
Google Bigtable: наиболее широко используемое хранилище данных, ориентированное на столбцы
Опубликовано: 2022-12-19Bigtable — это хранилище данных, ориентированное на столбцы, созданное Google. Он предназначен для обработки больших объемов данных с высокой степенью гибкости. Bigtable используется Google уже более десяти лет и является основой для многих его сервисов, включая Gmail, Google Maps и YouTube. Хотя Bigtable — не первое хранилище данных, ориентированное на столбцы, оно, безусловно, является наиболее широко используемым и известным.
В этой статье мы рассмотрим трехмерную модель хранилища NoSQL, разработанную Bigtable. Чтобы убедиться, что он структурирован правильно, мы сначала рассмотрим, как он реализован в теоретическом плане, а затем воспользуемся для этого клиентом Node.js. Модель хранения в Bigtable отличается от той, которую вы можете найти в аналогичной базе данных. Несколько ячеек в комбинации строки/столбца можно упорядочить по отметке времени для каждой ячейки. Вместо того, чтобы сохранять ячейки в произвольном порядке, каждая ячейка имеет значение и отметку времени, чтобы обеспечить сохранение ячеек в упорядоченном порядке. В этом примере мы будем использовать Node.js и простой JavaScript для создания Google Cloud Bigtable. В этой статье мы рассмотрим, как создать новый экземпляр Bigtable с помощью кода.
Мы начинаем с создания чистой среды, чтения и записи в ней, а затем разрушаем ее. При выполнении кода с помощью клиента Node.js Bigtable клиент Node.js Bigtable может вызвать ошибку «Отказано в доступе» и создать ссылку для включения Cloud Bigtable Admin API. Вам также следует создать отдельную учетную запись службы в вашем проекте GCP для выполнения роли администратора Bigtable. Чтобы создать таблицу Bigtable, мы должны сначала создать экземпляр базы данных и кластер таблиц. Для этого просто определите идентификатор таблицы и семейство столбцов в клиенте Node.js, и все готово. Простые строки можно создавать с помощью Bigtable в базе данных. Единственный способ запросить данные — использовать ключ строки для запроса определенной строки или группы строк.
Хотя время приема не влияет на порядок хранения версий, оно влияет на то, как они хранятся. Не требуется указывать весь ключ строки; достаточно просто префикса. Когда вам нужно запросить несколько строк из Bigtable, я всегда советую использовать потоковую передачу. При использовании потоковой передачи Bigtable не нужно буферизовать данные на сервере перед отправкой строк, что приводит к более высокой производительности. Фильтры можно использовать для ограничения версий ячеек, возвращая только те столбцы с определенными именами семейств или столбцы с определенными критериями отбора. Это особенно полезно, если у вас есть много версий для хранения, но только самая последняя требуется для определенных целей. Фильтры в основном используются для уменьшения объема запрашиваемых и отправляемых данных для повышения производительности запросов.
Другими словами, Cloud Bigtable — это база данных NoSQL , предназначенная для аналитических и операционных рабочих нагрузок. Эта система баз данных представляет собой кроссплатформенный гибрид, в котором используется Hadoop, а не HBase, использующий столбцовую базу данных. Облачная большая таблица может использоваться для поддержки приложений с высокой пропускной способностью и масштабируемостью с емкостью менее 10 МБ.
Apache Cassandra, ScyllaDB, Apache HBase, Google BigTable и Microsoft Azure CosmosDB являются примерами хранилищ с широкими столбцами.
Таблицы отличаются от реляционных баз данных с точки зрения хранения ключей/значений. Транзакции могут быть выполнены только один раз, а соединения не поддерживаются.
Является ли Google Bigtable базой данных Nosql?
Google Bigtable — это база данных NoSQL, предназначенная для хранения и управления большими объемами данных. Bigtable — это база данных, ориентированная на столбцы, что означает, что данные организованы в столбцы, а не в строки. Это делает его подходящим для хранения постоянно меняющихся данных, таких как веб-журналы или данные из социальных сетей. Bigtable также легко масштабируется, что означает, что он может легко обрабатывать большие объемы данных.
