
Введение в Hasura GraphQL Engine для динамических API с PostgreSQL
Опубликовано: 2019-11-07Как правило, в последние годы REST API подвергались критике за негибкость, связанную с быстро меняющимися техническими требованиями. Оглядываясь назад, многие считают, что GraphQL был создан, чтобы удовлетворить эту потребность в дополнительной гибкости и эффективности при разработке API. Таким образом, смягчая недостатки REST API. В результате перехода Facebook от приложений HTML5 к более надежным и нативным настройкам, GraphQL стал популярнее и популярнее за последние пять лет по уважительной причине. В этом блоге мы углубимся в феномен GraphQL, PostgreSQL, а затем подробно познакомимся с движком Hasura GraphQL. Во фрагменте, взаимосвязь и экосистема Hasura GraphQL Engine-PostgreSQL.
GraphQL: бунт Facebook
Хотя многие считают, что GraphQL был создан как протест против REST API, это может быть далеко от истины. По иронии судьбы, он был создан просто для удовлетворения внутренних потребностей Facebook. Первоначально разработанный и открытый командой Facebook, GraphQL часто путают с технологией баз данных. По сути, несмотря на ошибочное представление, GraphQL технически является языком запросов для API, а не для баз данных. Следовательно, это снижает сложность создания API, абстрагируя все запросы к одной конечной точке. В отличие от традиционных REST API, GraphQL является декларативным, то есть возвращается все, что запрошено. Хотя, чтобы получить немного больше контекста, нам нужно сделать шаг назад и вернуться к REST API.
REST-архитектура
Как правило, API-интерфейсы представляют собой правила, процедуры или протоколы, которые определяют, как должны взаимодействовать программные компоненты. Передача репрезентативного состояния (REST) — это, по сути, архитектура проектирования API, обычно используемая при реализации веб-сервисов, где все считается «ресурсом». К сожалению, методология RESTful постоянно ограничивалась работой с отдельными ресурсами. Следовательно, если данные необходимы и поступают из двух или более ресурсов, например, сообщений и пользователей, для сбора всего необходимого потребуется многократный обход сервера. Кроме того, в REST возникали проблемы с выборкой «больше» и «меньше». Все это не было идеальным, особенно с появлением большего количества приложений, управляемых данными, обрабатывающих большие наборы данных, объединяющих связанные ресурсы. Это могло бы объяснить затруднительное положение, с которым столкнулся Facebook.
Таким образом, потребность в архитектуре API, которая бы использовала более гибкий и прогрессивный подход.
Создание альтернативы
В качестве альтернативы, GraphQL не думает о данных с точки зрения URL-адресов ресурсов, вторичных ключей или таблиц, а с точки зрения графа объектов и моделей, использующих NSObjects или JSON. В частности, GraphQL не требует выделенных конечных точек для каждого варианта использования, поскольку различные возможности и варианты использования могут быть представлены в одном «Графике». Используя язык запросов GraphQL, вы можете точно описать, как должен выглядеть ответ, поэтому дополнительные обращения к серверу не требуются. Как язык запросов прикладного уровня, он предназначен для интерпретации строки с сервера/клиента и возврата этих данных в стабильном, понятном и предсказуемом формате. Это просто инструмент для лучшей консолидации данных.
Простота, стабильность и эффективность.
Правда в том, что не все проекты требуют GraphQL, несмотря на его четко определенную схему, поэтому мы точно знаем, что не будем перегружать данные. Однако, если у нас есть корпоративный продукт, который использует данные из нескольких источников, например, MySQL, Postgres и других API, то GraphQL — лучший вариант. GraphQL гордится своей простотой, особенно в отношении извлечения данных, поскольку данные собираются под общей конечной точкой или вызовом. По сути, поскольку клиенты получают именно то, что им нужно, это эффективно уменьшает размер каждого запроса, сделанного клиентом, что приводит к высокопроизводительным приложениям. Поскольку GraphQL объединяет данные, для которых в противном случае потребовалось бы несколько конечных точек, он упрощает сложное повторное извлечение, тем самым повышая эффективность запросов. Следовательно, его простота обеспечивает большую стабильность, планирование, построение, выполнение и непрерывную работу с течением времени.
