
Pig: O platformă de nivel înalt pentru Apache Hadoop
Publicat: 2023-02-22Pig este o platformă de nivel înalt pentru crearea de programe care rulează pe Apache Hadoop. Termenul „Pig” se referă la nivelul de infrastructură al platformei, care constă dintr-un compilator și mediu de execuție, precum și un set de operatori de nivel înalt. Stratul de infrastructură al lui Pig oferă un set de instrumente pentru dezvoltatori pentru a crea, întreține și executa programele lor Pig. Pig este un proiect open source care face parte din ecosistemul Apache Hadoop . Modelul de programare Pig se bazează pe fluxul de date, ceea ce facilitează scrierea de programe care procesează cantități mari de date. Programele Pig sunt compuse dintr-o serie de operatori care sunt executați într-un grafic aciclic direcționat. Pig este o alegere excelentă pentru procesarea unor cantități mari de date, deoarece este scalabil, eficient și ușor de utilizat.
Ca soluție NoSQL, aveți nevoie de modalități specifice, predefinite, de a analiza și de a accesa date. SQL (UNION, INTERSECT etc.) este o expresie de interogare comună care nu este folosită foarte des în lumea datelor mari. Deoarece Hive este optimizat pentru procesarea loturilor și a datelor mari, cel mai bine este să atingeți fiecare rând. Hive cheltuiește mult mai puțin timp și mai puțini bani pe operațiuni decât Hadoop, care are avantajul scalării. Chiar și interogările mici pe sistemele de dezvoltare pot fi COMANDI de mărime mai lente decât interogările similare pe RDBMS. Hive nu memorează în cache rezultatele interogărilor. Retrimiterea unei interogări repetate este o practică obișnuită în MapReduce.
Există două tipuri de Hive: 1) Hive nu este o bază de date; mai degrabă, este un motor de interogare care acceptă părți SQL specifice datelor de interogare b) Hive este o bază de date cu suport SQL c) Hive este o bază de date specifică SQL. Hive este un sistem de depozit de date bazat pe SQL pentru Hadoop, care include, printre altele, Pig și Python; Hive este folosit pentru stocarea datelor Hadoop .
Pig este un SQL?
Nu există un răspuns corect sau greșit la această întrebare, deoarece depinde de opinia personală. Unii oameni pot crede că porcul este un sql, în timp ce alții nu. În cele din urmă, este la latitudinea individului să decidă dacă porcul este sau nu un sql.
Astăzi, Apache Hive și Pig sunt doi termeni care devin rapid sinonimi cu big data. Cu aceste instrumente, dezvoltatorii de date și analiștii le pot folosi pentru a reduce complexitatea MapReduce, păstrând în același timp un nivel ridicat de integritate a datelor. Hive este o infrastructură de depozit de date cunoscută și ca instrument ETL (extracție, încărcare și transformare). Apache Hive, Pig și SQL sunt trei instrumente populare pentru analiza și gestionarea datelor. Trebuie să știți care platformă va fi cea mai potrivită pentru nevoile dvs. și cât de des ar trebui să o utilizați. Să ne uităm la cele trei moduri diferite de a folosi Hive, Pig și SQL în contextul acestor trei tehnologii. SQL este încă regele în gestionarea și analiza big data, în ciuda dominației Apache Hive și Apache Pig. Deoarece fiecare îndeplinește o funcție specifică, cerințele lor sunt adaptate afacerii. Apache Pig se bazează pe scripturi și necesită cunoștințe speciale, în timp ce Apache Hive este singura soluție de bază de date nativă pentru dezvoltator.
Porcul este un animal versatil, cu o mare flexibilitate. Pig, de exemplu, poate procesa fișiere jurnal care conțin date JSON sau XML, permițându-vă să citiți datele. De asemenea, este posibil să stocați date din serviciile web în Pig.
Tipurile de date ale hărților, tuplurile și tipurile de date ale pungii pot fi utilizate în mod interschimbabil. Sunt capabili să manipuleze date din orice sursă.