Эта база данных NoSQL может хранить широкий спектр типов данных и чрезвычайно стабильна. Он также поддерживает как сегментирование, так и репликацию, обеспечивая высокую доступность и надежность базы данных. Его используют многие приложения Google, в том числе Google Analytics, веб-индексирование, MapReduce и Google Maps, Google Books, My Search History, Google Earth, Blogger.com, Google Code Hosting и Google For для приложений, которым требуется база данных, способная обрабатывать большие объемы данных. количество элементов данных, Datastore — отличный выбор.
В каком порядке данные хранятся в Bigtable?
Нет определенного порядка, в котором данные хранятся в bigtable. Данные хранятся в случайном порядке, что затрудняет доступ к конкретным данным.
Google Bigtable: не только для хранения данных
Данные нельзя размещать в каком-либо определенном порядке в igtable. Поскольку Bigtable — это база данных, ориентированная на строки, все данные в строке организованы в столбцы, за которыми следует столбец. Поскольку данные хранятся в обратном хронологическом порядке, можно просто и быстро запросить самое последнее значение, но запросить самое старое значение сложно и требует много времени.
Ваши данные хранятся в Colossus, внутренней долговременной файловой системе Google, которая размещена в центрах обработки данных Google в результате использования Colossus компанией Bigtable. Bigtable можно использовать бесплатно, и вам не нужно использовать кластер HDFS или любую другую файловую систему.
Запрос к внешнему источнику данных можно выполнить без создания постоянной таблицы с помощью команды Combine: Файл определения таблицы с запросом. Существует встроенное определение схемы, а также запрос. Файл определения схемы JSON с запросом.
Bigtable против хранилища данных
Между Bigtable и Datastore есть несколько ключевых различий. Во-первых, Bigtable — это хранилище данных, ориентированное на столбцы, а Datastore — на строки. Это означает, что в Bigtable данные организованы в столбцы, а в Datastore — в строки. Во-вторых, в Bigtable нет концепции транзакций, в отличие от Datastore. Это означает, что в Bigtable нельзя откатить изменения до предыдущего состояния, а в Datastore можно. Наконец, Bigtable рассчитан на высокую пропускную способность и малую задержку, а Datastore — на высокую доступность и масштабируемость.
Какое облачное хранилище данных можно использовать для создания облачных баз данных Google? Поскольку Bigtable поддерживает большие рабочие нагрузки со сложными внутренними рабочими нагрузками, он предназначен для крупных организаций и предприятий. В отличие от SQL, который использует более строгий язык запросов GQL, хранилища данных выполняют транзакции ACID с подмножествами данных, известными как группы сущностей (хотя язык запросов GQL гораздо более открытый). Google Cloud Datastore и Google Cloud Bigtable — это две разные службы, которые имеют ряд различных функций. Кроме того, информация на изображении ниже может помочь вам выбрать подходящего поставщика услуг. Ответы выше, а также то, что обсуждается в учебнике Coursea Google Cloud Platform Big Data and Machine Learning Fundamentals, послужат моим руководством для этой статьи.
В чем разница между Bigtable и Datastore?
В чем разница между хранилищем данных и базой данных? И bigtable, и хранилище данных предназначены для обработки больших объемов данных и аналитики соответственно, а хранилище данных предназначено для ценных транзакционных данных. Хранилище данных также известно как база данных NoSQL, поскольку оно не соответствует традиционному стандарту SQL, что позволяет хранить данные более гибким и масштабируемым образом. Что за хранилище данных Google Bigtable? Модель хранения Bigtable хранит данные в масштабируемых таблицах, которые сортируются по картам ключей и значений. Таблица состоит из строк, каждая из которых описывает один объект, и столбцов, каждый из которых имеет свое значение. Хранилище данных устарело? Так как Cloud Datastore API v1beta3 был выпущен, он больше недоступен. Тем не менее продукт Cloud Datastore полностью функционален и поддерживается.
База данных больших таблиц
Bigtable — это распределенная система хранения для управления структурированными данными, предназначенная для масштабирования до очень больших размеров: петабайт данных на тысячах обычных серверов. Bigtable — это база данных, ориентированная на столбцы, что означает, что данные хранятся по столбцам, а не по строкам.
