
Baze de date NoSQL: fragmentare și replicare
Publicat: 2022-11-21Bazele de date NoSQL sunt adesea folosite pentru stocarea datelor la scară largă datorită capacității lor de a scala orizontal. Aceasta înseamnă că se pot scala prin adăugarea mai multor noduri la sistem, mai degrabă decât prin modernizarea hardware-ului unui singur nod. O modalitate prin care pot atinge această scalabilitate orizontală este prin sharding, care este un proces de distribuire a datelor pe mai multe noduri. Replicarea este o altă modalitate prin care bazele de date NoSQL se pot scala și implică crearea de copii ale datelor pe mai multe noduri.
Atât în bazele de date SQL, cât și în NoSQL, conceptul de fragmentare a bazei de date este critic pentru scalare. Baza de date este împărțită în mai multe bucăți (fragmente), după cum sugerează și numele.
De asemenea, puteți utiliza NoSQL Data Replication pentru a vă asigura că nu pierdeți date atunci când un server se blochează prin copierea și stocarea fără probleme a datelor dvs. structurate, nestructurate și semi-structurate. Puteți afla mai multe despre bazele de date NoSQL vizitând această pagină.
O bază de date relațională poate fi partiționată folosind metoda Sharding, cunoscută și sub numele de partiție orizontală. Amazon Relational Database Service ( Amazon RDS ) este un serviciu de baze de date relaționale gestionat, care simplifică utilizarea în cloud, oferind o varietate de caracteristici.
O metodă de replicare copiază datele de pe mai multe servere și le plasează într-o locație unde pot fi găsite. În replicare, sunt create copii master și slave, copiile master devenind copii autorizate care gestionează datele scrise, iar copiile slave devenind copii asincrone care gestionează datele scrise.
Nosql folosește Sharding?
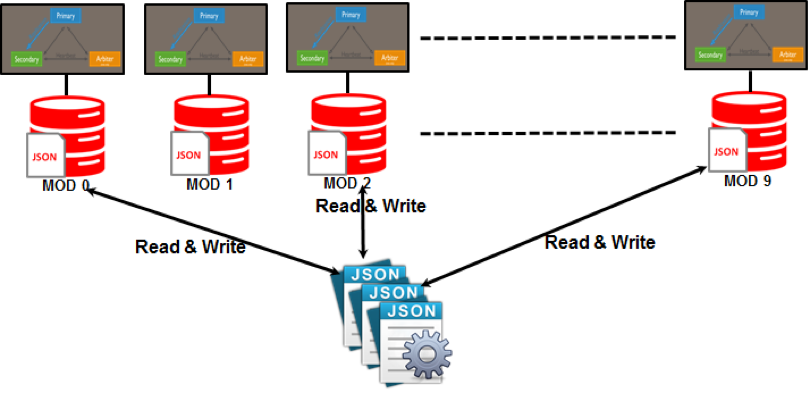
Modelele de partiții, cum ar fi partajarea, sunt utilizate în NoSQL. Partiționarea este un proces care atribuie fiecare partiție unui server care este probabil să fie independent de restul rețelei. Cu această scalare, puteți oferi utilizatorilor globali acces la un set divers de date, păstrând în același timp nivelul de performanță cât mai ridicat posibil.
MySQL Cluster este soluția. MySQL Cluster este un set de software care fragmentează automat tabelele peste noduri și permite bazelor de date să se scaleze orizontal pe hardware-ul de marfă ieftin pentru a servi sarcini de lucru intensive în citire și scriere folosind SQL, precum și direct prin intermediul API-urilor NoSQL. MySQL Cluster are potențialul de a fi folosit pentru mult mai mult decât blockchain-uri. De asemenea, poate fi folosit pentru a scala aplicațiile dvs. utilizând MySQL Cluster. Motivul pentru aceasta este că MySQL Cluster este un sistem de planificare. Ca rezultat, vă puteți scala aplicațiile, hotărând când și cum vor fi generate fragmentele. Acesta este un avantaj major deoarece nu trebuie să vă bazați pe cloud computing . Acest lucru se datorează faptului că fragmentele sunt produse pe nodurile în care se execută sarcina de lucru. Ca rezultat, puteți controla cât de multă concurență este necesară. Ca rezultat, MySQL Cluster are un set foarte puternic de caracteristici. Poate fi folosit pentru a vă scala aplicațiile și pentru a controla câtă concurență aveți nevoie.
