
Formatul de date HDF5: o opțiune atractivă pentru stocarea și gestionarea colecțiilor mari de date
Publicat: 2023-02-13HDF5 este un format de date conceput pentru stocarea și gestionarea colecțiilor de date mari și complexe. Este folosit frecvent în aplicații științifice și de inginerie, iar popularitatea sa a crescut în ultimii ani. HDF5 nu este o bază de date, dar poate fi folosit pentru a stoca date într-un format ierarhic care este similar cu un sistem de fișiere. Acest lucru face HDF5 o opțiune atractivă pentru aplicațiile care trebuie să stocheze și să gestioneze cantități mari de date.
Puteți extrage metadate și date brute din fișierele HDF5 și netCDF4 și puteți utiliza streaming Hadoop pentru a analiza datele Hadoop utilizând driverul de fișier virtual (VFD) HDF5 Connector Hadoop Distributed File System (HDFS).
Hdf5 este o bază de date?
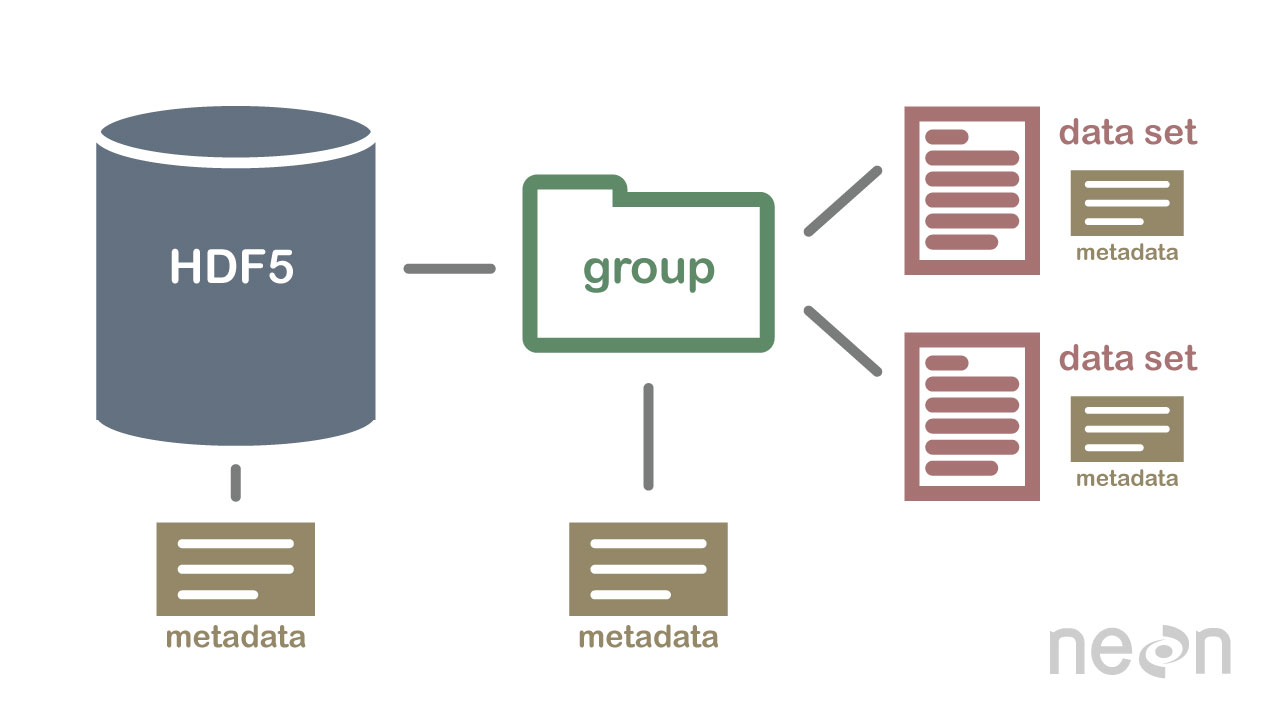
HDF5 nu este o bază de date, dar poate fi folosit pentru a stoca date într-o structură ierarhică, similară unui sistem de fișiere. HDF5 poate fi folosit pentru a stoca date într-o varietate de formate, inclusiv text, imagini și date binare .
Datele în format ierarhic (HDF5) sunt extrem de utile în cercetarea științifică. Sistemul de fișiere HDF5, deoarece este similar cu un sistem de fișiere în felul în care este foarte eficient, este un format excelent. Când vine vorba de date codificate în acest format, poate fi dificil să le accesezi. Acest ghid vă va prezenta modul în care Apache Drill vă poate ajuta să accesați și să interogați cu ușurință seturile de date HDf5. Drill are acces la fișierele HDF5 individuale prin opțiunea defaultPath. Acest lucru se realizează fie prin executarea directă a funcției table() în timpul interogării, fie prin intermediul configurației. Rezultatele acestei interogări pot fi găsite în tabelul de mai jos. Drill poate selecta apoi coloanele și le poate filtra individual, filtrate, agregate sau combinate cu alte date pe care le poate interoga.
