
Факторы принятия решения о сегменте базы данных NoSQL
Опубликовано: 2023-02-13Когда выполнять сегментирование базы данных NoSQL, — это решение, которое должно приниматься на основе ряда факторов, включая, помимо прочего: размер данных и скорость роста, нагрузку и сложность запросов, требования к доступности и масштабируемости, а также модель данных. Единого ответа на все вопросы нет, решение нужно принимать в каждом конкретном случае. Тем не менее, есть некоторые общие рекомендации, которым можно следовать. Если набор данных небольшой, а нагрузка запросов не слишком велика, сегментирование может не понадобиться. В этом случае один экземпляр базы данных NoSQL, вероятно, сможет справиться с нагрузкой. По мере роста набора данных и увеличения нагрузки запросов может потребоваться сегментирование для поддержания хорошей производительности. Модель данных также может диктовать, когда выполнять сегментирование. Если данные структурированы таким образом, что их можно легко разделить на отдельные разделы, то хорошим вариантом может стать шардинг. С другой стороны, если модель данных сложная и взаимосвязанная, то шардинг может быть невозможен или может быть не лучшим вариантом. Наконец, необходимо учитывать требования доступности и масштабируемости. Если данные должны быть высокодоступными и всегда доступными, может потребоваться сегментирование, чтобы обеспечить избыточность и устранить единые точки отказа. Если масштабируемость является серьезной проблемой, сегментирование может помочь распределить нагрузку между несколькими серверами.
Когда я должен начать шардить?
Однозначного ответа на вопрос, когда начинать шардинг, нет. Решение зависит от ряда факторов, включая объем хранимых данных, скорость добавления данных, ожидаемый будущий рост набора данных, желаемый уровень производительности и доступные ресурсы. Как правило, сегментирование следует рассматривать, когда набор данных слишком велик или растет слишком быстро, чтобы эффективно управляться одним сервером базы данных.
Почему разделение вашего Mongodb необходимо для больших наборов данных
Когда мне следует начать сегментировать MongoDB? Когда одна база данных может обрабатывать или хранить большой объем растущих данных, перепродажа является отличным вариантом. Десятикратное увеличение емкости хранилища базы данных повышает производительность приложения. Это также усложняет вашу систему. Повышает ли шардинг производительность? Использование хеширования для повышения производительности базы данных было одним из первых методов. Продукт стал одним из лучших в результате последних технологических достижений. Несмотря на то, что данные являются наиболее ценным активом компании, в настоящее время базам данных уделяется все больше внимания. Почему шардинг лучше репликации? Если вы можете считывать данные, которые не являются самыми последними, репликация может оказаться полезной для горизонтального масштабирования чтений. В общем пуле данных данные распределяются между несколькими серверами с помощью общего ключа, что обеспечивает горизонтальное масштабирование. Выбор правильного ключа сегмента имеет решающее значение. Почему мы шардируем MongoDB? С помощью MongoDB развертывания с большим количеством наборов данных и операций с высокой пропускной способностью можно поддерживать с помощью сегментирования. Системой базы данных, которая содержит огромные объемы данных или имеет большое количество одновременных пользователей, может быть сложно управлять на одном сервере. Серверу может не хватить ресурсов ЦП при высокой частоте запросов. Зачем нужен шардинг? Нормализация относится к горизонтальному (построчному) разделу базы данных, тогда как эпохальный раздел относится к горизонтальному (построчному) разделу. Таким образом, сегменты данных делятся на более мелкие, более быстрые и простые в управлении части очень больших баз данных. является примером того, как можно создать распределенные системы. Какая база данных лучше всего подходит для сегментирования? Использование сегментирования, также известного как горизонтальное разбиение, в качестве метода масштабирования является распространенным подходом для баз данных. Amazon RDS — это облачная управляемая служба реляционной базы данных, которая включает множество функций, упрощающих выполнение сегментации в нескольких облаках.
Нужен ли шардинг в Nosql?
