
Базы данных NoSQL: большая таблица
Опубликовано: 2023-01-04Базы данных NoSQL становятся все более популярными благодаря своей гибкости, масштабируемости и производительности. База данных NoSQL не требует предопределенной схемы и может хранить данные в любом формате. Это делает его идеальным для приложений, которым необходимо хранить большие объемы данных, которые постоянно меняются. Большая таблица — это тип базы данных NoSQL, предназначенный для хранения больших объемов данных. Большая таблица используется многими крупными организациями, такими как Google, Facebook и Amazon. Большая таблица хорошо масштабируется и может обрабатывать миллиарды строк и миллионы столбцов. Большая таблица также очень быстра и может обеспечить доступ к данным в режиме реального времени.
Компания Google выпустила серию общедоступных обновлений для своего сервиса баз данных Cloud Bigtable . В результате новых обновлений на каждый узел теперь доступно до пяти раз больше места для хранения. Google также добавил улучшенные возможности автоматического масштабирования, которые позволяют кластеру базы данных автоматически увеличиваться или уменьшаться в зависимости от его потребностей. Новая метрика использования ЦП и групповая маршрутизация кластера позволяют лучше понять, как используются ресурсы приложения. Из-за разделения вычислительных ресурсов и хранилища каждый тип ресурсов можно масштабировать отдельно в Bigtable. Благодаря новым возможностям пользователи теперь могут легко управлять развертываниями с высокой доступностью и улучшать управление рабочими нагрузками.
NoSQL — популярный выбор для хранения больших объемов данных. Сегодня этот тип базы данных становится все более популярным среди веб-компаний. Сторонники решений NoSQL говорят, что они предлагают более простую масштабируемость и повышенную производительность, чем традиционные базы данных.
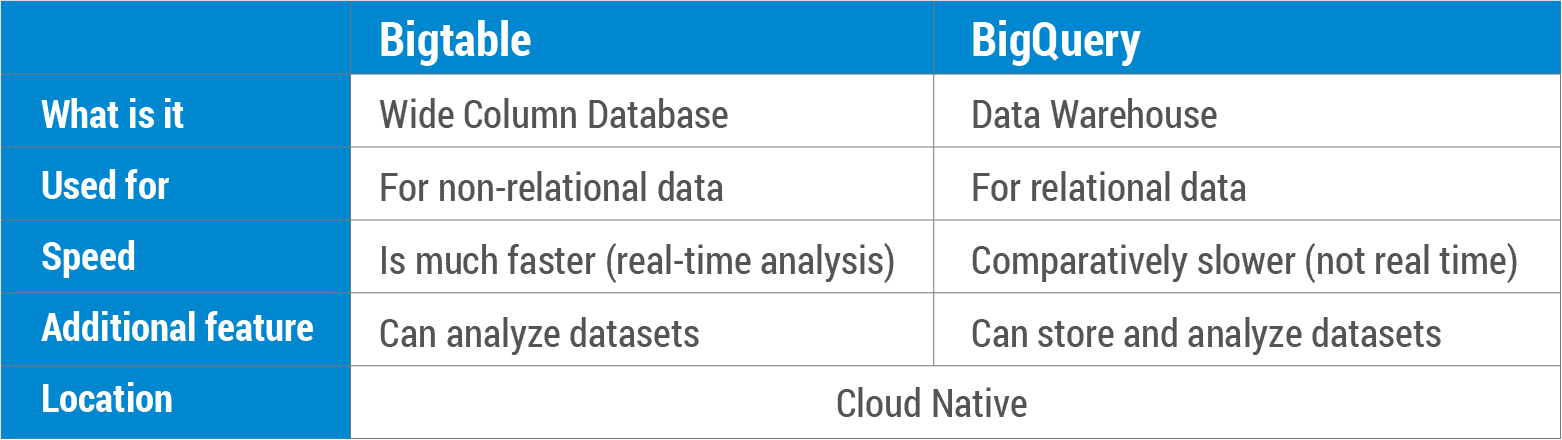
Bigtable — это тип службы базы данных NoSQL , которую могут использовать как разработчики, так и администраторы баз данных. BigQuery — это гибрид, поскольку он использует диалекты SQL и основан на технологии обработки данных Google, Dremel.