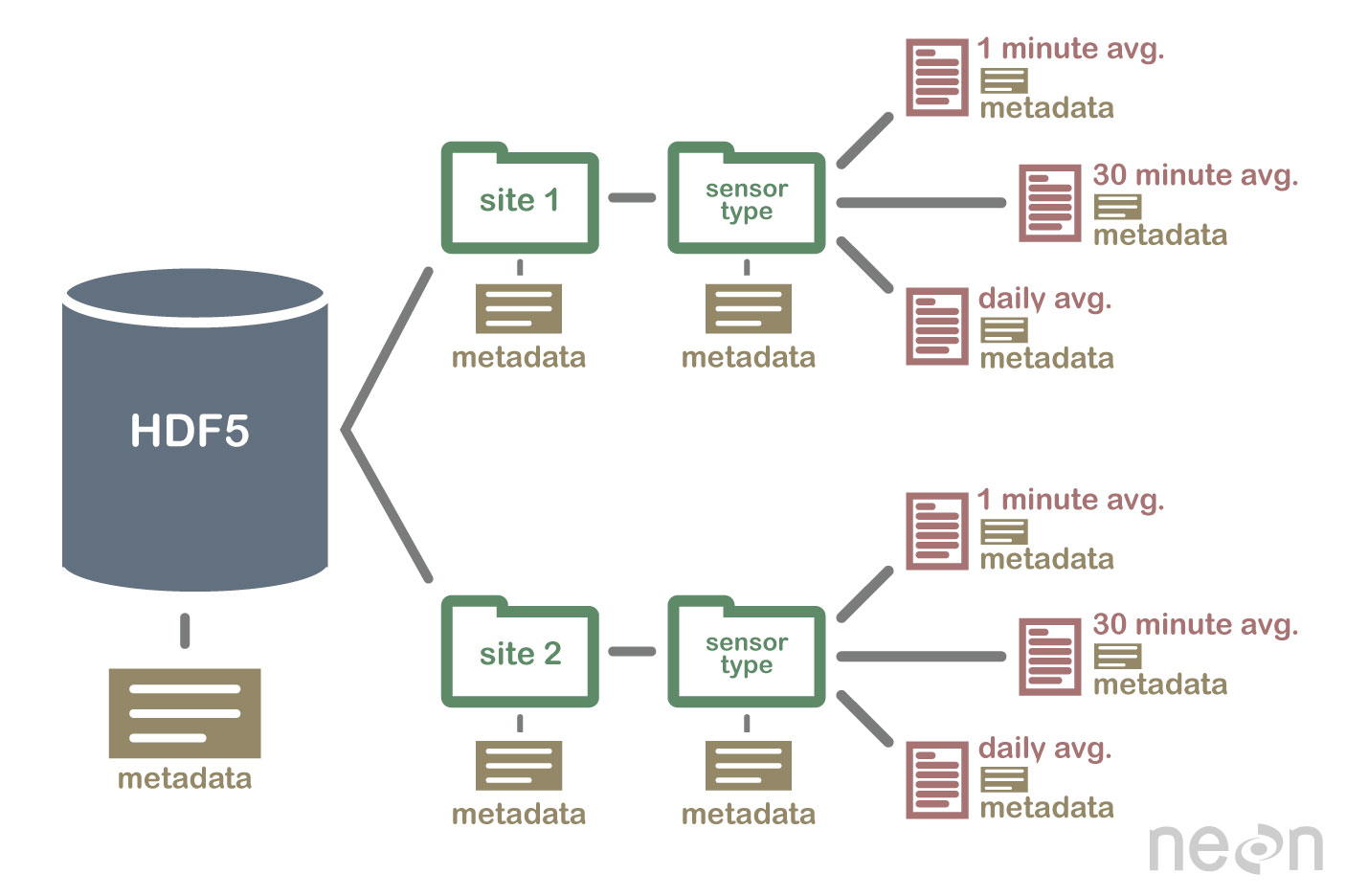
Specificația HDF5 definește un format de fișier pentru a stoca matrice de date. O matrice de date poate fi alcătuită din orice tip de date, inclusiv date șir, float, complexe și întregi. O matrice poate conține date de orice dimensiune și poate avea orice formă. În HDF5, trebuie mai întâi să creați un fișier antet pentru a crea un set de date. Fișierul antet include informații despre setul de date, precum și metadate. Fișierul antet include două informații importante: numele setului de date și numărul versiunii setului de date. O matrice de date este utilizată pentru a stoca datele unui set de date. Blocurile sunt formate din date dintr-o matrice de date. În matricea de date, fiecare bloc de date conține un set contigu de date. Numărul de blocuri al unui set de date este determinat de numărul de octeți din acesta. Datele pot fi accesate printr-o serie de metode, în conformitate cu specificația HDF5. metodele de indexare sunt cel mai frecvent utilizate pentru a obține date dintr-un set de date. Folosind aceste metode, puteți accesa datele introducând numele unui bloc în matricea de date pe care doriți să o accesați. Metoda structurii poate fi utilizată pentru a accesa datele dintr-un set de date. Când utilizați aceste metode, puteți accesa date utilizând structura unei matrice de date. În exemplul următor, puteți accesa datele dintr-o matrice de date utilizând valorile offset și lungime ale metodei structurii. O altă modalitate de a obține date dintr-un set de date este prin utilizarea metodelor funcționale. Puteți obține date utilizând una dintre metode, selectând funcția din fișierul antet pentru date. Metoda de accesare a unui tablou de date poate fi utilizată prin definirea valorii din fișierul antet ca element al matricei de date. În cele din urmă, puteți accesa datele dintr-un set de date folosind metoda de acces. Utilizând aceste metode, puteți accesa datele utilizând privilegiile de acces stabilite în fișierul antet. Cu alte cuvinte, utilizarea privilegiului de citire poate accesa datele dintr-o matrice de date prin metoda de acces. Datele pot fi create și utilizate într-o varietate de moduri folosind specificația HDF5. Metoda create este cea mai comună metodă de creare a unui set de date. Folosind metoda create, puteți crea un set de date introducând numele setului de date și numărul versiunii setului de date. În plus față de specificația HDF5, utilizarea seturilor de date poate fi realizată într-o varietate de moduri. Metoda cea mai des folosită.

