
MapReduce: модель программирования для больших наборов данных
Опубликовано: 2023-01-08MapReduce — это модель программирования и связанная с ней реализация для обработки и создания больших наборов данных с помощью параллельного распределенного алгоритма в кластере.
Мы трансформируем то, как мы работаем с огромными объемами данных, используя новые технологии. Хранилища данных, такие как Hadoop, NoSQL и Spark, являются одними из самых известных игроков в этой области. Администраторы баз данных и инженеры/разработчики инфраструктуры относятся к новому поколению профессионалов, специализирующихся на управлении системами высокого уровня сложности. Вместо базы данных Hadoop представляет собой программную экосистему, которая позволяет выполнять параллельные вычисления в виде массивных файлов. Эта технология обеспечила значительные преимущества с точки зрения поддержки больших потребностей в обработке больших данных. Для большой транзакции данных среднему кластеру Hadoop может потребоваться всего три минуты для обработки большой транзакции, которая обычно занимает 20 часов в централизованной системе реляционной базы данных.
Кластер mapreduce — это кластер с параллельным алгоритмом и моделью программирования, который обрабатывает и генерирует большие наборы данных так же, как и обычный кластер.
Экосистема Apache Hadoop предназначена для поддержки распределенных вычислений и обеспечивает надежную, масштабируемую и готовую к использованию среду. Модуль MapReduce этого проекта представляет собой модель программирования, используемую для обработки огромных наборов данных, находящихся в Hadoop (распределенная файловая система).
Этот модуль является компонентом экосистемы с открытым исходным кодом Apache Hadoop и используется для запроса и выбора данных в распределенной файловой системе Hadoop (HDFS). Данные могут быть выбраны для различных запросов с использованием алгоритма MapReduce, доступного для целей такого выбора.
Используя MapReduce, можно запускать задачи по обработке больших данных. Вы можете создавать программы MapReduce на любом языке программирования, включая C, Ruby, Java, Python и другие. Эти программы можно использовать одновременно для запуска программ MapReduce, что делает их очень полезными при анализе крупномасштабных данных.
Для чего используется Mapreduce в MongoDB?
Карты в MongoDB — это программная модель обработки данных, которая позволяет пользователям обрабатывать большие наборы данных и генерировать из них агрегированные результаты. MapReduce — это метод, используемый MongoDB для сокращения карт. Эта функция разделена на два компонента: функцию отображения и функцию сокращения.
Используя инструмент MapReduce от MongoDB, можно организовывать и агрегировать большие наборы данных. Эта команда в MongoDB использует два основных входа в MongoDB: функцию отображения и функцию сокращения для обработки большого объема данных. Для определения примеров выполните следующие действия. Мы определим функцию карты, функцию сокращения и примеры.
MapReduce будет сравнивать строки для сортировки вывода с использованием метода сортировки по умолчанию, независимо от того, используете ли вы метод по умолчанию или нет. Чтобы изменить способ сортировки данных, необходимо сначала создать алгоритм сортировки, а затем реализовать его с помощью класса преобразователя.
SpiderMonkey — широко используемый движок JavaScript. Он хорош для небольших приложений, но имеет некоторые ограничения. Например, у SpiderMonkey нет алгоритма сортировки. В результате, если вы хотите использовать Mapmapper для сортировки данных, вы должны сначала создать собственный алгоритм сортировки и реализовать его в классе Reduce.
Несмотря на свою популярность, SpiderMonkey не использует алгоритм сортировки. У SpiderMonkey есть и другие ограничения, но это примечательно. SpiderMonkey, например, не имеет хорошего сборщика мусора, поэтому, если ваша программа начинает тормозить, вам, возможно, придется принять некоторые меры, чтобы сделать ее быстрее.
Зачем использовать функцию Mapreduce?
Функция MapReduce может быть полезна в различных ситуациях. В некоторых случаях этот метод можно использовать для пакетной обработки данных. Это также полезно, если вам требуется, чтобы большое количество данных обрабатывалось одним приложением или процессом. Функцию MapReduce также можно использовать для обработки данных, разбросанных по нескольким узлам в распределенной системе. Используя функцию MapReduce, данные с узлов можно объединить в один вывод. Приложение MapReduce обычно используется для обработки больших объемов данных, хотя может потребоваться и для обработки очень больших объемов.
