
Базы данных NoSQL: сегментирование и репликация
Опубликовано: 2022-11-21Базы данных NoSQL часто используются для хранения больших объемов данных из-за их возможности горизонтального масштабирования. Это означает, что они могут масштабироваться, добавляя в систему больше узлов, а не обновляя аппаратное обеспечение одного узла. Один из способов достижения такой горизонтальной масштабируемости — сегментирование, то есть процесс распределения данных по нескольким узлам. Репликация — это еще один способ масштабирования баз данных NoSQL, который включает создание копий данных на нескольких узлах.
Как в базах данных SQL, так и в базах данных NoSQL концепция сегментирования базы данных имеет решающее значение для масштабирования. База данных разбита на несколько кусков (осколков), как следует из названия.
Вы также можете использовать репликацию данных NoSQL, чтобы гарантировать, что вы не потеряете данные при сбое сервера, беспрепятственно копируя и сохраняя ваши структурированные, неструктурированные и частично структурированные данные. Вы можете узнать больше о базах данных NoSQL, посетив эту страницу.
Реляционная база данных может быть разделена с использованием метода сегментирования, также известного как горизонтальное разделение. Amazon Relational Database Service ( Amazon RDS ) – это управляемая служба реляционной базы данных, которая упрощает использование в облаке, предоставляя различные функции.
Метод репликации копирует данные с нескольких серверов и помещает их в место, где их можно найти. При репликации создаются главные и подчиненные копии, при этом главные копии становятся авторитетными копиями, обрабатывающими записанные данные, а подчиненные копии становятся асинхронными копиями, обрабатывающими записанные данные.
Использует ли Nosql шардинг?
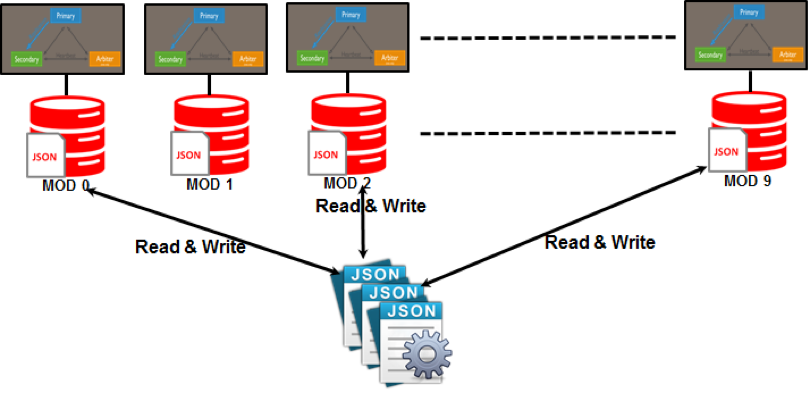
Шаблоны разделов, такие как совместное использование, используются в NoSQL. Разделение — это процесс, при котором каждый раздел назначается серверу, который, вероятно, будет независимым от остальной части сети. Благодаря этому масштабированию вы можете предоставить глобальным пользователям доступ к разнообразным наборам данных, сохраняя при этом максимально высокий уровень производительности.
MySQL Cluster — это решение. MySQL Cluster — это набор программного обеспечения, которое автоматически разбивает таблицы на узлы и позволяет базам данных горизонтально масштабироваться на недорогом серийном оборудовании для обслуживания рабочих нагрузок с интенсивным чтением и записью с использованием SQL, а также напрямую через API-интерфейсы NoSQL. MySQL Cluster может использоваться не только в блокчейнах. Его также можно использовать для масштабирования ваших приложений с помощью MySQL Cluster. Причина этого в том, что MySQL Cluster является системой планирования. В результате вы можете масштабировать свои приложения, решая, когда и как будут создаваться сегменты. Это большое преимущество, поскольку вам не нужно полагаться на облачные вычисления . Это связано с тем, что осколки создаются на узлах, где выполняется рабочая нагрузка. В результате вы можете контролировать, сколько параллелизма требуется. В результате MySQL Cluster обладает очень мощным набором функций. Его можно использовать для масштабирования ваших приложений и контроля необходимого уровня параллелизма.
Что такое шардинг и репликация в Nosql?
