
Scalarea unei baze de date NoSQL: sfaturi și trucuri
Publicat: 2022-11-18Bazele de date NoSQL devin din ce în ce mai populare pe măsură ce cantitatea de date generate de companii continuă să crească exponențial. Cu toate acestea, multe organizații sunt reticente în a trece la NoSQL, deoarece se tem că va fi mai dificil de scalat. Scalarea unei baze de date NoSQL nu este de fapt atât de diferită de scalarea unei baze de date relaționale. Principala diferență este că bazele de date NoSQL sunt proiectate pentru a fi scalabile pe orizontală, ceea ce înseamnă că se pot scala prin adăugarea mai multor noduri la sistem. Acest lucru este în contrast cu bazele de date relaționale , care sunt scalabile pe verticală, ceea ce înseamnă că se pot scala doar adăugând mai multe resurse la un singur server. Există câteva lucruri de reținut atunci când scalați o bază de date NoSQL: 1. Asigurați-vă că datele dvs. sunt distribuite uniform pe toate nodurile. 2. Adăugați noduri treptat pentru a evita supraîncărcarea sistemului. 3. Monitorizați îndeaproape performanța sistemului pentru a identifica orice blocaje. 4. Reglați sistemul în mod regulat pentru a asigura performanțe optime. Având în vedere aceste sfaturi, scalarea unei baze de date NoSQL nu ar trebui să fie mai dificilă decât scalarea unei baze de date relaționale.
Există numeroase metode și principii pentru scalarea unei baze de date, în funcție de tipul acesteia. Scalarea bazelor de date NoSQL și sql depinde de conceptul de fragmentare a bazei de date. Beneficiile de a putea stoca mai multe date se acumulează atunci când serverele sunt distribuite, dar moștenim și problemele care vin odată cu distribuirea. Shardingul automat nu este acceptat de o bază de date monolitică, iar inginerii ar trebui să scrie manual logica pentru a o gestiona. Pentru a rezolva această problemă, un proxy, cum ar fi un echilibrator de încărcare, poate fi instalat în fața serviciului de interogare și a bazei de date. Putem obține interogări mai rapide atunci când fragmentul este mare, deoarece acel proxy poate fi folosit din nou. Din cauza lipsei utilizatorilor finali care să fie conștienți de acest lucru, scalarea bazelor de date NoSQL este în mare măsură invizibilă.
Fiecare ciob este unic, spre deosebire de arhitectura master-slave. Dacă există întrebări de citire pe fragmentul principal, o solicitare va fi trimisă către fragmentele slave. La nivel de centru de date, putem replica baza de date pentru a ne asigura că avem o copie de rezervă. Nodul este un nod care poate comunica și schimba informații cu alte noduri. Fiecare nod comunică cu un număr fix de alte noduri printr-un protocol. Deoarece toate nodurile sunt egale în Cassandra, un nod își poate replica datele de la unul la altul fără a fi nevoie să-și facă griji că pierderea oricăror date. Protocolul de bârfă este unul dintre multele moduri prin care nodurile pot partaja informații.
O bază de date distribuită poate avea o serie de avantaje pe lângă obținerea de proprietăți suplimentare. O componentă critică a asigurării disponibilității este replicarea datelor. Când utilizați replicarea asincronă pentru baza de date, aceasta nu va fi întotdeauna complet consecventă la început, dar va deveni mai mult pe măsură ce trece timpul. Bazele de date SQL sunt utilizate în aplicații financiare care necesită o precizie ridicată a datelor, în timp ce bazele de date NoSQL sunt utilizate în aplicații mai puțin semnificative, cum ar fi numărul de vizualizări.
Scalare verticală se referă la procesul de creștere treptată a volumului de lucru de calcul cu utilizarea upgrade-urilor hardware. Trecerea la o arhitectură distribuită și adăugarea mai multor computere pentru a rezolva problema noastră implică scalarea, cunoscută și sub numele de scalare orizontală sau scalare.