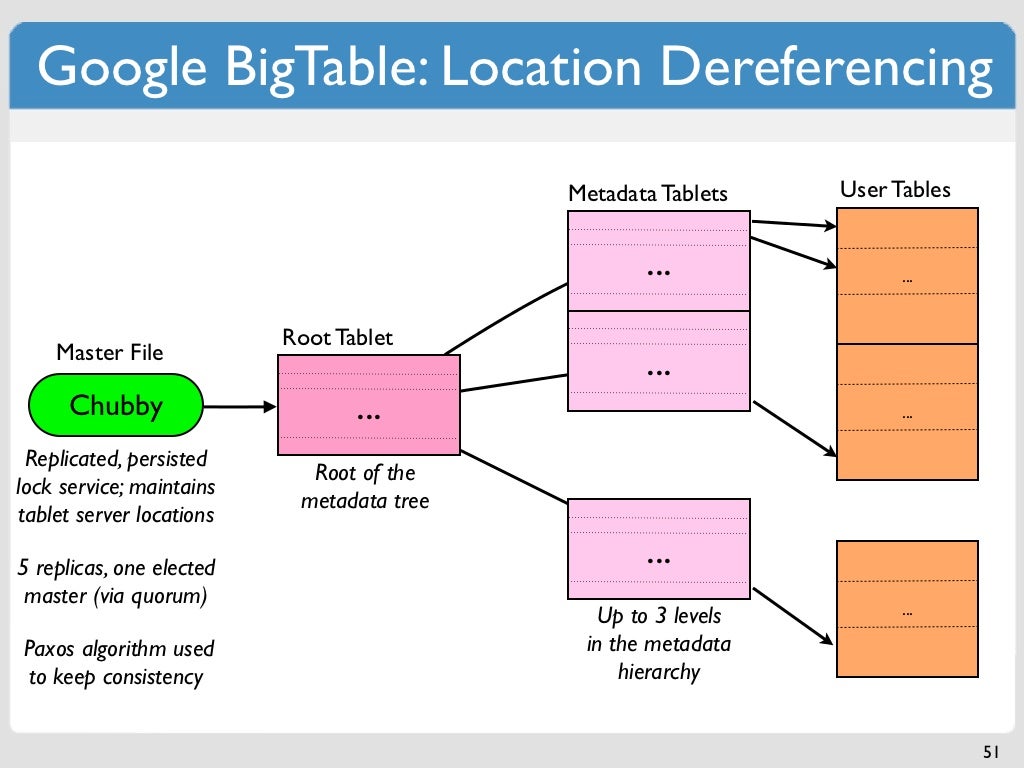
Таблица представляет собой разреженную, густонаселенную структуру со строками и столбцами, которые могут достигать миллиардов строк. Bigtable — отличный выбор для хранения больших объемов данных с малой задержкой. Поскольку он поддерживает высокую скорость чтения и записи при малой задержке, он является подходящим источником данных для операций MapReduce. При использовании таблицы Bigtable она разбивается на блоки смежных строк, называемые планшетами, чтобы упростить запросы. В файловой системе Colossus, которую использует Google, планшеты хранятся в формате SSTable. Узел Bigtable — это подмножество каждого планшета, входящего в состав экземпляра Bigtable. Добавление узлов в кластер может увеличить количество одновременных запросов, которые он может обрабатывать.

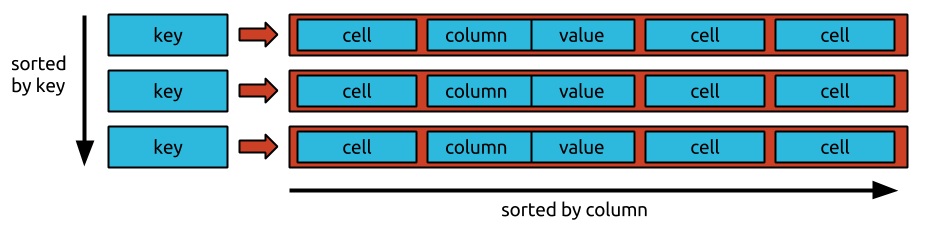
Строка содержит набор записей ключа или значения, которые представляют собой комбинацию семейства столбцов, метки времени столбца и ключа. Bigtable обрабатывает все данные одинаково: как необработанные байтовые строки. Поскольку Bigtable хранит мутации последовательно и регулярно их сжимает, количество мутаций, которые можно сохранить в данный момент времени, требует большего объема памяти. Bigtable сжимает ваши данные, используя сложный автоматизированный алгоритм. Поскольку делеции на самом деле являются новыми типами мутаций, они требуют больше места для хранения в краткосрочной перспективе. Запатентованные Google методы хранения позволяют достичь надежности данных, превышающей ту, которая достигается при стандартной трехсторонней репликации HDFS. Помимо управления доступом к таблицам Bigtable, вы можете управлять доступом к другим службам Google Cloud, назначая роли пользователям в разделе «Управление идентификацией и доступом» (IAM) вашего проекта Google Cloud. Согласно политике шифрования Google Cloud по умолчанию, все данные в облаке шифруются в состоянии покоя с использованием тех же надежных систем управления ключами, которые мы используем для наших зашифрованных данных. Используя резервную копию, вы можете сохранить копию схемы и данных таблицы, а затем восстановить эту копию данных в новой таблице в будущем.