Почему это называется Mapreduce?
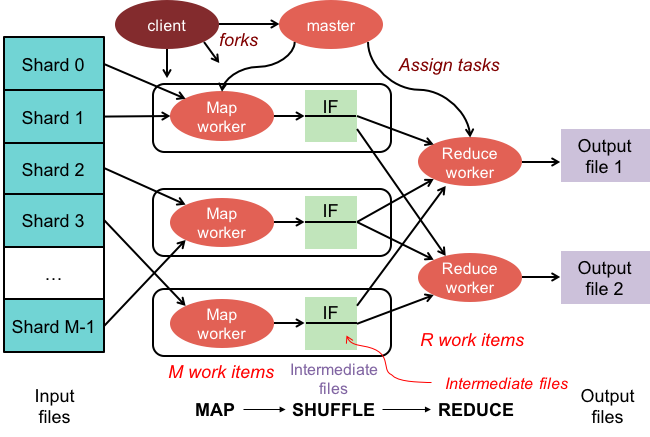
Есть несколько теорий о том, почему он называется MapReduce. Во-первых, это игра слов, поскольку алгоритмы уменьшения карты включают разбиение проблемы на более мелкие части (отображение), затем решение этих частей и их обратное соединение (уменьшение). Другая теория состоит в том, что это ссылка на статью, написанную сотрудниками Google в 2004 году, под названием «MapReduce: упрощенная обработка данных в больших кластерах». В статье авторы используют термины «карта» и «уменьшение» для описания двух основных фаз предлагаемой ими модели обработки.
Однако важно отметить, что модель MapReduce используется ограниченно. Он не подходит для больших наборов данных и должен быть распараллелен для правильной работы. Когда дело доходит до решения этих проблем, у Apache Spark есть мощная альтернатива MapReduce. Кластерная вычислительная система Spark основана на Hadoop и работает как вычислительная платформа общего назначения. Этот инструмент можно использовать для ускорения традиционных задач анализа данных, таких как интеллектуальный анализ данных и машинное обучение, а также для более сложных задач обработки данных, таких как хранение данных и анализ больших данных. Это программное обеспечение создано с использованием Erlang, языка программирования, который является масштабируемым и отказоустойчивым. Он может обрабатывать большие объемы данных и может работать на нескольких машинах одновременно. Кроме того, Spark использует параллелизм, позволяя нескольким узлам выполнять одну и ту же задачу одновременно. В целом, он может автоматизировать крупномасштабные задачи анализа данных и сделать их более масштабируемыми. Если вам нужно распараллелить обработку и обрабатывать большие наборы данных, это отличная альтернатива MapReduce.
В чем разница между Mapreduce и агрегацией?
При работе с большими данными mapreduce является важным методом извлечения данных из большого объема данных. На данный момент MongoDB 2.2 включает новую структуру агрегации. С точки зрения функциональности агрегация похожа на mapreduce, но на бумаге она работает быстрее.
В этом сценарии агрегация MongoDB и MapReduce запускаются в контейнерах Docker в конфигурации Sharded. Производительность конвейера агрегатора выше, чем у mapreduce, поскольку он обеспечивает более быструю и простую навигацию. Вот как работает эта проблема: твит подсчитывает шведские местоимения, такие как «den», «denne», «denna», «det», «han», «hon» и «hen» (с учетом регистра) в хэштеге Twitter. Сколько дескрипторов Twitter у пользователя? Было отправлено более 4 миллионов твитов. В этом эксперименте мы сначала создадим базу данных MongoDB и включим сегментирование. Потоки Twitter были импортированы в базу данных, и были выполнены запросы с использованием MapReduce и Aggregation Pipeline.
Mapreduce: лучший инструмент для агрегации данных
Программа mapReduce считывает список документов из коллекции и обрабатывает их с помощью набора предопределенных функций. Операция mapReduce формирует поток готовых к обработке документов, которые будут обрабатываться на этапе редукции. Можно комбинировать mapsreduce и агрегацию в различных ситуациях. Оператор агрегации $group — это инструмент, который можно использовать для группировки документов в одном поле. Когда несколько документов объединяются с помощью оператора агрегации $merge, может быть создан новый документ. Оператор агрегации $accumulator можно использовать для представления результатов нескольких операций уменьшения карты в одном документе.
