
Solr — мощная поисковая платформа
Опубликовано: 2022-11-18Solr — это мощная поисковая платформа, которая позволяет очень быстро запрашивать большие объемы данных. Он построен на основе библиотеки поиска Apache Lucene и предоставляет REST-подобный API для простой интеграции с вашим приложением. Одной из ключевых особенностей Solr является его масштабируемость — он может легко обрабатывать миллиарды документов и запросов. Solr часто называют базой данных NoSQL, поскольку она не использует традиционную модель реляционной базы данных. Однако важно отметить, что Solr не является традиционной базой данных и не должна использоваться как таковая. Он предназначен для индексации и поиска, а не для хранения данных. Если вам нужно хранить данные, вы должны использовать базу данных NoSQL, такую как MongoDB или Cassandra.
Поскольку Elasticsearch является единственным проектом с открытым исходным кодом, способным конкурировать с Solr, Solr является одной из двух самых популярных поисковых систем с открытым исходным кодом в мире. NoSQL расшифровывается как Not Only SQL, что означает, что он использует языки запросов отдельно от традиционного SQL, а не только к базам данных. Несмотря на превосходную функцию полнотекстового поиска, Solr может быть чрезвычайно полезен в базе данных NoSQL. Данные о работоспособности извлекались непосредственно из HBase с помощью старых приложений Explorys и Worklist. Solr предоставил Worklist три основные функции: он был чрезвычайно прост в использовании, а функции были очень интуитивно понятны. Процесс фильтрации и сортировки очень эффективен. Поскольку фильтрация Solr основана на идентификаторах документов и кэшировании, она может почти мгновенно подсчитать количество документов, соответствующих критериям фильтрации.
Solr — отличное решение для базы данных NoSQL, которое часто сочетается с другими службами больших данных. Мы немедленно предоставили обратную связь нашим пользователям, когда они работали над добавлением и настройкой фильтров, отправив параметр rows=0 в Solr. Крайне важно рассмотреть больше, чем просто поддержание схемы Solr , чтобы создать поисковую систему, которая хороша для релевантности.
Можете ли вы использовать Solr в качестве базы данных?
Да, вы можете использовать Solr в качестве базы данных. Это мощная поисковая система, которую можно использовать для индексации и поиска данных. Его можно использовать для хранения данных в структурированном формате и быстрого их извлечения.
Является ли использование поискового индекса в качестве базы данных неправильным? В моем случае у меня была аналогичная идея хранить несколько основных элементов данных в Solr. Однако процесс обновления Solr изменил мое мнение, и я должен признать, что ошибался. Если вы обновили 2 мажорные версии, но не переиндексировали (например, удалили исходные документы, а затем сами индексные файлы), то ядро больше не распознается.
Algolia, Elastic Observability, Coveo и Yext — это лишь некоторые из популярных альтернатив Apache Solr. Algolia — это поисковая система на естественном языке, которая анализирует и обрабатывает поисковые запросы на основе того, что мы знаем о человеке или теме на естественном языке. Elastic Observability — это платформа данных, которая обеспечивает анализ данных и приложений в режиме реального времени. Coveo, платформа для маркетинга в поисковых системах, позволяет нацеливать и измерять маркетинговые усилия в поисковых системах. Используя Yext, вы можете нацеливать и измерять свои маркетинговые кампании в поисковых системах.
Что такое базы данных Nosql?
