
База данных NoSQL: Импала
Опубликовано: 2023-03-03NoSQL — это термин, используемый для описания базы данных, которая не использует традиционную структуру реляционной базы данных. Вместо этого базы данных NoSQL часто разрабатываются как более простое и масштабируемое решение.
Impala — это база данных NoSQL, разработанная для обеспечения быстрого и масштабируемого решения для управления большими наборами данных. Impala основана на модели данных Google Bigtable и использует столбчатый формат хранения. Impala доступна как проект с открытым исходным кодом и поддерживается Cloudera.
Apache Impala — это механизм запросов SQL с открытым исходным кодом, который устанавливается в кластере Hadoop и выполняет массовую параллельную обработку (MPP) данных, хранящихся в системе. Первоначально разработанный в 2012 году, проект с открытым исходным кодом известен как Microsoft Formula 1.
Платформа Impala позволяет пользователям выполнять SQL-запросы с малой задержкой к данным Hadoop , хранящимся в HDFS и Apache HBase, без необходимости перемещать или преобразовывать данные.
Основана ли Impala на Sql?
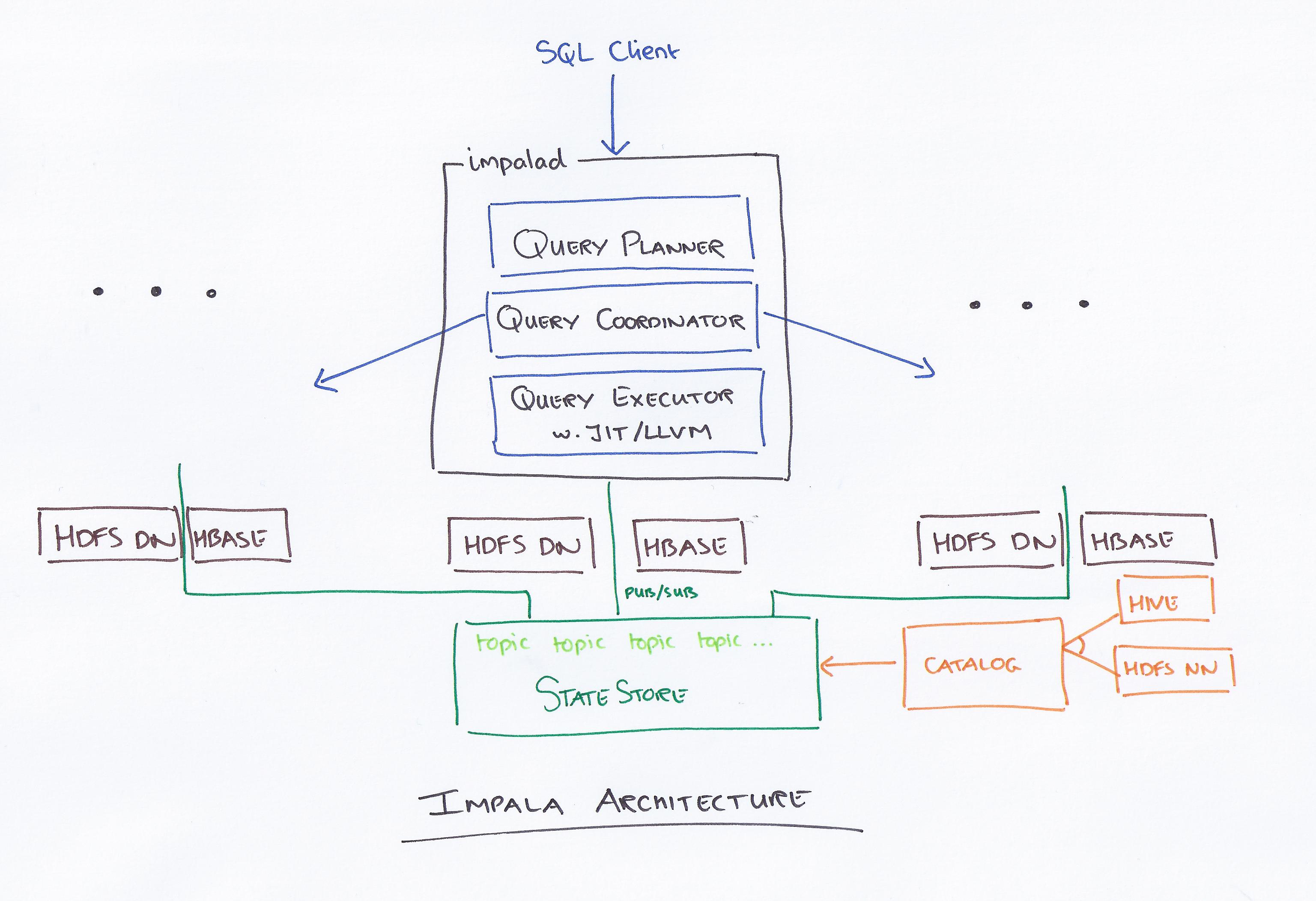
Impala — это механизм запросов на основе SQL, работающий на Apache Hadoop. Это позволяет пользователям запрашивать данные, хранящиеся в HDFS и HBase, с помощью SQL. Impala обеспечивает высокую производительность и низкую задержку по сравнению с другими механизмами запросов Hadoop, такими как Hive и Pig.