Преимущества GraphQL
В двух словах, GraphQL позволяет извлекать данные с помощью легко понятных запросов, позволяет быстро разрабатывать легкие и быстрые приложения, поскольку доступ к данным осуществляется более напрямую, чем через сервер. Кроме того, он позволяет извлекать несколько ресурсов с помощью одного запроса без использования нескольких URL-адресов или цепочки ресурсов, используя при этом одну конечную точку для всех данных. Помните, что данные определяются на сервере с помощью схемы на основе графа, поэтому они доставляются в виде пакета, а не посредством нескольких вызовов. Это позволяет ускорить сбор ответов API во время разработки API.
Это, в свою очередь, снижает нагрузку на команды разработчиков переднего плана, упрощает управление версиями API, упрощает обслуживание и снижает требования к передаче данных. Кроме того, он обеспечивает большую предсказуемость при получении данных, поддерживает декларативную выборку данных и снижает вероятность избыточной и недостаточной выборки. По сути, избыточная выборка происходит, когда клиент загружает больше информации, чем на самом деле требуется в приложении, в то время как недостаточная выборка подразумевает, что конкретная конечная точка не предоставила достаточно информации, что требует от клиента дополнительных запросов для получения того, что ему нужно.
Технически GraphQL — это оболочка, которую можно определить, что означает, что вам не нужно полностью заменять систему REST. По сути, это означает, что GraphQL совместим с системами, с которыми совместимы REST-ориентированные API. Кроме того, GraphQL обеспечивает плавную и независимую разработку клиентской и серверной частей. Это связано с тем, что после того, как схема будет четко определена, команды, работающие над внешним и внутренним интерфейсом, будут знать об определенной структуре данных. Многие разработчики полного стека считают все эти преимущества выгодными. Наконец, GraphQL обладает удивительной способностью к тщательному самоанализу и самодокументированию.

Варианты использования GraphQL в разработке API
Считающийся чрезвычайно мощным, GraphQL используется разработчиками полного стека, которым требуется стабильная читабельность, высокая скорость и индексация. В частности, GraphQL полезен при разработке API, требующих высокой пропускной способности данных. По сути, это минимизирует объем данных, необходимых для передачи по сети. Это очень удобно для мобильных пользователей, маломощных устройств и ненадежных сетей. Это одна из первых причин, по которой Facebook разработал GraphQL. Вопреки распространенному мнению, GraphQL применим не только в огромных сложных базах данных, он может создавать относительно простые базы данных с большей эффективностью.
Кроме того, его можно применять на множестве уникальных интерфейсных фреймворков и платформ, обеспечивая разнородный ландшафт, поддерживаемый с помощью одного API, который соответствует всем требованиям пользователя. Кроме того, это способствует быстрой разработке функций, поскольку значительно увеличивает скорость разработки функций для групп разработчиков с полным стеком. Это достигается за счет сокращения взаимодействия, необходимого между командами при разработке новых функций, поскольку разработчики внешнего интерфейса могут делать запросы к API, например, для введения новых функций или изменения существующих, не дожидаясь, пока разработчики бэкенда доставят их. Этого краткого обзора GraphQL должно быть достаточно, поскольку мы приступаем к знакомству с движком Hasura GraphQL. Хотя давайте коснемся PostgreSQL для большего контекста.
Что такое PostgreSQL?
Как бесплатная система управления реляционными базами данных, управляемая сообществом, PostgreSQL не принадлежит какой-либо одной компании. Postgres считается самой мощной и внутренне согласованной доступной СУБД. Она была написана на C и поддерживает ряд языков программирования, таких как C/C++, JavaScript, Java, Python, R, Go, Lisp, .Net и т. д. разработчиками полного стека, PostgreSQL более многофункционален, чем его сестра MySQL, и набирает популярность благодаря своим функциям, масштабируемости и производительности. PostgreSQL популярен в проектах, где требования связаны со сложными процедурами, замысловатым дизайном, индивидуальной интеграцией и целостностью данных.
Преимущества Postgres для Full-Stack разработчиков
Как правило, такие функции, как полнотекстовый поиск, столбцы JSON, логическая репликация, дают Postgres преимущество над MySQL. Это оптимально для требований к производительности типичных коммерческих баз данных, позволяя консолидировать несколько систем баз данных в одну с меньшими накладными расходами и затратами. Кроме того, его более поздние функции для хранилища ключей-значений (типы столбцов JSON / JSONB) делают его подходящей альтернативой базам данных NoSQL. Кроме того, он поддерживает кластеризацию или архитектуру master-slave, что делает его хорошо подходящим для облачных сред. Кроме того, его популярное расширение внешней оболочки данных позволяет запрашивать внешние источники непосредственно из PostgreSQL, когда это необходимо. В частности, он лучше всего подходит для систем, требующих выполнения сложных запросов, хранения данных и динамического анализа данных.
