
Factorii de diferențiere ai Hadoop: scalabilitate la sursă deschisă și toleranță la erori
Publicat: 2022-11-18Hadoop este un cadru de software open-source pentru stocarea distribuită și procesarea seturilor mari de date pe grupuri de computere. Este proiectat să se extindă de la un singur server la mii de mașini, fiecare oferind calcul și stocare locală. În loc să se bazeze pe hardware pentru a oferi o disponibilitate ridicată, cadrul este conceput pentru a detecta și gestiona defecțiunile la nivelul aplicației. Hadoop este o bază de date nosql, deoarece folosește o arhitectură complet diferită de o bază de date relațională tradițională. Hadoop este proiectat să se scaleze pe orizontală, ceea ce înseamnă că se poate scala pentru a găzdui mai multe date prin adăugarea mai multor servere de mărfuri la cluster. Hadoop este, de asemenea, conceput pentru a fi tolerant la erori, ceea ce înseamnă că, dacă un server din cluster se defectează, sistemul poate continua să funcționeze fără acel server.
Hadoop nu este folosit pentru stocarea datelor și nici nu necesită utilizarea stocării relaționale; mai degrabă, este folosit pentru a stoca cantități mari de date pe servere distribuite. O bază de date Hadoop este mai degrabă un tip de date decât un sistem software care permite calculul paralel masiv. Este un tip de bază de date NoSQL de legare (cum ar fi HBase) care permite utilizatorilor să interogheze și să caute baze de date într-o varietate legată. RDBMS, în forma sa actuală, nu ar putea concura cu Hadoop, deoarece este capabil să gestioneze atât datele relative, cât și cele tranzacționale. Hadoop are capacitatea de a gestiona orice tip de date, fie că sunt structurate, semi-structurate sau nestructurate, și acceptă o gamă largă de metode. Analiza datelor mari oferă companiilor un avantaj competitiv în lumea reală, oferind informații mai profunde. Hadoop, ca serviciu, acceptă utilizarea procesării analitice online (OLAP) în procesarea datelor. Este important să rețineți că viteza procesului de date este determinată de numărul de solicitări de date. Puteți folosi Hadoop dacă nu doriți tranzacții ACID sau suport OLAP, de exemplu.
Hadoop și bazele de date în memorie sunt două tehnologii complet diferite care se suprapun. Nu sunt la fel, dar sunt de acord asupra unor lucruri.
Aplicațiile analitice care utilizează SQL-on- Hadoop combină metodele de interogare în stil SQL consacrate cu elemente mai noi ale cadrului de date Hadoop . SQL-on- Hadoop permite dezvoltatorilor de întreprinderi și analiștilor de afaceri să colaboreze pe clustere Hadoop cu interogări familiare SQL.
Este o bază de date NoSQL care oferă un mijloc pentru stocarea și preluarea datelor. Non-relațional/non-SQL este unul dintre termenii folosiți în mod obișnuit în acest spațiu.
Datele sunt gestionate în diferite moduri de Hadoop și SQL. SQL este un limbaj de programare, în timp ce Hadoop este un cadru de componente în software. Ambele instrumente sunt utile pentru big data, dar au dezavantaje. Platforma Hadoop poate gestiona un set mult mai mare de date, dar scrie date o singură dată.
Care este diferența dintre Hadoop și Nosql?
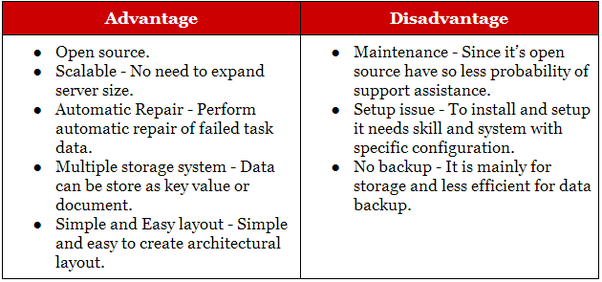
Hadoop este potrivit pentru aplicațiile de arhivare analitică și istorică, în timp ce NoSQL este ideal pentru sarcinile de lucru operaționale care completează omologii lor relaționali. Bazele de date NoSQL au început ca baze de date de stocare cheie-valoare , dar mai târziu, bazele de date document/json și graph li s-au alăturat.
Procesarea în timp real, datele mari și datele nestructurate sunt doar câteva dintre scenariile în care tehnologia NoSQL poate fi utilizată. Ca urmare, unele dintre aceste provocări, cum ar fi scalabilitatea și disponibilitatea, pot fi abordate. Baza de date NoSQL are o serie de avantaje față de baza de date relațională tradițională. Ei pot procesa seturi de date într-un mod mult mai rapid și mai scalabil decât anterior. Sistemele de administrare a bazelor de date folosesc, de asemenea, mai puține cunoștințe și expertiză decât bazele de date tradiționale , ceea ce le face mai ușor de utilizat. O bază de date NoSQL are o varietate de avantaje față de o bază de date relațională tradițională. Cel mai important lucru de luat în considerare este dacă le aveți nevoie pentru procesarea în timp real și pentru seturi mari de date.