Аналитическая база данных MPP Impala обеспечивает самое быстрое получение информации в отрасли. Он интегрирован с CDH и доступен через Cloudera Enterprise. Базы данных MPP для Apache Hadoop, такие как Impala, используют HDFS для более быстрого получения информации.
Импала — это база данных
Я считаю, что это база данных.
Является ли Impala ETL-инструментом?
Impala — это не инструмент ETL, это механизм запросов SQL, который можно использовать для выполнения запросов SQL после очистки данных в процессе.
Для чего используется Apache Impala?
Используя SQL-подобные запросы, мы можем считывать данные из различных источников с помощью Impala. Apache Impala работает лучше, чем Hive и другие механизмы SQL, когда речь идет о доступе к данным, хранящимся в распределенной файловой системе Hadoop . Мы используем Impala для хранения данных в Hadoop HBase, HDFS и Amazon S3.
19 компаний, которые используют Apache Impala в своих технологических стеках
Apache Impala — популярный механизм обработки данных для различных крупных предприятий. Согласно сообщениям, 19 технологических компаний, включая Stripe, Agoda и Expedia.com, используют Apache Impala. Платформа Impala гибкая и эффективная, способная быстро и эффективно обрабатывать большие наборы данных. Широкое использование этого инструмента демонстрирует, насколько он полезен и полезен при обработке данных.
В чем разница между Sql Hive и Impala?
Цель Hive — обрабатывать длительные запросы, требующие множественных преобразований и объединений. Благодаря низкой задержке и способности обрабатывать небольшие запросы механизм обработки запросов Impala идеально подходит для интерактивных вычислений. Spark поддерживает как краткосрочные, так и долгосрочные запросы в дополнение к краткосрочным и долгосрочным запросам.
Hive лучше подходит для длительных пакетных заданий
Основная цель инструментов — не обработка пакетов. Hive лучше подходит для долгосрочной пакетной обработки, чем Impulsa, которая может обрабатывать небольшие наборы данных.
Является ли Impala базой данных
Импала — это база данных, которая хранит данные в столбцовом формате. Он предназначен для масштабирования и обеспечения высокой производительности для больших наборов данных.
В первоначальном выпуске Impala поддерживаются следующие основные типы данных столбца: STRING, VARCHAR, VARCHar2, INT и FLOAT, а не число, и тип BLOB не поддерживается. Impala SQL-92 включает некоторые усовершенствования стандартов SQL, но не все из них. Когда данные слишком велики для создания, обработки и анализа на одном сервере, Impala работает лучше, чем другие хранилища данных , и обладает большей масштабируемостью. Нет необходимости удалять исходное расположение файлов данных при загрузке Impala, потому что она легкая. Первым шагом в изучении тестирования производительности, масштабируемости и конфигураций кластера с несколькими узлами обычно является сбор большого количества данных. Cloudera Impala оптимизирована для загрузки и массового чтения больших наборов данных, что позволяет делать больше с меньшими затратами. Многомегабайтный размер блока HDFS позволяет Impala обрабатывать огромные объемы данных параллельно на нескольких сетевых серверах.