На самом деле, PostgreSQL лучше поддерживает определенные функции, которых нет в MySQL. Например, проверьте ограничения, расширенные типы данных (такие как массивы, карты, JSON), расширенную геопространственную поддержку (PostGIS) и расширенную полнотекстовую поддержку. Кроме того, он поддерживает неблокирующее создание индексов, частичные индексы, общие табличные выражения и дополнительные функции динамической аналитики. Тем не менее, PostgreSQL предлагает встроенную поддержку SLL для соединений для шифрования связи между клиентом и сервером, а также встроенное расширение под названием SE-PostgreSQL, которое обеспечивает дополнительные элементы управления доступом на основе политики SELinux.
Благодаря большому количеству функций для продуктов корпоративного уровня PostgreSQL подходит для больших систем, где данные требуют проверки подлинности, а скорость чтения/записи имеет решающее значение для успеха проекта. Кроме того, он также поддерживает несколько средств повышения производительности, которые обычно доступны в проприетарных решениях. К ним относятся: параллелизм без блокировки чтения, SQL-сервер и поддержка геопространственных данных, и это лишь некоторые из них.

Еще одним важным преимуществом архитектуры Postgres является ее уникальная расширяемость. Он позволяет пользователям добавлять такие функции, как типы данных, методы доступа к индексам, языки серверного программирования, сторонние оболочки данных (FDW) и загружаемые расширения без изменения основного системного кода. Он использует современную многоядерную архитектуру процессора, что позволяет его производительности расти почти линейно по мере увеличения количества ядер. Это важно. Обычно такие функции, как полнотекстовый поиск, столбцы JSON, логическая репликация, дают Postgres преимущество над MySQL. Это оптимально для требований к производительности типичных коммерческих баз данных, позволяя консолидировать несколько систем баз данных в одну с меньшими накладными расходами и затратами. Кроме того, его более поздние функции для хранилища ключей-значений (типы столбцов JSON / JSONB) делают его подходящей альтернативой базам данных NoSQL. Кроме того, он поддерживает кластеризацию или архитектуру master-slave, что делает его хорошо подходящим для облачных сред. Кроме того, его популярное расширение внешней оболочки данных позволяет запрашивать внешние источники непосредственно из PostgreSQL, когда это необходимо. В частности, он лучше всего подходит для систем, требующих выполнения сложных запросов, хранения данных и динамического анализа данных.

Минусы PostgreSQL
Как правило, если вам нравятся стандарты ANSI SQL, рассмотрите PostgreSQL, хотя, если вы предпочитаете стандарты ODBC, выберите MySQL. К сожалению, производительность Postgres иногда отстает от работающих, «всегда работающих» производственных сред. Дополнительным недостатком Postgres является тот факт, что его репликация реализована на уровне механизма хранения. Это делает его более дорогим, чем репликация MySQL, которая является более зрелой и реализована на «уровне механизма запросов».
Введение в движок Hasura GraphQL
Поскольку мы кратко рассмотрели разработку GraphQL API и PostgreSQL, у нас должно быть достаточно контекста для введения в движок Hasura GraphQL. По сути, Hasura — это просто механизм GraphQL для СУБД PostgreSQL, обеспечивающий упрощенный способ начальной загрузки и управления разработкой API GraphQL. Оглядываясь назад, Hasura в настоящее время является единственным доступным решением, которое мгновенно добавляет GraphQL-as-a-Service в существующие приложения на основе PostgreSQL. По сути, обходя трудоемкую задачу написания внутреннего кода, который обрабатывает GraphQL.
Хасура упрощенный
Давайте на минуту упростим Хасуру еще больше. По сути, API — это интерфейсы, которые позволяют вам запрашивать информацию (запрос) и, таким образом, отвечать, отправляя данные JSON или XML. Эта база данных обычно размещается и загружается с сервера. Вот тут-то и приходит Хасура, чтобы все упростить. Оглядываясь назад, можно сказать, что механизм Hasura GraphQL — это сервер, который обрабатывает ваши запросы GraphQL через базу данных Postgres. Это эффективно сокращает время, необходимое вашему приложению для подготовки к работе, позволяя вам легко создавать, просматривать и изменять таблицы вашей базы данных всего за несколько кликов. Следовательно, это позволяет разработчикам полного стека создавать масштабируемые приложения GraphQL на PostgreSQL в более короткие сроки. Это экономит разработчикам недели на предварительное кодирование и может предотвратить попадание проблемных ошибок, связанных с утечкой данных, в рабочую среду.
