
Искра для Nosql
Опубликовано: 2023-02-05Spark — мощный инструмент для работы с данными, особенно с большими наборами данных. Он разработан, чтобы быть быстрым и эффективным, и поддерживает различные форматы данных, включая базы данных NoSQL . Базы данных NoSQL становятся все более популярными, поскольку они хорошо подходят для обработки больших объемов данных. Spark может помочь вам эффективно запрашивать данные NoSQL и управлять ими.
Для эффективной работы очень важно управлять базами данных вашего приложения с помощью Apache Spark и NoSQL ( Apache Cassandra и MongoDB). Цель этого блога — предоставить советы по разработке приложений Apache Spark с использованием бэкендов NoSQL. Это тематический парк, а в TCP/IP sPark есть аттракционы как в CassandraLand, так и в MongoLand. Когда мы попытались запросить данные DOE, наше приложение Spark начало вращаться со своей оси. Урок здесь заключается в том, что при запросе Cassandra важны последовательности клавиш. CassandraLand также предлагает американские горки Partitioner, которые являются одним из самых популярных аттракционов. В то время как клиенты наслаждаются поездкой на американских горках, операторы аттракционов могут отслеживать, кто катался на них каждый день, сохраняя свою информацию.
В первом уроке мы рассмотрим управление соединениями MongoDB. Когда вам нужно обновить информацию о парке, например о новом статусе членства в парке Министерства энергетики, вы можете использовать индексы mongo . MongoDB и Spark следует использовать для обеспечения надлежащего управления вашим соединением, а также для индексации в определенных случаях.
Apache Spark — это популярная система распределенной обработки данных с открытым исходным кодом, созданная для использования в рабочих нагрузках с большими данными. Эта функция, в дополнение к кэшированию в памяти и оптимизированному выполнению запросов, позволяет выполнять быстрые аналитические запросы к большим объемам данных.
Имея почти такой же код, он более эффективен и универсален, позволяя одновременно обрабатывать пакетные данные и данные в реальном времени. В результате старые инструменты работы с большими данными становятся все более устаревшими из-за отсутствия в них этой функциональности.
Какой тип базы данных Spark?
