
Как хранить структурированные данные в базе данных NoSQL
Опубликовано: 2022-11-17Базы данных NoSQL часто используются для хранения неструктурированных данных , но их также можно использовать для хранения структурированных данных. Существует несколько различных способов хранения структурированных данных в базе данных NoSQL, и наиболее подходящий метод будет зависеть от конкретных данных и желаемого результата. Одним из способов хранения структурированных данных в базе данных NoSQL является использование подхода, ориентированного на документы. Это означает, что данные хранятся в документах, которые затем объединяются в коллекции. Другой способ хранения структурированных данных в базе данных NoSQL — использование подхода «ключ-значение». Это означает, что данные хранятся в хранилище ключей и значений, где каждый ключ соответствует значению. Наконец, подход, ориентированный на графы, также можно использовать для хранения структурированных данных в базе данных NoSQL. Это означает, что данные хранятся в графе, где узлы представляют данные, а ребра представляют отношения между данными.
Термин «неструктурированные данные» имеет широкий спектр коннотаций и может иметь разное значение для разных людей. РСУБД, поскольку она ожидает, что вы все определите, ожидает, что вы сделаете это заранее (особенно, например, будет сложно управлять данными с именем и типом столбца (например, этот). Когда пользователь в последний раз посещал конкретной страны, вы хотели бы знать, как часто они ее посещали. В базе данных № SQL можно смоделировать таблицу таким образом, чтобы имя ячейки соответствовало имени таблицы. BLOB может безопасно храниться в любой СУБД, включая Oracle Database и другие реляционные базы данных . Значение ключа не может быть указано в случаях CLOB и BLOB. Поскольку они полуструктурированы (JSON, XML, не все поля известны), они различаются по своей неструктурированности.
Базы данных NoSQL часто используются для обработки полуструктурированных данных. Устройства IIoT генерируют структурированные, неструктурированные и частично структурированные данные в режиме реального времени. Структурированными данными легко управлять и обрабатывать, когда структура определяется продавцом.
Hadoop может помочь компании структурировать и понять закономерности и тенденции, скрытые в огромных объемах данных, генерируемых из различных источников, особенно в эпоху огромных объемов данных. Очевидно, что превосходные возможности Hadoop для неструктурированных данных невозможно переоценить, но его также можно использовать для решения сложных проблем со структурированными данными.
Для предприятий, которые обрабатывают и анализируют огромные объемы разнообразных и неструктурированных данных, таких как большие данные, NoSQL является лучшим вариантом. Базы данных NoSQL не имеют таких же ограничений, как реляционные базы данных, в отношении того, какие данные могут храниться.
Может ли MongoDB хранить структурированные данные?

Да, MongoDB может хранить структурированные данные. Это достигается с помощью BSON (Binary JSON) для хранения данных в двоичном формате. BSON — это надмножество JSON, поэтому любой документ JSON можно хранить в базе данных MongoDB .
Например, популярность MongoDB в последние годы возросла благодаря целому ряду факторов. Крупномасштабное приложение, в котором данные не могут быть структурированы и должны храниться гибким образом, хорошо подходит для облачного хранилища. Поскольку MongoDB классифицируется как неструктурированная база данных, в ней используется другой подход к хранению данных . Поскольку JSON — это тип данных, который можно форматировать различными способами, текстовые файлы и другие неструктурированные ресурсы хранятся в этом формате. MongoDB хорошо подходит для обработки больших объемов данных, потому что она создана для этой цели. MongoDB может легко обрабатывать большие объемы данных, потому что это физически невозможно.
Какие типы данных хранит Nosql?
Базы данных NoSQL используются для хранения неструктурированных данных, что означает, что они не вписываются в традиционный формат таблиц. Это могут быть сообщения в социальных сетях, комментарии, изображения или что-то еще, что не вписывается в традиционную структуру базы данных . Поскольку базы данных NoSQL более гибкие, они могут быть хорошим выбором для приложений, которым требуется быстрый и простой доступ к большим объемам данных.
