
Горизонтальная масштабируемость с базами данных NoSQL
Опубликовано: 2022-11-20Базы данных NoSQL являются горизонтально масштабируемыми, что означает, что они могут масштабироваться путем добавления дополнительных узлов в систему, в отличие от вертикального масштабирования, которое означает добавление большего количества ресурсов к одному узлу. Это означает, что базу данных NoSQL можно сегментировать или разделить на несколько частей, и каждая часть может храниться на отдельном сервере. Это позволяет горизонтально масштабировать базу данных, что намного эффективнее и масштабируемее, чем вертикальное масштабирование.
Масштабирование имеет решающее значение для баз данных SQL и NoSQL, и концепция сегментирования базы данных является его неотъемлемой частью. Мы разбиваем базу данных на куски (осколки), как следует из названия.
Кроме того, в NoSQL отсутствуют возможности динамических операций. Нет никакой гарантии, что соединение будет обладать КИСЛОТНЫМИ свойствами. Базы данных SQL являются вариантом в таких случаях. Кроме того, если ваше приложение требует гибкости во время выполнения, избегайте NoSQL.
Каковы некоторые недостатки баз данных NoSQL? Одним из недостатков баз данных NoSQL является то, что в них отсутствует поддержка транзакций ACID (атомарность, согласованность, изоляция, надежность), необходимая для транзакций ACID в нескольких документах. Многие приложения могут использовать атомарность одной записи при правильном проектировании схемы.
Можно ли разделить MongoDB?
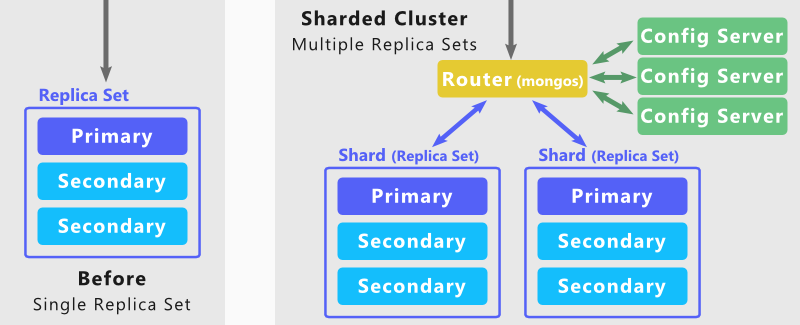
Серверная часть MongoDB построена на архитектуре сегментирования для поддержки очень больших наборов данных и операций с высокой пропускной способностью. Большие базы данных с большими объемами данных или работающие высокоскоростные приложения могут привести к снижению пропускной способности сервера.
Используя MongoDB Sharding, вы можете масштабировать свою базу данных для обработки бесконечного числа одновременных пользователей. Это достигается за счет увеличения пропускной способности операций чтения и записи, а также емкости системы хранения. Существует множество коллекций, из которых вы можете выбрать. Чтобы максимизировать производительность кластера, тщательно выбирайте ключ сегмента. База данных MongoDB NoSQL поддерживает два типа распределения данных по кластерам с возможностью сегментирования. Данные можно разделить на диапазоны, используя значение ключа диапазона сегмента. Используя хэш-хеширование, можно вычислить значение хешированного осколка.
Некоторые ключи сегментов могут быть закрыты, но их хешированные значения вряд ли будут находиться в одном фрагменте. Настроив и включив параметр Sharding, можно будет получить доступ к базе данных. Убедитесь, что ваши монго подключены. Ваши осколки также будут добавлены в кластер. Каждый раз, когда вы выполняете эту процедуру, вы выполняете одну транзакцию для каждого сегмента. Необходимо включить настройку шардинга в вашей базе данных. Затем используйте метод sh.shardCollection(), чтобы разбить вашу коллекцию. Вы создали свой первый сегментированный кластер. До сих пор маршрутизаторы (экземпляры mongos) использовались для взаимодействия приложений.
MongoDB — отличная база данных NoSQL для предприятий малого и среднего бизнеса, которым требуется масштабируемость и производительность. Кроме того, он включает в себя такие функции, как сегментирование, которое позволяет распределять документы по сегментам для повышения производительности. Если ваша база данных достигает 200 ГБ или более, процессы резервного копирования и восстановления могут замедлиться. В результате всякий раз, когда ваша база данных MongoDB превышает определенный размер, вы всегда должны консультироваться со своим поставщиком MongoDB.
Какие базы данных поддерживают шардинг?

