
Pig: платформа высокого уровня для Apache Hadoop
Опубликовано: 2023-02-22Pig — это высокоуровневая платформа для создания программ, работающих на Apache Hadoop. Термин «Свинья» относится к уровню инфраструктуры платформы, который состоит из компилятора и среды выполнения, а также набора высокоуровневых операторов. Уровень инфраструктуры Pig предоставляет разработчикам набор инструментов для создания, обслуживания и выполнения своих программ Pig. Pig — проект с открытым исходным кодом, входящий в экосистему Apache Hadoop . Модель программирования Pig основана на потоке данных, что упрощает написание программ, обрабатывающих большие объемы данных. Программы для свиней состоят из серии операторов, которые выполняются в ориентированном ациклическом графе. Pig — отличный выбор для обработки больших объемов данных, поскольку он масштабируемый, эффективный и простой в использовании.
В качестве решения NoSQL вам требуются определенные, предопределенные способы анализа и доступа к данным. SQL (UNION, INTERSECT и т. д.) — это распространенное выражение запроса, которое не очень часто используется в мире больших данных. Поскольку Hive оптимизирован для пакетной обработки и обработки больших данных, лучше коснуться каждой строки. Hive тратит на операции гораздо меньше времени и денег, чем Hadoop, преимущество которого заключается в масштабе. Даже небольшие запросы в системах разработки могут выполняться на ПОРЯДКИ медленнее, чем аналогичные запросы в СУБД. Hive не кэширует результаты запросов. Повторная отправка повторного запроса — обычная практика в MapReduce.
Существует два типа Hive: 1) Hive не является базой данных; скорее, это механизм запросов, который поддерживает части SQL, специфичные для данных запроса. b) Hive — это база данных с поддержкой SQL. c) Hive — это база данных, специфичная для SQL. Hive — это система хранения данных на основе SQL для Hadoop, включающая, среди прочего, Pig и Python; Hive используется для хранения данных Hadoop .
Является ли свинья Sql?
На этот вопрос нет правильного или неправильного ответа, так как он зависит от личного мнения. Кто-то может поверить, что свинья — это sql, а кто-то нет. В конечном счете, каждый сам решает, является ли pig sql или нет.
Сегодня Apache Hive и Pig — это два термина, которые быстро становятся синонимами больших данных. С помощью этих инструментов разработчики данных и аналитики могут использовать их для уменьшения сложности MapReduce, сохраняя при этом высокий уровень целостности данных. Hive — это инфраструктура хранилища данных, также известная как инструмент ETL (извлечение, загрузка и преобразование). Apache Hive, Pig и SQL — три популярных инструмента для анализа данных и управления ими. Вы должны знать, какая платформа будет лучше всего соответствовать вашим потребностям и как часто вы должны ее использовать. Давайте рассмотрим три различных способа использования Hive, Pig и SQL в контексте этих трех технологий. SQL по-прежнему лидирует в управлении большими данными и их анализе, несмотря на доминирование Apache Hive и Apache Pig. Поскольку каждый выполняет определенную функцию, их требования адаптированы к бизнесу. Apache Pig основан на сценариях и требует специальных знаний, в то время как Apache Hive — единственное решение для баз данных, родное для разработчика.
Свинья — универсальное животное с большой гибкостью. Pig, например, может обрабатывать файлы журналов, содержащие данные JSON или XML, что позволяет вам читать данные. Также возможно хранить данные из веб-сервисов в Pig.
Типы данных карты, кортежи и типы данных пакетов могут использоваться взаимозаменяемо. Они способны обрабатывать данные из любого источника.

Является ли Pig инструментом ETL?
На этот вопрос нет однозначного ответа, поскольку он зависит от того, как вы определяете инструмент ETL. Вообще говоря, инструмент ETL — это программное приложение, которое помогает вам извлекать данные из одного или нескольких источников, преобразовывать их в формат, совместимый с вашей целевой системой, и загружать их в эту систему. Некоторые люди сказали бы, что pig — это инструмент ETL, потому что он может выполнять все эти функции. Другие могут возразить, что pig не является инструментом ETL, потому что он специально не предназначен для преобразования данных. В конечном счете, ответ на этот вопрос зависит от вашего собственного определения инструмента ETL.
Как вы можете использовать Pig для обработки ETL?
Приложение Pig можно описать как модель транзакций ETL, которая описывает, как процесс извлекает данные из объекта и преобразует их в хранилище данных на основе набора правил. Пользователи определяют пользовательские функции (UDF) Pig, чтобы получать данные из файлов, потоков и других источников.
Что такое инструмент для свиней?
Платформа или инструмент, известный как Pig, обрабатывает большие наборы данных. Эта библиотека содержит высокий уровень абстракции для обработки данных в процессе MapReduce. Pig Latin — это язык сценариев высокого уровня, который используется в процессе кодирования для разработки кодов анализа данных.
В чем разница между Pig и Sql?
SQL Pig Latin и Apache Pig — это процедурные языки. SQL — это язык сценариев, который носит декларативный характер. Использование схемы полностью зависит от Apache Pig. Данные можно хранить без схемы (типы значений хранятся в $, $ и т. д.).
Является ли свинья частью Hadoop?
Приложение Pig Hadoop — это язык программирования высокого уровня, который можно использовать для анализа массивных наборов данных. Проект Yahoo! Pig Hadoop был одним из первых проектов Hadoop . В целом, он выполняет значительный объем работы по администрированию данных при работе с Hadoop.
