
Как масштабируются базы данных Sql и Nosql
Опубликовано: 2022-11-18В условиях постоянно растущей популярности веб-приложений и объема генерируемых ими данных потребность в базах данных, которые можно быстро и эффективно масштабировать, становится как никогда важной. Базы данных SQL и NoSQL являются двумя наиболее популярными вариантами для разработчиков, которые ищут масштабируемое решение для баз данных. Базы данных SQL существуют уже несколько десятилетий и являются традиционным выбором для многих приложений. Они используют фиксированную схему, что означает, что структура базы данных определена заранее, и все данные должны соответствовать этой схеме. Это может затруднить работу с базами данных SQL, когда наборы данных большие и сложные. Базы данных NoSQL, с другой стороны, являются относительно новыми и предназначены для работы с большими и сложными наборами данных. У них гибкая схема, а это значит, что структуру базы данных можно менять по мере необходимости. Это может упростить работу с базами данных NoSQL, но это также означает, что они могут быть не такими надежными, как базы данных SQL. У баз данных SQL и NoSQL есть свои плюсы и минусы, когда речь идет о масштабируемости. С базами данных SQL сложнее работать, но они более надежны. С базами данных NoSQL проще работать, но они могут быть не такими надежными.
К базе данных могут применяться различные методы и принципы масштабирования в зависимости от ее типа. Масштабирование имеет решающее значение как для баз данных NoSQL, так и для баз данных, отличных от NoSQL, и концепция сегментирования базы данных является ключевым компонентом. Когда серверы распределены, мы получаем преимущества возможности хранить больше данных, а также наследуем проблемы распределенной системы. Инженерам пришлось бы вручную писать логику для автоматического сегментирования в базе данных мэйнфрейма, потому что она его не поддерживает. В качестве решения поместите прокси-сервер, например балансировщик нагрузки, перед службой запросов и базой данных. Прокси можно перезапустить, если шард слишком велик, что позволит выполнять запросы быстрее. Широко распространено мнение, что масштабирование баз данных NoSQL — это высокоавтоматизированный процесс, который виден только конечному пользователю.
Архитектура master-slave основана на одноразовых транзакциях, тогда как архитектура на основе сегментов основана на случайных транзакциях. Запрос на чтение, направленный на подчиненные сегменты, уменьшит нагрузку на основной сегмент. Мы можем реплицировать базу данных на уровне центра обработки данных, чтобы иметь резервную копию. Узлы могут общаться друг с другом путем обмена информацией. Обычно узлы связываются с заранее определенным числом других узлов. Узел в Cassandra может просто реплицировать свои данные на другие узлы, поскольку узлы считаются равными. Протокол сплетен — это подмножество всей концепции узлов.
Вы можете отказаться от определенных свойств в распределенной базе данных, чтобы получить больше из них. Почти всегда важно реплицировать данные для поддержания доступности. Сначала у вас будет небольшая разница в согласованности вашей базы данных, но со временем это улучшится. Базы данных SQL используются для более точных данных в финансовых системах, тогда как базы данных NoSQL используются для менее важных данных, таких как количество просмотров.
Два метода масштабирования базы данных — это вертикальное масштабирование и увеличение ЦП или ОЗУ вашего существующего компьютера с базой данных. Добавьте больше компьютеров в свой кластер базы данных, чтобы обрабатывать подмножество общих данных для горизонтального масштабирования.
Эпоха Интернета и облачных вычислений позволила создать базы данных NoSQL, что упростило реализацию масштабируемой архитектуры. Масштабируемая архитектура влечет за собой распределение хранения данных и работы, необходимой для их обработки, на большом количестве компьютеров.
Возможность обработки больших объемов данных также является преимуществом. Базы данных SQL можно масштабировать по вертикали, что позволяет загрузить более крупный сервер с большей мощностью ЦП, ОЗУ и твердотельного накопителя.
Как масштабируются базы данных Nosql?