Бигтабл против Кассандры
Cassandra и Bigtable используют разные методы, чтобы определить, какой узел обработки должен выполнять операции чтения и записи. В Cassandra ключ секции называется ключом, тогда как в Bigtable ключ строки называется ключом. Политика балансировки нагрузки для Cassandra должна быть проверена клиентом как часть процесса.
Распределенная база данных — это база данных, совместно используемая несколькими людьми. Эта компания включает в свою систему многомерные хранилища ключей и значений, что позволяет обрабатывать десятки тысяч запросов в секунду (QPS). Цель этого документа состоит в том, чтобы сравнить и противопоставить две системы баз данных. Ключевые особенности Bigtable включают в себя: Создана статья «Распределенная система хранения структурированных данных». Если Bigtable определяет, что для набора данных требуется перебалансировка диапазонов, обрабатывающему узлу несложно изменить диапазоны данных, поскольку уровень хранения отделен от уровня обработки. Bigtable также можно использовать для поддержки асинхронной репликации в географически распределенных кластерах до четырех кластеров в топологиях. Отказоустойчивость Cassandra связана с ее уровнем настраиваемой согласованности.
Настроив стратегию топологии репликации данных, вы можете задать географическую репликацию. Как правило, используется параметр QUORUM (или LOCAL_QUORUM в некоторых центрах обработки данных). Чтобы считаться успешной, настройка уровня согласованности операции должна быть выполнена при условии, что большинство узлов реплики отвечает узлу-координатору. Используя конфигурации центра обработки данных и стоек, реплики Cassandra способны выдерживать большие нагрузки по сравнению с традиционными репликами. При выполнении операций чтения и записи топология определяет, какие узлы необходимы для обеспечения согласованности. Экземпляр Bigtable может содержать один кластер или группу до четырех больших реплик. Bigtable и Cassandra — это хранилища данных NoSQL, представляющие собой хранилища с широкими столбцами.
Ключ строки Bigtable используется для сортировки глобальных данных в таблице по порядку. Узлы Bigtable автоматически распределяют ответственность узлов за ключевые диапазоны, также известные как планшеты, как часть функции узлов Bigtable. Служба Bigtable клиента не применяет типы данных столбцов, которые она отправляет. В Bigtable каждому столбцу в таблице присваивается имя семейства. Несмотря на то, что таблицы часто имеют больше семейств столбцов (максимальное количество столбцов в таблице равно 100), для каждой таблицы требуется по крайней мере одно семейство столбцов. Ключевое пересечение строк состоит из двух ячеек (семейство столбцов в сочетании с квалификатором столбца). В Cassandra и Bigtable есть метод выбора узла обработки для операций чтения и записи.
В Cassandra идентифицируется ключ раздела, тогда как в Bigtable используется ключ строки. Политика балансировки нагрузки, учитывающая центры обработки данных, например политика с несколькими кластерами, обеспечивает потенциальную возможность аварийного переключения. Обе базы данных используют аналогичный метод завершения записи и оптимизированы по скорости. Данные хранятся в двух базах данных через неизменяемые файлы SSTable. В Cassandra координатор должен уведомить клиента о завершении записи до того, как ответят несколько реплик. Успешная запись в Bigtable может быть подтверждена только ответом от одного узла, поскольку каждый ключ строки назначается только одному узлу. Ячейки в любой базе данных не могут быть включены в объединенную SSTable.
