bază de date Nosql scalabil
Un serviciu de baze de date nosql scalabil este un tip de bază de date care poate gestiona date la scară largă. Este un serviciu bazat pe web care poate fi folosit pentru a stoca și gestiona cantități mari de date. Acest tip de bază de date este conceput pentru a fi scalabil, astfel încât să poată gestiona date la scară largă.
Acest tutorial presupune că aveți un mediu Node.js funcțional. Am creat un folder numit nodejs-dynamodb-sample în care să despachetez fișierele DynamoDB. Pagina GitHub pentru proiect este https://www.gofundme.com/adamfowleruk/nodesurvey.html. Exemplul de aplicație folosește DynamoDB pentru a căuta și a prelua date de film. Pentru a stoca date pe S3, vom folosi serviciul Amazon Identity and Access Management (IAM) și pentru a accesa DynamoDB pe AWS, vom folosi serviciul Amazon DynamoDB. Pentru a utiliza serviciul Amazon iADM, trebuie mai întâi să vă înregistrați și să creați un utilizator. Un titlu de film și un an pot fi adăugate la secțiunea POST/filme a căutării dvs.
Faceți o listă de filme dintr-un anumit an introducând câmpul introdus cu cheie. Acum vă puteți crea propria aplicație urmând acest exemplu de bază. Dacă intenționați să utilizați din nou tabelele, ar trebui să le ștergeți după ce le-ați terminat de utilizat, ceea ce va genera costuri de găzduire și servicii AWS. Pe AWS, accesați consola DynamoDB și introduceți cantitatea de stocare pe care ați folosit-o. Puteți vizualiza articolele dintr-un tabel făcând clic pe „Filme”, să vedeți valorile pe care le vedeți în aplicația dvs. și să vedeți costurile lunare estimate făcând clic pe fila Capacitate. Pe pagina mea GitHub, includ un eșantion de cod în acest exercițiu: https://github.com/adamfowleruk/nodejs-dynamodb-sample.
Baza de date Google Cloud Bigtable
Google Cloud Bigtable este un serviciu de baze de date NoSQL rapid, complet gestionat, la scară de petabyți, ideal pentru sarcini de lucru analitice și operaționale mari.
Magazinul de date Google este mai potrivit pentru aplicațiile care au nevoie de răspunsuri rapide la solicitările utilizatorilor.
În baza de date Bigtable de la Google, nu există o bază de date relațională. Interogările SQL, îmbinările și tranzacțiile pe mai multe rânduri nu sunt acceptate. Prin urmare, dacă căutați suport standard pentru baze de date, nu vă puteți aștepta. Bigtable, pe de altă parte, nu oferă o cantitate mare de date sau analize. Natura optimizată a lui Bigtable se datorează în parte analizei sale de înaltă performanță și capabilităților de tratare a datelor. Datastore, pe de altă parte, este conceput pentru a permite ca date tranzacționale de mare valoare să fie transmise aplicațiilor. Ca rezultat, Datastore este mai potrivit pentru aplicațiile care necesită răspunsuri rapide la solicitările utilizatorilor.