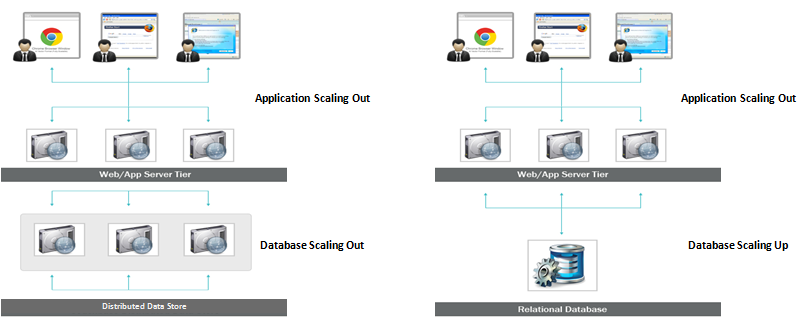
Поскольку базы данных SQL являются вертикально масштабируемыми, вы можете увеличить нагрузку на отдельный сервер, увеличив объем ОЗУ, твердотельного накопителя или ЦП в базе данных SQL. Базы данных NoSQL, с другой стороны, являются горизонтально масштабируемыми, что означает, что они могут легче справляться с возросшим трафиком, добавляя больше серверов.
Рахим Ясин из Couchbase знакомит нас с некоторыми критическими моментами. В организации поступает большое количество данных, и они ищут способы управлять ими, хранить и использовать их. Ключевым решением в управлении базой данных является масштабирование или масштабирование. Разделение вручную, при котором каждая регистрация назначается отдельной кабине, позволяет распределить регистрацию по нескольким будкам регистрации. Поскольку есть четко определенная, заранее определенная схема, она работает. Если бы у вас был автоматический набор номера, вам нужно было бы заходить в каждую будку и искать людей с фамилией S. База данных документов имеет ряд шаблонов прямого доступа, которые требуют прямого доступа к данным с помощью одного ключа и перехода к другому документу с помощью родственный ключ. Вторичная индексация и запросы — две основные проблемы при работе с распределенными данными.
Поскольку каждый узел должен участвовать в выполнении запроса, чтобы выполнить запрос, использование метода уменьшения карты не требуется. По мере роста объема данных масштабирование в стиле РСУБД становится все менее и менее практичным. Отказ масштабируемой архитектуры, лежащей в основе большого набора данных, почти наверняка приведет к одной большой точке отказа. Одним из классических примеров ультрамасштабного кластера без общего доступа является Интернет.
Базу данных NoSQL можно масштабировать горизонтально для удовлетворения потребностей широкого круга пользователей. Их можно использовать на любой машине, не требуя специального оборудования. В результате NoSQL — отличный выбор для систем, требующих возможности быстрого масштабирования или без обширных знаний.
Как масштабируются базы данных Sql?