Hdf5 este o bază de date relațională?
HDF5 nu este o bază de date relațională.
Graphql este Nosql sau Sql?
Scopul principal al GraphQL este de a utiliza un sistem de tip pentru a returna datele mai rapid și mai eficient. SQL (limbaj de interogare structurat) este un limbaj mai vechi, mai utilizat pe scară largă pentru stocarea datelor în sisteme de baze de date tabulare sau relaționale . Dacă doriți ca API-ul dvs. să fie construit pe baza unei baze de date NoSQL, ar fi o idee bună să lucrați cu GraphQL.
Type Mismatch este o bază de date GraphQL și NoSQL creată de Herman Camarena și Roger Cochrane. Utilizarea GraphQL poate duce la introducerea unui sistem de tip mai degrabă decât a unui sistem NoSQL, eliminând flexibilitatea creată de sistemele NoSQL. O colecție GraphQL conține o mare varietate de documente care sunt consistente ca structură și conțin câteva excepții. Deoarece GraphQL are un set încorporat de tipuri de date care se potrivesc cu tipurile de backend, dezvoltatorii pot alege ce tipuri de date să creeze. GraphQL ar trebui să abordeze problema nepotrivirilor de tip pentru a-și realiza pe deplin potențialul. În ceea ce privește caracteristicile sale, oferă o soluție de nepotrivire de nivel inferior datorită numeroaselor sale avantaje. Lucrarea este din ce în ce mai automatizată cu instrumente precum JSON2SDL de la StepZen.
Este un instrument puternic care poate fi folosit pentru a crea aplicații mai rezistente și mai eficiente, dar SQL nu este un înlocuitor. În ceea ce privește întreținerea, aceasta poate avea un impact negativ deoarece îngreunează unele sarcini.
Graphql: un limbaj de interogare pentru orice bază de date
Limbajul de interogare GraphQL permite clienților și serverelor să comunice între ei. O instanță GraphQL poate prelua și persista modificări fie dintr-o sursă de date, fie dintr-o stare persistentă. Un resolver este un set de funcții arbitrare care sunt utilizate pentru a accesa și manipula date. API-ul este disponibil într-o varietate de baze de date, iar GraphQL poate fi utilizat cu oricare. Baza de date MongoDB este o bază de date sursă de date populară , care este agnostică pentru diferite tipuri de date.
Nosql folosește arbori B?
Bazele de date NOSQL nu folosesc arbori B deoarece nu se bazează pe modelul relațional. Bazele de date NOSQL se bazează adesea pe perechi cheie-valoare, depozite de documente sau baze de date grafice.
Arborii B sunt structura de indexare implicită în MongoDB. În stocarea datelor , un arbore B este o metodă mai eficientă. Datele pot fi organizate folosind numere întregi și șiruri de caractere dacă sunt folosite împreună. Ca rezultat, bazele de date cu un volum mare de date ar trebui să ia în considerare utilizarea acestuia. Deoarece copacii B pot ocupa mult spațiu, sunt un model eficient. Acest lucru este benefic pentru bazele de date care trebuie să păstreze o cantitate mare de date. Arborii B sunt, de asemenea, o alegere bună pentru bazele de date care trebuie să organizeze datele într-un mod specific.
Ce bază de date folosește B-tree?
Există de mult timp și poate fi folosit într-o gamă largă de baze de date. Bazele de date NoSQL pot fi construite peste motoarele B-tree, pe lângă motoarele B-tree. MongoDB, de exemplu, indexează datele în arbori B. Algoritmul este același pentru DBMS ca și pentru o bază de date relațională, deși există unele excepții. Șirurile și numerele întregi pot fi folosite pentru a organiza datele în arborele B.
Ce bază de date folosește B-tree? Mysql, în articolul care urmează, folosește atât Btree, cât și B+tree. SQL Server stochează indecși bazați pe date persistente bazate pe chei sub forma unui BTree. Ca rezultat, fiecare nod dintr-un astfel de arbore apare ca o singură pagină.