Ce este fragmentarea și replicarea în Nosql?
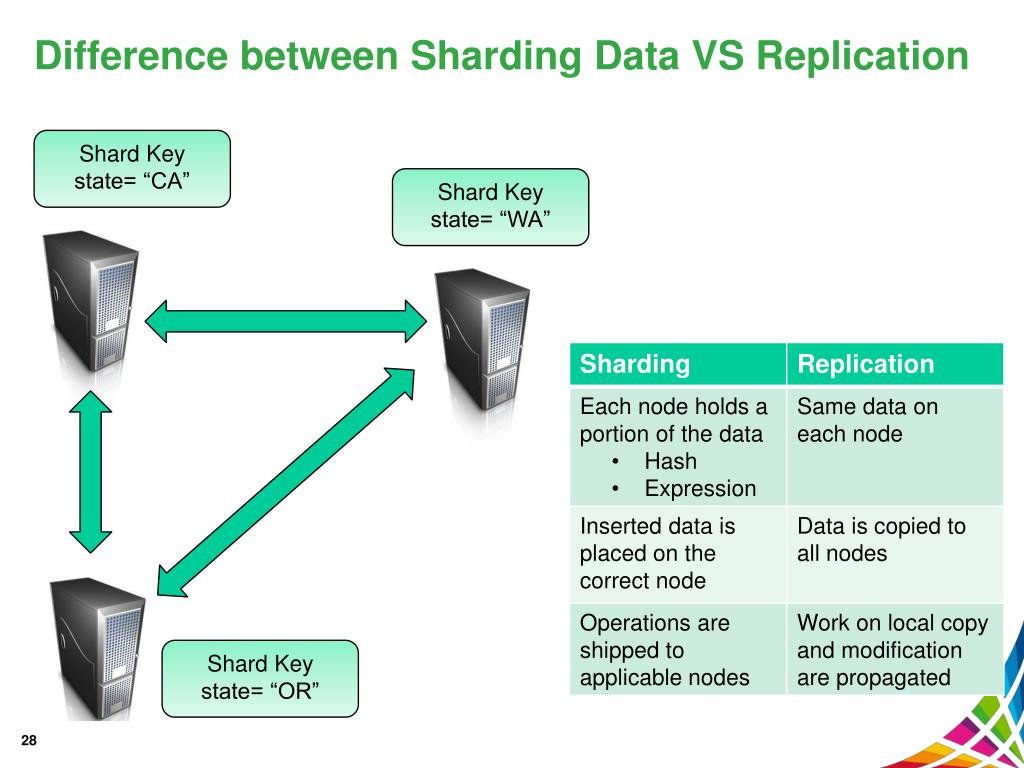
Care este diferența dintre replicare și fragmentare? Replicarea datelor este actul de transfer de date de la nodul de server primar la nodurile de server secundare . Ca o copie de rezervă în cazul în care serverul principal eșuează, acest lucru poate ajuta la asigurarea că datele sunt disponibile. Această funcție poate fi utilizată pentru a scala serverele pe orizontală folosind o cheie shard.
Avantajele Sharding
Când aveți de-a face cu date care trebuie să fie partiționate, dar care nu au resursele necesare pentru a le replica, spațierea poate fi benefică într-o varietate de situații. Când trebuie să scalați citirile, replicarea este utilă, dar scrierile de date pot fi gestionate mai eficient prin sharding. Alegerea unei chei shard greșite poate avea un impact negativ asupra performanței sistemului.
Mongodb folosește Sharding?
