
Hadoop HDFS и NoSQL: мощная комбинация для больших данных
Опубликовано: 2023-01-05Hadoop — это платформа с открытым исходным кодом, которая позволяет выполнять распределенную обработку больших наборов данных в кластерах компьютеров с использованием простой модели программирования. HDFS — это распределенная файловая система Hadoop , которая обеспечивает масштабируемый и отказоустойчивый способ хранения данных. Базы данных NoSQL — это новый класс баз данных, предназначенный для предоставления масштабируемой, гибкой и высокопроизводительной альтернативы традиционным реляционным базам данных.
Основное различие между Hadoop и HDFS заключается в том, что Hadoop — это платформа с открытым исходным кодом для хранения, обработки и анализа данных, тогда как HDFS — это файловая система, которая позволяет пользователям получать доступ к данным Hadoop. В результате HDFS является модулем Hadoop .
SQL и Hadoop могут управлять данными различными способами. Платформа Hadoop используется для сборки программных компонентов, тогда как среда SQL используется для сборки баз данных. Для больших данных важно учитывать плюсы и минусы каждого инструмента. Платформа Hadoop сохраняет данные только один раз, тогда как Hadoop хранит гораздо большее количество наборов данных.
Hadoop — это не база данных, а часть программного обеспечения, позволяющая выполнять массивные параллельные вычисления. Эта технология позволяет базам данных NoSQL (таким как HBase) распределять данные по тысячам серверов с минимальным снижением производительности.
Hadoop не хранит данные так, как это делает реляционное хранилище. Распределенный сервер — одно из приложений, которое использует его чаще всего. Хотя это база данных Hadoop , она не считается реляционной базой данных, поскольку хранит файлы в HDFS (распределенная файловая система).
В чем разница между Nosql и Hdfs?
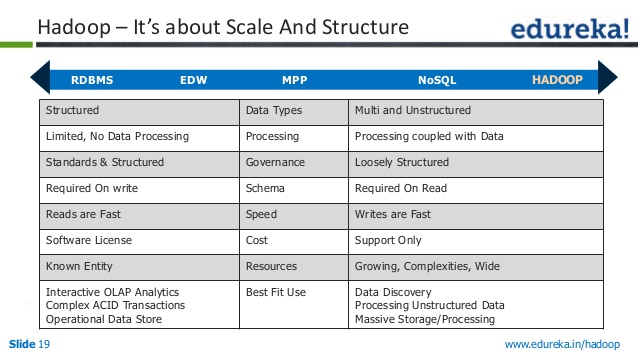
Это файловая система, и ее также называют файловой системой. Уже ясно, что это приложение предлагает ряд функций. Где вы берете этот материал NOSQL? С его помощью мы сможем обрабатывать большие объемы данных в режиме реального времени, потому что это не требует от нас использования реляционных баз данных или других функций.
Диспетчер хранилища HBase, работающий в Hadoop, обеспечивает произвольное чтение и запись с малой задержкой. В системе HBase используется функция автоматического сегментирования, при которой большие таблицы распределяются динамически. Каждый региональный сервер отвечает за обслуживание набора регионов, и существует только один региональный сервер, способный обслуживать один регион (т. е. HMaster и HRegion — две основные службы, предоставляемые HBase. Компонент HRegion таблицы HBase отвечает за обработку подмножества данных таблицы.При запуске Регионального сервера он назначается каждому Региону.В результате мастер не участвует в операциях чтения и записи.