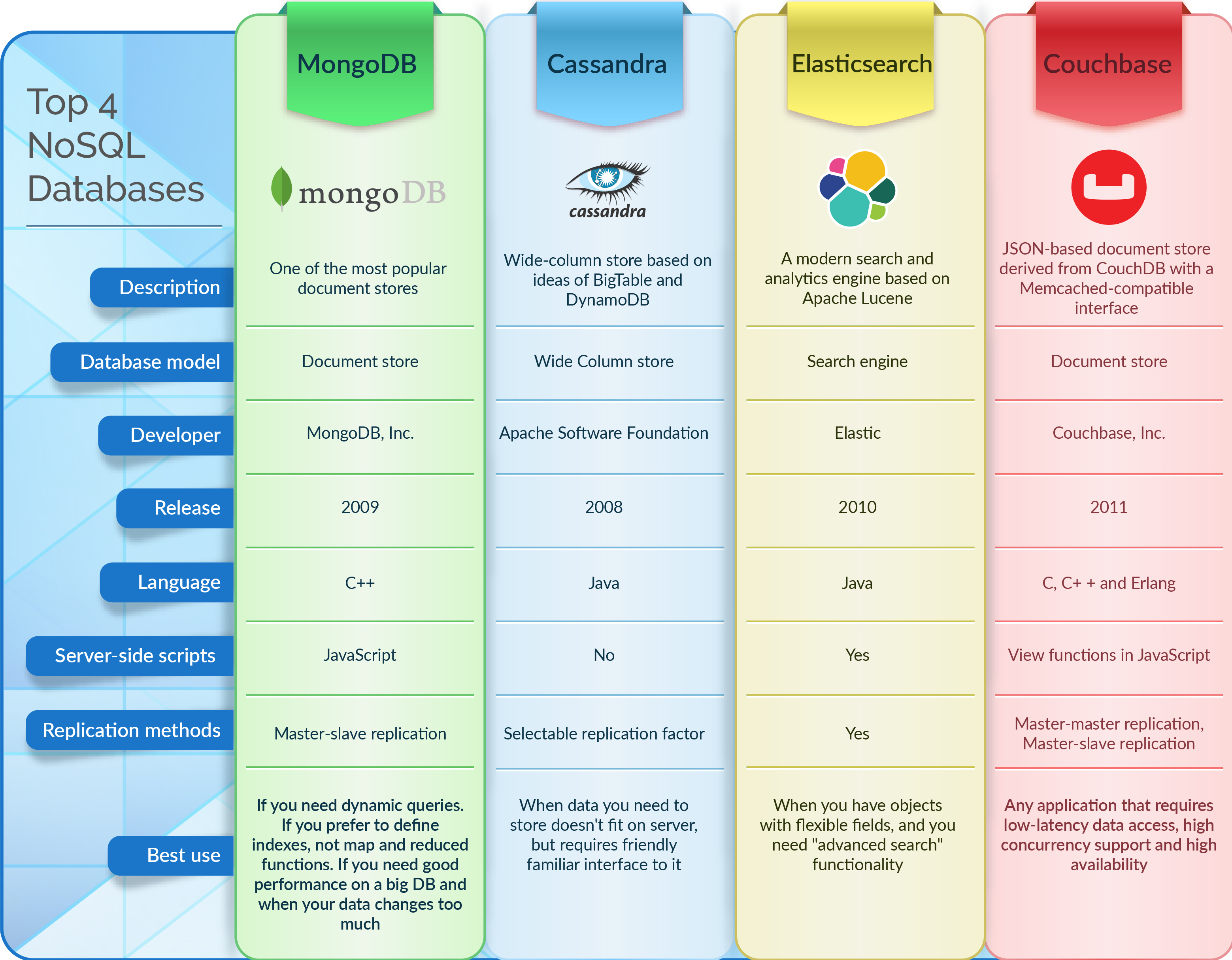
Базы данных Nosql — это базы данных, которые не используют традиционную модель реляционной базы данных. Вместо этого они используют различные модели, включая базы данных «ключ-значение», документы, столбцы и графы.