Bigtable Sql или Nosql?
На этот вопрос нет однозначного ответа, поскольку все зависит от того, как вы определяете каждый термин. Однако если мы возьмем широкое определение SQL как любой базы данных, которая использует язык структурированных запросов, а NoSQL как любую базу данных, которая не использует язык структурированных запросов, то Bigtable будет считаться базой данных NoSQL.
Что такое сравнение Bigtable и BigQuery? Bigtable — это база данных NoSQL, позволяющая хранить данные безопасным и масштабируемым образом. BigQuery — это реляционное хранилище данных, в котором огромные объемы данных хранятся в базе данных SQL. Bigtable была интегрирована в продукты Google, такие как Analytics, Finance, Personalized Search, Earth и Writely, для их повседневной работы. Bigtable, база данных NoSQL с изменяемыми данными , хорошо работает со сценариями OLTP. BigQuery — это реляционное хранилище данных SQL, которое можно использовать для приложений OLAP. И Bigtable, и BigQuery являются облачными решениями с лучшими в отрасли соглашениями об уровне обслуживания. Кроме того, они предлагают автоматическое резервное копирование (с репликацией), а также неограниченную масштабируемость, автоматическое сегментирование и автоматическое восстановление после сбоя (с репликацией).
BigQuery, а не база данных NoSQL, этого не делает.
Какой тип базы данных Nosql представляет собой Bigtable?
Cloud Bigtable — это база данных NoSQL, которую можно использовать для анализа данных и выполнения операций. Это альтернатива HBase, которая представляет собой систему баз данных со столбцами, использующую HDFS. Приложения с пропускной способностью менее 10 МБ подходят для Cloud Bigtable, который может поддерживать высокий уровень пропускной способности и масштабируемости.
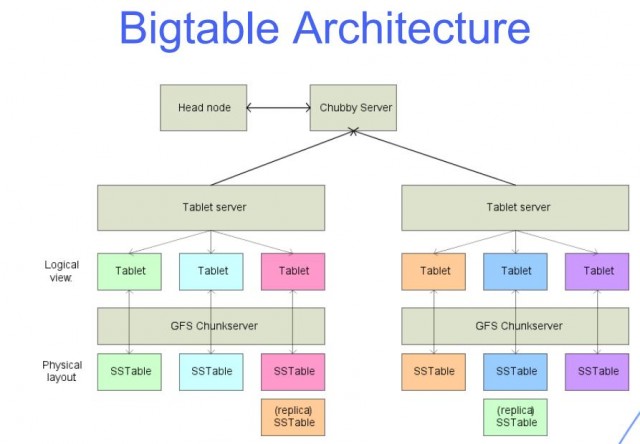
Базы данных Big Table, как их называют, являются подмножеством баз данных NoSQL. Приложение Bigtable от Google похоже на Kleenex. Базы данных Bigtable являются отраслевым стандартом для подражания и вдохновения. Хотя статья в первую очередь посвящена Bigtable, в ней также рассматриваются другие базы данных NoSQL. Bigtable был разработан в первую очередь для внутреннего использования Google, без доступа извне. Bigtable был представлен Google в 2004 году и с тех пор используется более чем в 60 приложениях Google. Для реализации Bigtable требуется один главный сервер для отслеживания планшетов в кластере других серверов.
Фонд Apache Software Foundation внес свой вклад в ряд превосходных технических инициатив, особенно в области баз данных. Accumulo и HBase используют те же принципы проектирования, что и Google Bigtable, но в формате, доступном на коммерческой основе. В настоящее время Apache HBase работает с системой обмена сообщениями Facebook и тесно интегрирован с Hadoop, что позволяет ему обрабатывать большие наборы данных. База данных Hypertable основана на Bigtable, простой табличной базе данных. Hypertable работает так же, как Hadoop и HFS. Baidu, одна из крупнейших поисковых систем Китая, является одним из основных спонсоров Hypertable. В число клиентов входят сайты онлайн-аукционов, такие как eBay, Groupon и Rediff.com, а также офлайновые розничные продавцы, такие как Lowe's и TJ Maxx.