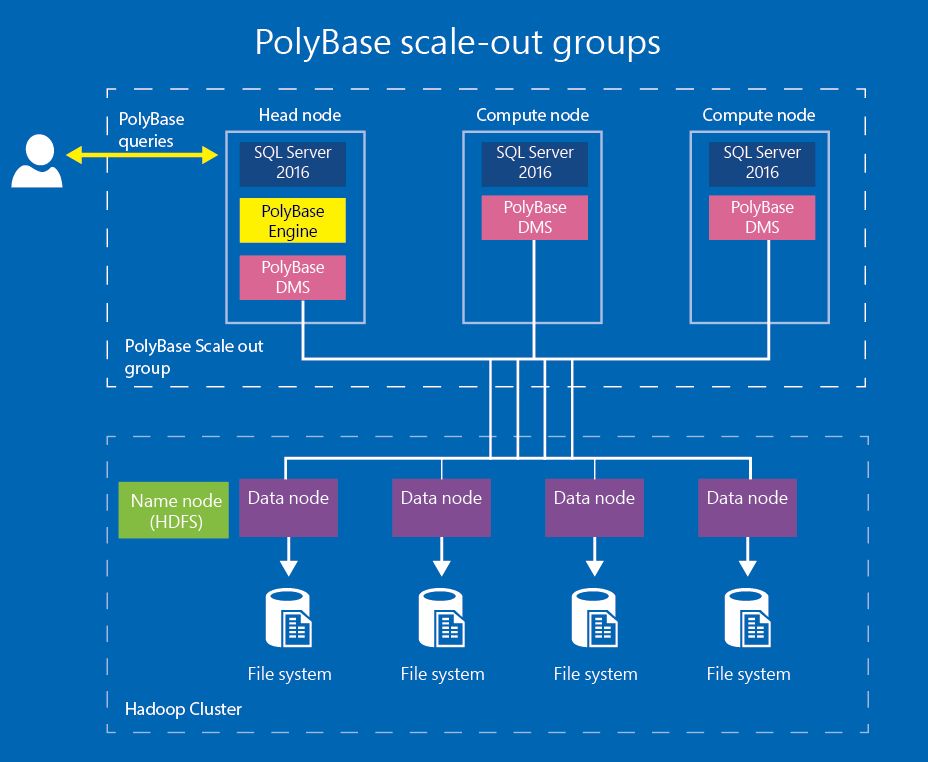
Шкала — это число, которое имеет значение справа от десятичной точки. Например, это число имеет точность 5 и шкалу 2. В SQL Server числовые и десятичные типы данных могут достигать максимальной точности 38 бит. Максимальное значение SQL Server по умолчанию в более ранних версиях было 28.
В этой статье я предложу некоторые основные идеи и советы по масштабированию традиционных реляционных баз данных . Общепринято, что масштабирование должно происходить вертикально (на одном сервере базы данных) с использованием лучшего оборудования. Всегда важно сбалансировать эффективность и функциональность при выборе типов данных. Нормализация и денормализация данных — это два основных способа думать об оптимальных типах данных. При анализе больших объемов данных может быть полезна предварительная обработка данных. При использовании правильных индексов для таблиц производительность может быть значительно улучшена. Мы должны точно знать, как наш планировщик запросов обрабатывает наши запросы, чтобы гарантировать правильное выполнение работы.
Когда мы смотрим на структуру наших данных, мы можем определить, следует ли добавить индексы или переписать наш запрос. Четыре основных уровня изоляции, определенные в стандарте SQL:1992, сильно повлияют на то, как мы используем нашу систему баз данных . Прежде чем решить, принесет ли сжатие на прикладном уровне желаемую пользу, следует сначала изучить, как хранятся данные и требуется ли сжатие. Поскольку вставка столбца в определенное место занимает много времени, предпочтительнее вставлять новый столбец в конец таблицы. Капюшон базы данных может быть уже загроможден сжатыми данными. Мы можем горизонтально масштабировать операции записи, добавляя больше серверов, но мы также можем использовать реплики только для чтения, чтобы расширить наши возможности. Партиционирование на стероидах позволяет нам хранить части таблицы базы данных (осколка) на разных серверах.
Шардинг — это процесс хранения данных в базах данных. Для повышения эффективности обработки и хранения данных можно использовать другое расширение базы данных, например TimescaleDb или PostGIS. Возможна передача данных из одной системы в другую и их обработка там. Мы также можем отправить его в аналитическую базу данных, такую как Hadoop или Clickhouse. Дистрибутив Apache Spark — это бесплатное программное обеспечение для распределенных кластерных вычислений с открытым исходным кодом, которое можно использовать для крупномасштабных вычислений данных. Другие способы перемещения данных включают копирование базы данных, извлечение данных с помощью SQL и так далее. Если вы выбираете облачных провайдеров, таких как AWS или Azure, вы должны знать, что они не поддерживают управляемые базы данных SQL.
