
5 способов оптимизировать базу данных NoSQL
Опубликовано: 2023-01-12Базы данных NoSQL становятся все более популярными, поскольку они считаются более масштабируемыми и гибкими, чем традиционные реляционные базы данных . Существует несколько способов оптимизации базы данных NoSQL, в том числе: 1. Тщательная разработка схемы: это важно, поскольку хорошо спроектированная схема может помочь повысить производительность и сделать данные более управляемыми. 2. Индексирование данных: это может помочь повысить производительность запросов. 3. Использование кэширования. Кэширование может помочь повысить производительность за счет сохранения часто используемых данных в памяти. 4. Разделение данных. Это может помочь повысить производительность и масштабируемость за счет распределения данных по нескольким серверам. 5. Мониторинг производительности: это важно для выявления узких мест и принятия корректирующих мер.
Джей Патель, архитектор eBay, недавно опубликовал статью о моделировании данных с использованием хранилища данных Cassandra. Он объясняет, как они разработали свою модель данных с помощью Cassandra, как они использовали столбцы и семейства столбцов и как они оптимизировали результаты запросов с помощью оптимизации запросов. Один из моих любимых выводов из их подхода заключается в том, что его можно применить к любой базе данных NoSQL. Прежде чем вы сможете оптимизировать свою модель данных, вы должны сначала понять, как к ней будет осуществляться доступ. Когда вы начинаете замечать, что ваши запросы выполняются дольше, вы понимаете, что ваша реляционная база данных испытывает проблемы с производительностью. Когда данные нормализованы, меньше вероятность того, что они приведут к ненужным соединениям или запросам n+1. Даже если денормализация возможна с хранилищами данных NoSQL, с ней связаны затраты.
Что такое оптимизация запросов в Nosql?
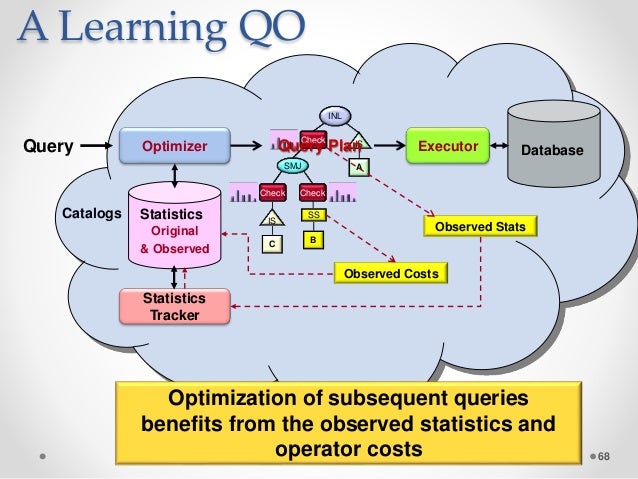
Цель оптимизации запроса — найти наиболее эффективный план. При измерении эффективности используются задержка и пропускная способность. Оптимизация на основе затрат стоит столько же, сколько стоимость памяти, ЦП и дискового пространства. В мире NoSQL большинство баз данных теперь обеспечивают поддержку языка запросов, подобного SQL.
База данных MongoDB — это база данных NoSQL, также известная как база данных документов. Эта база данных была разработана таким образом, чтобы ее было легче разрабатывать, чем другие реляционные базы данных. С помощью объяснения() мы можем увидеть, как работает наш запрос. Вы можете использовать Объяснение для создания документа, включающего планы запросов, этапы запросов и многое другое. В результате этой статьи мы можем понять, как индекс может изменить этапы сканирования конкретной коллекции. Цель этой статьи — пройтись по основам оптимизации. Подробные сведения об оптимизации этапа агрегации будут рассмотрены в следующих статьях. Чернокожие преуспевают в области технологий. Эта коллекция ресурсов освещает некоторые вещи, которые нам следует знать.
Что делает Nosql быстрым?
Базы данных Nosql спроектированы так, чтобы быть быстрыми и масштабируемыми. Для этого они используют различные методы, такие как горизонтальное масштабирование, сегментирование и денормализация.