Hadoop — это программная платформа с открытым исходным кодом, которая позволяет пользователям эффективно хранить и обрабатывать огромные объемы данных. Это позволяет использовать базы данных NoSQL, которые могут уменьшить объем данных, необходимых для хранения на отдельных серверах. База данных NoSQL, с другой стороны, не требует фиксированной схемы, поскольку она ориентирована на масштабируемость. Из-за этого они являются отличным выбором для хранения больших объемов данных распределенным образом.
К какому типу хранилища данных Nosql относится Bigtable?
Одна из немногих функций, доступных на рынке дженериков. На самом базовом уровне Bigtable представляет собой базу данных NoSQL, которая охватывает широкий диапазон столбцов.
Является ли Bigtable столбцовой базой данных?
Хранилища с широкими столбцами, такие как Bigtable и Apache Cassandra, не являются столбцами в традиционном смысле этого слова, потому что они вообще не используют столбчатые структуры данных на двух уровнях.
Является ли Bigtable нереляционной базой данных?
На этот вопрос нет однозначного ответа, поскольку он зависит от того, как вы определяете «нереляционную базу данных». Bigtable — это хранилище данных, ориентированное на столбцы, которое некоторые считают типом базы данных NoSQL. Однако он поддерживает транзакции и индексирование, которые обычно связаны с реляционными базами данных. Итак, это действительно зависит от того, как вы определяете нереляционную базу данных.
Оператор CREATE EXTERNAL TABLE можно использовать для создания таблицы в BigQuery, указав таблицу, из которой будут извлекаться данные. Параметр uri можно использовать для указания таблицы, из которой будут извлекаться данные. Схема таблицы включает имя таблицы, тип таблицы, имена столбцов и типы данных, а также схему таблицы опции bigtable_options.
Если вы используете MySQL, инструмент импорта BigQuery можно использовать для автоматического импорта данных из таблицы MySQL в BigQuery. Имя таблицы и семейство столбцов вводятся в инструмент, который импортирует данные в таблицу BigQuery.
При использовании консоли Google Cloud необходимо вручную ввести имя таблицы и уточняющие параметры семейства столбцов. На платформе Google Cloud возможен импорт данных из различных источников, включая MySQL, PostgreSQL, MongoDB и Redis.
Ключевые особенности Bigtable
Каковы некоторые особенности Bigtable?
Скорость чтения и записи Bigtable, масштабируемость и способность обрабатывать большие объемы данных — это лишь некоторые из его многочисленных особенностей. Кроме того, поскольку Bigtable является базой данных NoSQL, SQL-запросы не поддерживаются. Это устраняет необходимость выполнения операций SQL в отдельных базах данных.
Является ли Bigtable базой данных?
Bigtable не является реляционной базой данных. Это распределенная система хранения для управления структурированными данными, предназначенная для масштабирования до очень больших размеров: петабайт данных на тысячах обычных серверов. Google использует Bigtable для поддержки многих своих крупных сервисов, таких как Google Analytics и Google Maps.
Cloud BigTable предоставляет уникальный набор функций, позволяющий масштабировать его до более чем 100 000 столбцов и миллиардов строк. Он поддерживает хранение приблизительно петабайтов и терабайтов данных. По сравнению с BigTable у него очень низкая задержка, но он также может хранить большой объем данных. BigTable может хранить структурированные данные в столбцах, что позволяет обрабатывать веб-сервисы и данные поиска компании в Интернете. Алгоритмы сжатия также используются для увеличения пропускной способности системы. BigTable имеет эффективные внутренние серверы, которые предлагают лучшие возможности, чем самоуправляемая установка HBase, которая входит в состав BigTable. Строки в BigTable имеют общую границу, поэтому их также называют блоками.