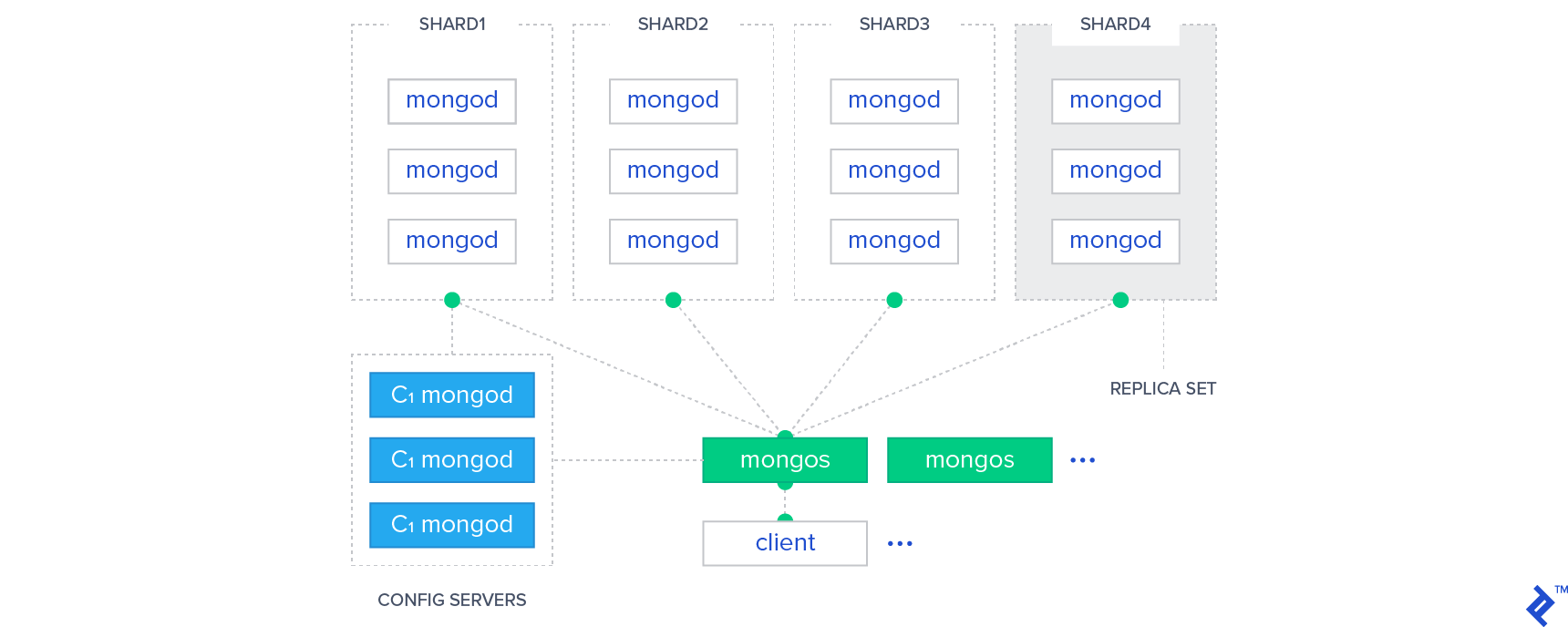
В NoSQL шаблон Sharding используется для разделения данных. Разделение — это метод размещения каждого раздела на потенциально отдельных серверах, разбросанных по всему миру. Масштабирование позволяет людям без проблем получать доступ к набору данных в различных точках по всему миру.
В базе данных MongoDB есть важный инструмент, известный как Sharding. Его можно использовать для повышения производительности за счет распределения больших наборов данных по нескольким серверам. Часть данных на сервере идентифицируется как часть данных на другом сервере с помощью ключа сегмента. В результате данные можно копировать между серверами без повторной индексации.
Является ли Sharding правильным решением для вашей базы данных?
В результате, если единственная база данных вашего приложения не может обрабатывать или хранить большой объем растущих данных, хранение их в экземпляре Sharding — отличный вариант. Наличие Sharding повышает производительность базы данных и масштабирует приложение. Однако в результате в вашей системе возникает некоторая дополнительная сложность. Если вы все еще не уверены, подходит ли вам сегментирование, имейте в виду, что MongoDB также может поддерживать горизонтальное масштабирование.