NoSQL poate suporta scalarea bazată pe metode orizontale.
MongoDB, ca bază de date NoSQL, este scalabilă deoarece datele sale nu sunt stocate în baze de date relaționale. Datele sunt stocate ca documente asemănătoare JSON, care sunt ușor accesibile printr-o solicitare HTTP. Distribuția documentelor poate fi efectuată pe orizontală pe mai multe noduri prin utilizarea acestei metode.
Cum scalați baza de date Nosql?
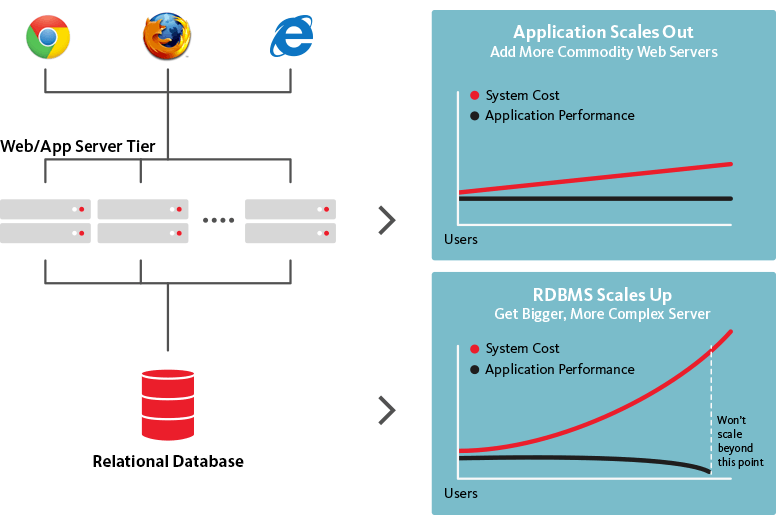
Bazele de date NoSQL, pe de altă parte, sunt scalabile pe orizontală, ceea ce înseamnă că pot gestiona un trafic crescut după cum este necesar prin simpla adăugare a mai multor servere la baza de date. Deoarece bazele de date NoSQL pot fi transformate în structuri mult mai mari și mai puternice, este alegerea logică pentru seturi mari de date și baze de date în continuă evoluție.
Pentru ca acest tutorial să funcționeze, trebuie să aveți un mediu Node.js funcțional. În această postare, voi despacheta fișierele DynamoDB într-un folder numit nodejs-dynamodb-sample. Pentru o versiune detaliată a acesteia, accesați pagina mea GitHub: https://www.gofundme.com/adamfowleruk/nodesurvey.html. Exemplul de aplicație poate căuta și prelua informații despre film din DynamoDB. Vom stoca date în S3 pe Amazon Web Services și vom accesa DynamoDB prin serviciul Amazon Identity and Access Management (IAM). Pentru a utiliza serviciul de analiză în aplicație al Amazon, trebuie mai întâi să vă înregistrați și să creați un cont. Notați anul și titlul fiecărui film pe care doriți să-l POSTați /filme.
Puteți introduce un câmp cu cheie pentru a găsi filme dintr-un anumit an. După aceea, vă puteți proiecta propria aplicație de la zero. Puteți folosi tabelele până când le-ați terminat, dar ar trebui să le ștergeți odată ce au fost folosite. Vizitați consola DynamoDB de pe Amazon Web Services pentru a vedea cât de mult spațiu de stocare ați folosit până acum. Fila „Filme” vă permite să vizualizați elementele dintr-un tabel și valorile din aplicația dvs., precum și costul lunar estimat pe lună în fila Capacitate. Acest cod poate fi găsit pe pagina mea GitHub: https://github.com/adamfowleruk/nodejs-dynamodb-sample.