Эти устройства, называемые «планшетами», помогают вам управлять рабочей нагрузкой запросов. Облачная файловая система Google Colossus используется для хранения всех планшетов. Все операции записи в BigTable хранятся в общем журнале Colossus, как и файлы SSTable. Семь ключевых возможностей BigTable имеют решающее значение для успеха бизнеса. BigTable может персонализировать, ускорить и автоматизировать вашу жизнь различными способами. строки и столбцы — это два измерения данных в BigTable. Каждая строка содержит уникальный идентификатор или индекс, к которым можно получить доступ с помощью ключа одной строки.
У каждого из столбцов в семействе есть уточняющий столбец. Использование единиц определения столбца, таких как ключи строки, помогает в идентификации столбца. Когда дело доходит до баз данных, BigTable известен как разреженный. Каждая из версий BigTable с метками времени представлена ячейкой, которая является одним из измерений в структуре трехмерной карты. Эта мощная база данных, которая может быть персонализирована и чувствительна к скорости, может использоваться для поддержки мобильных веб-сайтов и приложений. Если вы вспомните прошлое, то сможете выяснить, какие взаимодействия дали наилучшие результаты. Это поможет вам внедрить больше аналитики данных и улучшит обслуживание клиентов.
Google Cloud Bigtable, база данных NoSQL с открытым исходным кодом, интегрирована с Google Cloud. Тот факт, что он совместим со многими существующими экосистемами больших данных и Hadoop, означает, что его можно использовать для неструктурированных данных или данных, требующих малой задержки.
Bigtable: отличный выбор для приложений, интенсивно использующих данные
Bigtable, служба базы данных NoSQL, используется для больших аналитических и операционных рабочих нагрузок. В результате это отличный выбор для приложений, интенсивно использующих данные и работающих в реальном времени. Кроме того, поскольку он ориентирован на столбцы, он идеально подходит для хранения данных в трех измерениях.
Bigtable против Mongodb
Между Bigtable и MongoDB есть несколько ключевых различий. Во-первых, Bigtable — это база данных, ориентированная на столбцы, а MongoDB — база данных, ориентированная на документы. Это означает, что в Bigtable данные хранятся в столбцах, а в MongoDB — в документах. Во-вторых, Bigtable не поддерживает вторичные индексы, в отличие от MongoDB. Это означает, что если вы хотите запросить данные в Bigtable, вы должны знать конкретный столбец, который вы хотите запросить. В MongoDB вы можете запросить любое поле в документе. Наконец, Bigtable предназначен для горизонтального масштабирования, а MongoDB — для вертикального. Это означает, что в Bigtable вы можете добавить больше машин в свой кластер для увеличения емкости, а в MongoDB вы можете добавить больше ОЗУ и ЦП на свой сервер для увеличения емкости.
Google Cloud Bigtable: не только для больших данных
Bigtable по-прежнему является компонентом инфраструктуры Google, созданной в 2007 году. Хотя Cloud Bigtable идеально подходит для хранения больших объемов данных с малой задержкой, он не идеален для данных, к которым не требуется частый доступ. Cloud Bigtable, например, не подходит для озера данных.
База данных больших таблиц
База данных bigtable — это база данных, использующая структуру данных bigtable . Bigtable — это распределенная система хранения структурированных данных, предназначенная для масштабирования до очень больших размеров.
Большая таблица — это та, которая имеет много строк и столбцов и обычно мало заполнена. Bigtable идеально подходит для больших наборов данных благодаря низкой задержке и высокой плотности. Этот источник данных идеально подходит для операций MapReduce, поскольку он поддерживает высокую пропускную способность чтения-записи с малой задержкой и идеален для больших наборов данных. Данные таблицы Bigtable разбиваются на блоки смежных строк, каждая из которых называется планшетом, чтобы уменьшить нагрузку запросов. Формат SSTable используется для хранения планшетов Google в Colossus, файловой системе компании. Каждый планшет связан с определенным узлом в экземпляре Bigtable, также известным как узел. Добавление узлов в кластер может увеличить способность кластера обрабатывать несколько одновременных запросов.