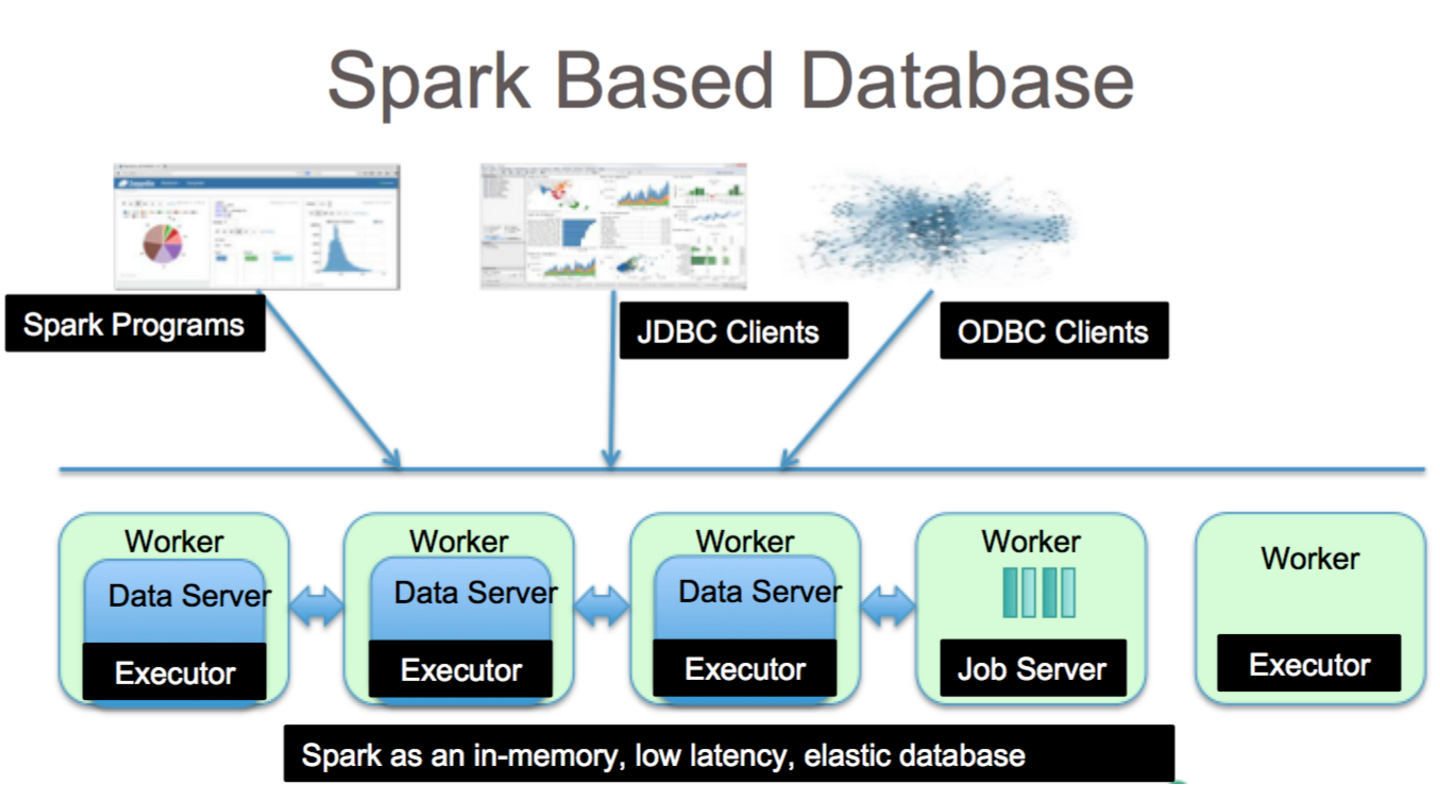
Apache Spark — это платформа обработки данных, которая может обрабатывать данные из различных репозиториев данных, включая (HDFS), базы данных NoSQL и реляционные базы данных.
Несмотря на то, что реляционные базы данных неоднократно подвергались ажиотажу, они будут по-прежнему популярны, независимо от последних достижений и появления баз данных NoSQL. Со временем хранить данные в реляционных базах данных становится все труднее. В этой статье мы рассмотрим некоторые из значительных достижений в использовании преимуществ реляционной базы данных в глобальном масштабе. Когда он был впервые выпущен, интерфейс между Spark и анализом больших данных был минимальным. Многие люди написали много кода, чтобы запустить эту мощную, но относительно медленную программу. Пользователи смогут легко комбинировать эти две модели в базе данных Spark SQL . Он также принимает широкий спектр форматов данных из различных источников.
Проект с открытым исходным кодом Apache Spark является наиболее активным, в него вносят свой вклад сотни участников. Помимо бесплатного проекта с открытым исходным кодом, Spark SQL начал набирать популярность в основных отраслях. Помимо Spark SQL, примерно две трети клиентов Databricks Cloud (размещенная служба, на которой работает Spark) используют другие языки программирования. После завершения нашего первого тематического исследования мы продемонстрируем, как применить блоки данных к делу в этом практическом примере. Spark DataFrame — это набор строк (типов строк), распределенных по одной и той же схеме. Каждый столбец в наборе данных помечен именем. API DataFrame позволяет разработчикам интегрировать процедурный и реляционный код.

Spark также может обрабатывать расширенные функции, такие как UDF. Таблица в реляционной базе данных аналогична фрейму данных в базе данных фрейма данных, но здесь требуется больше оптимизаций. Ими можно манипулировать так же, как и собственными распределенными коллекциями Spark (RDD). В целом запрос Spark SQL быстрее, чем запрос Shark, и более конкурентоспособен с Impulsa. В Query 3a, где из-за избирательности запроса одна из таблиц оказывается очень маленькой, существует значительная разница между Impala и Impala.