Какую проблему решает Hasura в разработке API?
Как правило, Hasura упрощает управление жизненным циклом API во время крупномасштабного производственного использования, особенно для сложных API. Прежде всего, GraphQL Engine привлекает разработчиков полного стека, у которых есть отставание в проектах разработки корпоративных API с использованием существующих баз данных PostgreSQL. В идеале, поскольку GraphQL обеспечивает молниеносные циклы разработки API, Hasura предоставляет организациям упрощенный способ поэтапного перехода на GraphQL, не затрагивая существующие приложения, базы данных или пользователей. Помимо легкости и высокой производительности, движок поставляется с пользовательским интерфейсом администратора, позволяющим вам исследовать API-интерфейсы GraphQL и визуально управлять схемой базы данных и данными.
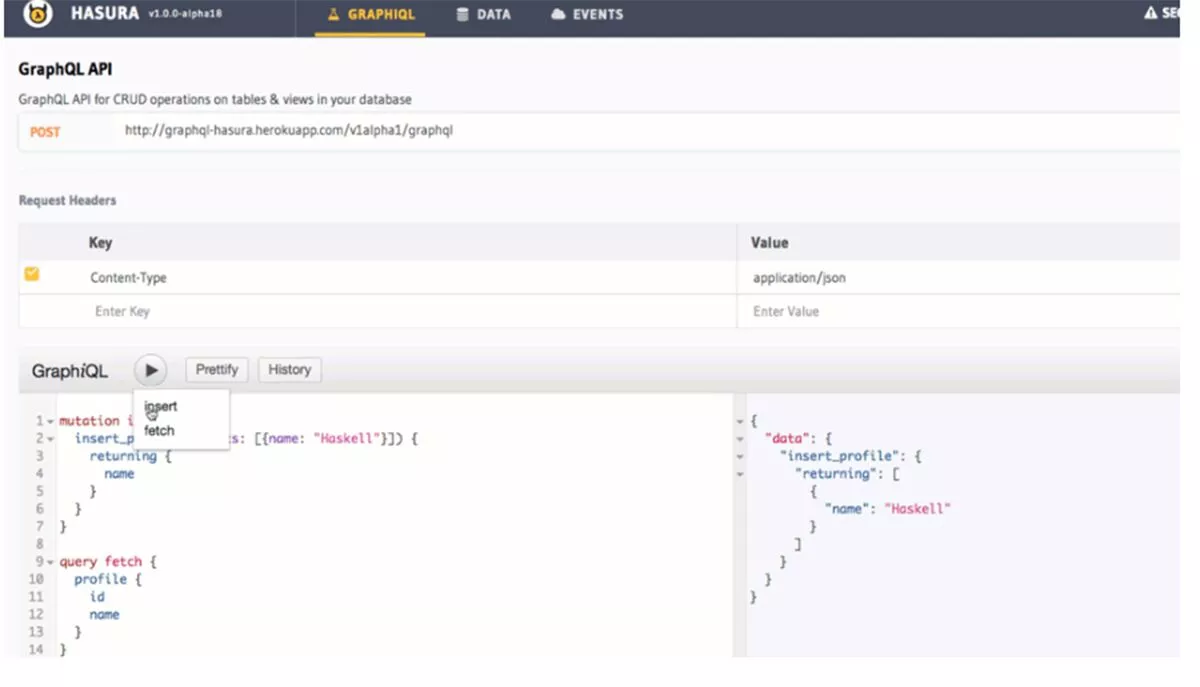
Преимущества Хасуры
Во-первых, у Hasura есть надежная и стабильная модель управления изменениями базы данных или «миграциями». Это выгодно, поскольку управление схемой базы данных часто бывает сложным. Например, такие задачи, как; отслеживание изменений с течением времени и связывание изменений схемы с улучшениями API (управление схемой). Кроме того, рутинные задачи, такие как поддержка сценариев, которые могут развернуть новую базу данных или откатить изменения, могут оказаться утомительными и вызвать труднодиагностируемые ошибки или простои. Положительным моментом является то, что компоненты миграции базы данных Hasura представляют собой простой SQL, поэтому его можно переносить за пределы набора инструментов Hasura. В общем, Hasura имеет отличные функции управления схемой, и вам не нужно писать код для обработки подключений к веб-сокетам.