Когда вы должны шардить Mongodb?
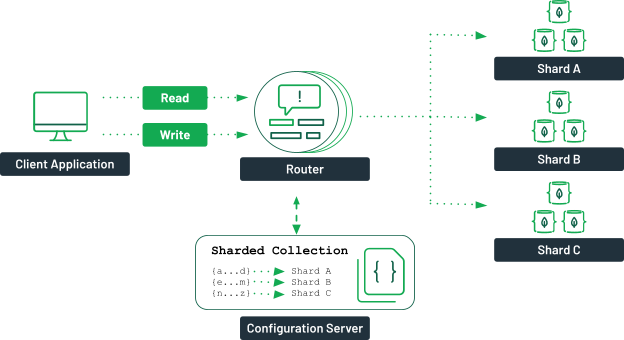
MongoDB следует сегментировать, когда размер данных превышает возможности одного сервера и когда требуется высокая производительность запросов.
Когда разделять базу данных Mongodb
Стоит ли вам рассмотреть возможность сегментирования вашей базы данных MongoDB? При принятии решения об использовании сегмента для базы данных MongoDB следует учитывать несколько факторов. Прежде всего, если ваше приложение MongoDB испытывает высокую частоту запросов, рекомендуется использовать сегментирование. Сравинг также может помочь расширить базу данных, если это необходимо. Прежде чем решить, использовать ли шардинг, вы должны рассмотреть его преимущества и затраты. Как вы шардируете MongoDB? Если вы планируете сегментировать свою базу данных MongoDB, мы рекомендуем использовать Amazon Relational Database Service (Amazon RDS). Функции Amazon RDS упрощают использование сегментирования в облаке, а также его можно масштабировать.
Зачем вам шардировать базу данных?
Что такое шардирование базы данных ? Образец набора данных может быть распределен по нескольким базам данных с использованием метода замены эпох, который затем сохраняется на нескольких машинах. Общая емкость системы хранения будет увеличена в результате разделения больших наборов данных на более мелкие фрагменты и их хранения на нескольких узлах данных.
Является ли шардинг решением ваших проблем с базой данных?
Зачем необходимо шардировать базу данных? Разделение — отличное решение, когда одна база данных в вашем приложении не может обрабатывать/хранить большой объем растущих данных. В целом, масштабируя базу данных, вы можете повысить производительность своего приложения. Кроме того, это усложняет вашу систему. Что такое шард в базе данных? Цель репликации базы данных — разбить большое количество наборов данных на разделы или осколки. Каждый узел может хранить свою собственную строку данных в каждом сегменте в виде уникальных строк, которые хранятся отдельно друг от друга. Исходная схема или структура базы данных является общей для всех сегментов, но узлы, на которых выполняются сегменты, немного отличаются. Можете ли вы использовать сервер sql для сегментирования? Используя фрагменты, можно более эффективно масштабировать большой набор данных и управлять им. Существует множество методов разделения набора данных на сегменты. Для шардинга можно использовать базу данных NoSQL или SQL. Можем ли мы разделить базу данных MySQL? В кластере ряды разделов (кластеров) автоматически выполняются на узлах, что позволяет горизонтально масштабировать базы данных на недорогом стандартном оборудовании для обработки рабочих нагрузок с интенсивным чтением и записью, а также API-интерфейсов SQL и NoSQL непосредственно с сервера. Возможен ли шардинг только для реляционной базы данных? Одним из наиболее популярных методов масштабирования реляционных баз данных является метод сегментирования горизонтального масштабирования. Amazon Relational Database Service (Amazon RDS) — это управляемая служба реляционной базы данных, которая упрощает сегментирование в облаке благодаря своим обширным функциям.

Зачем нам нужен шардинг в MongoDB?