Mapreduce в MongoDB
MongoDB mapreduce — это технология обработки больших наборов данных. Это мощный инструмент для анализа данных, который позволяет обрабатывать и объединять данные параллельным и распределенным образом. MapReduce широко используется для анализа данных в различных областях, включая анализ веб-трафика, анализ журналов и анализ социальных сетей.

При использовании команды mapReduce вы можете выполнять операции агрегации map-reduce для коллекции. Функция карты может преобразовать любой документ в нулевой или во многие другие. В версиях MongoDB от 4.2 до более ранних каждый эмит может содержать только половину максимального размера документа BSON. Устаревший код JavaScript типа BSON, используемый в MapReduce, больше не поддерживается, и этот код больше нельзя использовать для своих функций. MongoDB 4.4 больше не включает устаревший код JavaScript типа BSON с областью действия (тип BSON 15). Параметр области действия указывает, к каким переменным разрешен доступ функции сокращения. Чтобы уменьшить количество входных данных, MongoDB ограничивает размер документа BSON половиной его максимального размера.
Большие документы, возвращенные на сервер, могут быть возвращены, а затем объединены в последующих сокращениях, что может нарушить требование. MongoDB 4.2 — самая последняя версия. Этот параметр можно использовать для создания новой сегментированной коллекции, а также для уменьшения карты для создания новой коллекции с тем же именем коллекции. Функция finalize получает в качестве аргументов значение ключа и уменьшенное значение от функции сокращения. Существует три варианта настройки параметра out. Этот параметр, помимо создания новой коллекции, не работает со вторичными элементами наборов реплик. Параметр NonAtomic: false может быть предоставлен только в том случае, если коллекция уже существует для передачи, имеет явную спецификацию.
Использование функции сокращения как для нового, так и для существующего документа приводит к тому, что ключ в новом документе совпадает с ключом в существующем документе. Сокращение карты не работает, если имя коллекции является существующей незакрепленной коллекцией, которая была настроена. В этом случае MongoDB не может заблокировать свою базу данных, если значение nonAtomic равно true. Только вторичные элементы наборов реплик, которые используют этот параметр, могут быть вне набора. Для перезаписи операции уменьшения карты не требуется никаких пользовательских функций. cust_id используется для вычисления поля значения группы $group stage методом cust_id. Этап $merge объединяет результаты этапа $merge в выходную коллекцию с использованием доступных операторов конвейера агрегации.
Например, этап $out можно использовать для записи вывода коллекции agg_alternative_1. Каждый входной документ может быть обработан с помощью функции карты. Каждый элемент в заказе связан с новым значением объекта, содержащим как число 1, так и количество элементов в заказе. В ReduceVal поле счетчика представляет собой сумму полей счетчика, сгенерированных элементами массива. Если функция finalize модифицирует объект ReducedVal, включив в него вычисляемое поле с именем avg, измененный объект возвращается пользователю. На этапе $unwind документ разбивается на отдельные документы для каждого элемента массива с использованием поля массива элементов. Этап $project изменяет форму выходного документа, чтобы отразить выходные данные mapreduce, включая два поля -id и value.
Он перезаписывает существующий документ, если нет существующего документа с тем же ключом, что и новый результат. Если указать параметр out, mapReduce возвращает выходной документ в следующем формате, если вы хотите записать результаты в коллекцию. Массив результирующих документов возвращается, если выходные данные записываются встроенными. Каждый документ содержит два поля: имя исходного документа и имя документа-получателя. Когда значение ключа вводится в поле -id, создается поле значения для сокращения или завершения значений для ключа.
Что такое Emit в MongoDB?
Как функция карты, функция карты может в любое время вызывать emits (key, value) для создания выходного документа, включающего ключ и значение. Один эмит в MongoDB 4.2 и более ранних версиях может содержать только половину максимального размера файлов BSON MongoDB. Начиная с версии 4.4 MongoDB ограничение снимается.