Во-вторых, механизм Hasura GraphQL позволяет легко извлекать необходимые данные с помощью одного запроса. Это достигается за счет того, что вы можете добавлять представления как отношения к таблицам или другим представлениям. Кроме того, он позволяет создавать собственные преобразователи со сшиванием схемы и интеграцией бессерверных функций или API-интерфейсов микросервисов, которые запускаются при событиях базы данных. Это может пригодиться и облегчает создание приложений 3factor. На самом деле Hasura — чрезвычайно легкий двигатель. Оглядываясь назад, он потребляет всего до 50 МБ ОЗУ даже при обслуживании более 1000 запросов в секунду. Блестящая окупаемость инвестиций!
В частности, Hasura еще больше упрощает детализированную авторизацию и аутентификацию на уровне данных API. Он позволяет подключаться к предпочтительному поставщику аутентификации через веб-перехватчик, JWT, Auth0 или пользовательские реализации. И, таким образом, спецификация ролей для пользователей, определяющая, кто может получить доступ к различным данным, например, администратор, анонимные пользователи и т. д. Как правило, его гранулярная система контроля доступа основана на структуре таблиц базы данных, аналогичной схеме GraphQL. Кроме того, настраиваемые правила разрешений строго определены на основе операций и значений базы данных.
Наконец, Hasura блестяще поддерживает эффективную подкачку с помощью простой SQL-подобной модели смещения/ограничения. Например, он использует модель управления доступом для ограничения количества строк, возвращаемых для данного запроса. Его модель позволяет настраивать лимиты по ролям. Например, пользователи, которые навязывают гораздо более высокую скорость запросов, ограничены меньшими ограничениями на количество строк. Это позволяет избежать нагрузки на базу данных и механизм GraphQL. Кроме того, в частности, Hasura не ограничивает вас только GraphQL. Вы по-прежнему можете запускать REST или другие микросервисы, отличные от GraphQL, для таблиц Postgres, которыми управляет Hasura. Это возможно с помощью автоматического сшивания схем Hasura. Это позволяет объединить службу GraphQL, не относящуюся к Hasura, и серверную часть для единой унифицированной схемы, объединяя новые API, управляемые Hasura, с устаревшими API и данными.
Примеры использования хасуры
Подходящий для высокопроизводительных сред, Hasura Engine обеспечивает скорость при автоматизации реализации GraphQL-Postgres в существующих базах данных. Следовательно, это предоставляет компаниям, уже использующим Postgres, менее напряженный и поэтапный способ перехода на GraphQL путем связывания существующих таблиц в «граф». Hasura эффективно позаботится о сшивании схемы, позволяя легко применять пользовательскую бизнес-логику. Благодаря удаленным схемам GraphQL Hasura можно использовать в качестве шлюза для настраиваемой бизнес-логики, позволяя вам писать на серверы GraphQL на вашем любимом языке, а затем предоставлять данные одной конечной точке. Кроме того, Hasura имеет отличный синтаксис для запросов и мутаций со встроенными оперативными запросами, называемыми подписками в GraphQL.
Несколько ограничений Хасуры
К сожалению, модель системы контроля доступа Hasura не будет полностью работать для каждого приложения. Например, он не полностью поддерживает авторизацию доступа к API на уровне отдельных входных параметров. Не говоря уже о том, что он ограничен базой данных Postgres, требующей миграции в большинстве случаев. Хотя сообщения об ошибках, которые GraphQL API возвращает для некорректно сформированных запросов, незначительны, они довольно недружественны для Hasura. В противном случае Hasura мало что может сделать, как мы видели в этом введении в Hasura GraphQL Engine.
Вывод
В заключение, по мере роста GraphQL, по сути, он еще больше упростит разработку API на предприятиях для создания веб-масштаба. Благодаря широкомасштабному и быстрому внедрению GraphQL в различных отраслях, Hasura имеет потенциал для дальнейшей автоматизации создания API-интерфейсов и управления ими с помощью стандартных отраслевых технологий, GraphQL и Postgres. Hasura упрощает создание CRUD (создание, чтение, обновление и удаление) бэкэндов GraphQL. Что еще более важно, Hasura, безусловно, лучший и единственный вариант, если вы начинаете с нуля с API, ориентированным на GraphQL, и Postgres, без написания внутреннего кода. По любым вопросам или консультациям по корпоративным возможностям GraphQL и Hasura обращайтесь к нам. Вот и все, что мы познакомились с Hasura GraphQL Engine.