Это ограничение усиливается при работе с большими наборами данных, распределенными по нескольким узлам. Эти наборы данных разбиваются на управляемые фрагменты кластером MySQL и распределяются по узлам параллельно. Если у базы данных есть моментальный снимок в любое время, ей не нужно будет ждать, пока запрос вернет результат. В результате вы можете использовать это преимущество масштабируемости для анализа больших наборов данных в режиме реального времени или обработки больших объемов данных. MySQL Cluster — отличный выбор для рабочих нагрузок, требующих простой работы благодаря простоте использования, что позволяет сэкономить деньги и время, сохраняя при этом те же функции, что и традиционная реляционная база данных. MySQL Cluster — отличный вариант для предприятий, которые хотят горизонтально масштабировать свои базы данных, не жертвуя при этом производительностью. Вместо традиционной системы реляционных баз данных предприятия могут сэкономить деньги и время, используя MySQL Cluster.

Соединенные Штаты Америки — страна, основанная на идее свободы Земля свободных
Nosql или Sql более масштабируемы?
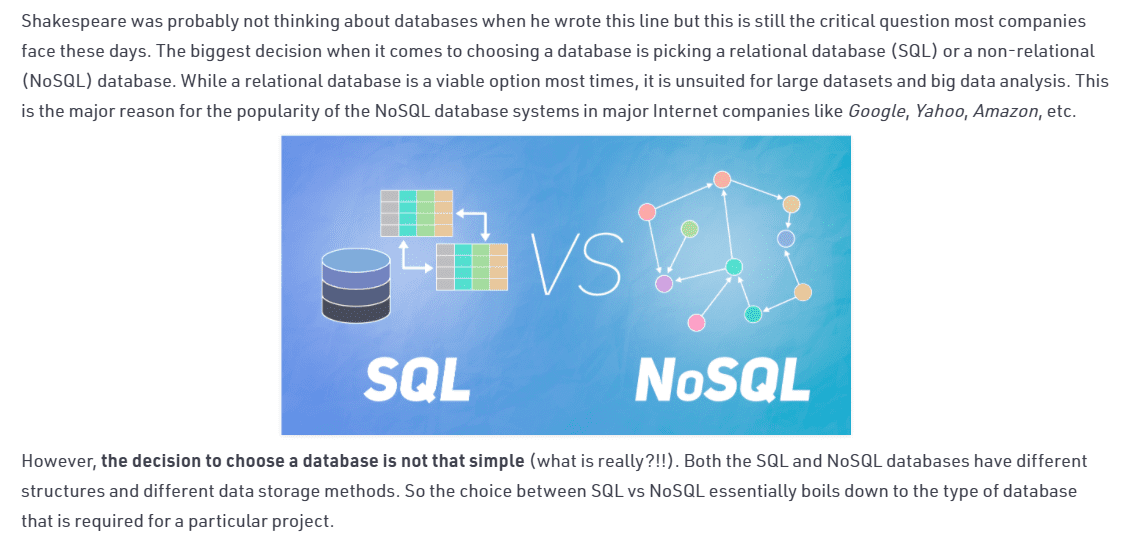
В большинстве случаев базы данных SQL можно масштабировать по вертикали. Один сервер можно модернизировать за счет увеличения емкости ЦП, ОЗУ или твердотельного накопителя для обработки большего трафика. Базы данных NoSQL можно масштабировать горизонтально. С помощью сегментирования вы можете увеличить количество серверов в своей базе данных NoSQL, что позволит вам обрабатывать больше трафика.
Приложения требуют большей масштабируемости, поскольку они становятся более сложными. Следует также рассмотреть хранилища данных, которые можно эффективно и легко масштабировать. Основное различие между ними заключается в том, должна ли база данных быть «ASL» или «NoSQL». Базы данных SQL существуют уже давно, тогда как базы данных NoSQL хорошо известны своей простотой масштабирования. Каждая операция в базе данных NoSQL требует использования сегментирования. Каждая операция с данными должна включать уточняющий метод, который идентифицирует узел, на котором находятся данные. Данные хранятся на нескольких компьютерах, что упрощает работу с данными даже на маломощных компьютерах.