В области анализа больших данных Pig Hadoop представляет собой язык программирования высокого уровня. Чтобы анализировать данные с помощью Apache Pig, мы должны сначала написать скрипты с использованием Pig Latin. скрипты, которые будут преобразованы в задачи MapReduce . Это достигается за счет использования Pig Engine, расширения Apache Pig. Следуя приведенным ниже инструкциям, вы можете установить Apache Pig в Linux/CentOS/Windows (через виртуальную машину или Cloudera). Первый шаг — загрузить и установить Apache Pig. Второй шаг — изменить переменные среды Apache Pig с помощью файла bashrc.
На шаге 3 определите версию Pig . Этот файл можно сохранить в другом каталоге после перемещения. Пятый шаг — запустить Grunt Shell (сценарий, используемый для запуска Pig Latin), щелкнув команду Pig.
Почему Pig Latin — лучший язык сценариев высокого уровня для анализа данных
Код анализа данных Pig Latin написан на языке сценариев высокого уровня. Это SQL-подобный язык, предназначенный для параллельной обработки потоков данных.
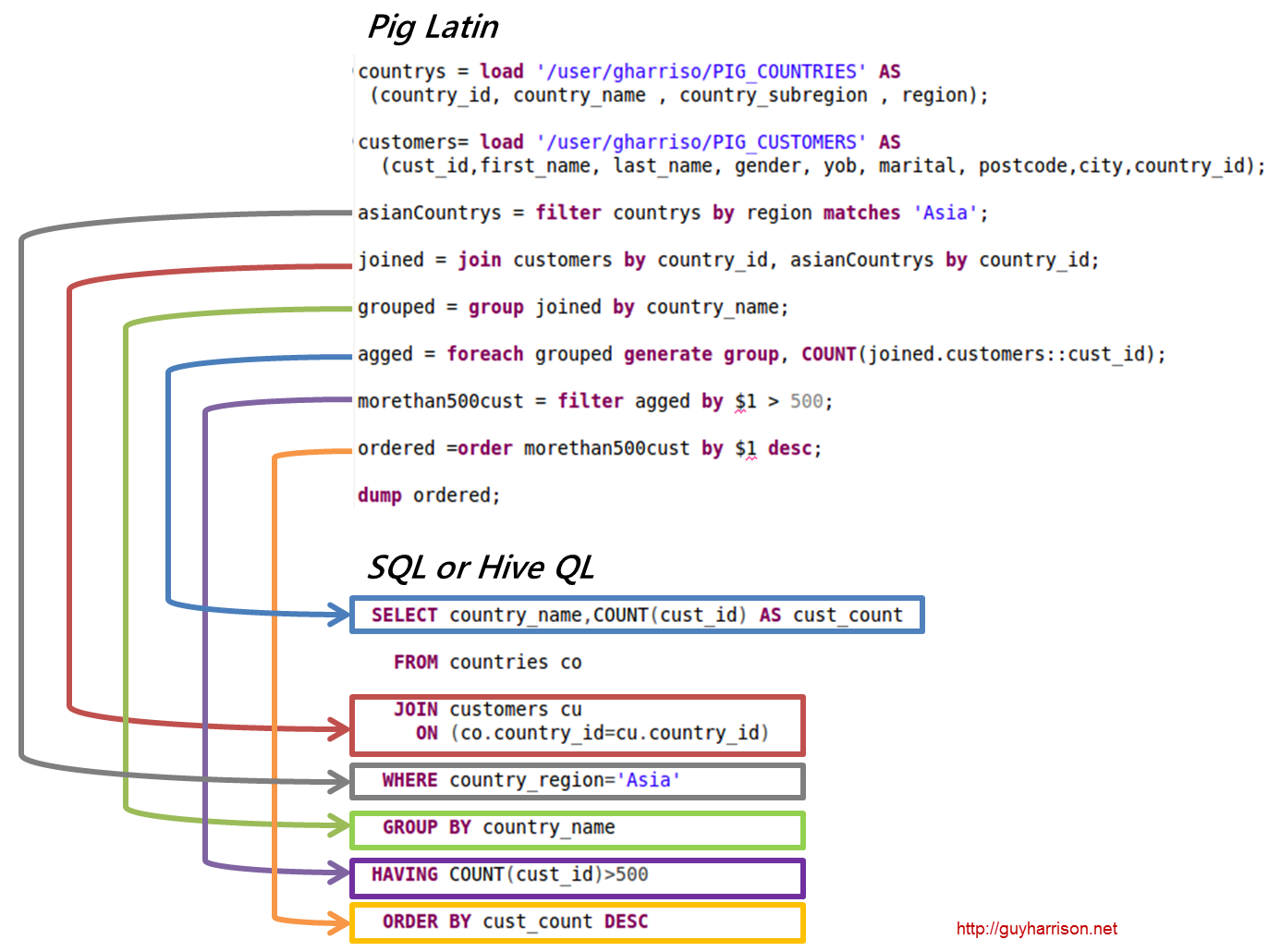
Пример свиньи Apache
Pig — это высокоуровневая платформа для создания программ, работающих на Apache Hadoop. Язык для этой платформы называется Pig Latin. Pig может выполнять свои задания Hadoop в MapReduce, Tez или Spark. Pig Latin абстрагирует программирование от идиомы Java MapReduce в нотацию, которая упрощает программирование MapReduce. Например, следующий оператор Pig Latin эквивалентен приведенному выше коду Java MapReduce: A = LOAD 'mydata' USING PigStorage(',') AS (id:int, name:chararray, age:int, gpa:float); ДАМП А;