
Diferitele tipuri de clustere de calculatoare
Publicat: 2023-02-16În informatică, un cluster este un grup de sisteme informatice independente care lucrează împreună, astfel încât, în multe privințe, pot fi privite ca un singur sistem. Clusterele sunt de obicei implementate pentru a îmbunătăți performanța și disponibilitatea față de cea a unui singur computer, în timp ce sunt de obicei mult mai rentabile decât computerele individuale cu viteză sau disponibilitate comparabilă. Există diferite tipuri de clustere de computere, inclusiv clustere de calcul de înaltă performanță, clustere de computere utilizate în scopuri comerciale și clustere de stocare. În fiecare tip de cluster, sistemele componente lucrează împreună pentru a îndeplini o sarcină sau sarcini comune. Clusterele de calcul de înaltă performanță (HPC) sunt utilizate pentru aplicații științifice și de inginerie care necesită o mare putere de calcul și/sau stocare de date. Aceste clustere constau de obicei dintr-un grup de computere de bază, conectate printr-o rețea locală rapidă (LAN). Calculatoarele dintr-un cluster HPC rulează de obicei același sistem de operare (OS) sau similar și au aceleași componente hardware sau similare. Clusterele comerciale sunt folosite pentru a rula aplicații de afaceri care necesită un grad ridicat de disponibilitate și/sau scalabilitate. Aceste clustere constau adesea din servere care rulează o varietate de sisteme de operare și au o varietate de componente hardware. În multe cazuri, serverele dintr-un cluster comercial sunt, de asemenea, conectate la o rețea de stocare (SAN), astfel încât să poată accesa depozitele de date comune. Clusterele de stocare sunt folosite pentru a oferi un depozit de stocare centralizat care poate fi accesat de un grup de computere. Clusterele de stocare constau de obicei dintr-un grup de servere de stocare care sunt conectate la un SAN. Serverele dintr-un cluster de stocare rulează de obicei o varietate de sisteme de operare și au o varietate de componente hardware.
Ce este un cluster mongodb fragmentat și care este rostul conectării la unul în MongoDB? Cum mă conectez la unul sau doar la localhost? Medalia de aur este acordată în insigna Noob 7461. Au fost produse zece insigne de argint și 23 de insigne de bronz. Un cluster replicat este format din zece servere, cu unul pentru interfața mongos, trei pentru fiecare set de replici și unul pentru fiecare set de replici de server de configurare. Într-un sistem de replicare, o componentă este duplicată, astfel încât să existe întotdeauna o copie de rezervă dacă ceva nu merge bine. Toate cioburi trebuie să fie replici pentru a putea fi fabricate.
Un cluster mongodb, de exemplu, este folosit în mod obișnuit pentru a descrie un cluster fragmentat în MongoDB. Un mongodb sharded servește următoarele funcții: Scale citește și scrie de la mai multe noduri. Deoarece fiecare nod nu gestionează întregul set de date, puteți particționa datele doar în regiuni din fragment.
Un cluster de baze de date , după cum sugerează și numele, este o colecție de baze de date care poate fi rulată de o instanță a unui server de baze de date care rulează. Postgres, care înseamnă baza de date „implicit” în PostgreSQL, va fi inclusă ca bază de date implicită într-un cluster de baze de date după ce a fost creată.
Un cluster MongoDB poate fi denumit și „set de replică” sau „cluster fragmentat”. Într-un set de replici, mai multe servere transportă copii ale acelorași date. Nodurile dintr-un set de replică sunt de obicei trei. Când o aplicație client efectuează orice operațiuni pe un nod, toate citirile și scrierile sunt trimise la acel nod; dacă ceva nu merge bine, două noduri secundare îl protejează.
Clusterul și baza de date sunt aceleași?