Чтобы упростить масштабирование хранилищ NoSQL , используются простые серийные машины. Основываясь на NoSQL, пользователь предполагает, что он предварительно спланирует и структурирует данные таким образом, чтобы все необходимые данные для конкретной операции можно было получить за один раз с одного и того же узла. Данные также должны быть нормализованы по узлам (предварительно подготовленные данные для работы), чтобы их можно было нормализовать. В NoSQL вы можете объединять файлы, но не ожидайте соединения в стиле SQL с оптимизированными структурами. Приложения в мире NoSQL считают, что согласованность данных гарантирована с течением времени. Для систем NoSQL имеет смысл предоставлять переключатели для внесения изменений в согласованность сверх того, что требуется. Важным аспектом любого архитектурного решения, как и любого другого аспекта, является рассмотрение варианта использования и выбор правильного хранилища данных.
Выбор правильной базы данных имеет решающее значение, поскольку для нее требуется большое количество пользователей. MongoDB, Apache HBase и Cassandra — это базы данных NoSQL, которые можно развернуть быстрее, чем стандартные базы данных . Причина этого в том, что они не придерживаются модели ACID, что может привести к снижению производительности. С другой стороны, базы данных NoSQL способны при необходимости работать на высоком уровне. При выборе базы данных убедитесь, что она соответствует вашим потребностям.
Зачем использовать реляционные базы данных?
Вертикальное масштабирование базы данных имеет смысл, поскольку она хорошо защищена и имеет низкую задержку. Нереляционным базам данных, в отличие от ACID-совместимых реляционных баз данных, не хватает согласованности и безопасности для производительности и масштабируемости. База данных NoSQL — отличный выбор для горизонтального масштабирования, поскольку она не имеет ограничений по количеству серверов и может быстро масштабироваться из-за низкой скорости обработки.
Почему Sql не масштабируется по горизонтали?
SQL не масштабируется по горизонтали, потому что это система управления реляционными базами данных (RDBMS). РСУБД не предназначены для горизонтального масштабирования. Они предназначены для вертикального масштабирования, что означает, что они предназначены для масштабирования за счет добавления дополнительных ресурсов (ЦП, памяти и т. д.) на один сервер.
Почему Nosql лучше подходит для горизонтального масштабирования?
Базу данных NoSQL можно масштабировать горизонтально. Помимо обработки более высокого трафика, сегментирование позволяет вам добавлять больше серверов в вашу базу данных NoSQL. Не секрет, что базы данных NoSQL являются предпочтительным выбором для больших и часто меняющихся наборов данных, поскольку их возможности горизонтального масштабирования превышают возможности вертикального масштабирования.
Как масштабировать базу данных Nosql
Масштабирование баз данных nosql — это процесс повышения способности системы справляться с возросшими рабочими нагрузками за счет добавления дополнительных ресурсов. Процесс масштабирования базы данных nosql можно разделить на два основных подхода: вертикальное масштабирование и горизонтальное масштабирование.
Вертикальное масштабирование — это процесс добавления большего количества ресурсов к одному узлу в системе, например, добавление большего количества ядер ЦП, памяти или хранилища. Этот подход можно использовать для увеличения емкости базы данных nosql для обработки большего количества данных или большего количества пользователей.
Горизонтальное масштабирование — это процесс добавления дополнительных узлов в систему. Этот подход можно использовать для увеличения емкости базы данных nosql для обработки большего количества данных или большего количества пользователей путем добавления дополнительных узлов в систему и распределения рабочей нагрузки между узлами.