Каждая строка содержит комбинацию семейства столбцов, идентификатор столбца и метку времени, по сути, массив записей ключей/значений. В подавляющем большинстве случаев Bigtable преобразует все данные в необработанные байтовые строки. Поскольку Bigtable хранит мутации последовательно и сжимает их только раз в несколько месяцев, мутации занимают больше места для хранения, когда они преобразуются в строку. Bigtable сжимает данные с помощью интеллектуального алгоритма и использует технологию сжатия. Поскольку делеции представляют собой особый тип мутаций, они требуют дополнительного места для хранения в краткосрочной перспективе. Собственные методы хранения Google позволяют ему выдерживать испытание временем для данных, выходящих за рамки стандартной трехсторонней репликации HDFS. Пользователи могут получить доступ к вашим таблицам Bigtable, используя роли, назначенные им вашим проектом Google Cloud и системой управления идентификацией и доступом (IAM). Большая часть данных Google Cloud шифруется в состоянии покоя с использованием тех же надежных систем управления ключами, которые мы используем для наших зашифрованных данных. Резервную копию можно использовать для сохранения копии схемы и данных таблицы, а также для последующего восстановления резервной копии в новой таблице.
Bigtable — это хорошо спроектированная распределенная система хранения, способная хранить до петабайт данных. Поскольку он прост в использовании, это отличный выбор для крупномасштабного хранения данных .

Сила облачных вычислений
База данных Cloud Bigtable способна хранить десятки тысяч строк и столбцов, и к ней можно получить доступ из любой точки мира. В результате он хорошо подходит для крупномасштабного хранения данных. Cloud Bigtable теперь доступен в Google Cloud с 6 мая 2015 года. С тех пор было обработано более 10 EXAbyte данных и обработано более 5 миллиардов запросов в секунду. В результате Cloud Bigtable все еще используется и является ценным инструментом для хранения данных.
Бигтабл против Кассандры
Каждый узел выбирается для операций чтения и записи с использованием собственного метода. В Cassandra идентифицируется ключ секции, тогда как в Bigtable используется ключ строки. Политика балансировки нагрузки Cassandra сначала проверяется клиентом.
Системы баз данных, такие как Bigtable и Cassandra, являются распределенными. Они создают многомерные хранилища ключей и значений, способные обрабатывать десятки тысяч запросов в секунду (QPS). Цель этого документа — объяснить различия и сходства между двумя системами баз данных. Bigtable содержит многие из основных функций, описанных в Bigtable. В статье описывается распределенная система хранения структурированных данных. Когда Bigtable идентифицирует назначение диапазона как необходимое для набора данных, диапазоны данных для узла обработки легко изменить, поскольку уровень хранения отделен от уровня обработки. Кроме того, Bigtable допускает асинхронную репликацию между географически распределенными кластерами в топологиях до четырех.
Отказоустойчивость обеспечивается Cassandra, что коррелирует с уровнем согласованности. Используя настраиваемую стратегию топологии репликации данных, вы можете задать географическую репликацию. В большинстве топологий с несколькими центрами обработки данных параметром по умолчанию является QUORUM (или LOCAL_QUORUM). Для того, чтобы настройка этого уровня считалась успешной, требуется, чтобы большинство узлов реплики отвечало узлу-координатору. Реплики данных в Cassandra можно улучшить с точки зрения отказоустойчивости, используя конфигурации центра обработки данных и стойки. Топология определяет, какие узлы необходимы для обеспечения согласованности во время операций чтения и записи. Экземпляр Bigtable может иметь один или несколько кластеров или набор из четырех реплицированных кластеров.