MongoDB, Apache HBase și Cassandra sunt trei baze de date NoSQL care sunt ideale pentru scalare orizontală. Deoarece structurile lor de date sunt mai orizontale, acest lucru facilitează adăugarea mai multor servere la sistem, eliminând în același timp nevoia de a le schimba. În plus, aceste baze de date sunt relativ noi, așa că sunt încă în curs de dezvoltare și perfecționare, ceea ce înseamnă că este posibil să se îmbunătățească în timp.
De ce este ușor să scalați Nosql?
Nosql este ușor de scalat, deoarece este proiectat pentru a fi scalabil pe orizontală. Aceasta înseamnă că se poate scala prin adăugarea mai multor noduri la un cluster nosql . Nosql este, de asemenea, ușor de scalat, deoarece poate gestiona cantități mari de date și un număr mare de interogări pe secundă.
Aplicațiile necesită un nivel ridicat de scalabilitate pentru a funcționa corect. Alegerea depozitelor de date cu o interfață de utilizator simplă și eficientă este la fel de importantă. Principalul punct de disputa este dacă folosirea unei baze de date „ASL” sau „Nosql” este mai bună. Bazele de date NoSQL, spre deosebire de bazele de date SQL, sunt populare deoarece sunt simplu de construit. Oprirea tuturor operațiunilor dintr-o bază de date NoSQL depinde în mod inerent de sharding. În general, fiecare operațiune de date necesită utilizarea unui operator de calificare, care poate fi folosit pentru a identifica un nod cu datele. Datele sunt stocate pe mai multe mașini și acest lucru face foarte simplă efectuarea operațiunilor de date chiar și pe cele mai mici mașini.

Ca rezultat, magazinele NoSQL se pot scala pentru a utiliza o mașină de mărfuri relativ simplă. Se presupune că utilizatorii vor planifica și structura datele în așa fel încât să poată fi preluate dintr-o singură mișcare de la același nod pentru a efectua o anumită operație pe baza de date NoSQL. Denormalizarea datelor în acest mod ar putea implica, de asemenea, că nodul este gata să ruleze date pre-gătite. Sunt posibile alăturari în NoSQL, dar nu sunt la fel de robuste precum îmbinările SQL. În lumea practică a NoSQL, designerii de aplicații cred că în cele din urmă va apărea consistența datelor. Pe lângă faptul că oferă comutatoare pentru a ajusta consistența în diferite sisteme NoSQL, multe sisteme NoSQL oferă rutine pentru a face coerența să pară mai proeminentă. O parte importantă a oricărei decizii de arhitectură este evaluarea cazului de utilizare și alegerea depozitului de date adecvat pe baza acelui caz.
Toate bazele de date Nosql sunt scalabile?
Ca rezultat al erelor internetului și cloud computing, bazele de date NoSQL au fost create pentru a facilita implementarea unei arhitecturi scale-out. scalabilitatea se realizează prin combinarea stocării datelor cu munca necesară procesării lor pe un număr mare de computere într-o arhitectură cu scalabilitate.
Sistemul ar trebui să poată gestiona baze de date extrem de mari la o latență foarte scăzută, gestionând și rate de solicitare foarte mari. Când vine vorba de site-uri web cu volum mare, cum ar fi eBay, Amazon, Twitter și Facebook, scalabilitatea și disponibilitatea ridicată sunt esențiale. Puteți rula mai multe instanțe ale unui server în același timp cu scalare orizontală.
Baza de date MongoDB este scalabilă atât pe orizontală, cât și pe verticală, atât în ceea ce privește scara, cât și numărul de utilizatori. În MongoDB, vă puteți scala clusterul pe verticală sau pe orizontală, adăugând mai multe resurse și împărțind datele în bucăți mai mici. Ca rezultat, MongoDB este o alegere populară pentru aplicațiile la scară largă și pentru depozitele de date.