Este porcul un instrument Etl?
Nu există un răspuns definitiv la această întrebare, deoarece depinde de modul în care definiți un instrument ETL. În general, un instrument ETL este o aplicație software care vă ajută să extrageți date dintr-una sau mai multe surse, să le transformați într-un format compatibil cu sistemul dvs. țintă și să le încărcați în acel sistem. Unii oameni ar spune că porcul este un instrument ETL, deoarece poate îndeplini toate aceste funcții. Alții ar putea argumenta că porcul nu este un instrument ETL, deoarece nu este conceput special pentru transformarea datelor. În cele din urmă, răspunsul la această întrebare depinde de propria definiție a instrumentului ETL.
Cum puteți folosi porcul pentru procesarea Etl?
O aplicație Pig poate fi descrisă ca un model de tranzacție ETL, care descrie modul în care un proces extrage date dintr-un obiect și le transformă într-un depozit de date bazat pe un set de reguli. Utilizatorii definesc funcțiile definite de utilizator (UDF) ale porcului pentru a ingera date din fișiere, fluxuri și alte surse.
Ce este Pig Tool?
O platformă sau un instrument cunoscut sub numele de Pig procesează seturi mari de date. Această bibliotecă conține un nivel ridicat de abstractizare pentru procesarea datelor în procesul MapReduce. Pig Latin este un limbaj de scripting de nivel înalt care este utilizat în procesul de codificare pentru a dezvolta codurile de analiză a datelor.
Care este diferența dintre Pig și Sql?
SQL Pig Latin și Apache Pig sunt limbaje procedurale. SQL este un limbaj de scripting de natură declarativă. Depinde în întregime de Apache Pig dacă se utilizează sau nu schema. Datele pot fi stocate fără a fi nevoie de o schemă (tipurile de valori sunt stocate în $, $ și așa mai departe).
Porcul face parte din Hadoop?
O aplicație Pig Hadoop este un limbaj de programare la nivel înalt care poate fi folosit pentru a analiza seturi masive de date. Proiectul Pig Hadoop de la Yahoo! a fost unul dintre primele proiecte Hadoop . În general, efectuează o cantitate semnificativă de muncă de administrare a datelor atunci când rulează Hadoop.
În domeniul analizei datelor mari, Pig Hadoop este un limbaj de programare de nivel înalt. Pentru a analiza datele folosind Apache Pig, trebuie mai întâi să scriem scripturi folosind Pig Latin. scripturi care vor fi transformate în sarcini MapReduce . Acest lucru se realizează prin utilizarea Pig Engine, o extensie Apache Pig. Urmând pașii de mai jos, puteți instala Apache Pig pe Linux/CentOS/Windows (prin VM sau Cloudera). Primul pas este să descărcați și să instalați Apache Pig. Al doilea pas este modificarea variabilelor de mediu Apache Pig folosind fișierul bashrc.
La pasul 3, determinați versiunea Pig . Acest fișier poate fi salvat într-un alt director după ce a fost mutat. Al cincilea pas este să lansați Grunt Shell (scriptul folosit pentru a rula Pig Latin) făcând clic pe comanda Pig.
De ce Pig Latin este cel mai bun limbaj de scripting de nivel înalt pentru analiza datelor
Codul de analiză a datelor Pig Latin este scris într-un limbaj de scripting de nivel înalt. Este un limbaj asemănător SQL care este destinat să proceseze fluxuri de date în paralel.