Это фантастический инструмент для анализа данных с помощью Spark SQL. Доступ к синтаксису HiveQL, Hive SerDes и HiveDF можно получить через синтаксис HiveQL, а также через Hive SerDes и HiveDF. Хранилища метаданных Hive , SerDes и UDF уже реализованы. Несмотря на то, что Spark — это база данных, это также база данных NoSQL. В результате при создании управляемой таблицы в Spark вы сможете использовать различные инструменты, совместимые с SQL, для хранения данных. Выражения SQL можно использовать для доступа к таблицам в Spark путем подключения к JDBC через коннекторы с сайта jdbc.org. В результате вы также можете использовать сторонние инструменты, такие как Tableau, Talend и Power BI. Возможность использования Spark идеально подходит для анализа данных, и это полезный инструмент для широкого круга отраслей.
Spark Sql: лучшее из обоих миров
Он устраняет разрыв между двумя моделями, упомянутыми ранее, процедурной и реляционной, за счет включения двух основных компонентов. В результате вы можете выполнять крупномасштабные реляционные операции с внешними источниками данных и встроенными распределенными коллекциями Spark с помощью API DataFrame.
Что такое искра в базе данных? Это платформа с открытым исходным кодом, использующая машинное обучение, интерактивную обработку запросов и рабочие нагрузки в реальном времени. У этой компании нет собственной системы хранения; скорее, он использует аналитику в других системах хранения, таких как HDFS, Amazon Redshift, Amazon S3, Couchbase и других, в дополнение к своей собственной. Когда дело доходит до обработки структурированных данных, Spark SQL — это не просто база данных; это тоже модуль. Подавляющее большинство из них написано на DataFrames, которые представляют собой программные абстракции, работающие в сочетании с SQL-запросами.
Какой тип SQL sql для «sparksql»? Hive SQL поддерживает синтаксис HiveQL, а также Hive SerDes и UDF, что позволяет вам получать доступ к ранее созданным хранилищам Hive. Использовать существующие хранилища метаданных Hive, SerDes и UDF в Spark SQL несложно.
Может ли MongoDB запускать Spark?
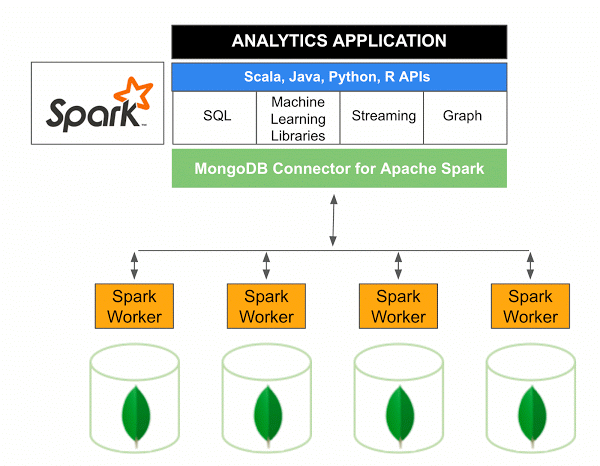
Версия 10.0 соединителя MongoDB для Apache Spark включает в себя поддержку Spark Structured Streaming через новый Spark Data Sources API V2 , а также реализацию нового Spark Data Sources API V2.
Коннектор MongoDB для Spark — это проект с открытым исходным кодом, который позволяет записывать данные из MongoDB и читать их из MongoDB с помощью Scala. Благодаря служебным методам соединителей взаимодействие между Spark и MongoDB упрощается, что делает их мощной комбинацией для создания сложных аналитических приложений. Используя встроенные функции репликации и сегментирования, Spark можно реализовать в различных рабочих нагрузках, использующих базы данных MongoDB .
Spark: быстрый способ создания приложений с большим объемом данных
С помощью мощного инструмента Spark вы можете быстро разрабатывать более функциональные приложения. Включив MongoDB, разработчики могут ускорить процесс разработки, используя единую технологию базы данных. Кроме того, Spark предназначен для работы в облаке и включает поддержку хранилищ данных NoSQL , что делает его идеальным для приложений, интенсивно использующих данные.