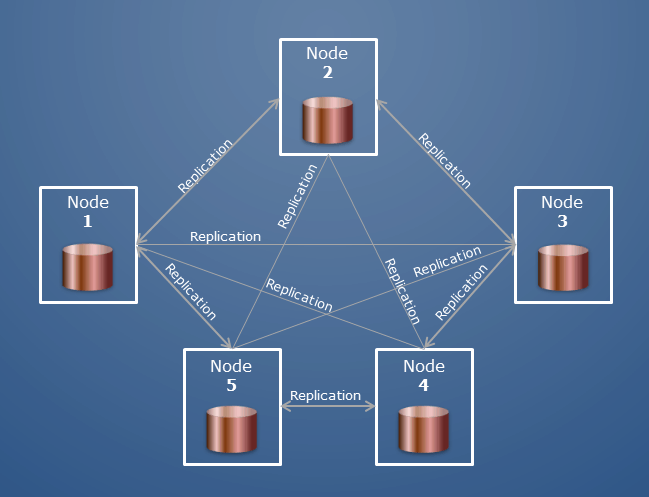
Există mai multe grupuri de gazde care alcătuiesc un cluster. Gazdele unui cluster fragmentat sunt clasificate într-o varietate de roluri. O bază de date este o colecție de colecții; în Oracle, ar fi echivalent cu o bază de date și o aschemă.
Un cluster de baze de date este o colecție de servere sau instanțe care conectează o bază de date la alta. Gruparea bazelor de date este utilizată de servere dintr-o varietate de motive, dintre care principalele sunt redundanța datelor, echilibrarea încărcăturii, disponibilitatea ridicată și monitorizarea și automatizarea. În consecință, dacă un computer eșuează, toate datele noastre vor fi disponibile altora, oferindu-ne avantajul redundanței datelor. Cu clustering, există o oportunitate de a automatiza multe dintre procesele bazei de date, creând în același timp reguli pentru a identifica potențialele probleme. În arhitectura cluster, toate cererile sunt direcționate către un număr de computere, fiecare dintre acestea fiind capabil să gestioneze cererea și să o producă pentru utilizator. Un cluster de failover sau de înaltă disponibilitate reproduce serverele și reconfigurează hardware-ul pentru a asigura disponibilitatea serviciului. Aceste tipuri de clustere sunt profitabile pentru utilizatorii de computere care se bazează complet pe sistemele lor. Scopul clusterelor de înaltă performanță este de a crește capacitatea rețelei, în același timp îmbunătățind performanța.
Într-un sistem distribuit Hadoop, nodurile acționează ca centre de stocare și procesare a datelor. Distincția principală dintre un cluster și un server este că clusterul folosește mai multe noduri care comunică între ele pentru a efectua un set de operațiuni. Un cluster conține un număr de noduri care vor efectua un set de operații. Sistemul distribuit Hadoop poate suporta până la 10.000 de baze de date. Rezultate similare de interogare pot fi obținute atunci când datele din mai multe tabele din aceeași bază de date sunt combinate într-o interogare din mai multe baze de date din același cluster.
Beneficiile Cluste
Folosind un cluster, puteți gestiona cu ușurință mai multe baze de date, oferind spațiu de stocare uniform pentru tabele și coloane pentru toate. Acest lucru îmbunătățește performanța și integritatea datelor și, astfel, face sistemul mai eficient.
Unde este numele clusterului în Mongodb?
Nu există un răspuns stabilit pentru această întrebare, deoarece numele clusterului poate fi găsit în locuri diferite, în funcție de tipul de cluster MongoDB utilizat. De exemplu, într-un set de replică, numele clusterului este de obicei stocat în colecția local.system.replset, în timp ce într-un cluster fragmentat se găsește de obicei în colecția config.shards.
MongoDB Atlas este o ofertă MongoDB-as-a-Service NoSQL Database-as-a-Service care este disponibilă în cloud-urile publice Microsoft Azure, Google Cloud Platform și Amazon Web Services. Puteți crea un cluster MongoDB funcțional în câteva minute folosind browserul dvs. web preferat făcând clic pe un link pentru a-l configura. Nu este nevoie să instalați software pe stația dvs. de lucru pentru a vă conecta la web prin intermediul acestuia și puteți utiliza interfața web pentru a face acest lucru. Când seturile de replici MongoDB sunt utilizate împreună cu mai multe servere MongoDB, sunt asigurate redundanța datelor și disponibilitatea ridicată. Clusterul MongoDB are capacitate suplimentară de operațiuni de citire, permițându-i să direcționeze clienții către servere suplimentare. Într-o replicare, unul sau mai mulți membri ai setului de replică sunt replicați asincron de la oplog-ul nodului primar la secundar, permițând setului de replică să funcționeze în ciuda oricăror potențiale defecțiuni ale membrilor săi. În MongoDB, puteți efectua operațiuni suplimentare de citire și scriere în plus față de comenzile standard de intrare și ieșire.