Bigtable и Cassandra функционируют как хранилища с широкими столбцами NoSQL. Ключ строки определяет порядок, в котором сортировка глобальных данных таблицы отображается в Bigtable. В Bigtable узлы используются для балансировки ответственности за ключевые диапазоны, которые обычно называют планшетами. Служба Bigtable не применяет типы данных столбцов, которые отправляет клиент. Семейство столбцов Bigtable выбирает, какие столбцы в таблице следует сохранять и извлекать из одного в другой. В каждой таблице должно быть хотя бы одно семейство столбцов, но в таблицах часто их больше (максимальное количество столбцов в таблице равно 100). Ключ строки находится в одной ячейке, а имя столбца — в другой.
Cassandra и Bigtable используют разные методы для выбора узла обработки как для операций чтения, так и для записи. В Cassandra различается ключ раздела, тогда как в Bigtable используется ключ строки. Создавая многокластерную политику, политика балансировки нагрузки, учитывающая центры обработки данных, обеспечивает преимущества аварийного переключения. Обе базы данных оптимизированы для быстрой записи и используют для этого схожий процесс. Обе базы данных хранят данные в файлах SSTable, которые являются неизменяемыми файлами. В Cassandra необходимо связаться с несколькими репликами, прежде чем координатор сообщит клиенту, что написание завершено. Поскольку каждый ключ строки в Bigtable назначается только одному узлу, для подтверждения успешной записи требуется ответ от этого узла.
В результате слияния SSTable обе базы данных могут исключать ячейки. При возврате данных в Cassandra предложение WHERE в запросе CQL ограничивает количество строк. При использовании Bigtable необходимо консультироваться только с узлом, отвечающим за диапазон ключей. Результаты чтения узла могут быть ограничены различными способами. На этапе сжатия Bigtable и Cassandra хранят данные в SSTables, которые регулярно объединяются. Bigtable не ограничивает количество версий меток времени для каждой ячейки, но другие размеры строк могут. Репликация, предоставляемая Colossus, гарантирует высокую надежность данных.
Интерфейс командной строки Bigtable, а также его клиентские библиотеки для различных распространенных языков программирования дополняют возможности Cassandra. Каждый узел Bigtable должен обслуживать серию SSTables, содержащих данные, хранящиеся в этих таблицах. Вам больше не нужно рассчитывать реплики хранилища в Bigtable, как в Cassandra, при определении размера кластера. Экземпляры Bigtable обычно хранят данные на твердотельных накопителях (SSD) или жестких дисках (HDD). В отличие от Cassandra, которая основана на теории отсутствия потери плотности хранения для достижения отказоустойчивости, рабочая нагрузка не теряет плотности. Экземпляр Bigtable легко масштабировать вверх или вниз по мере необходимости, чтобы соответствовать требованиям рабочей нагрузки, сохраняя при этом минимальные усилия и время простоя. Экземпляр может иметь только четыре кластера, но они могут быть сгруппированы в любом поддерживаемом облачном регионе на планете.
Чтобы создать метрику для QPS pernode, Google рекомендует использовать производительность Bigtable с репрезентативными данными и запросами. Bigtable включает управляемые компоненты для общих функций администрирования Cassandra. Таблица, являющаяся частью кластера, создается как восстанавливаемая копия таблицы в резервной копии большой таблицы. Цена резервной копии ниже, чем у облачного хранилища или не потребляет ресурсы узла. Другой вариант — использовать управляемый экспорт данных в облачное хранилище для резервного копирования Bigtable. Bigtable с легкостью справляется с общими внутренними задачами обслуживания Cassandra, такими как исправление ОС, восстановление узлов, ремонт узлов, мониторинг уплотнения хранилища и ротация SSL-сертификатов. Панели мониторинга предварительно созданы для отслеживания показателей пропускной способности и использования на уровне экземпляра, кластера и таблицы на странице консоли Bigtable Google Cloud. Вы можете использовать панель мониторинга для расширенной настройки производительности.
SQL используется в Bigtable, как и доступ к данным в базе данных NoSQL по ключу строки. Узлы распределяются по сети, и сплетни используются для поддержания согласованности сети. Благодаря этой системе емкость хранилища данных увеличивается, а доступность поддерживается без единой точки отказа.