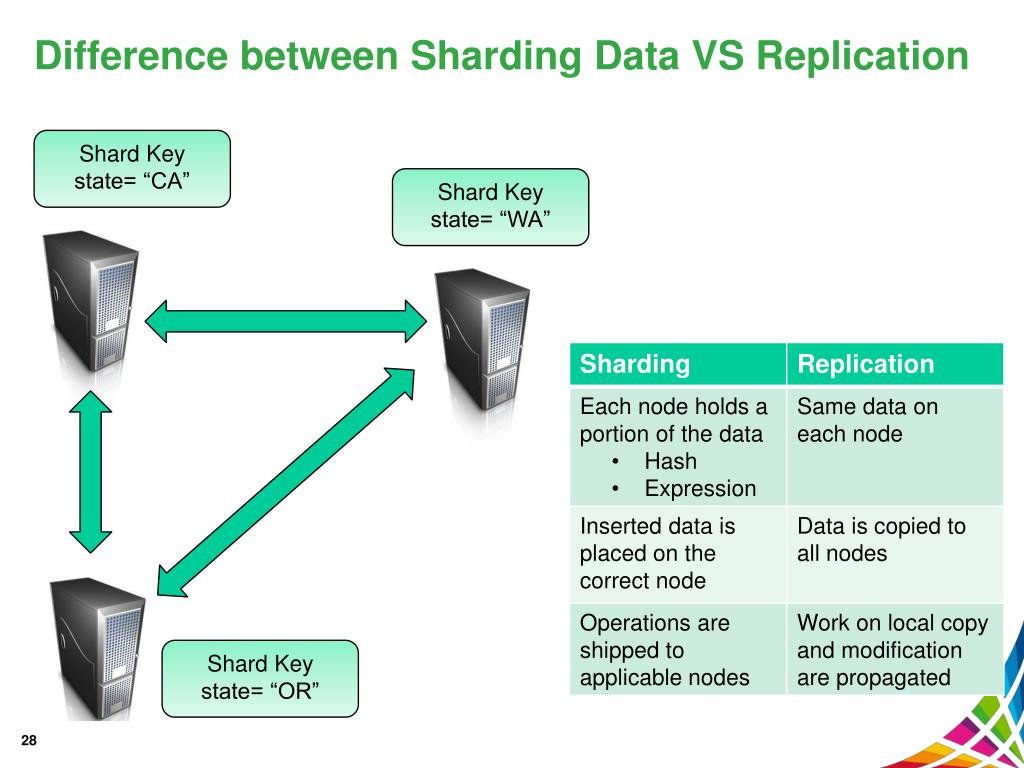
В чем разница между репликацией и шардингом? Репликация данных — это действие по передаче данных с узла первичного сервера на узлы вторичного сервера . В качестве резервной копии на случай сбоя основного сервера это может помочь обеспечить доступность данных. Эту функцию можно использовать для горизонтального масштабирования серверов с помощью ключа сегмента.
Преимущества шардинга
Когда вы имеете дело с данными, которые должны быть разделены, но не хватает ресурсов для их репликации, интервалы могут быть полезны в различных ситуациях. Когда вам нужно масштабировать чтение, репликация полезна, но запись данных может обрабатываться более эффективно с помощью сегментирования. Выбор неправильного ключа сегмента может негативно сказаться на производительности системы.
Использует ли MongoDB шардинг?
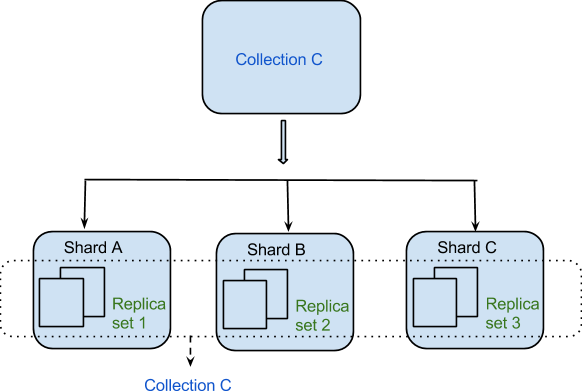
Данные распределяются между машинами распределенным образом благодаря шардингу. MongoDB использует сегментирование для поддержки крупномасштабных развертываний, требующих высокой пропускной способности. Может быть сложно построить один сервер для системы баз данных с большим количеством наборов данных или приложения с высокой пропускной способностью.
Наиболее распространенная стратегия решения проблем с дальним сегментированием — подходить к нему в самом общем смысле. Корневой узел кластера имеет заранее определенное количество сегментов, которые можно разделить в зависимости от их расстояния от центра обработки данных кластера. Первичный узел называется корневым узлом, поскольку он является первым узлом, создаваемым в наборе данных. Фрагмент другого типа называется вторичным фрагментом. Возможна ранжированная или хеширующая транзакция. Значение хеш-ключа конкретного сегмента определяет, сколько данных он может сгенерировать. Идентификатор создается с помощью хеш-ключа для каждой части данных в транзакции. Каждая стратегия имеет множество преимуществ и недостатков. Разделение диапазона проще реализовать, когда набор данных небольшой, а не большой, и более эффективно, когда он небольшой. Когда набор данных большой, хеширование более эффективно. Репутация MongoDB в плане скорости обусловлена тем, что она поддерживает делегирование данных другим службам MongoDB. Фрагменты набора данных могут быть распределены между несколькими серверами в MongoDB для повышения скорости обработки данных. MongoDB поддерживает несколько вариантов репликации в дополнение к сегментированию. В результате репликация позволяет распределять набор данных по нескольким серверам для обеспечения согласованности. Репликация данных необходима, если вы хотите, чтобы информация всегда была точной и актуальной. Кроме того, разрозненные кластеры в MongoDB могут быть полезны для повышения производительности. Sraving — это метод передачи больших объемов данных с одного сервера на другой таким же образом, как и репликация. Ключ сегмента — это элемент данных, который можно скопировать (или «осколки») с одного сервера на другой. Два основных метода распределения данных между сегментированными кластерами в MongoDB основаны на диапазоне и распределены. Хеширование может быть выполнено с использованием зашифрованного сервера. Разделяя вещи, вы можете достичь более чем одной цели.