Базы данных NoSQL на основе документов хранят данные так же, как и реляционные базы данных. Программное обеспечение для управления данными создано таким образом, чтобы быть адаптируемым, масштабируемым и способным своевременно реагировать на потребности современного бизнеса. Базы данных документов , хранилища ключей и значений, базы данных с широкими столбцами и базы данных графов — это лишь некоторые из типов баз данных NoSQL. Большинство из 2000 крупнейших предприятий мира быстро внедряют базы данных NoSQL для поддержки критически важных приложений. В этом контексте пять тенденций создают технические проблемы, которые слишком сложны для решения большинства реляционных баз данных. Из-за фиксированной модели данных реляционные базы данных являются серьезным препятствием для гибкой разработки. Модель приложения определяет модель данных NoSQL.
Данные должны быть смоделированы в модели NoSQL независимо от того, как они структурированы. Формат JSON используется по умолчанию для хранения данных в базе данных, ориентированной на документы. Таким образом можно масштабировать платформы ORM, снижая накладные расходы на разработку приложений. N1QL (произносится как никель) — это язык запросов SQL-to-JSON, который был выпущен как часть Couchbase Server 4.0. Инструмент также поддерживает агрегацию (GROUP BY), сортировку (SORT BY), объединение (LEFT OUTER / INNER) и множество других функций. Распределенная база данных NoSQL с масштабируемой архитектурой, отсутствием единой точки отказа и убедительными эксплуатационными преимуществами — одна из самых привлекательных функций. Поскольку все больше взаимодействий с клиентами происходит в Интернете через веб-приложения и мобильные приложения, доступность становится проблемой.
Базы данных NoSQL просты в изучении и использовании. Они предназначены для хранения информации, написания и чтения книг. Они также способны управлять и контролировать кластеры различных размеров любого размера. Встроенная репликация, включенная в распределенную базу данных NoSQL, обеспечивается самой базой данных — никакого дополнительного программного обеспечения не требуется. Кроме того, аппаратные маршрутизаторы обеспечивают немедленный и постоянный доступ к критически важным данным. Пока администраторы базы данных исследуют проблему, приложениям не нужно ждать, пока база данных обнаружит проблему, прежде чем выполнять собственное восстановление. Технология NoSQL становится все более популярной в качестве платформы для современных веб-приложений, мобильных приложений и приложений IoT.
Существует множество причин, по которым базы данных NoSQL становятся все более популярными. Их можно масштабировать для удовлетворения потребностей крупных организаций, и они легко адаптируются. В качестве примера рассмотрим Ryanair и Marriott в качестве клиентов MongoDB. Эти организации, помимо использования MongoDB для своих мобильных приложений и систем бронирования, также используют его для своих веб-сайтов. Система управления контентом Presto компании также построена на NoSQL. Система помогает эффективно управлять собственным контентом компании.
Будущее работы Будущее работы удаленно
Что не является базой данных Nosql?
В чем разница между базами данных NoSQL и не-NoSQL? Microsoft SQL Server, система управления реляционными базами данных компании, является основным продуктом.
В конце 2000-х основное внимание было уделено масштабированию, быстрым результатам запросов и упрощению программирования благодаря базам данных NoSQL. Базы данных NoSQL легко создавать, поскольку они имеют гибкую модель данных, масштабируемую модель данных и простой в использовании пользовательский интерфейс. Реляционные базы данных SQL (язык структурированных запросов) обычно строятся с жесткими, сложными и табличными схемами, а также с недопустимо большим вертикальным масштабированием. Версия MongoDB 4.0 включала поддержку многодокументных транзакций ACID, а версия 4.2 добавляла поддержку сегментированных кластеров. В списке нет моделей данных. В большинстве баз данных NoSQL оптимизированы запросы, а не дублирование данных. Кроме того, некоторые No.
Базы данных NoSQL поддерживают сжатие, чтобы уменьшить объем хранилища. Графические базы данных, например, могут быть полезны для анализа взаимосвязей, но они могут быть не самыми удобными для получения ежедневных данных. Использование MongoDB или другой базы данных в вашем случае использования будет продемонстрировано в официальном документе «Где использовать MongoDB». Использование MongoDB Atlas в качестве отправной точки — один из самых простых способов изучения баз данных NoSQL. Университет MongoDB предлагает совершенно бесплатное онлайн-обучение, которое поможет вам в изучении MongoDB.