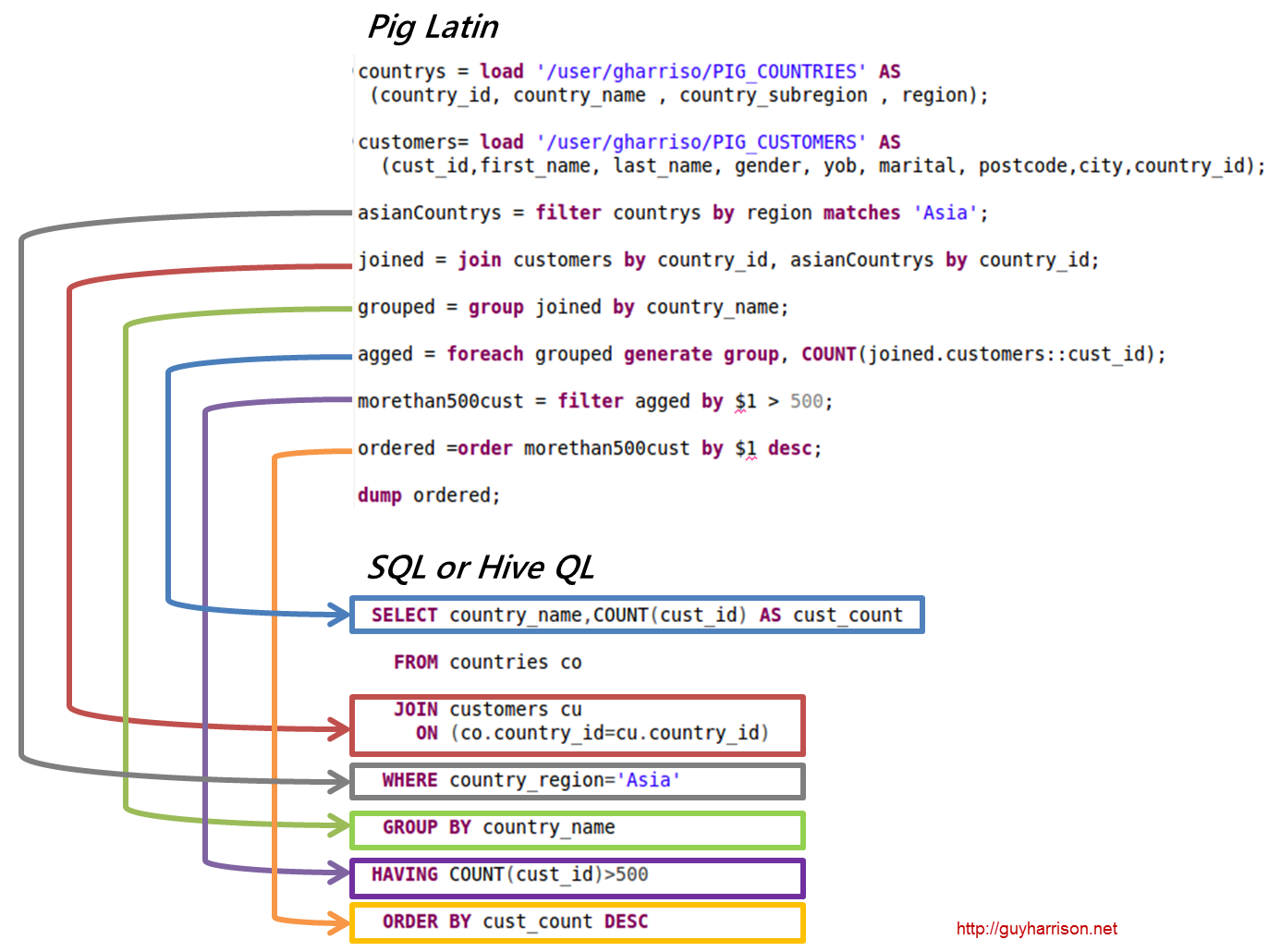
Exemplu de porc Apache
Pig este o platformă de nivel înalt pentru crearea de programe care rulează pe Apache Hadoop. Limba pentru această platformă se numește Pig Latin. Pig își poate executa joburile Hadoop în MapReduce, Tez sau Spark. Pig Latin rezumă programarea din limbajul Java MapReduce într-o notație care face programarea MapReduce mai ușoară. De exemplu, următoarea instrucțiune Pig Latin este echivalentă cu codul Java MapReduce de mai sus: A = LOAD 'mydata' USING PigStorage(',') AS (id:int, name:chararray, age:int, gpa:float); GHODĂ A;