Подавляющее большинство систем noSQL представляют собой просто постоянные хранилища ключей или значений (например, Project Voldemort). Если ваши запросы относятся к типу, который требует от вас поиска заданного значения ключа, система может сделать это так же быстро, как и РСУБД. Базы данных документов (такие как CouchDB) также являются популярными системами nosql. Денормализация широко используется в этих базах данных для структурирования структуры данных. На самом деле я считаю, что производительность приложения можно измерить количеством частей, необходимых для выполнения одного требования. Когда используется NoSQL, производительность базы данных NoSQL, такой как djondb, может быть в десять раз выше, если вам нужна только одна простая вставка. Разработчик сможет работать более эффективно, поскольку NoSQL позволяет потреблять меньше данных.
Основная цель NoSQL DATABASES (без границ) — поддерживать высокий уровень масштабируемости. Вы должны учитывать, какие типы запросов вы выполняете, какие столбцы вы используете в таблице и какую реализацию вашего сервера вы используете. Если вы создадите больше узлов со скоростью 1000000 об/мин, стабильная 2 мс и используете меньше кода, вы получите более быстрый узел с более высокой стабильной скоростью и производительностью.
Что делает Nosql быстрее, чем Sql?
Этот метод влечет за собой сбор, консолидацию и разделение различных объектов данных. В результате база данных NoSQL выполняет операции чтения и записи быстрее, чем база данных SQL.
Почему базы данных Nosql берут верх
Помимо множества факторов, базы данных NoSQL становятся все более популярными. Они просты в использовании, способны обрабатывать большие объемы данных и могут быть адаптированы для удовлетворения конкретных требований вашего приложения. Помимо того, что они гибкие и настраиваемые, они имеют много преимуществ, чего невозможно найти в других типах баз данных.
Настройка производительности Nosql

Настройка производительности Nosql заключается в том, чтобы убедиться, что ваша база данных nosql работает максимально эффективно. Есть несколько ключевых моментов, на которых следует сосредоточиться при настройке базы данных nosql: 1. Убедитесь, что ваша база данных правильно проиндексирована. 2. Убедитесь, что ваши запросы оптимизированы. 3. Убедитесь, что ваши данные правильно нормализованы. 4. Убедитесь, что ваша база данных настроена правильно. Сосредоточившись на этих ключевых областях, вы можете гарантировать, что ваша база данных nosql работает с максимальной производительностью.
Когда Mango находится под высокой нагрузкой, сценарий MangoNoSql выполняет фоновую запись в фоновом режиме. Функция пакетной записи позволяет писать за кулисами. Каждая задача будет выполняться параллельно с другими, фокусируясь на количестве баллов из пула. Если вы заметили какие-либо события потери данных NoSQL в своей системе, рекомендуется изменить настройки производительности. Когда вы нажмете кнопку «Создать резервную копию сейчас», будет создана очередь заданий для резервного копирования системы сейчас. Все значения точек, готовые для записи в список памяти в составе модулей NoSQL, хранятся в манго. После этого он выбирает из списка до «Пакетная запись после вставок для каждой задачи» и запускает поток для вставки вставок.
Плюсы и минусы Nosql
При разработке баз данных NoSQL очень важно, чтобы они были гибкими и быстрыми. У него меньше накладных расходов, потому что у него меньше ограничений, чем у SQL. Хранилище Shallow NoSQL является гибким, что позволяет распределять его между различными объектами (документами или парами ключ-значение). База данных NoSQL считается несложной с точки зрения разработки, функциональности и производительности. Он прост в освоении и используется людьми, которые предпочитают хранить данные, не соответствующие традиционным моделям баз данных .