Bazele de date Nosql sunt alegerea mai bună pentru companiile cu sarcini de lucru mari de date
Dacă sarcinile dvs. de lucru de date sunt mai concentrate pe analizarea și procesarea unor cantități mari de date variate și nestructurate, cum ar fi Big Data, bazele de date NoSQL sunt o alegere mai bună. Spre deosebire de bazele de date relaționale , bazele de date NoSQL nu se bazează pe un model de schemă fix. RDBMS este mai flexibil decât RDBMS-urile tradiționale în ceea ce privește stocarea, procesarea și gestionarea datelor, ceea ce îl face o opțiune mai bună pentru companiile care au nevoie de capacitatea de a accesa rapid cantități mari de date și au nevoie să le stocheze pe termen nelimitat.
Big Data este Sql sau Nosql?

Dacă sarcinile dvs. de lucru de date sunt în primul rând preocupate de procesarea și analizarea rapidă a unor cantități mari de date diverse și nestructurate, cum ar fi Big Data, NoSQL este cel mai bun pariu. Modelul bazei de date NoSQL este unic prin faptul că nu se bazează pe aceeași structură de schemă ca o bază de date relațională.
Nu se mai pune problema dacă big data va îmbunătăți producția; este o chestiune de când. În big data, există cantități vaste, diverse și complexe de date structurate și nestructurate disponibile. Senzorii, camerele de la producția și dispozitivele de consum pot fi folosite pentru a colecta date mari în producție. Deoarece majoritatea datelor din producție sunt nestructurate, arhitecturile NoSQL nu pot concura cu abordări rigide precum SQL. O bază de date NoSQL nu necesită scheme pentru a stoca date în același tabel de bază de date, permițând utilizatorilor să stocheze date în diferite structuri. Linia de separare a unei companii poate fi determinată de câte date intenționează să utilizeze. Tranzacțiile trebuie să respecte patru principii fundamentale de funcționare pentru a fi considerate o tranzacție de bază de date relaționale.
Deoarece sistemele NoSQL și sistemele cloud pot fi integrate, este o idee bună să folosiți cadre de cloud computing pentru a sprijini sistemele NoSQL. Optimizarea procesului de producție în timp real prin NoSQL poate fi realizată prin integrarea cu Manufacturing Execution Systems (MES). Acest succes a fost posibil prin utilizarea analizei de date mari pentru a produce răspunsuri mai rapide la condițiile în schimbare. MongoDB este o bază de date NoSQL bună, deoarece este simplu de configurat și poate fi folosită pentru analiză. Utilizarea arhitecturilor de baze de date cu răspuns mai rapid, cum ar fi NoSQL, permite managementului să efectueze simulări mai bune, permițându-le să ia decizii mai bune despre produse în lumea reală. Bazele de date B2B sunt vulnerabile la atacuri între site-uri, precum și la atacuri prin injecție și atacuri de forță brută. Un atac de injecție are loc atunci când un atacator adaugă date la comenzile de interogare NoSQL sau la instrucțiunile de stocare.

Sectorul de producție este preocupat în special de securitatea arhitecturii NoSQL. Dacă un atac de refuzare a serviciului sau un atac de injecție este livrat cu succes, un producător poate fi capabil să modifice specificațiile. Din acest motiv, concurenții pot obține un avantaj pe o piață extrem de competitivă.
Procesele de afaceri care se bazează pe date în timp real devin din ce în ce mai frecvente pe măsură ce companiile caută modalități de a-și îmbunătăți eficiența și receptivitatea la nevoile clienților. Bazele de date NoSQL bazate pe cloud, cum ar fi Cloud Bigtable, oferă o modalitate rapidă și eficientă de a stoca și accesa seturi mari de date, făcându-le o soluție excelentă pentru aceste tipuri de aplicații.
Cloud Bigtable este un serviciu de baze de date NoSQL care este complet gestionat și oferă un timp de funcționare de 99,999%. Este ideal pentru sarcinile de lucru analitice și operaționale, deoarece are viteze mari de alimentare a datelor și este ușor de scalat în sus și în jos. Ca rezultat, este o alegere excelentă pentru procesarea datelor în timp real în aplicații precum jocurile mobile și analiza de retail.
Este Nosql cea mai bună bază de date pentru date mari?