Однако у баз данных NoSQL есть некоторые недостатки. Базы данных NoSQL не только не содержат ACID, но и не обладают теми же свойствами, что и реляционные базы данных. Транзакции в вашем приложении могут привести к проблемам, если ваша система полагается на них. Кроме того, базы данных NoSQL обычно не обеспечивают такой же уровень гибкости во время выполнения, как базы данных SQL. Вам следует избегать использования баз данных NoSQL, если вашему приложению необходимо динамически изменять свои модели данных.
Что из перечисленного не является базой данных?
Поскольку все запросы, отчеты и таблицы связаны с базами данных, связи не являются объектами базы данных; они связаны с математикой.
Является ли MongoDB базой данных Nosql?
Программа управления базой данных MongoDB NoSQL имеет открытый исходный код и бесплатна для использования. Язык NoSQL является альтернативой традиционным реляционным базам данных. Базы данных NoSQL отлично подходят для крупномасштабного распространения данных. Информация, ориентированная на документ, может управляться, храниться или извлекаться с помощью MongoDB, которая представляет собой инструмент управления документами.
Как Solr хранит данные
Apache Solr индексирует данные в локальной файловой системе, как следует из его названия. В результате использования HDFS (распределенной файловой системы Hadoop) пользователи могут пользоваться множеством преимуществ, включая крупномасштабное и распределенное хранилище с резервными возможностями и возможностями аварийного переключения. Apache Solr включает поддержку HDFS.
В отличие от многих других поисковых систем, Solr может выдавать немедленные результаты, потому что ищет индекс, а не ищет напрямую текст. Сканируя индекс в конце книги, индекс можно использовать для поиска страниц, связанных с ключевым словом. Этот индекс хранится в каталоге данных как индекс в каталоге, известном как каталог данных. Поисковая система Solr основана на Lucene, системе полнотекстового поиска с открытым исходным кодом. Отношения между Solr и Lucene аналогичны отношениям автомобиля и его двигателя. В этой статье мы подробно рассмотрим различия между Lucene и Solr.

Как использовать сохраненные поля в Sol
Формат поля документа используется в Solr. Документ может содержать некоторую форму поля, которое представляет собой просто набор данных. При поиске документа с помощью Solr результаты будут включать совпадения для всех полей в индексируемом документе.
Сохраненное поле — это поле, которое не нужно искать, но которое все же нужно отображать при поиске чего-либо. В Solr они называются хранимыми полями. Solr индексирует все сохраненные поля в результате своего алгоритма индексации, поэтому при поиске документа Solr возвращает результаты, включающие все сохраненные поля.
Хранение полей имеет множество преимуществ. Если вы хотите отобразить заголовок документа в списке результатов, вам может потребоваться сохранить заголовок в виде файла. Если вы хотите иметь возможность находить все документы, которые вы когда-либо искали, используя один и тот же идентификатор, вы можете отслеживать идентификатор документа с помощью нескольких поисков.
Результаты поиска также могут отображаться путем сохранения полей. Название документа может появиться в списке результатов, если оно помечено. Вы также можете отобразить идентификатор документа, чтобы его можно было легко найти, выполнив поиск документа на нескольких сайтах.
Возможности Solr включают возможность индексировать данные, а также сохранять их. Чтобы проиндексировать документ, Solr должен сначала создать базу данных всех полей в нем, а затем будет сохранена информация о позиции каждого поля. Вы можете искать и отображать результаты из этого типа информации.
Помимо мощных возможностей поиска, Solr позволяет использовать мощные приложения для поиска документов. Когда вы предоставляете данные пользователям на основе их запроса, они основаны на их запросе.
Учебное пособие по базе данных Solr
База данных solr — это тип базы данных, использующий программное обеспечение solr для индексации и поиска данных. Это мощный инструмент, который можно использовать для очень быстрого индексирования и поиска больших объемов данных.