Процесс распределения данных между несколькими машинами известен как хеширование. С MongoDB развертывания с большими наборами данных и высокоскоростными операциями могут выиграть от использования сегментирования. Систему базы данных с большим объемом данных или приложение, которое может обрабатывать большое количество запросов, может быть сложно запустить на одном сервере.
Нужен ли нам шардинг в Nosql?
Шардинг базы данных необходим для масштабирования баз данных SQL и NoSQL , которые одновременно являются базами данных SQL и NoSQL. Мы разбиваем базу данных на несколько частей (осколков), как следует из названия. У каждого сегмента есть свой индекс, который используется для определения того, какие данные он хранит.
Преимущества шардинга
Процесс распределения данных между несколькими серверами в кластере называется сегментированием. Можно повысить производительность базы данных, распределив работу, которую она должна выполнять, между несколькими серверами.
Служба MongoDB использует ключ сегмента для распространения документов из одной коллекции в другую. MongoDB делит данные на куски, которые делятся на непересекающиеся диапазоны в соответствии с диапазоном значений ключа. Серверная часть MongoDB пытается равномерно распределить эти фрагменты между кластерами.
Не существует единого способа использования Cassandra для шардинга. В Mongodb каждый вторичный узел хранит все данные основного узла, тогда как в Cassandra каждый вторичный узел хранит только несколько ключевых разделов. Если Cassandra сегментирована, она может достичь тех же уровней производительности, что и MongoDB, без необходимости во вторичном узле.
Зачем нам нужен шардинг в реляционных базах данных?
Благодаря наилучшему распределению данных и рабочей нагрузки в хорошо спроектированной архитектуре базы данных все сегменты базы данных могут быть распределены одинаково. Каждый раз, когда запрос проходит через другой набор сегментов, он соответствует ожидаемой производительности.
Какая БД лучше всего подходит для шардинга?
Разделение базы данных возможно в Cassandra, HBase, HDFS, MongoDB и Redis. MySQL, PostgreSQL, Memcached, Zookeeper и Sqlite — это лишь некоторые из баз данных, которые изначально не поддерживают сегментирование PostgreSQL и MySQL. Если база данных не поддерживает встроенную логику сегментирования , она должна храниться в приложении.
Шардинг в Nosql
Существует несколько различных подходов к сегментированию базы данных NoSQL. Наиболее распространенным является использование хеш-функции для определения того, на каком осколке следует хранить конкретный фрагмент данных. Это можно сделать либо на уровне приложения, либо на уровне базы данных. Другой подход заключается в использовании сегментации на основе диапазона, которая включает в себя хранение данных в разных сегментах на основе диапазона значений, в которые они попадают. Это часто используется для таких вещей, как данные временных рядов. Есть также несколько других менее распространенных подходов, но эти два являются наиболее распространенными.
Почему сегментирование является ключом к масштабированию базы данных Cassandra
При масштабировании базы данных nosql ключевым моментом является использование сегментирования. База данных разделена на несколько частей, известных как плиты, к которым затем можно получить доступ с нескольких компьютеров. Система может хранить большие наборы данных в меньших фрагментах и кластерах узлов, увеличивая общую емкость хранилища.
Sraving, в частности, может принимать форму сегментирования на основе ключей и автоматизировать распределение данных между узлами в Cassandra. Другими словами, Cassandra может обрабатывать большие наборы данных, не требуя дополнительного оборудования или программного обеспечения.
Для какой категории баз данных Nosql не рекомендуется разделять данные?
На этот вопрос нет однозначного ответа, поскольку он зависит от конкретных потребностей приложения. Однако обычно рекомендуется не разбивать данные в хранилищах ключей и значений или базах данных, ориентированных на документы.
Разделение Nosql против разделения
Разделение и сегментирование — это методы разбиения большого объема данных на более мелкие подмножества. Разделение отличается от сегментирования тем, что оно влечет за собой разделение данных на несколько компьютеров, а не их распределение между ними. Функция секционирования экземпляра базы данных используется для разделения подмножеств данных между ним.