Оптимизация производительности MongoDB
MongoDB — это мощная система баз данных с открытым исходным кодом, ориентированная на работу с документами. Он имеет функцию поиска на основе индекса, которая делает поиск данных быстрым и легким. Однако, как и любую другую систему баз данных, производительность MongoDB можно оптимизировать, чтобы обеспечить ее бесперебойную и эффективную работу. Есть несколько основных вещей, которые можно сделать для оптимизации производительности MongoDB. Во-первых, важно убедиться, что установлены правильные индексы. Это гарантирует, что данные могут быть получены быстро и легко. Во-вторых, важно, чтобы база данных была хорошо организована. Это поможет уменьшить размер данных и упростить запросы. Наконец, важно регулярно контролировать базу данных, чтобы обеспечить ее бесперебойную работу. Следуя этим простым советам, можно обеспечить бесперебойную и эффективную работу MongoDB.

Гай Харрисон объясняет, как использовать новую агрегацию окон и конвейер агрегации в MongoDB 5.0 в этой записи блога. Озеро данных было создано в результате взрыва интереса к большим данным и Hadoop. Было разработано озеро данных, современная и более эффективная альтернатива корпоративному хранилищу данных (EDW). Блог этой недели посвящен индексам B-дерева MongoDB и тому, как создавать конкатенированные индексы для оптимизации многоключевого поиска. Кроме того, при рассмотрении или использовании индексов мы учитываем некоторые компромиссы.
Что такое улучшение производительности в MongoDB?
Если вы знаете свои шаблоны запросов MongoDB, вы можете повысить производительность MongoDB за счет: сохранения результатов частых подзапросов для снижения нагрузки чтения; и обнаружение ваших шаблонов запросов MongoDB. Убедитесь, что у вас есть индексы для каждого поля, которое вы запрашиваете на регулярной основе. Если вы заметили медленные запросы, вы можете использовать свои журналы для их идентификации.
Нужно ли MongoDB много оперативной памяти?
MongoDB требует 1 ГБ ОЗУ для работы с одним ресурсом. Если системе придется начать подкачку памяти на диск, это серьезно повлияет на производительность, и этого следует избегать.
Есть ли в MongoDB оптимизатор запросов?
Когда индекс доступен в MongoDB, оптимизатор запросов определяет, какой план запроса является наиболее эффективным, и кэширует его. Количество «рабочих единиц» (работ), выполняемых планом выполнения запроса, используется для определения наиболее эффективного плана запроса, когда планировщик запросов проверяет планы-кандидаты.
Инструмент оптимизации запросов MongoDB
MongoDB предоставляет инструмент оптимизации запросов, который позволяет пользователям повысить производительность своих запросов. Этот инструмент позволяет визуализировать план выполнения запроса и оптимизировать запрос на основе результатов. Инструмент также позволяет пользователям просматривать план выполнения запроса в различных форматах, включая JSON, BSON и CSV.
MongoDB предоставляет статистику выполнения запросов как часть системы проверки. Эта информация может использоваться разработчиком для оптимизации запроса. Вкладка «Объяснение плана», например, позволяет пользователям графически иллюстрировать статистику плана. В дополнение к queryPlanner, executeStats и allExecutionPlans для объяснения можно использовать режимы многословия. Уникальные, частичные, разреженные (не индексировать документы без поля индекса), скрытые (не видеть результаты планировщика запросов) и многоключевые индексы — все они поддерживаются MongoDB. Вместо использования ключей префиксов индекса или различных порядков сортировки для индексов используется составной индекс. MongoDB оптимизирует производительность запросов, используя два отдельных индекса или префикса при соединении двух индексов или их префиксов.
Конвейер Mongod содержит этап, который соответствует неиндексированному полю. Это простое решение — переписать этап сопоставления, чтобы использовать уже существующее и проиндексированное поле. Оптимизатор ищет единицы работы, которые должны быть выполнены при выполнении каждого плана-кандидата. При запуске приложений, требующих интенсивного чтения, следует увеличить размер наборов реплик и выполнить сегментирование. Необходимо контролировать состояние и продолжительность репликации. True: обновлять все совпадающие документы максимально эффективно при использовании multi. Изучите метрики блокировки в определенном порядке.