Из-за предложения WHERE в запросе CQL в Cassandra невозможно вернуть более одной строки. Только узел, отвечающий за диапазон ключей, требуется для консультации в Bigtable. На узле обработки можно ограничить количество данных, которые можно прочитать. На этапе уплотнения SSTables регулярно объединяются, и в них сохраняются данные, хранящиеся в Bigtable и Cassandra. Нет правил, определяющих количество версий меток времени для каждой ячейки, но могут быть другие ограничения на размер строки. Гарантии надежности данных обеспечивает система репликации Colossus. Bigtable, как и Cassandra, имеет интерфейс командной строки и клиентские библиотеки для многих распространенных языков программирования.
Каждому узлу назначается SSTable в Bigtable, и хранящиеся в нем данные обслуживаются этим узлом. При определении размера кластера Cassandra вам не нужно учитывать реплики хранилища, как в случае с Bigtable. Твердотельные накопители (SSD) или жесткие диски (HDD) являются наиболее часто используемыми типами хранилищ для экземпляров Bigtable . Как продемонстрировала Cassandra, для достижения отказоустойчивости не происходит потери плотности хранения. Экземпляр Bigtable можно масштабировать в соответствии с требованиями рабочей нагрузки с минимальными усилиями и минимальным временем простоя. Хотя кластеров всего четыре, каждый кластер можно создать в любом поддерживаемом облачном регионе по всему миру. Google рекомендует протестировать производительность Bigtable с репрезентативными данными и запросами, чтобы создать метрику QPS для каждого узла.
Cassandra выполняет большое количество функций администрирования, используя управляемые компоненты Bigtable. Резервные копии больших таблиц создают восстанавливаемые копии таблицы, которые хранятся как объекты в кластере. Резервные копии потребляют меньше ресурсов узла и стоят дешевле, чем облачное хранилище. Еще один способ резервного копирования Bigtable — использование управляемого экспорта данных в облачное хранилище. Внутренние задачи обслуживания, такие как исправление ОС, восстановление узла, ремонт узла, мониторинг сжатия хранилища и ротация SSL-сертификата, выполняются службой Bigtable без проблем. Панели мониторинга доступны для мониторинга показателей пропускной способности и использования на уровне экземпляров, кластеров и таблиц на странице консоли Bigtable Google Cloud . Вы можете использовать панель мониторинга для расширенной настройки производительности.
В документе Bigtable описывается система хранения данных, которая поддерживает массовое масштабирование. Каждая таблица в данных разделена на несколько разделов. Вы можете запросить таблицу, используя ключ строки или диапазон ключей строки. В документе Bigtable также описывается метод распределения работы таблицы по кластеру узлов. Apache Cassandra, база данных с открытым исходным кодом, основана на некоторых концепциях из статьи Bigtable. Центры обработки данных используют архитектуру распределенных узлов, в которой хранилище совместно используется серверами, которые обслуживают данные. Доступ к системе хранения данных Bigtable осуществляется с помощью интерфейса командной строки cbt и клиентских библиотек. Помимо Python, Bigtable включает ряд языков программирования, что упрощает интеграцию с приложениями.
Google Datastax Astra Cassandra как услуга: простота развертывания и масштабирования
Google DataStax Astra Cassandra как услуга — отличный выбор для изучения Cassandra. Пользовательский интерфейс оператора Kubernetes упрощает настройку, управление и масштабирование развертывания Cassandra.
Документация по Bigtable
Документация Bigtable — отличный ресурс для изучения этого мощного инструмента. В нем представлен обзор функций и возможностей Bigtable, а также подробная информация о том, как его использовать. Документация хорошо организована и проста в использовании, что делает ее ценным ресурсом для всех, кто заинтересован в изучении этого мощного инструмента.
Google Cloud Platform отвечает за размещение базы данных Google Bigtable . OpenTSDB 2.1 и более поздние версии легко использовать в сочетании с серверной частью Google. Все, что вам нужно сделать, это создать экземпляр Bigtable, настроить таблицы TSDB с помощью оболочки Bigtable HBase и запустить TSD. Клиенты Bigtable в настоящее время находятся в стадии бета-тестирования и претерпевают множество изменений.
Эффективная компоновка данных Bigtable
Bigtable также хорошо подходит для операций MapReduce. Благодаря эффективному расположению данных MapReduce может обрабатывать большие объемы данных за короткий период времени.