Вместо того, чтобы планировать нормализованные индексы и время и усилия, необходимые для их создания, вы сделаете это в Impala. Механизм запросов Impala может обрабатывать большие объемы данных, поступающих из хранилищ данных. Он анализирует кластер и распределяет задачи между узлами, чтобы уменьшить количество потребляемых ресурсов. Разделение хранилища данных — знакомая концепция в Impala. Разбиение на разделы сокращает дисковые операции ввода-вывода и повышает масштабируемость запросов в Impala. Файлы данных необходимы, так как вы не сможете получить доступ ни к каким встроенным таблицам в Impala. INSERT — одна из доступных опций.
Чтобы построить две игрушечные таблицы, используйте оператор value. Если вы использовали пакетно-ориентированное программное обеспечение, вы можете попробовать его. Вы можете включить технологию SQL-on-hadoop в свою конфигурацию Apache Hive. Таблицы Hive в Impala не загружаются и не конвертируются, что требует много времени.
Impala: мощный инструмент управления данными для Hadoop
Синтаксис SQL знаком пользователям Impala, который может запрашивать данные, хранящиеся в HDFS и Apache HBase. Таким образом, вместо традиционных реляционных баз данных можно использовать Hadoop и Impulsa. Кроме того, благодаря своим функциям это мощный инструмент управления данными. Кроме того, его возможности для больших наборов данных впечатляют, и он может с легкостью с ними работать.
Импала в больших данных
Impala — это механизм запросов MPP SQL с открытым исходным кодом, работающий на Apache Hadoop. Он обеспечивает быстрые интерактивные SQL-запросы к данным, хранящимся в HDFS и HBase. Impala предназначена для повышения производительности Apache Hadoop за счет предоставления быстрого интерактивного интерфейса SQL для данных, хранящихся в HDFS и HBase.

Impala во главе с Cloudera — это новая система запросов. У Hadoop есть HDFS и HBase, поэтому он может запрашивать хранящиеся там большие данные уровня PB. Эта технология основана на кусте и памяти для вычислений, а также с учетом хранилища данных и обеспечивает пакетную обработку в реальном времени и многократную параллельную обработку. Клиент отправляет запрос на узел в сети impalad, где идентификатор запроса возвращается для последующих клиентских операций. На первом этапе процесса создания анализатора генерируется автономный план выполнения (план для одной машины, план распределенного выполнения), а также будет выполняться SQL, например, изменение порядка соединения, включение предикатов и т. д. Все узлы хранят копию самой последней информации метаданных, чтобы гарантировать, что вы не остались в стороне. Прежде чем использовать Hadoop, Hive или Impurbia, необходимо сначала установить необходимое программное обеспечение для обработки данных.
Конфигурационный файл Impala можно изменить. Каждый узел выполняет изменение конфигурации в Impala. Все узлы отвечают за подключение пакета драйверов MySQL к базе данных. Узлы изменяют путь Java Bigtop.
Сравнение улья и импалы
Помимо этих трех основных, есть еще несколько незначительных отличий. В Hive есть подмножество HiveQL, тогда как в Implicit есть подмножество HiveQL. Hive и Impala используются для хранения данных и интерактивных запросов соответственно. Hive, в отличие от Impala, не предназначен для интерактивных вычислений.
Что такое Impala в Hadoop
Impala — это механизм запросов SQL с открытым исходным кодом для данных, хранящихся в кластере Hadoop. Он предназначен для предоставления быстрых интерактивных SQL-запросов к данным, хранящимся в HDFS, HBase или любом другом источнике данных Hadoop .