Длительное время блокировки может указывать на то, что структура запроса или архитектура системы не работают должным образом. Пакетная обработка повышает эффективность использования ресурсов. События в Kafka, например, могут потребляться пакетами, а не кусками. Невозможно проиндексировать запрос к сегментированной коллекции, если индекс не содержит ключа к коллекции. Используя $planCacheStats, вы можете лучше понять информацию о кэше на этапе агрегирования. Это также означает, что размер кеша плана будет ограничен 0,5 ГБ, что совпадает с ограничением размера в более ранней версии.
Хранилища данных Nosql
Вместо хранения данных в таблицах базы данных NoSQL хранят данные в документах. В результате мы помечаем их как «не только SQL», и поэтому их можно классифицировать как гибкие модели данных с использованием множества различных методов. Базы данных NoSQL делятся на четыре типа: чистые базы данных документов, хранилища ключей и значений, базы данных с широкими столбцами и базы данных графов.
Хранилище данных Redis — это хранилище пар ключ-значение в памяти с открытым исходным кодом, разработанное IBM. Его можно использовать для хранения данных сеанса для более быстрого доступа, в дополнение к кэшированию, организации очередей и очереди, и он дешевле, чем традиционные базы данных . База данных NoSQL часто используется в качестве дополнения, а не замены реляционной базы данных. Базовый тип сохраняемости имеет набор характеристик, отличный от того, который хранится в реляционной базе данных. PyMongo, созданный с использованием кода Python, позволяет вам взаимодействовать с одним или несколькими экземплярами MongoDB, используя общий интерфейс. ORM Python, созданный на основе PyMongoEngine, специально разработан для MongoDB. Цель базы данных Graph — предоставить всесторонний обзор хранилищ данных NoSQL и сравнить их с другими типами хранилищ данных. Ниже приводится краткое описание NoSQL и его использования, а также описание теоремы о непротиворечивости, доступности и допуске к разделению (CAP). данные сеанса могут храниться в памяти быстрее, чем в традиционной базе данных с постоянным хранилищем.
Базы данных NoSQL обладают следующими характеристиками: простота масштабирования, высокая доступность и низкая задержка доступа к данным. Приложения базы данных предназначены для обработки большего количества типов данных, чем традиционные базы данных. Это упрощает хранение данных с помощью упрощенной модели, что позволяет выполнять более быструю и эффективную обработку. Кроме того, они подходят для крупномасштабного анализа данных. Базы данных NoSQL имеют ряд преимуществ по сравнению с обычными базами данных . Их преимущества заключаются в том, что они могут масштабироваться, обеспечивать высокий уровень доступности и низкий уровень задержки при доступе к данным.
Почему базы данных Nosql берут верх
Использование баз данных NoSQL имеет множество преимуществ по сравнению с традиционными реляционными базами данных, и они становятся все более популярными. Одной из основных причин этого является конструкция ObjectStore, позволяющая более эффективно использовать методы объектно-ориентированного программирования. Базы данных NoSQL, помимо своей масштабируемости, также предлагают множество других преимуществ. Данные могут быть легко обработаны, потому что они большие и могут быть обработаны за короткий период времени. Для любой компании, которая ищет надежную и масштабируемую базу данных документов , MongoDB — отличный выбор. Кроме того, он бесплатен для использования и является популярным выбором для предприятий любого размера.
Текстовый индекс MongoDB
Текстовые индексы MongoDB поддерживают обработку текста для конкретного языка, включая токенизацию, формирование корней и стоп-слова для конкретного языка. Их можно использовать с любым полем, содержащим текст на основе языка.
Создание текстовых индексов в MongoDB так же просто, как использование метода createIndex(). Основная функция текстового индекса — идентифицировать любой элемент в строке или массиве элементов в тексте. Составные индексы содержат ключи как восходящего, так и нисходящего индекса в дополнение к ключу текстового индекса. В этом случае давайте выполним поиск в коллекции студенческих сообщений, создав текстовый индекс в поле заголовка. MongoDB суммирует результаты каждого поля индекса в документе, умножая его вес на общее количество совпадений. Вес поля индекса по умолчанию равен единице, поэтому вы можете изменить его с помощью метода createIndex(). Вы можете создать несколько текстовых индексов, используя спецификатор подстановочных знаков ($**).