
Масштабирование базы данных NoSQL: советы и рекомендации
Опубликовано: 2022-11-18Базы данных NoSQL становятся все более популярными, поскольку объем данных, генерируемых компаниями, продолжает расти в геометрической прогрессии. Однако многие организации не хотят переходить на NoSQL, опасаясь, что его будет сложнее масштабировать. Масштабирование базы данных NoSQL на самом деле ничем не отличается от масштабирования реляционной базы данных. Основное отличие заключается в том, что базы данных NoSQL предназначены для горизонтального масштабирования, что означает, что их можно масштабировать, добавляя в систему дополнительные узлы. Это отличается от реляционных баз данных , которые масштабируются по вертикали, а это означает, что они могут масштабироваться только за счет добавления дополнительных ресурсов на один сервер. При масштабировании базы данных NoSQL следует помнить о нескольких вещах: 1. Убедитесь, что ваши данные равномерно распределены по всем узлам. 2. Добавляйте узлы постепенно, чтобы не перегружать систему. 3. Внимательно следите за производительностью системы, чтобы выявить узкие места. 4. Регулярно настраивайте систему, чтобы обеспечить оптимальную производительность. С учетом этих советов масштабирование базы данных NoSQL не должно быть более сложным, чем масштабирование реляционной базы данных.
Существует множество методов и принципов масштабирования базы данных в зависимости от ее типа. Масштабирование баз данных NoSQL и sql зависит от концепции сегментирования базы данных. Преимущества возможности хранить больше данных возрастают, когда серверы распределены, но мы также наследуем проблемы, возникающие при распределении. Автоматическое сегментирование не поддерживается монолитной базой данных, и инженерам пришлось бы вручную писать логику для его обработки. Чтобы решить эту проблему, перед службой запросов и базой данных можно установить прокси, например балансировщик нагрузки. Мы можем получать более быстрые запросы, когда сегмент большой, потому что этот прокси снова можно использовать. Из-за того, что конечные пользователи не знают об этом, масштабирование баз данных NoSQL практически незаметно.
Каждый шард уникален, в отличие от архитектуры master-slave. Если на главном сегменте есть какие-либо запросы на чтение, запрос будет отправлен на подчиненные сегменты. На уровне центра обработки данных мы можем реплицировать базу данных, чтобы убедиться, что у нас есть резервная копия. Узел — это узел, который может общаться и обмениваться информацией с другими узлами. Каждый узел связывается с фиксированным числом других узлов через протокол. Поскольку все узлы в Cassandra равны, узел может реплицировать свои данные с одного узла на другой, не беспокоясь о потере каких-либо данных. Протокол сплетен — один из многих способов обмена информацией между узлами.
Распределенная база данных может иметь ряд преимуществ помимо получения дополнительных свойств. Важнейшим компонентом обеспечения доступности является репликация данных. Когда вы используете асинхронную репликацию для своей базы данных, поначалу она не всегда будет полностью согласованной, но со временем она станет более согласованной. Базы данных SQL используются в финансовых приложениях, требующих высокой точности данных, тогда как базы данных NoSQL используются в менее важных приложениях, таких как подсчет просмотров.
Вертикальное масштабирование относится к процессу постепенного увеличения вычислительной нагрузки с использованием обновлений оборудования. Переход к распределенной архитектуре и добавление дополнительных компьютеров для решения нашей проблемы влечет за собой масштабирование, также известное как горизонтальное масштабирование или горизонтальное масштабирование.
NoSQL может поддерживать масштабирование на основе горизонтальных методов.
MongoDB как база данных NoSQL является масштабируемой, поскольку ее данные не хранятся в реляционных базах данных. Данные хранятся в виде документов в формате JSON, к которым легко получить доступ через HTTP-запрос. Распределение документов может выполняться горизонтально по нескольким узлам с помощью этого метода.
Как вы масштабируете базу данных Nosql?