Масштабирование вашей базы данных с помощью шардинга
Базы данных Nosql могут масштабироваться горизонтально, реплицируя схему и разделяя ее на сегменты. Разделение баз данных — это процесс репликации схемы с последующим разделением ее на различные части на основе идентификатора ключа на отдельном экземпляре сервера базы данных для распределения нагрузки. Каждая распределенная таблица содержит один ключ сегмента.
Большие наборы данных можно обрабатывать, загружая и сохраняя их в микросервисах. Существует множество способов разбить большой объем данных на мелкие части. Базы данных SQL и NoSQL можно использовать для объединения и удаления данных.
Базы данных SQL и NoSQL отличаются своей способностью управлять масштабом и неоднородностью данных, в то время как базы данных SQL выигрывают от возможности секционирования ядра базы данных. Shrsiting — это эффективный метод управления вашими данными, независимо от того, нужно ли вам увеличивать или уменьшать масштаб.
Каким образом распределенная база данных Nosql обычно разделяет данные?
Существует несколько различных способов разделения данных в распределенной базе данных NoSQL, но наиболее распространенным подходом является использование хэш-функции. Эта функция используется для определения того, на каком узле в базе данных должна храниться часть данных. Когда поступает новый фрагмент данных, хеш-функция используется для определения, на каком узле его следует сохранить. Если узел уже заполнен, данные отправляются на следующий узел в базе данных.
Осколок в базе данных
Что такое осколок в базе данных?
Осколок сервера базы данных — это подмножество данных, хранящихся на этом сервере. Набор данных, известный как осколок, состоит из равных частей. Поскольку большие наборы данных могут храниться на нескольких серверах меньшего размера, клиенты получают к ним более быстрый доступ.
Монгодб Шардинг
Шардинг MongoDB — это процесс распределения данных между несколькими машинами. Это способ масштабирования базы данных mongodb путем разделения данных на более мелкие части и распределения их по нескольким серверам. Это обеспечивает горизонтальное масштабирование базы данных, а это означает, что в систему можно добавить больше серверов по мере необходимости для обработки возросшего трафика.
Разделение вашей базы данных
Доступны различные типы сегментирования, в том числе ранжированные/динамические, алгоритмические/хэшированные, основанные на сущностях/связях и на основе географии. Разделение данных на диапазоны и назначение серверов каждому из них осуществляется с помощью динамического сегментирования . Сервер перемещается в разные регионы по мере добавления данных в массив, в зависимости от размера массива. Алгоритмическое/хешированное сегментирование делит данные на сегменты и назначает сервер для каждого сегмента. Если данные добавляются в корзину, им присваивается хеш-значение на сервере. Метод сегментирования на основе отношений разделяет данные на сущности и отношения между сущностями. Каждая сущность имеет список всех сущностей, с которыми она связана. Шардинг на основе географии делит данные на регионы, каждому региону назначается сервер, а затем данные разбиваются на регионы.
Стратегия разделения диапазона ключей
Стратегия секционирования диапазона ключей определяет, как данные в секционированной таблице распределяются по нескольким физическим секциям. Диапазон ключей основан на значениях столбца разделения, и каждому разделу назначается диапазон значений на основе ключей разделения. Эта стратегия часто используется для равномерного распределения данных по нескольким серверам или для обеспечения того, чтобы данные хранились в одном и том же физическом месте.
Разделение диапазонов: подход службы интеграции к распределению данных
Служба интеграции, которая распределяет строки данных на основе порта или набора портов, определенных как ключи секции, использует секционирование по диапазону для распределения строк данных. Диапазоны значений для каждого порта указаны в следующем формате. В результате служба интеграции использует ключ и диапазон для отправки строк в соответствующий раздел.
Служба интеграции распределяет строки данных на основе порта или набора портов, которые вы определяете как ключ секции, используя секционирование по диапазонам.
Когда вы загружаете новые данные и удаляете старые данные, это отличный способ сделать это. Это упрощает процесс разделения диапазона. Распространение данных, например, является обычной практикой, когда данные за предыдущие 36 месяцев хранятся в сети.