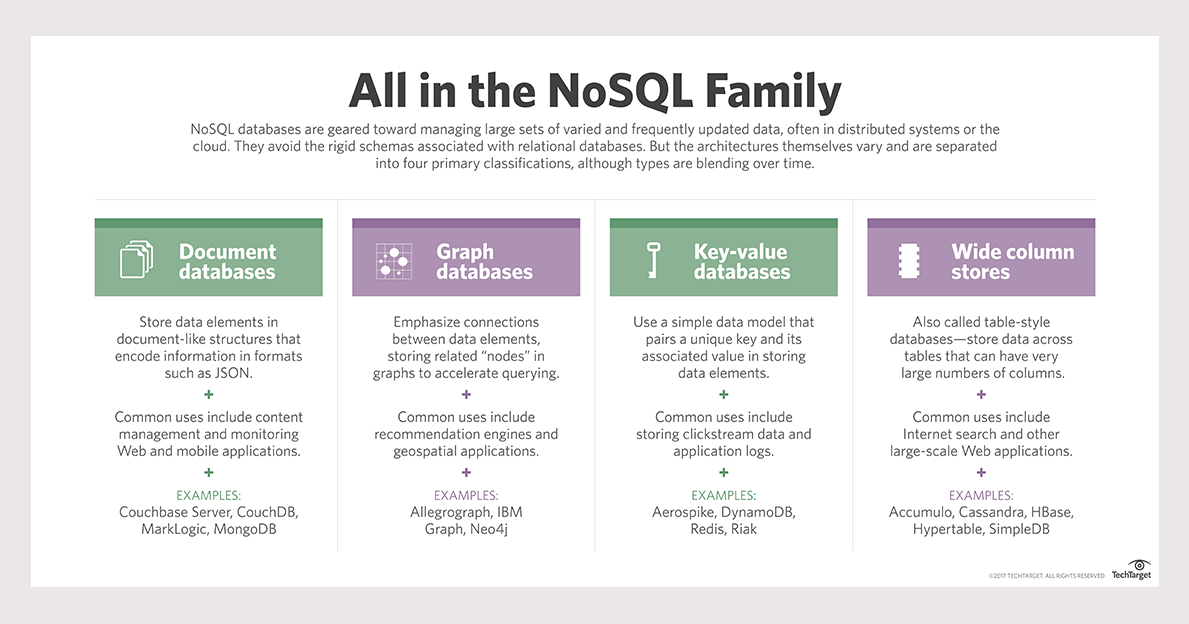
Термин «нереляционная база данных» относится к базе данных, которая не имеет фиксированной структуры. Хранилище «ключ-значение», столбцовые, документные, графовые и графовые базы данных являются наиболее распространенными типами баз данных. В мире NoSQL базы данных типа «ключ-значение» являются одними из самых простых в использовании типов баз данных. Данные хранятся, собираются и удаляются с помощью простого набора функций. База данных хранилища ключей-значений не имеет языка запросов, который можно было бы использовать. Типы данных определяются требованиями приложений, которые их обрабатывают. Наиболее распространенный вариант использования баз данных «ключ-значение» — запись сеансов в приложениях, требующих входа в систему.
В дополнение к более общему варианту использования корзина для покупок позволяет веб-сайтам электронной коммерции хранить данные о сеансе покупок каждого пользователя. Когда проходят праздничные распродажи и специальные акции, масштабируемость хранилищ ключей и значений полезна. Кроме того, система имеет встроенную избыточность, так что ни один предмет из корзины никогда не будет потерян. Базы данных типа "ключ-значение" служат определенной цели и включают в себя функции, повышающие ценность одних и накладывающие ограничения на другие.
Язык программирования MongoDB не только популярен, но и чрезвычайно гибок. В результате вы можете увеличить количество серверов для обработки дополнительной нагрузки. Кроме того, функция репликации MongoDB гарантирует, что данные всегда актуальны и находятся в нескольких местах. В результате MongoDB является очень привлекательным вариантом для крупных организаций, которые хотят, чтобы данные были надежными и непротиворечивыми.
Является ли Nosql неструктурированными данными или полуструктурированными данными?
Нереляционные базы данных используются для хранения структурированных и неструктурированных данных в NoSQL (а не только в языках структурированных запросов). Благодаря высокой масштабируемости и простоте поиска NoSQL идеально подходит для неструктурированных данных.

Данные могут храниться в различных форматах, таких как электронные таблицы, текст и видео или даже аудиофайлы. Это тип данных, которые хранятся в хранилище и, как ожидается, будут иметь некоторую предопределенную структуру перед сохранением. Неструктурированный набор данных — это набор данных, который нельзя хранить в реляционной базе данных из-за отсутствия предопределенной модели данных. Неструктурированные данные — это термин, который относится к неструктурированным данным, которые являются неструктурированными, но содержат некоторую форму метаданных, которые можно использовать для определения структуры данных или иерархии данных. Инженеры и ученые в области машинного обучения и искусственного интеллекта анализируют этот тип данных, используя такие методы, как машинное обучение и ИИ, для извлечения смысла (или даже высокоуровневой структуры). Он включает в себя электронные письма и другие документы в аналогичном формате, но содержащие метаданные, которые позволяют пользователям получать доступ к определенной информации на определенном уровне, независимо от формата. В этой статье мы рассмотрели несколько реальных примеров каждого из различных типов данных, а также рассмотрели, как они используются в современных организациях.