În cele mai multe cazuri, nodul primar este sursa tuturor operațiunilor de citire, dar rutarea către secundare poate fi configurată. Riscul de date potențial învechite este mai mare atunci când cel mai apropiat nod este un nod secundar. Pentru ca scrierea să se propagă cu succes în cluster, va trebui să includeți opțiuni pentru scrierea datelor într-un set de replica MongoDB. Ca parte a acestui proces, pentru inserare trebuie adăugată o proprietate de referință la scriere. Când se primește o solicitare de scriere, clusterului i se cere să recunoască faptul că a avut succes în marea majoritate a nodurilor purtătoare de date. Configurația unui cluster fragmentat îi permite să fie configurat și ca set de replică. Un set de replică conține atât procese mongod primare, cât și secundare. Dacă masterul eșuează, se recomandă ca numărul total al acestor procese să fie impar pentru a se asigura că majoritatea este efectuată.
Clusterele MongoDB , după cum sugerează și numele, sunt clustere de noduri care lucrează împreună pentru a stoca și gestiona date. Când creați un cluster MongoDB, specificați câte noduri să includeți și pentru ce trebuie să fie configurate. Vă puteți conecta aplicația la clusterul dvs. MongoDB cu Node odată ce este creată. MongoDB Compass poate fi considerat un driver pentru biblioteca MongoDB JS sau un driver PyMongo pentru MongoDB. Principalul avantaj al conectării aplicației la un cluster este că poate citi și scrie date în acesta. Cu MongoDB Compass, vă puteți explora, modifica și vizualiza datele într-o varietate de moduri. Un exemplu despre cum vă puteți vizualiza datele poate fi găsit într-o grilă, care vă permite să observați cum se schimbă datele în timp și cine distribuie datele în clusterul dvs.
Unde este clusterul în Mongodb Atlas?
Nu există un răspuns definitiv la această întrebare, deoarece locația unui cluster în MongoDB Atlas poate varia în funcție de o serie de factori, inclusiv regiunea geografică în care se află și nevoile specifice ale aplicației pe care o alimentează. Cu toate acestea, în general, un cluster în MongoDB Atlas poate fi găsit în secțiunea „Clustere” a consolei MongoDB Atlas.
Un cluster poate fi fie un set de replică, fie un set fragmentat. Numărul total de noduri ale fiecărui proiect este constrâns de o constrângere specifică bazată pe gama lor de funcții în regiuni. Fiecare proiect Atlas poate implementa până la 25 de baze de date. Vă rugăm să contactați administratorii bazei de date pentru orice întrebări despre limita de implementare a bazei de date. Versiunea TLS 1.2 este versiunea TLS implicită pentru clusterele create după 1 iulie 2020.

Ce este un cluster în Mongodb
În MongoDB, un cluster este un grup de servere de baze de date care mențin copii ale acelorași date. Fiecare server dintr-un cluster este denumit nod. Un cluster poate avea unul sau mai multe noduri.
Pentru ce este gruparea bazelor de date? Procesul de conectare a mai multor servere sau instanțe la o singură bază de date este denumit conexiune SQL. În MongoDB, un cluster este fie un set de replică, fie un cluster fragmentat, în funcție de tipul de MongoDB. Voi trece peste fiecare dintre aspectele distincte ale acestor grupuri mai detaliat în paragrafele următoare. Datorită echilibrării încărcării MongoDB și a numărului de mașini, acesta are un nivel ridicat de disponibilitate. Un cluster poate fi utilizat pentru a automatiza multe procese de baze de date, permițând, de asemenea, crearea de reguli pentru a alerta probleme potențiale. O bază de date MongoDB poate fi împărțită în două tipuri: seturi de replici și clustere de fragmentare.
Datele sunt stocate pe mai multe mașini într-un fragment. Metoda MongoDB de a oferi scalabilitate a datelor se bazează pe aceasta. Acest lucru reduce timpul necesar pentru a gestiona cantități mari de date. Datorită cantității de date oferite de replici, aplicațiile distribuite pot beneficia și de ele.
Problemele de performanță și conflictul de date pot apărea dacă mai multe proiecte Atlas sunt implementate în același cluster. Atlas vă recomandă să utilizați un singur cluster gratuit pentru fiecare proiect Atlas. Un instrument bun de grupare a datelor este necesar într-o gamă largă de aplicații de analiză și extragere a datelor. Pentru a evita potențialele probleme de performanță și conflictele de date în proiectele Atlas, Atlas vă recomandă să utilizați un singur cluster gratuit per proiect.