Impala использует широкий спектр знакомых компонентов Hadoop . INSERT может записывать только данные того типа, который может читать Impala, тогда как SELECT может читать данные того типа, который может читать Impala. При использовании файлов формата Avro, RCFile или SequenceFile данные загружаются в Hive. Статистику таблиц и статистику столбцов можно использовать в дополнение к статистике таблиц и столбцов. Все операторы DDL и DML автоматически обновляются с помощью демона каталогизации в Impala 1.2 и более поздних версиях, если они отправляются через демон каталогизации. Метод INVALIDATE METADATA возвращает метаданные для всех таблиц в хранилище метаданных, к которым был осуществлен доступ. Файлы данных хранятся в каталогах для новой таблицы и читаются независимо от имени файла при работе Impala.
В целом Apache Hive хорошо работает в качестве платформы для хранения данных, тогда как Impala лучше подходит для параллельной обработки. Hive отказоустойчив, а Impulsa — нет.
Апач Импала
Apache Impala — это быстрый интерактивный механизм запросов SQL для Apache Hadoop. Это позволяет пользователям выполнять SQL-запросы с малой задержкой к данным, хранящимся в HDFS и Apache HBase, без необходимости перемещения или преобразования данных.
Концепция архитектуры Impala позволяет обрабатывать интерактивные запросы с использованием HDFS более эффективно, чем любой другой механизм запросов. Hive намного медленнее из-за своих дисковых операций ввода-вывода, но Apache намного быстрее, потому что это совершенно другой движок. Между Impulsa и Presto нет различий, потому что Impulsa использует гораздо более быструю технологию, а Presto использует аналогичную архитектуру. Когда дело доходит до файлов Parquet, Impala работает лучше всего. Определите, какие данные вы должны секционировать, на основе запросов ваших аналитиков. Со статистикой Compute Stats ваши запросы будут намного проще, особенно если они включают более одной таблицы (объединения). У нас четыре раза в неделю случались сбои сервера каталогов Impala, и наши запросы выполнялись слишком долго.
Кроме того, количество файлов, которые мы создаем, сильно влияет на производительность наших запросов. В итоге мы стали управлять нашими разделами и объединять их в файл оптимального размера примерно 256Мб. Утверждается, что каждый раздел имеет только один файл (если его размер не превышает 256 МБ). Наиболее подходящий тип столбца следует выбирать из всех типов данных, поддерживаемых Implicit. Чтобы ограничить количество одновременных запросов или Y-памяти, доступной пользователю, используйте Impala Admission Control. Если запрос длится более 30 минут, он считается мертвым.
Лучший движок для больших данных: Impala
Механизм Impala — это механизм обработки данных Hadoop, специально разработанный для больших кластеров. Он потребляет гораздо меньше энергии и потребляет значительно меньше ресурсов, чем стандартный механизм MapReduce Hadoop. Implicit использует распределенную файловую систему HDFS в качестве основного носителя данных, полагаясь на избыточность HDFS для предотвращения сбоев оборудования или сети на уровне отдельных узлов. Файлы данных, представляющие табличные данные, физически представлены знакомыми форматами файлов HDFS и кодеками сжатия.
Механизм запросов с параллельной обработкой
Механизм запросов с параллельной обработкой — это тип механизма базы данных, предназначенный для параллельной обработки запросов. Это можно сделать, используя несколько процессоров, несколько ядер или несколько машин. Параллельная обработка может значительно повысить производительность механизма запросов, особенно для сложных запросов.
Многопроцессорный компьютер используется для преобразования сложных запросов в планы выполнения, которые могут выполняться одновременно, что позволяет обрабатывать большие объемы данных одновременно. Эффективное выполнение, такое как хорошее время ответа на запрос или высокая пропускная способность запроса, требуется для высокой производительности. Это достигается за счет использования эффективных методов параллельного выполнения и оптимизации запросов.
Параллельная обработка: будущее ETL?
Высокоуровневый запрос может быть преобразован в план выполнения, который может эффективно выполняться многопроцессорным компьютером с использованием параллельной обработки запросов. Параллельная обработка использует метод объединения параллельных и распределенных данных, а также различные методы выполнения, предоставляемые системой параллельных баз данных . Параллельная обработка запросов реализована в ETL путем деления набора записей в каждой исходной таблице, предназначенной для передачи, на порции одинакового размера, а затем выполнения процесса преобразования данных для каждой исходной таблицы в цикле, выборки данных последовательно, порция за порцией. .