Когда дело доходит до работы с неструктурированными и объемными данными, базы данных NoSQL, такие как MongoDB и Cassandra, выделяются среди традиционных реляционных баз данных. Компании, работающие с большими объемами данных, такими как большие данные, предпочитают использовать эти инструменты для быстрой обработки и анализа огромных объемов разнообразных и неструктурированных данных. MongoDB хранит данные в коллекциях, тогда как hadoop хранит данные в другой файловой системе, известной как HDFS. В результате этой разницы выгодно иметь другую архитектуру. Также гораздо быстрее запрашивать данные в MongoDB, чем искать в отдельных файлах. Кроме того, поскольку mongodb разработан для сред с большими объемами, он хорошо подходит для обработки больших объемов данных при относительно низких затратах. Компаниям, которым требуются решения для работы с большими данными, рекомендуется использовать базы данных NoSQL. У них есть многочисленные преимущества перед традиционными базами данных с точки зрения скорости обработки и аналитики, и они хорошо подходят для крупномасштабного анализа данных и управления ими.
Является ли Hadoop базой данных Nosql?
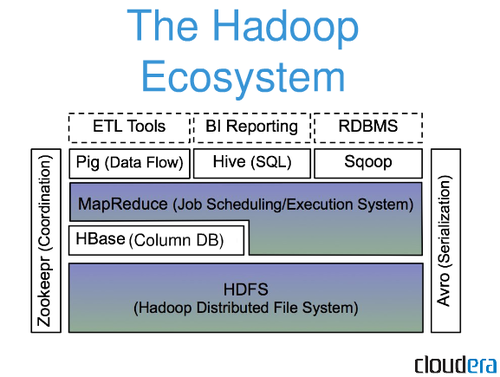
Hadoop — это не традиционная система управления реляционными базами данных. Это распределенная файловая система, которая помогает хранить и обрабатывать большие наборы данных в кластере стандартных серверов. Hadoop предназначен для масштабирования от отдельных серверов до тысяч машин, каждая из которых предлагает локальные вычисления и хранилище.
Новые технологии революционизируют использование данных в сверхмассивном масштабе. В инфраструктуре больших данных есть множество игроков, включая Hadoop, NoSQL и Spark. Администраторы баз данных и инженеры/разработчики инфраструктуры теперь работают на них, чтобы управлять сложными системами в новом поколении администраторов баз данных и инженеров инфраструктуры. Поскольку Hadoop — это программная экосистема, а не база данных, она позволяет выполнять вычисления огромных объемов данных со скоростью, которая является одновременно эффективной и результативной. Преимущества, которые он обеспечивает для огромных объемов данных, которые он обрабатывает, изменил правила игры для обработки больших данных. Большая транзакция данных, например та, которая занимает 20 часов в централизованной системе реляционной базы данных, может быть завершена всего за три минуты в кластере Hadoop.
Существует более одного языка SQL на выбор. MongoDB, чистая база данных документов, является одним из типов базы данных NoSQL; Cassandra, база данных с широкими столбцами, — еще одна; и Neo4j, графическая база данных, является другим. Эта функция была создана SQL- on-Hadoop . SQL-on-Hadoop — это новый класс аналитических инструментов, который сочетает в себе стандартные SQL-запросы с платформами данных Hadoop. SQL-on-Hadoop позволяет корпоративным разработчикам и бизнес-аналитикам сотрудничать с Hadoop в стандартных вычислительных кластерах, позволяя выполнять знакомые SQL-запросы. Преимущества SQL-на-hadoop. Многочисленные преимущества SQL-on-Hadoop, помимо простоты использования, стоят времени и ресурсов разработчиков корпоративных данных и аналитиков. Для начала они могут работать с Hadoop на массовых вычислительных кластерах, что позволит им быстро и легко начать работу с аналитикой больших данных. SQL-on-Hadoop также позволяет им использовать знакомые SQL-запросы, упрощая изучение аналитики больших данных. Кроме того, SQL-on-Hadoop предоставляет функциональность Hadoop map/reduce, а также богатые возможности анализа данных, которые он предоставляет.
Базы данных Nosql на подъеме
В результате базы данных NoSQL становятся все более популярными благодаря своей масштабируемости, производительности чтения/записи и гибкости данных. На рынке есть несколько хороших примеров баз данных NoSQL, включая DynamoDB, Riak и Redis.
Hive — это легкая и модульная база данных NoSQL с отличными показателями производительности. Он написан на чистом языке программирования Dart и популярен среди разработчиков благодаря своей простоте.