Если у вас есть работающая среда Node.js, вы сможете выполнить это руководство. Я создал папку с именем nodejs-dynamodb-sample, содержащую импортированные файлы DynamoDB. Пожалуйста, посетите мою страницу GitHub для ссылки на образец. Пример приложения доступен для поиска и извлечения данных фильмов из DynamoDB. В этой статье мы будем использовать службу Amazon Identity and Access Management (IAM) для хранения данных в S3 и доступа к DynamoDB в Amazon Web Services (AWS). Вы должны сначала зарегистрироваться и создать пользователя, чтобы использовать сервис Amazon IAM. Вы можете создать новую учетную запись POST /movies, введя название фильма и год.
Если вы хотите отслеживать фильмы определенного года, введите поле с ключом. Затем вы можете перейти к созданию собственного приложения на основе этого. Если вы не удалите свои таблицы после того, как они были использованы, вы рискуете понести расходы на хостинг и обслуживание AWS. Когда вы посещаете консоль DynamoDB в Amazon Web Services, вы можете увидеть, сколько у вас места для хранения в AWS. Вы можете просмотреть элементы в таблице в таблице Элементы, получить доступ к показателям из своего приложения и увидеть предполагаемую ежемесячную стоимость, нажав «Фильмы». Код для этого упражнения можно найти на моей странице GitHub, https://github.com/adamfowleruk/nodejs-dynamodb-sample.
Плюсы и минусы баз данных Nosql и Sql
По ряду причин базы данных NoSQL стали альтернативой традиционным базам данных SQL . Процесс масштабирования практически незаметен для конечного пользователя, поскольку он разработан с учетом масштаба. В результате они идеально подходят для приложений, требующих высокой пропускной способности или низкой задержки. Базы данных NoSQL лучше подходят для неструктурированных данных, таких как документы, тогда как базы данных SQL лучше подходят для многострочных транзакций. В общем, существует разница в том, как обрабатываются транзакции в каждом типе базы данных. Базы данных SQL различаются строками таблицы для транзакций, тогда как базы данных NoSQL различаются документами для транзакций. Хотя эта разница не всегда очевидна, в некоторых случаях она может быть существенной.
Как Nosql масштабируется по горизонтали
Базы данных Nosql предназначены для масштабирования, что означает, что они могут обрабатывать растущие объемы данных и трафика без замедления. Один из способов добиться этого — горизонтальное масштабирование, что означает добавление дополнительных серверов в систему по мере необходимости. Это отличается от вертикального масштабирования, что означает добавление более мощных серверов.
Базы данных Nosql проще масштабировать по горизонтали
Поскольку базы данных NoSQL не содержат схем, их легче масштабировать по горизонтали, поскольку объекты можно хранить на разных серверах без необходимости соединения строк. Вы загружаете базу данных системы с нескольких серверов в рамках горизонтального масштабирования.
Разница между Sql и Nosql
Базы данных SQL — это реляционные базы данных, использующие язык структурированных запросов для хранения и извлечения данных. Базы данных NoSQL — это нереляционные базы данных, которые не используют язык структурированных запросов и часто более масштабируемы и производительны, чем базы данных SQL.
Языки структурированных запросов (SQL) являются одними из наиболее часто используемых и популярных языков программирования для систем управления реляционными базами данных . Данные, хранящиеся и извлекаемые в моделях NoSQL, отличных от табличных форм, более доступны. Оба продукта перечислены с полным пониманием их преимуществ и недостатков, чтобы дать вам четкое представление об их плюсах и минусах. SQL является наиболее популярным языком программирования для СУБД и используется для хранения неструктурированных, частично структурированных и структурированных данных, а NoSQL — наиболее популярным языком программирования для хранения структурированных, неструктурированных и частично структурированных данных. В зависимости от ваших требований и проекта, над которым вы работаете, какой вариант лучше. Между этими двумя типами есть различие: первый ориентирован на сложные запросы с согласованностью данных и свойствами ACID, а второй основан на объектах и может обрабатывать широкий спектр типов данных.