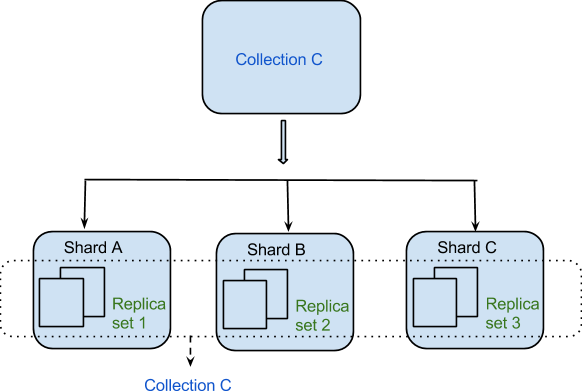
Datele sunt distribuite între mașini într-o manieră distribuită în virtutea Sharding-ului. MongoDB folosește sharding pentru a susține implementări la scară largă care necesită un nivel ridicat de debit. Poate fi dificil să construiți un singur server pentru un sistem de baze de date cu un număr mare de seturi de date sau cu o aplicație de mare capacitate.
Cea mai obișnuită strategie pentru rezolvarea problemelor Ranged Sharding este abordarea acesteia în sensul său cel mai general. Nodul rădăcină al clusterului are un număr predeterminat de fragmente care pot fi împărțite în funcție de distanța lor față de centrul de date al clusterului. Nodul primar este denumit nodul rădăcină deoarece este primul nod creat în setul de date. Un alt tip de fragment este denumit fragment secundar. O tranzacție ranged sau hashing este posibilă ambele. Valoarea cheii hash a unui anumit fragment determină câte date poate genera. Un identificator este creat de cheia hash pentru fiecare parte de date dintr-o tranzacție. Există numeroase avantaje și dezavantaje pentru fiecare strategie. Este mai simplu de implementat interval Sharding atunci când setul de date este mic, spre deosebire de un set mare, și este mai eficient când este mic. Când setul de date este mare, hashingul este mai eficient. Reputația MongoDB pentru viteză derivă din faptul că acceptă delegarea datelor către alte servicii MongoDB. Fragmentele setului de date pot fi distribuite între mai multe servere în MongoDB pentru a îmbunătăți viteza de procesare a datelor. MongoDB acceptă mai multe opțiuni de replicare în plus față de sharding. Ca rezultat, replicarea permite distribuirea unui set de date pe mai multe servere pentru a menține consistența. Replicarea datelor este necesară dacă doriți să vă asigurați că informațiile sunt întotdeauna exacte și actualizate. În plus, clusterele împrăștiate din MongoDB pot fi utile pentru îmbunătățirea performanței. Salvarea este o tehnică de transfer de cantități mari de date de la un server la altul în același mod în care este replicarea. O cheie shard este un element de date care poate fi copiat (sau „shards”) de la un server la altul. Cele două metode principale de distribuire a datelor în clustere fragmentate din MongoDB sunt bazate pe intervale și distribuite. Hashing se poate face folosind un server criptat. Împărțind lucrurile, poți realiza mai mult de un lucru.

Ar trebui să-ți spargi Mongodb-ul?
Nu este sigur dacă fragmentarea îmbunătățește sau nu performanța în unele cazuri, dar s-a dovedit că crește performanța în unele cazuri. În plus, ca rezultat, shardingul introduce propriul set de provocări, cum ar fi asigurarea unor copii de siguranță și restaurări solide. Înainte de a decide asupra unei strategii de sharding , ar trebui să vă gândiți la avantajele și dezavantajele acestui lucru.