Структурированные данные обычно хранятся в базах данных (которые позже используются для хранения данных). Неструктурированные данные хранятся в нереляционных базах данных или озерах данных, поскольку не существует заранее определенной схемы, которой необходимо следовать для классификации данных. Для полуструктурированных данных и данных на основе иерархии хорошим вариантом является MongoDB.
Популярность систем баз данных NoSQL возросла благодаря их масштабируемости и гибкости. Этот метод хранения данных идеально подходит для неструктурированных и полуструктурированных данных, а также для полуструктурированных и неструктурированных данных. Поскольку с данными проще работать более гибким способом, они идеально подходят для итеративной разработки.
Хранение неструктурированных данных
Неструктурированная система хранения данных — это файловая система, которая не накладывает никакой структуры на данные, которые она хранит. Данные просто хранятся в виде плоского файла без какой-либо структуры, навязываемой файловой системой. Этот тип системы хранения обычно используется для хранения текстовых или двоичных данных, таких как изображения, которые не нужно организовывать каким-либо особым образом.
К этой категории относится около 80% неструктурированных данных. Объем, разнообразие и скорость неструктурированных данных затрудняют их хранение. Системы хранения, которые традиционно создавались для обработки больших объемов неструктурированных данных, в будущем могут оказаться не в состоянии это делать. В результате ваша инфраструктура хранения данных должна быть способна обрабатывать большое количество транзакций, а также масштабироваться. При разработке проекта больших данных очень важно, чтобы предприятия заранее планировали хранить неструктурированные данные. Крайне важно выбрать гибкую, экономически эффективную, масштабируемую инфраструктуру хранения данных, адаптированную к широкому спектру вариантов использования. База данных Nosql (Norelational) — отличный способ хранения этой информации.
MongoDB Atlas или другие облачные базы данных , такие как MongoDB как услуга (DaaS), — отличные варианты. База данных MongoDB хранит данные в формате BSON (подобном json) на основе документов. Атрибуты документа различаются в зависимости от типа данных. Поскольку данные резервируются и могут быть реплицированы, хранилища документов хорошо масштабируются и доступны для проектирования. Платформа базы данных как услуги MongoDB Atlas использует основные облачные платформы, такие как AWS, Azure и Google Cloud, для хранения баз данных. Перед доступом к хранилищу данных необходимо выполнить этап извлечения, преобразования и загрузки (ETL) для неструктурированных данных. Хранилища данных обрабатывают и хранят данные из различных источников, чтобы обеспечить их готовность к анализу. Озера данных хранят все данные в собственном формате, который представляет собой сочетание необработанных и обработанных данных.
Благодаря своей простоте, легкости и простоте обработки JSON идеально подходит для хранения неструктурированных данных. Его можно легко преобразовать в различные форматы, включая HDFS, Cassandra и MongoDB, все из которых поддерживаются этим приложением. Из-за отсутствия необходимости объединения данных наше решение было простым в реализации. Используя функцию json_archive, мы могли бы создавать отдельные файлы для каждого объекта JSON. Реляционная база данных может хранить неструктурированные данные различными способами. Начнем с того, что реляционные базы данных являются наиболее эффективным способом хранения и запроса больших объемов неструктурированных данных. Они обеспечивают высокоэффективное сжатие больших объемов данных, и во многих случаях включают языки запросов, семантику и другие механизмы, обслуживающие определенные типы данных. Во-вторых, структура реляционной базы данных облегчает запрос данных. Каждая запись хранится как отдельный объект JSON в реляционной базе данных, и все ее данные хранятся как один. Независимо от того, ищете ли вы конкретную запись или полный набор записей, вы сможете найти нужную информацию. Третье преимущество реляционной базы данных заключается в том, что она способна обрабатывать большие объемы данных. Помимо возможности хранить десятки миллионов записей, они способны обрабатывать сложные запросы.
Неструктурированные данные: что, где и как хранить
Несмотря на то, что неструктурированные данные могут храниться в любом формате, обычно они хранятся в текстовом или нетекстовом формате. Неструктурированные данные, как правило, требуют большей емкости хранилища, поскольку они не вписываются в предопределенную структуру. Облачное хранилище обеспечивает безопасность и возможность доступа к данным из любого места, что делает его отличным вариантом для неструктурированных данных. Использование файлового хранилища — хороший способ хранения больших объемов данных с целью их организации. Это программное обеспечение основано на хранении на основе пути, что означает, что папки и каталоги используются для хранения данных. Крайне важно знать, где находятся данные в файловой системе хранения, если их нужно найти.