MongoDB, de exemplu, este o alegere excelentă pentru stocarea unor cantități mari de date. Acestea permit o gamă largă de scenarii de procesare agilă și de înaltă performanță. În plus, datele nestructurate sunt stocate în baze de date NoSQL pe mai multe noduri de procesare și pe mai multe servere. Drept urmare, bazele de date NoSQL au fost alegerea implicită a unora dintre cele mai mari depozite de date din lume. Care bază de date este cea mai bună pentru date mari? Când vine vorba de această întrebare, nu este posibil să prezicem care bază de date este cea mai bună pentru date mari din cauza nevoilor variate ale organizației. Amazon Redshift, Azure Synapse Analytics, Microsoft SQL Server, Oracle Database, MySQL, IBM DB2 și multe alte baze de date sunt printre cele mai populare opțiuni pentru stocarea de date mari.
Hadoop este o bază de date
Hadoop este un sistem de fișiere distribuit și un cadru pentru rularea aplicațiilor pe grupuri mari de hardware de bază. Hadoop nu este o bază de date.
Hadoop, un cadru open-source, permite stocarea și procesarea eficientă a seturilor masive de date. Tabelele Hive și Imperative pot fi create folosind fișiere text în HDFS. Acceptă cele trei formate majore de fișiere: fișiere de secvență, fișiere de date Avro și fișiere Parquet. O serie de octeți este reprezentată de serializarea datelor ca unitate de memorie. Avro, un cadru eficient de serializare a datelor, este susținut pe scară largă de Hadoop și ecosistemul său.
Utilizarea fișierelor text ca format de stocare pentru tabelele Hive și Implicit simplifică gestionarea și manipularea datelor. Ca rezultat, este o alegere bună pentru procesarea în loturi sau stocarea datelor într-o varietate de formate. În plus, serializarea datelor prin Avro permite stocarea și recuperarea datelor care sunt atât eficiente, cât și convenabile. Ca rezultat, este o opțiune bună pentru stocarea datelor într-o varietate de formate sau pentru efectuarea procesării paralele.
Hadoop vs Nosql
Hadoop gestionează date mari pentru un cluster de hardware de bază. Dacă funcționalitatea nu corespunde nevoilor dumneavoastră sau nu este funcțională, aceasta poate fi modificată. Acesta este denumit NoSQL și este un tip de sistem de gestionare a bazelor de date care stochează date structurate, semi-structurate și nestructurate.
MongoDB, ca bază de date NoSQL (Nu numai SQL), a fost creată în 2007 ca rezultat al dezvoltării C++. Un Hadoop este o colecție de programe software open-source care sunt scrise în principal în Java pentru procesarea datelor mari. Această platformă include, de asemenea, căutare în text integral, instrumente avansate de analiză și un limbaj de interogare ușor de utilizat. Deși Hadoop este cel mai bine cunoscut pentru capacitatea sa de a stoca și procesa cantități mari de date, face acest lucru și în loturi mici. MongoDB oferă o varietate de instrumente de procesare a datelor în timp real. Conectorii MongoDB pentru instrumente externe, cum ar fi Kafka și Spark, simplifică asimilarea și procesarea datelor. Când vine vorba de manipularea datelor, Hadoop și MongoDB oferă o gamă largă de avantaje față de bazele de date tradiționale. Hadoop este un instrument excelent pentru a face față structurilor mari de date datorită sistemului său de fișiere distribuit. MongoDB este singura bază de date care poate fi folosită ca înlocuitor pentru bazele de date tradiționale.
Este Spark o bază de date Nosql
În documentație, se precizează că un NoSQL DataFrame este un Spark DataFrame bazat pe formatul Spark pentru stocarea datelor. Spre deosebire de sursele de date anterioare, aceasta acceptă tăierea și filtrarea datelor (push-down de predicat), permițând interogărilor Spark să interogheze mai puține date și să încarce numai datele necesare, după cum este necesar.
Este esențial să mențineți conștientizarea tactică atunci când utilizați bazele de date Apache Spark și NoSQL ( Apache Cassandra și MongoDB) împreună într-o aplicație. Acest blog se concentrează pe modul de utilizare a Apache Spark într-o aplicație NoSQL. CassandraLand și MongoLand la TCP/IP sPark sunt două dintre cele mai populare plimbări și este un loc grozav de vizitat dacă vă plac parcurile tematice. În timp ce căutăm datele Departamentului de Energie, aplicația noastră Spark a început să-și învârtească roțile. Iată o lecție rapidă despre cât de importantă este secvența de taste Cassandra atunci când vine vorba de interogare. Există și roller coasterul Partitioner la CassandraLand. Clienții care se bucură de roller coasters își pot împărtăși informațiile cu operatorii de călătorii, astfel încât să poată urmări cine le-a călătorit zilnic.
Prima lecție din Lecția 1 MongoDB este gestionarea corectă a conexiunilor MongoDB. Când trebuie să actualizați informații despre noul statut de membru al parcului al Departamentului de Energie, indicii Mongo sunt extrem de folositori. În calitate de client MongoDB sau Spark, ar trebui să mențineți o conexiune și indexuri adecvate în cazul actualizărilor de sistem.