Sharding în Nosql
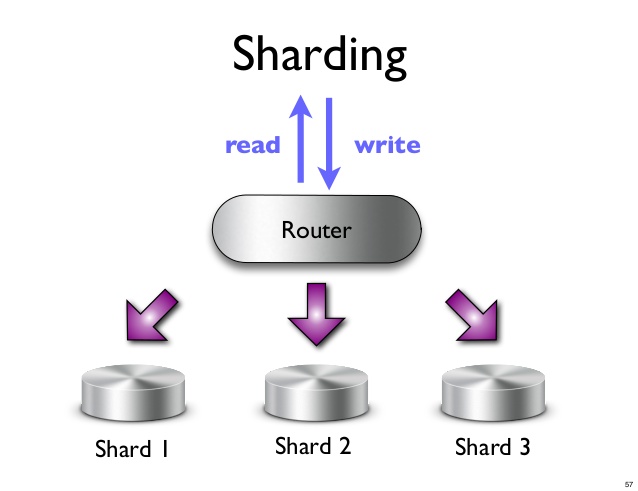
Un shard este o partiție orizontală a datelor într-o bază de date sau într-un motor de căutare. Fiecare fragment este o bază de date independentă sau o instanță de motor de căutare. Într-o bază de date NoSQL, o colecție de documente poate fi împărțită în fragmente, fiecare dintre acestea fiind stocată pe un server separat.
Sharding vs replicare
Distincția dintre replicare și sharding este că replicarea este duplicarea datelor, în timp ce sharding-ul este împărțirea datelor în bucăți discrete. În acest caz, v-ați împărțit colecția în mai multe părți pe baza fragmentării. Recuperarea bazei de date oferă imagini cu toate seturile de date.
Beneficiile Sharding
Datele sunt împărțite pe mai multe mașini pentru a crește numărul de utilizatori simultani și pentru a îmbunătăți performanța. Datele sunt stocate pe partiții separate în fiecare dintre mașini.
Replicare în Nosql
Există câteva moduri diferite în care replicarea poate fi gestionată într-o bază de date NoSQL. O modalitate este ca baza de date să se repete automat pe un server secundar ori de câte ori se face o modificare. Acest lucru asigură că există întotdeauna o copie de rezervă disponibilă în cazul în care serverul principal se defectează. O altă modalitate este de a replica manual datele pe un server secundar în mod regulat. Acest lucru oferă administratorului mai mult control asupra momentului în care are loc replicarea, dar înseamnă, de asemenea, că există șansa ca serverul secundar să nu fie actualizat în cazul unei defecțiuni.
Ce este Sharding în baza de date
Sharding este un proces de partiţionare orizontală a datelor într-o bază de date. În sharding, o bază de date este împărțită în părți mai mici, numite shards. Fiecare fragment este stocat pe un server separat. Procesul de sharding ajută la îmbunătățirea performanței unei baze de date prin distribuirea încărcării pe mai multe servere.
O singură bucată de date poate fi replicată într-o singură tranzacție cu ajutorul sharding-ului. Ca rezultat al împărțirii unui set de date în bucăți mai mici și al distribuirii lor pe mai multe servere, capacitatea totală de stocare a sistemului poate fi mărită. În unele cazuri, acest lucru ar putea fi util dacă datele sunt mari și necesită mai multe servere pentru a le menține. Wrapper-urile de date străine sunt, de asemenea, folosite pentru a citi date de pe servere la distanță, oferind stocării datelor și mai multă flexibilitate.
Care este diferența dintre partiționare și fragmentare?
Partiționarea și Sharding sunt două abordări pentru structurarea colecțiilor mari de date în fragmente mici. Atât fragmentarea, cât și partiția înseamnă că datele sunt răspândite pe mai multe computere, dar sunt distincte. Procedura de partiţionare a unei instanţe de bază de date presupune gruparea subseturi de date în cadrul acesteia.
Care Db este cel mai bun pentru Sharding?
Partajarea bazei de date este acceptată de Cassandra, HBase, HDFS, MongoDB și Redis. Bazele de date care nu acceptă în mod nativ PostgreSQL, Memcached, Zookeeper, MySQL și Sqlite sunt considerate baze de date. Logica Jarryd trebuie să fie prezentă într-o aplicație dacă nu are suport încorporat pentru baze de date.
Sharding-ul este posibil în Sql?
Este posibil, totuși, să se implementeze fragmentarea bazată pe intervale (în esență orizontală), într-un mod care o face mai transparentă pentru aplicație. Modul tipic de a face acest lucru în SQL Server este printr-o vizualizare partiționată, dar nu trebuie să fie așa.