С другой стороны, Bigtable более масштабируема и обеспечивает более высокий уровень доступности, чем Cassandra. Bigtable также более удобен для пользователя, чем другие языки программирования, что делает его отличным выбором для наборов данных с меньшим количеством ресурсов.
Google все еще использует Bigtable?
Google Analytics, веб-индексирование, MapReduce и многие другие приложения Google, такие как Google Maps, Google Books, My Search History, Google Earth, Blogger.com, хостинг Google Code, используют его для создания и изменения данных, хранящихся в Bigtable, Google Maps. , Google Книги, Мой поиск
Google использует Cassandra?
Топология DataStax Astra Cassandra as a Service была развернута в Google Cloud с использованием операционной системы TensorFlow, а также с использованием операционной системы Apache Cassandra в трех зонах Google Cloud.
Является ли Bigtable таким же, как Hbase?
Временная метка Bigtable хранится в микросекундах, тогда как временная метка HBase хранится в миллисекундах. Это различие может быть полезно при использовании клиентской библиотеки HBase для Bigtable и просмотре обратных временных меток.
Чем хорош Bigtable?
База данных Bigtable NoSQL — это база данных с широкими столбцами, которая идеально подходит для использования в базе данных NoSQL. Система оптимизирована для обеспечения низкой задержки, большого количества операций чтения и записи и высокой производительности при масштабировании. Использование табличных случаев обычно ограничивается определенным масштабом или пропускной способностью, которая требует высокой задержки, например Интернет вещей (IoT), AdTech, FinTech и т. д.
Bigtable против Bigquery
Между bigtable и bigquery есть несколько ключевых различий. Bigtable разработан как масштабируемая база данных, ориентированная на столбцы, а bigquery разработан как масштабируемая реляционная база данных. Bigtable не поддерживает SQL, в отличие от bigquery. Bigtable используется не так широко, как bigquery, но у него есть некоторые преимущества перед bigquery, например возможность масштабирования до большего количества столбцов и строк.
За последние годы Google добился значительного прогресса в облачном хранении больших объемов данных. Bigtable — это полностью управляемая служба базы данных NoSQL с петабайтным масштабом, основанная на объектно-ориентированном администрировании баз данных (OOPA). BigQuery построен с использованием Bigtable и Google Cloud Platform, а также системы баз данных Google Dremel. Между BigQuery и Bigtable есть три основных различия. Решение « Большие данные как услуга» (BaaS) — это решение, которое предоставляет Google Cloud BigQuery. BigQuery используется такими продуктами Google, как Analytics, Finance, Personalized Search, Earth, Orkut и Writely. При использовании молниеносной обработки данных BigQuery 35 миллиардов строк можно обработать за считанные секунды.
База данных NoSQL — это аббревиатура службы базы данных; другими словами, это не реляционная база данных. Столбцы ключей могут иметь несколько размеров, а полосы клавиш можно прокручивать по горизонтали. Отдельные элементы данных с большей емкостью хранения 10 мегабайт могут снизить производительность. Если вам нужно комплексное решение для хранения неструктурированных объектов (например, видеофайлов), облачное хранилище, вероятно, будет лучшим вариантом. Это отличный выбор для запросов, требующих сканирования таблицы, или для просмотра большой базы данных за один раз. В BigQuery загруженный объект не может измениться за время своего существования, а его данные всегда неизменяемы. Таблицы внутри большой таблицы хранят масштабируемые данные , которые были отсортированы в отсортированные карты ключей/значений по ключу, строке и отметке времени.
С помощью Integrate.io вы можете автоматизировать ETL и процесс интеграции данных, чтобы связать свои источники данных и облачные хранилища данных. Платформа интеграции включает в себя более 100 готовых интеграций, в том числе BigQuery, а также интерфейс перетаскивания, который делает управление процессами интеграции проще, чем когда-либо. Свяжитесь с нашей командой экспертов по данным, чтобы обсудить вашу ситуацию или начать 14-дневный пилотный запуск платформы Integrate.