Должны ли вы раздробить свой Mongodb?
Неизвестно, улучшает ли шардинг производительность в некоторых случаях, но было показано, что в некоторых случаях он повышает производительность. Кроме того, в результате сегментация создает собственный набор проблем, таких как обеспечение надежного резервного копирования и восстановления. Прежде чем принять решение о стратегии сегментирования , вы должны подумать о плюсах и минусах этого.
Шардинг в Nosql
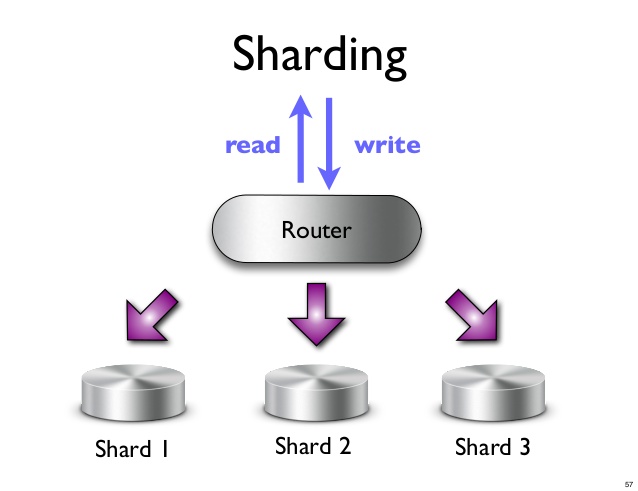
Шард — это горизонтальный раздел данных в базе данных или поисковой системе. Каждый сегмент представляет собой независимую базу данных или экземпляр поисковой системы. В базе данных NoSQL коллекция документов может быть разделена на сегменты, каждый из которых хранится на отдельном сервере.
Шардинг против репликации
Различие между репликацией и сегментированием заключается в том, что репликация — это дублирование данных, тогда как сегментирование — это разделение данных на отдельные фрагменты. В этом случае вы разделили свою коллекцию на несколько частей на основе сегментирования. Извлечение вашей базы данных дает изображения всех ваших наборов данных.
Преимущества шардинга
Данные распределяются между несколькими машинами, чтобы увеличить количество одновременных пользователей и повысить производительность. Данные хранятся в отдельных разделах на каждой из машин.
Репликация в Nosql
Существует несколько различных способов обработки репликации в базе данных NoSQL. Один из способов заключается в том, чтобы база данных автоматически реплицировала себя на вторичный сервер всякий раз, когда вносятся изменения. Это гарантирует, что всегда будет доступна резервная копия на случай, если основной сервер выйдет из строя. Другой способ — регулярно вручную реплицировать данные на вторичный сервер. Это дает администратору больше контроля над тем, когда происходит репликация, но это также означает, что в случае сбоя вторичный сервер не будет обновлен.
Что такое шардинг в базе данных
Шардинг — это процесс горизонтального разделения данных в базе данных. При сегментировании база данных делится на более мелкие части, называемые шардами. Каждый шард хранится на отдельном сервере. Процесс сегментирования помогает повысить производительность базы данных за счет распределения нагрузки между несколькими серверами.
Один фрагмент данных может быть реплицирован в одной транзакции с помощью сегментирования. В результате разделения набора данных на более мелкие части и распределения их по нескольким серверам общая емкость системы хранения может быть увеличена. В некоторых случаях это может быть полезно, если данные большие и для их поддержки требуется несколько серверов. Оболочки внешних данных также используются для чтения данных с удаленных серверов, что обеспечивает еще большую гибкость хранения данных.
В чем разница между секционированием и шардингом?
Разделение и сегментирование — это два подхода к структурированию больших коллекций данных на небольшие фрагменты. И сегментирование, и разделение означают, что данные распределяются между несколькими компьютерами, но они различны. Процедура разделения экземпляра базы данных влечет за собой группировку подмножеств данных внутри него.
Какая БД лучше всего подходит для шардинга?
Разделение базы данных поддерживается Cassandra, HBase, HDFS, MongoDB и Redis. Базы данных, которые изначально не поддерживают PostgreSQL, Memcached, Zookeeper, MySQL и Sqlite, считаются базами данных. Логика Jarryd должна присутствовать в приложении, если оно не имеет встроенной поддержки баз данных.
Возможен ли шардинг в Sql?
Однако можно реализовать сегментирование на основе диапазона (в основном горизонтальное) таким образом, чтобы сделать его более прозрачным для приложения. Типичный способ сделать это в SQL Server — через секционированное представление, но это не обязательно.