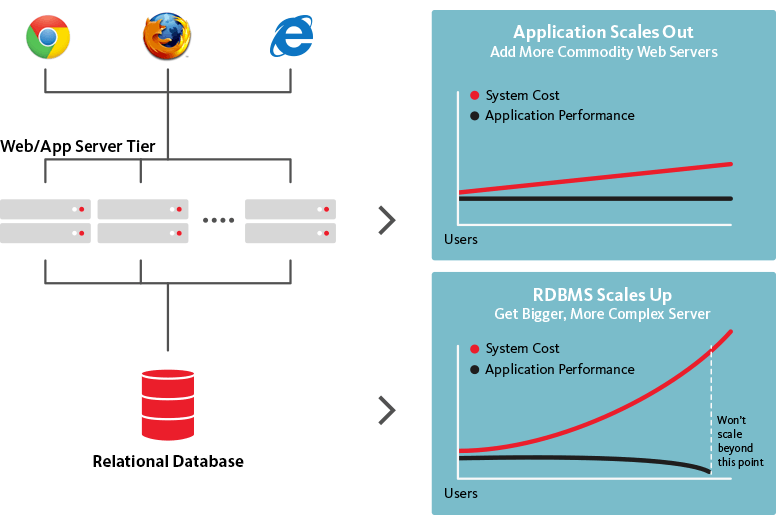
Базы данных NoSQL, с другой стороны, являются горизонтально масштабируемыми, что означает, что они могут обрабатывать увеличивающийся трафик по мере необходимости, просто добавляя больше серверов в базу данных. Поскольку базы данных NoSQL могут быть преобразованы в гораздо более крупные и мощные структуры, это логичный выбор для больших наборов данных и постоянно развивающихся баз данных.
Чтобы этот учебник работал, у вас должна быть работающая среда Node.js. В этом посте я распакую файлы DynamoDB в папку с именем nodejs-dynamodb-sample. Для получения подробной версии перейдите на мою страницу GitHub: https://www.gofundme.com/adamfowleruk/nodesurvey.html. Пример приложения может искать и извлекать информацию о фильмах из DynamoDB. Мы будем хранить данные в S3 на Amazon Web Services и получать доступ к DynamoDB через службу Amazon Identity and Access Management (IAM). Чтобы использовать службу Amazon In-App Analytics, вы должны сначала зарегистрироваться и создать учетную запись. Запишите год и название каждого фильма, который вы хотите опубликовать / фильмы.
Вы можете ввести ключевое поле, чтобы найти фильмы определенного года. После этого вы можете разработать собственное приложение с нуля. Вы можете использовать свои таблицы, пока не закончите их, но вы должны удалить их, как только они будут использованы. Посетите консоль DynamoDB в Amazon Web Services, чтобы узнать, какой объем хранилища вы уже использовали. Вкладка «Фильмы» позволяет просматривать элементы в таблице и показатели из вашего приложения, а также расчетную ежемесячную стоимость в месяц на вкладке «Емкость». Этот код можно найти на моей странице GitHub: https://github.com/adamfowleruk/nodejs-dynamodb-sample.
MongoDB, Apache HBase и Cassandra — это три базы данных NoSQL, которые идеально подходят для горизонтального масштабирования. Поскольку их структуры данных более горизонтальны, это упрощает добавление дополнительных серверов в систему, а также устраняет необходимость их изменения. Кроме того, эти базы данных являются относительно новыми, поэтому они все еще разрабатываются и совершенствуются, а это означает, что со временем они, вероятно, улучшатся.
Почему Nosql легко масштабировать?
Nosql легко масштабировать, потому что он предназначен для горизонтального масштабирования. Это означает, что его можно масштабировать, добавляя дополнительные узлы в кластер nosql . Nosql также легко масштабировать, поскольку он может обрабатывать большие объемы данных и большое количество запросов в секунду.
Для правильной работы приложений требуется высокий уровень масштабируемости. Не менее важно выбирать хранилища данных с простым и эффективным пользовательским интерфейсом. Главный предмет разногласий заключается в том, что лучше использовать базу данных «ASL» или «Nosql». Базы данных NoSQL, в отличие от баз данных SQL, популярны, потому что их просто создавать. Остановка всех операций в базе данных NoSQL по своей сути зависит от сегментирования. В общем, каждая операция с данными требует использования уточняющего оператора, который можно использовать для идентификации узла с данными. Данные хранятся на нескольких машинах, что упрощает выполнение операций с данными даже на самых маленьких машинах.

В результате хранилища NoSQL могут масштабироваться для использования относительно простой стандартной машины. Предполагается, что пользователи будут планировать и структурировать данные таким образом, чтобы их можно было получить за один раз с одного и того же узла для выполнения определенной операции в базе данных NoSQL. Денормализация данных таким образом может также означать, что узел готов к запуску предварительно подготовленных данных. Соединения в NoSQL возможны, но они не так надежны, как соединения SQL. В практическом мире NoSQL разработчики приложений считают, что в конечном итоге будет достигнута согласованность данных. В дополнение к переключателям для настройки согласованности между различными системами NoSQL многие системы NoSQL предоставляют подпрограммы, которые делают согласованность более заметной. Важной частью любого архитектурного решения является оценка варианта использования и выбор подходящего хранилища данных на основе этого варианта.
Все ли базы данных Nosql масштабируемы?