Arhitectura Cluster Mongodb
Un cluster MongoDB este un grup de servere MongoDB care lucrează împreună pentru a vă păstra datele. Fiecare server dintr-un cluster este numit nod. Un cluster poate avea orice număr de noduri. Un cluster este alcătuit dintr-un set de replică, care este un grup de noduri care au fiecare o copie a datelor dvs. Un set de replică are cel puțin trei noduri, astfel încât, dacă un nod se defectează, datele dvs. sunt încă disponibile.
Arhitectura seturilor de replici este un factor important în capacitatea și capacitatea MongoDB. Clusterele MongoDB sunt de obicei distribuite în trei replici de noduri. Recuperarea bazei de date după un dezastru trebuie să fie constant stabilă, mai ales după un dezastru. Una dintre cele mai bune modalități de a implementa un cluster fragmentat este utilizarea unei strategii de replicare. Datele conținute în cheile Shard trebuie distribuite în același mod. Ar trebui să scalați baza de date pe orizontală și să reduceți numărul de operațiuni care pot fi efectuate pe o singură instanță. Cu puține fragmente, operațiunile de citire și scriere pot deveni lente din cauza faptului că numărul de fragmente limitează numărul de operațiuni.
Fiecare parte de date dintr-un fragment este alcătuită dintr-un subset al acelei piese bazate pe un set specific de criterii. Este obișnuit ca numărul minim de fragmente necesare pentru a obține semnificația fragmentării să fie de două. Interogările scatter-gather ar trebui utilizate numai dacă pot fi utilizate concomitent unele cu altele pe toate fragmentele. Atunci când selectați un grup, este esențial să aveți cel puțin șapte membri cu drept de vot pentru ca procesul electoral să fie cât mai simplu posibil. Dacă aveți doar șapte sau mai puțini membri cu drept de vot, dar un număr egal de membri, trebuie folosit arbitrul. Arbitrii nu stochează copii de date, rezultând mai puține resurse necesare pentru procesarea datelor. Utilizarea numelui de gazdă DNS logic mai degrabă decât a adresei IP este preferată atunci când configurați membrii setului de replici sau membrii clusterului sharded. Deoarece unele conexiuni ale setului de replică ale grupului de drivere sunt după nume de seturi de replică, aceste nume ar trebui utilizate separat pentru seturi. Distribuția geografică a nodurilor setului de replici este ideală pentru a aborda redundanța redundantă și pentru a asigura toleranța la erori dacă unul dintre centrele de date este absent.
Numele clusterului Mongodb
Un cluster MongoDB este un grup de servere MongoDB care lucrează împreună pentru a oferi disponibilitate și scalabilitate ridicate. Un cluster are de obicei un server primar care acționează ca server principal și unul sau mai multe servere secundare care acționează ca sclavi. Serverul primar conține datele, iar serverele secundare copiază datele de pe serverul principal.
Programele de baze de date orientate spre documente sunt create pentru stocare de mare volum cu ajutorul MongoDB, un program multiplatform. MongoDB, un program de baze de date NoSQL, este clasificat ca atare deoarece folosește documente în stil JSON cu scheme opționale. Puteți îmbunătăți performanța instalând baza de date în același centru de date cu celelalte resurse DigitalOcean. Regiunea are unul sau mai multe centre de date și fiecare are propria sa rețea VPC. Tipul de mașină, numărul și dimensiunea nodurilor bazei de date pot fi toate selectate. Cu alte cuvinte, puteți adăuga până la două noduri de așteptare în cluster. Adăugați un nume de proiect, completați-l și utilizați orice etichete pe care doriți să le utilizați atunci când îl creați. Un cluster poate dura până la cinci minute.
Puterea Mongodb Atlas Cluste
MongoDB Atlas Cluster este o soluție de bază de date NoSQL ca serviciu în cloud public care rulează în MongoDB. Este o platformă de date robustă, scalabilă, care vă permite să creați și să implementați rapid aplicații. Folosind MongoDB Atlas Cluster, vă puteți conecta în siguranță la MongoDB din orice locație din lume.