В чем разница между Hadoop и базой данных?

Хотя СУБД не хранит и не обрабатывает данные, Hadoop скорее хранит и обрабатывает данные как распределенную файловую систему. RDBMS, с другой стороны, представляет собой структурированную базу данных, которая хранит данные в строках и столбцах и может обновляться с помощью SQL и представляться в различных таблицах.
Внедрение технологий и инструментов больших данных росло быстрыми темпами. Дистрибутив Hadoop с открытым исходным кодом работает в распределенной файловой системе и позволяет обмениваться и обрабатывать большие наборы данных. RDB — это базовая система управления базами данных, которая в простейшей форме используется всеми системами управления базами данных, такими как Microsoft SQL Server, Oracle и MySQL. Несмотря на то, что РСУБД классифицируется как эволюция, она больше похожа на любую другую стандартную базу данных, чем на серьезное предприятие. Это не база данных, а скорее распределенная файловая система, которая может хранить и обрабатывать большие наборы файлов данных. Хотя такие системы, как Hadoop, могут обеспечить более высокую производительность, у них есть некоторые недостатки, о которых редко говорят. Вы должны подумать о том, как управлять своим кластером Hadoop, безопасностью, Presto или любым другим интерфейсом, который вы используете.
Большинство систем реляционных баз данных, таких как SQL Server и Oracle, намного проще в использовании. Большинство организаций сталкиваются с серьезной проблемой нехватки квалифицированных специалистов, способных эффективно работать с Hadoop, а также со значительными затратами на персонал. Если у вас 10 000 сотрудников, вам потребуется много данных, чтобы отслеживать их всех. Эта информация может храниться в Presto различными способами. Раздел даты может использоваться для хранения положения человека каждый день. С другой стороны, СУБД можно использовать в качестве примера модели данных. Единственный способ использовать этот метод — если у вас уже есть доступ к данным за предыдущий день.
В чем ключевая разница между реляционными базами данных и большими данными?
Основное различие между реляционными базами данных и большими данными заключается в том, что реляционные базы данных оптимизированы для хранения структурированных данных, тогда как большие данные оптимизированы для хранения неструктурированных и частично структурированных данных. Реляционная база данных моделируется по образцу реляционной модели, тогда как база данных больших данных моделируется по образцу распределенной модели. Структурированные данные можно эффективно хранить и обрабатывать в реляционных базах данных. Таблица содержит данные и обеспечивает доступ и извлечение на языке структурированных запросов (SQL). Большие данные определяются как любые данные, которые являются неструктурированными или полуструктурированными.

В чем разница между Hadoop и MongoDB?
Поскольку MongoDB работает на C, она лучше управляет памятью, чем любая другая база данных. Hadoop — это набор программного обеспечения на основе Java, который обеспечивает основу для хранения, извлечения и обработки данных. Hadoop оптимизирует пространство более эффективно, чем MongoDB.
MongoDB — это база данных NoSQL (не только SQL), созданная на C. Hadoop — это программная платформа с открытым исходным кодом, в основном состоящая из Java, которая позволяет обрабатывать большие объемы данных. Кроме того, MongoDB Atlas включает в себя полнотекстовый поиск, расширенную аналитику и интуитивно понятный язык запросов. Hadoop эффективен при хранении и обработке больших объемов данных, но делает это небольшими партиями. В MongoDB доступно множество встроенных инструментов обработки данных в реальном времени. Благодаря своим коннекторам для внешних инструментов, таких как Kafka и Spark, MongoDB упрощает получение и обработку данных. Преимущества Hadoop и MongoDB перед традиционными базами данных в области больших данных многочисленны. Hadoop, распределенная файловая система, может использоваться для работы с огромными файлами. MongoDB — единственная база данных, способная заменить традиционную базу данных с точки зрения производительности.