В результате эпохи Интернета и облачных вычислений были созданы базы данных NoSQL, чтобы упростить реализацию масштабируемой архитектуры. Масштабируемость достигается за счет объединения хранения данных с работой, необходимой для их обработки на большом количестве компьютеров в масштабируемой архитектуре.
Система должна быть в состоянии обрабатывать чрезвычайно большие базы данных с очень низкой задержкой, а также обрабатывать очень высокие скорости запросов. Когда речь идет о крупных веб-сайтах, таких как eBay, Amazon, Twitter и Facebook, решающее значение имеют масштабируемость и высокая доступность . Вы можете запускать несколько экземпляров сервера одновременно с горизонтальным масштабированием.
База данных MongoDB масштабируется как по горизонтали, так и по вертикали как по масштабу, так и по количеству пользователей. В MongoDB вы можете масштабировать свой кластер по вертикали или горизонтали, добавляя дополнительные ресурсы и разбивая данные на более мелкие фрагменты. В результате MongoDB является популярным выбором для крупномасштабных приложений и хранилищ данных.
Лучшие базы данных Nosql для быстрого масштабирования и большого объема данных
Другие базы данных NoSQL можно масштабировать в соответствии с вашими конкретными потребностями точно так же, как и другие базы данных. MongoDB, например, — популярный язык программирования, потому что он может быстро масштабироваться и обрабатывать большие объемы данных. Хранилища данных на основе Redis широко используются благодаря своим возможностям в памяти и скорости.
Вертикальное масштабирование Nosql
Базы данных Nosql являются горизонтально масштабируемыми, что означает, что они могут обрабатывать увеличенный трафик за счет добавления дополнительных узлов в систему. Это отличается от вертикального масштабирования, при котором система масштабируется путем добавления дополнительных ресурсов к одному узлу.
Каждая база данных должна быть масштабирована для обработки ежедневно генерируемых объемов данных. Термин «масштабирование» подразделяется на два типа: вертикальное и горизонтальное. Если вы хотите хранить больше данных, вам следует инвестировать в сервер объемом 2 ТБ. Один сервер становится все дороже и больше. Процесс добавления машин к серверу приводит к горизонтальному масштабированию. В этом случае данные разбиваются на наборы и распределяются по нескольким серверам или сегментам. Поскольку он следует модели денормализации, нет необходимости в единственной точке истины. Этот подход может не привести к обновлению информации, когда мастеру не удается выполнить запись, поскольку он не обновляет информацию о подчиненных репликах, когда мастеру не удается выполнить запись.
Что такое вертикальное масштабирование в Sql?
Целью подхода вертикального масштабирования является увеличение мощности отдельной машины за счет увеличения ресурсов того же логического сервера. Существующее программное обеспечение должно быть обновлено за счет таких ресурсов, как память, хранилище и вычислительная мощность, чтобы работать с максимальной эффективностью.
Как масштабировать базу данных по горизонтали
Что такое горизонтальное масштабирование и как оно работает? Метод горизонтального масштабирования требует добавления дополнительных узлов, чтобы справиться с нагрузкой. Это чрезвычайно сложно с реляционными базами данных из-за сложности распределения связанных данных между узлами.
Помимо добавления дополнительных экземпляров для распределения нагрузки, горизонтальное масштабирование (или горизонтальное масштабирование) влечет за собой увеличение количества экземпляров приложения или службы. Напротив, вертикальное масштабирование требует добавления к экземпляру дополнительных ресурсов, таких как мощность ЦП и память. Благодаря базовым протоколам HTTP, большинства веб-приложений и API их можно легко масштабировать независимо друг от друга. Некоторые базы данных теперь позволяют синхронизировать записанные данные и обмениваться ими между несколькими экземплярами. Если трафик маршрутизируется таким образом, больше ресурсов выделяется для наиболее часто запрашиваемых элементов. Хотя обратные прокси-серверы обычно используются для обработки HTTP-запросов, базы данных не всегда используются для этого. Большинство баз данных можно пересылать с помощью программного обеспечения, такого как nginx или HAproxy, оба из которых могут быть выполнены на уровне TCP.
Если ваш прокси-сервер понимает, как работают соединения на уровне протокола, он может определить, не синхронизирована ли реплика чтения или не может ли она реагировать, даже если сетевое соединение активно. Маршрут можно корректировать в зависимости от нагрузки на реплику, а также количества подключений. Есть несколько прокси-серверов, которые могут выполнять различные функции. Несколько улучшений были достигнуты в постоянных томах и заявках, но есть и неотъемлемые трудности, если вы не выберете базу данных, которая одинаково оценивает каждый экземпляр. Поскольку контейнеры перемещаются по кластеру, перезапуск одной из ваших реплик чтения должен быть в порядке. Если это произойдет с основной базой данных , вы вряд ли будете в восторге.