Cum se creează un cluster în Mongodb
Utilizați următorii pași pentru a crea un cluster în MongoDB:
1. Alegeți o topologie de implementare.
2. Selectați tipul de set de replică pe care doriți să îl implementați.
3. Alegeți numărul de seturi de replici pe care doriți să le implementați.
4. Configurați seturile de replici.
5. Conectați-vă la routerul mongos.
6. Configurați cheia shard.
7. Addshards la cluster.
8. Verificați dacă clusterul este funcțional.
MongoDB Atlas este un nivel gratuit al MongoDB, care este serviciul de baze de date cloud complet gestionat de MongoDB. Serviciul este conceput pentru sarcinile de lucru ale întreprinderilor, precum și pentru clustere globale . Nu trebuie să creați un cont cu Amazon Web Services (AWS), Google Cloud Platform sau Microsoft Azure. Acesta vă va solicita să vă creați un cont de administrator pentru a accesa serviciul. Pentru a accesa serviciul, un cluster trebuie să fie legat la o adresă IP. Setările de securitate implicite ale MongoDB Atlas împiedică toate conexiunile externe. Parola dvs. nu trebuie să aibă caractere speciale și doar caractere alfanumerice pentru a facilita conectarea la Studio 3T. Când creați un șir de conexiune pentru MongoDB, caracterele speciale trebuie să fie codificate. La Pasul 1, alegeți Java din lista derulantă DRIVER și apoi din lista derulantă VERSIUNE. Dacă selectați driverul și versiunea, serviciul va actualiza automat șirul de conexiune la Pasul 2.
Clustering Mongodb: o opțiune excelentă pentru un debit la cerere mare
Folosind clusteringul MongoDB , puteți îndeplini cerințele ridicate de debit, disponibilitate și debit pentru medii mari. Clusterele MongoDB pot fi configurate pentru a suporta o gamă largă de tipuri de seturi de replici MongoDB, de la setări simple cu un singur nod până la configurații cu mai multe noduri foarte disponibile.
Tutorial Mongodb Cluster
Un cluster MongoDB este un grup de servere MongoDB care lucrează împreună pentru a vă păstra datele. Un cluster MongoDB poate fi la fel de mic ca un singur server sau la fel de mare ca sute de servere. Când creați un cluster MongoDB, specificați numărul de servere (noduri) pe care le doriți în cluster. Fiecare nod dintr-un cluster MongoDB stochează un subset al datelor dvs. Clusterele MongoDB sunt proiectate pentru a fi scalabile și pentru a oferi disponibilitate ridicată. Puteți adăuga oricând noduri la un cluster pentru a crește capacitatea acestuia sau pentru a înlocui un nod eșuat. Când eliminați un nod dintr-un cluster, celelalte noduri redistribuie datele din nodul eliminat, astfel încât datele să fie în continuare distribuite uniform în cluster.
Ghidul Ușor al Hevo pentru Clustering MongoDB este primul pas. Când o bază de date este prea mică sau prea lentă pentru a rula un sistem, operațiunile unei organizații continuă. MongoDB are numeroase funcții avansate care au fost concepute pentru cloud, cum ar fi fragmentarea și replicarea. MongoDB face posibilă stocarea mai multor copii ale acelorași date, făcându-le extrem de accesibile. Dacă un server eșuează, datele de la celălalt pot fi recuperate imediat. Puteți automatiza, simplifica și îmbogăți procesul de replicare a datelor utilizând Hevo Data. Replicarea datelor este simplă și ușor de utilizat atunci când aveți acces la versiunea noastră de încercare gratuită de 14 zile.
Pentru a configura clusterele MongoDB, trebuie mai întâi să instalați toate cele trei componente necesare. Cu platforma Hevo automatizată, fără cod, puteți urmări tot ceea ce trebuie să faceți pentru o experiență de replicare a datelor fără probleme. Pentru a asigura disponibilitatea maximă, trebuie să fie prezente mai multe servere de configurare sau routere. Când routerul determină în ce fragment sunt găzduite datele, trimite cereri către clusterul corespunzător. În procesul de stabilire a clusterelor MongoDB, vor fi necesari următorii pași pentru a adăuga fragmente la acestea. Într-o configurație în cluster, portul 27018 este utilizat ca implicit pentru serverele shard. Înseamnă că este mai degrabă un server shard decât un server de configurare.