Почему MongoDB — лучший выбор для гибких и масштабируемых данных
Из-за отсутствия жесткой схемы MongoDB часто ассоциируется с NoSQL. Из-за отсутствия жесткой схемы данные могут храниться в любом удобном для приложения формате. Гибкость базы данных обеспечивает важное преимущество при ее увеличении или уменьшении, поскольку это означает, что данные могут храниться таким образом, который соответствует потребностям приложения.
Диаграмма данных с диаграммами ER может использоваться для визуализации взаимосвязей между различными частями данных. На ER-диаграмме изображен ряд узлов, представляющих набор данных, а связи между ними служат идентификатором.
Отношения не применяются в MongoDB, потому что это не реляционная база данных. Диаграмма ER отображает отношения, существующие в данных, а также помогает визуализировать их.
MongoDB — отличный выбор для гибких и масштабируемых данных. Его гибкость позволяет хранить данные удобным для приложения способом, а масштабируемость позволяет быстро и легко обрабатывать большие наборы данных.
Пример Map-reduce Mongodb
В MongoDB map-reduce — это парадигма обработки данных для агрегирования данных из коллекций. Это похоже на карту и функции сокращения в функциональном программировании.
Операции Map-Reduce состоят из двух фаз:
1. Фаза сопоставления применяет функцию сопоставления к каждому документу в коллекции. Функция сопоставления создает один или несколько объектов для каждого входного документа.
2. Фаза редукции применяет функцию редукции к документам, созданным на этапе сопоставления. Функция сокращения объединяет объекты и создает на выходе один объект.
Например, рассмотрим сборник статей. Мы можем использовать map-reduce для вычисления количества слов в каждой статье.
Во-первых, мы определяем функцию сопоставления, которая создает пару ключ-значение для каждого документа, где ключ — это идентификатор статьи, а значение — количество слов в статье.
Затем мы определяем функцию сокращения, которая суммирует значения для каждого ключа.
Наконец, мы выполняем операцию map-reduce для коллекции. Результатом является документ, содержащий агрегированные данные.
В монгоше есть база данных. Метод mapReduce() является оболочкой для команды mapReduce. В этом разделе представлено несколько примеров, таких как альтернатива конвейера агрегации без пользовательского выражения агрегации. Карты можно переводить с помощью пользовательских выражений, используя Map-Reduce to Aggregation Pipeline Examples Translation. Операцию уменьшения карты можно изменить без необходимости определять пользовательские функции с помощью доступных операторов конвейера агрегации. Функцию карты можно использовать для обработки каждого документа на входе. Каждый элемент имеет собственное значение объекта, связанное с новым значением, содержащим число 1, количество для заказа и список элементов.
Если ключ в текущем документе совпадает с ключом в новом документе, операция перезаписывает этот документ. Вы можете переписать операцию уменьшения карты, используя операторы конвейера агрегации, а не определяя пользовательские функции. Этап $unwind разбивает документ по полю массива элементов, в результате чего создается документ для каждого элемента массива. Когда этап $project изменяет форму выходного документа, вывод map-reduce зеркально отражается. Операция перезаписывает существующий документ с тем же ключом, что и новый результат.
Что такое функция Mapper в Hadoop?
В качестве редюсера вы должны объединить данные из картографов, чтобы получить единый ответ. Сокращение выходных данных производится, когда в качестве входных данных принимается набор выходных данных карты, каждый из которых представляет собой подмножество сгенерированного результата.
Картографы используются для разделения данных на управляемые фрагменты, а затем назначают каждый фрагмент задаче в зависимости от его размера. Входные данные получает функция отображения, где есть параметры, указывающие на выполнение задачи.
Ряд элементов соответствует фрагментам данных, которые были сопоставлены преобразователем в выходных данных. В результате выходные данные карты перенаправляются редюсеру, который преобразует их в выходные данные сокращения.
Ошибки также обрабатываются функцией сопоставления. В этом случае картограф вернет вывод ошибки, который не является выводом карты. Поскольку редюсер не может обработать эти данные, преобразователь вернет сообщение об ошибке.
Экосистема Hadoop
Экосистема Hadoop — это платформа для обработки и хранения больших данных. Он состоит из ряда компонентов, каждый из которых играет определенную роль в обработке и хранении данных. Важнейшими компонентами экосистемы являются распределенная файловая система Hadoop (HDFS), фреймворк MapReduce и общая библиотека Hadoop .