Rdbms против Nosql против Hadoop
Существует три основных типа хранилищ данных — RDBMS, NoSQL и Hadoop. Каждый из них имеет свои сильные и слабые стороны, поэтому важно выбрать правильный для ваших нужд.
РСУБД (система управления реляционными базами данных) является наиболее распространенным типом хранилища данных. Он прост в использовании и легко масштабируется. Однако он не такой гибкий, как NoSQL или Hadoop, и его обслуживание может быть более дорогим.
NoSQL (не только SQL) — это новый тип хранилища данных, который становится все более популярным. Она более гибкая, чем РСУБД, и может быть более масштабируемой. Однако он не так прост в использовании и может быть более дорогим в обслуживании.
Hadoop — это тип хранилища данных, предназначенный для больших данных. Он очень масштабируемый и может обрабатывать много данных. Однако ее не так просто использовать, как РСУБД или NoSQL, и ее обслуживание может быть более дорогостоящим.
Подход предприятия к хранению, обработке и анализу данных можно значительно улучшить с помощью платформы Apache Hadoop . Озеро данных может выполнять несколько типов аналитических рабочих нагрузок на одном и том же оборудовании и программном обеспечении, а также управлять большими объемами данных. Теперь аналитики могут эффективно взаимодействовать с данными на ходу с помощью таких инструментов, как Apache Impala и Apache Spark. Hadoop, в отличие от системы управления реляционными базами данных (RDBMS), не обладает теми же возможностями, что и база данных, а скорее представляет собой распределенную файловую систему, способную обрабатывать огромные объемы данных. Объем данных, который можно легко и эффективно обрабатывать, называется объемом данных. Другими словами, это процесс обработки общего объема данных за определенный период времени, который можно оптимизировать. Он имеет возможность хранить и обрабатывать данные из широкого круга источников и подготавливать их к анализу.
В небольшом количестве РСУБД могла управлять только структурированными и полуструктурированными данными. Hadoop не может обрабатывать данные из различных источников или любой структурированной структуры. Время отклика, масштабируемость и стоимость — вот некоторые из других важных факторов, которые следует учитывать.
Почему Rdbms по-прежнему остается самой популярной системой управления базами данных
Наиболее широко используемой системой управления базами данных в мире является РСУБД. Он обеспечивает широкий спектр функций, а также является чрезвычайно надежным. Реляционная база данных лучше всего подходит для хранения данных, которые необходимы для доступа нескольких пользователей.
Базы данных NoSQL набирают популярность отчасти из-за их преимуществ в производительности по сравнению с реляционными базами данных. Они также позволяют хранить большие объемы данных, которыми не нужно делиться с несколькими пользователями.
Хадуп Nosql
В обычном аппаратном кластере Hadoop хранит большие данные. У вас есть возможность изменить любую функцию, которая не работает или соответствует вашим потребностям, если это необходимо. Напротив, система управления базами данных NoSQL — это тип системы управления базами данных, которая используется для хранения структурированных, полуструктурированных и неструктурированных данных.
Является ли Hdfs базой данных
Файловая система HDFS — это распределенная файловая система, работающая на обычном оборудовании. С помощью этой функции один кластер Apache Hadoop можно настроить для поддержки сотен (и даже тысяч) узлов. Apache Hadoop, который также включает MapReduce и YARN, состоит из нескольких основных компонентов.
Высокопроизводительный доступ к данным обеспечивает распределенная файловая система Hadoop (HDFS), являющаяся компонентом операционной системы Hadoop . Основной узел имени кластера отвечает за отслеживание того, где хранятся данные файла кластера. В дополнение к управлению доступом к файлам узел Имя управляет доступом к файлам, таким как чтение, запись, создание, удаление и т. д. Yahoo представила распределенную файловую систему Hadoop как часть своих требований к размещению онлайн-рекламы и поисковой системе. Протокол HDFS предоставляет пространство имен файловой системы для хранения пользовательских данных. Узлы данных могут взаимодействовать друг с другом во время обычных операций с файлами, потому что они взаимодействуют друг с другом. Распределенная файловая система Hadoop (HDFS) является компонентом многих озер данных с открытым исходным кодом. HDFS используется eBay, Facebook, LinkedIn и Twitter для анализа больших объемов данных. В случае сбоя узла или оборудования для правильной работы HDFS требуется репликация данных.