Cele mai bune baze de date Nosql pentru scalare rapidă și volum mare de date
Alte baze de date NoSQL pot fi scalate pentru a satisface nevoile dumneavoastră specifice, la fel ca și alte baze de date. MongoDB, de exemplu, este un limbaj de programare popular, deoarece poate scala rapid și poate gestiona o mulțime de date. Depozitele de date bazate pe Redis sunt utilizate pe scară largă datorită capacităților și vitezei lor în memorie.
Scalare verticală Nosql
Bazele de date Nosql sunt scalabile pe orizontală, ceea ce înseamnă că pot gestiona un trafic crescut prin adăugarea mai multor noduri în sistem. Acest lucru este în contrast cu scalarea verticală, în care sistemul este scalat prin adăugarea mai multor resurse la un singur nod.
Fiecare bază de date trebuie să fie scalată pentru a gestiona volumul de date generate zilnic. Termenul „scalare” este clasificat în două tipuri: vertical și orizontal. Dacă doriți să stocați mai multe date, ar trebui să investiți într-un server de 2TB. Un singur server devine din ce în ce mai scump și mai mare. Procesul de adăugare a mașinilor la un server are ca rezultat scalarea orizontală. În acest caz, datele sunt împărțite într-un set și distribuite pe mai multe servere sau fragmente. Deoarece urmează modelul de-normalizării, nu este nevoie de un singur punct de adevăr. Această abordare poate să nu aibă ca rezultat o actualizare a informațiilor atunci când masterul nu reușește să efectueze o scriere, deoarece nu actualizează informațiile despre replicile slave atunci când masterul nu reușește să efectueze o scriere.
Ce este scalarea verticală în Sql?
Scopul abordării de scalare verticală este de a crește capacitatea unei singure mașini prin creșterea resurselor aceluiași server logic. Software-ul existent trebuie să fie actualizat cu resurse precum memoria, stocarea și puterea de procesare pentru a avea performanțe optime.
Cum să scalați baza de date pe orizontală
Ce este scalarea orizontală și cum funcționează? O metodă de scalare orizontală este una care necesită adăugarea de noduri suplimentare pentru a acomoda sarcina. Acest lucru este extrem de dificil cu bazele de date relaționale din cauza dificultății de a distribui datele aferente între noduri.
Pe lângă adăugarea mai multor instanțe pentru a partaja încărcarea, scalarea orizontală (sau extinderea) implică creșterea numărului de instanțe ale unei aplicații sau unui serviciu. În schimb, scalarea verticală necesită adăugarea mai multor resurse la instanță, cum ar fi puterea procesorului și memoria. Datorită protocoalelor care stau la baza HTTP, a majorității aplicațiilor web și a API-urilor, acestea pot fi scalate cu ușurință independent unele de altele. Unele baze de date vă permit acum să sincronizați și să partajați datele scrise între mai multe instanțe. Dacă traficul este direcționat în acest mod, mai multe resurse sunt dedicate articolelor cel mai frecvent solicitate. Deși proxy-urile inverse sunt utilizate în mod obișnuit pentru a gestiona cererile HTTP, bazele de date nu sunt întotdeauna folosite pentru a face acest lucru. Majoritatea bazelor de date pot fi redirecționate cu software precum nginx sau HAproxy, ambele putând fi făcute la nivel TCP.
Dacă proxy-ul dvs. poate înțelege cum funcționează conexiunile la nivel de protocol, poate determina dacă o replică citită nu este sincronizată sau nu poate reacționa chiar dacă conexiunea la rețea este activă. Traseul poate fi ajustat în funcție de încărcarea replicii, precum și de numărul de conexiuni. Există câteva servere proxy care pot îndeplini o varietate de funcții. Au fost făcute câteva progrese în volume persistente și revendicări, dar există și dificultăți inerente dacă nu selectați o bază de date care să evalueze fiecare instanță în mod egal. Deoarece containerele sunt mutate în jurul clusterului, repornirea uneia dintre replicile citite ar trebui să fie în regulă. Dacă acest lucru se întâmplă cu baza de date principală , este puțin probabil să fii încântat.