Базы данных, поддерживающие сегментирование, обычно предназначены для работы на нескольких серверах, причем на каждом сервере размещается часть базы данных. Это позволяет распределить базу данных по нескольким серверам, что может повысить производительность и масштабируемость.
Шардинг в Nosql

Шаблоны секционирования на основе технологий NoSQL включают хеширование. Разделение предполагает размещение каждого раздела на потенциально отдельном сервере — возможно, во всем мире. Пользователи со всего мира могут извлечь выгоду из такого масштабирования, которое позволяет им одновременно получать доступ к различным частям набора данных.
Наборы данных распределяются путем их хранения в нескольких базах данных для достижения желаемого результата. Поскольку этот подход позволяет разделить большие наборы данных на более мелкие фрагменты, для их хранения можно использовать несколько узлов данных. Поскольку данные распределяются между несколькими машинами, сегментированная база данных может обрабатывать больше запросов, чем может обработать одна машина. Используя сегментирование для неограниченной обработки возросшей нагрузки, вы можете увеличить пропускную способность, емкость хранилища и доступность вашей базы данных. Когда ваша рабочая нагрузка в основном предназначена для чтения, репликация данных обеспечит вам значительный прирост производительности, и вам может вообще не понадобиться использовать сегментирование. Для рабочей нагрузки, основанной преимущественно на записи или смешанной с чтением-записью, требуется другая архитектура. Существует множество различных типов и архитектур шардинга.

Использование сегментирования на основе диапазонов — это простой и понятный метод горизонтального разделения; однако его эффективность будет определяться наличием подходящих ключей и выбором соответствующих диапазонов. Хешированная или алгоритмическая запись сегментирования применяется в качестве входных данных, где хэш-функция или алгоритм используются для создания выходного значения или хэш-значения. Данные можно хранить в одном физическом пространстве с помощью сегментирования на основе хэшей. В реляционной базе данных данные, связанные с определенной таблицей, могут быть распределены по другим таблицам. Даже если невозможно получить подходящий ключ, хеширование входных данных позволяет равномерно распределить данные по осколкам. Это может помочь сократить количество широковещательных операций, а также повысить производительность. Служба сегментирования на основе географии также хранит связанные данные в одном месте на одном сервере. Ранжированный сегмент — это географически распределенный, в котором ключ для ключа является геолокационным ключом для сегментов. Существует ряд других вариантов, которые не рассматриваются в этой статье для распределения геоосколков.
Что такое шардинг в Sql?
Хранилище данных может быть распределено по нескольким базам данных с помощью метода хэширования, а затем сохранено на нескольких компьютерах. Это позволяет разбивать большие наборы данных на более мелкие фрагменты и хранить их в нескольких узлах данных, увеличивая общую емкость системы.
Этот алгоритм не гарантирует равномерного разделения данных
Этот алгоритм, согласно этому алгоритму, гарантирует, что данные будут распределены равномерно по шардам, но не гарантирует, что они будут распределены равномерно по шардам. Строка в столбце раздела с именем данных user_id будет равномерно распределена по пяти сегментам; однако значения данных для пяти осколков не будут разделены поровну.
Использует ли MongoDB шардинг?
Используя комбинацию методов, несколько компьютеров могут обмениваться данными с помощью метода сегментирования. При развертывании больших наборов данных и выполнении операций с большими объемами MongoDB использует сегментирование. Системы баз данных с большим объемом данных или приложениями, требующими высокой пропускной способности, могут занимать значительную емкость хранилища.
Будущее шардинга: Postgresql
Составьте план на будущее. Развернуть решение для сегментирования не только возможно, но и необходимо. В рамках этого процесса требуется регулярная настройка и оптимизация. Вы должны знать, что современные решения для шардинга быстро развиваются, и вы должны идти в ногу со временем. PostgreSQL добился значительного прогресса в области сегментирования за последние несколько лет, поэтому, если вам нужно решение, которое можно использовать на нескольких платформах, вам следует серьезно подумать об его использовании.
Разделение Nosql против разделения
Разбиение и алгоритмы сортировки большого набора данных на более мелкие секции аналогичны. Данные секционируются, чтобы их можно было распределить по многим компьютерам, тогда как сегментирование позволяет распределять их по нескольким компьютерам. Как правило, секционированные данные делятся на подмножества на основе одного экземпляра базы данных .
Разбиение вычитанием — это тип разбиения, помимо горизонтального разбиения. Другой метод — вертикальное разделение, при котором вы делите таблицу на более мелкие фрагменты. При репликации вертикального раздела это называется вертикальным разделением. Чтобы разделить данные, скопируйте схему, а затем используйте ключ сегмента. Вот несколько примеров, когда уместно делить стол. Когда данные секционированы, часто проще выполнять запросы. Предположим, что приложение содержит таблицу заказов, содержащую хронологическую запись заказов, и что эта таблица секционируется каждую неделю. Когда вы запрашиваете заказы на одну неделю, вы сможете получить доступ только к одному разделу таблицы заказов. Процедура сокращения секций для этого запроса теоретически может ускорить его выполнение в 100 раз.