Пример базы данных Hadoop
База данных Hadoop — это база данных, которая использует распределенную файловую систему Hadoop (HDFS) в качестве базового хранилища. Базы данных Hadoop обычно используются для хранения больших объемов данных, которые слишком велики для размещения на одном сервере.
Платформа с открытым исходным кодом для хранения и обработки больших наборов данных в распределенном режиме на обычном оборудовании. Apache Hadoop используется в различных приложениях. Это версия парадигмы Google с открытым исходным кодом, которая использовалась в их статье 2004 года MapReduce. В этой статье мы рассмотрим некоторые из наиболее часто задаваемых вопросов новичками в экосистеме больших данных. Платформа Apache Hadoop ориентирована на распределенную обработку данных, а не на хранение в базе данных или реляционное хранилище. Несмотря на наличие компонента хранилища, известного как HDFS (распределенная файловая система Hadoop), в котором хранятся файлы, используемые для обработки, HDFS подпадает под категорию реляционной базы данных. Hive, а также HiveQL можно использовать для запросов к хранилищу HDFS HDFS, которое встроено в HDFS.
Что является примером Hadoop?
Hadoop может использоваться компаниями, предоставляющими финансовые услуги, для оценки рисков, построения инвестиционных моделей и создания торговых алгоритмов; Hadoop также использовался для помощи в создании и управлении этими приложениями. Эта технология используется ритейлерами, чтобы помочь им лучше понимать и обслуживать своих клиентов, анализируя структурированные и неструктурированные данные.
Множество применений Hadoop
Hadoop можно использовать для управления данными в приложениях с большими данными, таких как анализ больших данных, анализ данных в реальном времени, научные исследования и хранилища данных. В результате это универсальная и адаптируемая платформа, идеально подходящая для широкого спектра приложений.
Является ли Spark базой данных Nosql
NoSQL DataFrame, согласно документации, является форматом источника данных для Spark DataFrame. В этом источнике данных доступны DataPruning и фильтрация (проталкивание предикатов), что позволяет выполнять запросы Spark на меньших объемах данных, и загружаются только те данные, которые необходимы для активного задания.
Требуется много тактических усилий, чтобы соединить базы данных Apache Spark и NoSQL (Apache Cassandra и MongoDB) друг с другом. Этот блог посвящен тому, как создавать приложения Apache Spark на бэкэндах NoSQL. TCP/IP sPark — это популярный тематический парк с большим количеством аттракционов в известных секциях CassandraLand и MongoLand. Когда наше приложение Spark искало данные из DOE, оно забуксовало и разочаровалось. Урок здесь заключается в том, что ключевая последовательность Cassandra имеет решающее значение в процессе выборки данных. В CassandraLand также есть популярные американские горки под названием Partitioner. Клиентам, катающимся на американских горках, рекомендуется отслеживать историю своих поездок, чтобы операторы могли отслеживать, кто катался на них каждый день. Mongo, урок 1. Правильное управление соединениями MongoDB При обновлении данных, таких как статус нового членства в парке Министерства энергетики, индексы Mongo могут быть очень полезными. В случае конкретных обновлений MongoDB и Spark должны обеспечить надлежащее управление соединениями и индексацию.
Spark: будущее больших данных
Apache Spark, распределенная система обработки, разработанная в сотрудничестве с Apache Software Foundation, представляет собой систему обработки больших данных на основе Hadoop. Платформа с открытым исходным кодом, которую можно использовать для оптимизации больших наборов данных и преодоления разрыва между процедурными и реляционными моделями. Кроме того, Spark поддерживает MongoDB, что позволяет использовать его для аналитики в реальном времени и машинного обучения.