Google BigQuery выходит на первое место по возможностям, несмотря на то, что MySQL по-прежнему широко используется. Это особенно верно для функций, которые обычно используются в бизнес-приложениях, таких как импорт и экспорт данных, анализ данных и объединение данных. MySQL, с другой стороны, имеет только 28 функций, а это означает, что он может не удовлетворить потребности многих предприятий. Google BigQuery основан на облаке, что позволяет получить к нему доступ из любого места, где есть подключение к Интернету. MySQL, с другой стороны, работает на архитектуре клиент-сервер и недоступен в облаке.
В чем разница между BigQuery и Bigtable?
Bigtable — это база данных NoSQL с широкими столбцами, оптимизированная для интенсивного чтения и записи. В отличие от BigQuery, который является корпоративным хранилищем данных для больших объемов реляционных данных, Oracle Data Warehouse служит службой дедупликации.
Построен ли BigQuery на Bigtable?
Bigtable, облачная служба запросов, разработанная в сотрудничестве с Google и Microsoft, и система Google Dremel для специальных запросов, соответственно.
Когда следует использовать Bigtable?
Bigtable идеально подходит для приложений, которым требуется высокая пропускная способность и масштабируемость при обработке данных типа "ключ-значение" с объемом данных не более 10 МБ на значение. Сильные стороны Bigtable заключаются в пакетных операциях MapReduce, потоковой обработке/аналитике и машинном обучении.
Масштабируемая служба базы данных Nosql
Масштабируемая служба базы данных nosql — это тип базы данных, который может обрабатывать крупномасштабные данные. Это веб-сервис, который можно использовать для хранения и управления большими объемами данных. Этот тип базы данных предназначен для масштабирования, чтобы он мог обрабатывать большие объемы данных.
В этом руководстве предполагается, что у вас есть рабочая среда Node.js. Я создал папку с именем nodejs-dynamodb-sample, в которую распаковал файлы DynamoDB. Страница проекта на GitHub https://www.gofundme.com/adamfowleruk/nodesurvey.html. Пример приложения использует DynamoDB для поиска и извлечения данных фильмов. Для хранения данных в S3 мы будем использовать сервис Amazon Identity and Access Management (IAM), а для доступа к DynamoDB на AWS — сервис Amazon DynamoDB. Чтобы использовать сервис Amazon iADM, вы должны сначала зарегистрироваться и создать пользователя. Название фильма и год можно добавить в раздел POST/movies вашего поиска.
Составьте список фильмов определенного года, введя поле ввода с ключа. Теперь вы можете создать собственное приложение, следуя этому базовому примеру. Если вы собираетесь использовать свои таблицы снова, вам следует удалить их после того, как вы закончите их использовать, что повлечет за собой расходы на хостинг и обслуживание AWS. В AWS перейдите в консоль DynamoDB и введите объем используемого хранилища. Вы можете просмотреть элементы в таблице, щелкнув «Фильмы», посмотреть показатели, которые вы видите в своем приложении, и просмотреть предполагаемые ежемесячные затраты, щелкнув вкладку «Емкость». На моей странице GitHub я включаю образец кода в этом упражнении: https://github.com/adamfowleruk/nodejs-dynamodb-sample.
База данных больших таблиц Google Cloud
Google Cloud Bigtable – это быстрая, полностью управляемая служба базы данных NoSQL объемом в петабайт, которая идеально подходит для больших аналитических и операционных рабочих нагрузок.
Хранилище данных Google лучше подходит для приложений, которым нужны быстрые ответы на запросы пользователей.
В базе данных Google Bigtable нет реляционной базы данных. SQL-запросы, объединения и многострочные транзакции не поддерживаются. В результате, если вам нужна стандартная поддержка базы данных, вы не можете этого ожидать. С другой стороны, Bigtable не предоставляет большого объема данных или аналитики. Оптимизированный характер Bigtable отчасти обусловлен его высокопроизводительными возможностями аналитики и обработки данных. Хранилище данных, с другой стороны, предназначено для предоставления приложениям ценных транзакционных данных. В результате хранилище данных лучше подходит для приложений, требующих быстрого реагирования на запросы пользователей.