Поскольку это руководство было проверено для Solr 8, оно может работать и в более ранних версиях. Поле id уже предопределено в каждом Lucene и Solr, поэтому необходимо понимать, какие типы полей оно может правильно индексировать. Динамические поля можно создавать «на лету» без предварительных определений, что позволяет изменять их в любое время. Библиотека Lucene , которую Solr использует для полнотекстового поиска, использует моментальные снимки на определенный момент времени, которые необходимо регулярно обновлять, чтобы обеспечить представление новых сведений в запросах. Solr, в отличие от JSON или XML, не зависит от формата данных, не зависит от формата данных.
Как использовать поисковую систему Solr в Java
Клиент Java необходим для подключения к серверу Solr, поэтому используйте файл org.apache.solr.client.solrjimpl. Класс, использующий протокол HttpSolrServer, называется HttpSolrServer. Этот класс использует Java Socket для связи с сервером Solr. При создании серверного приложения Solr необходимо сначала загрузить соответствующие классы. Например, в Java доступ к функциям поиска Solr можно получить с помощью файла org.apache.solr.client.solrj.impl. Класс org.apache.solr.client.solrj.request является компонентом класса SolrServer. Этот класс создает класс RequestHandler. Эта мощная поисковая система позволяет легко находить необходимую информацию. Чтобы получить доступ к серверу Solr, используйте клиент Java.
Solr против Lucene
Что касается проектов Apache Solr и Lucene, то они состоят из одних и тех же компонентов. Apache Solr, с другой стороны, является автономным сервером, хотя и с множеством дополнительных функций. Apache Lucene, с другой стороны, представляет собой решение на основе библиотеки Java, которое индексирует (хранит) и ищет данные.
Из-за своего кеша Solr имеет преимущество в области статических данных, что может упростить получение результатов. Данные временных рядов часто обрабатываются Elasticsearch, который использует свои фильтры и возможности группировки в дополнение к данным временных рядов.
Solr против Elasticsearch
Однозначного ответа на этот вопрос нет, так как все зависит от индивидуальных потребностей и предпочтений. Однако некоторые ключевые различия между Solr и Elasticsearch включают:
-Solr основан на традиционной модели реляционной базы данных, в то время как Elasticsearch использует документно-ориентированный подход.
-Solr обычно быстрее индексирует и ищет большие наборы данных, в то время как Elasticsearch обычно более масштабируем.
-Solr поддерживает более сложные функции запросов, такие как соединения и вложенные объекты, в то время как Elasticsearch имеет более простой синтаксис запросов.
Существует большое сообщество разработчиков обеих технологий, и доступна экспертная помощь. Elasticsearch ранее был известен как Apache 2.0 и имел открытый исходный код. С 2021 года, когда будет выпущена версия 7.11, Elasticsearch можно будет использовать бесплатно в соответствии с общедоступной лицензией на стороне сервера. Он предназначен для текстового поиска на уровне предприятия, который требует извлечения информации и/или анализа. В Elasticsearch также возможен полнотекстовый поиск, и можно читать такие документы, как PDF и Word. Elasticsearch требует больше памяти кучи, чем Solr (1 ГБ против 512 МБ), но эти значения по умолчанию можно изменить. Платформа Elasticsearch обеспечивает большую автоматизацию, сочетая перебалансировку кластера с очисткой данных, что обычно не требует вмешательства.
Разделение — это метод распределения данных между несколькими серверами, поддерживаемый Solr и Elastic. И Solr, и ElasticSearch являются популярными базами данных поисковых систем с большими вовлеченными сообществами и схожими возможностями. Elasticsearch более удобен для пользователя, чем Solr, его легче масштабировать, он обладает лучшими возможностями аналитики и запросов. Библиотека Apache Tika, которая может использоваться обеими базами данных, позволяет им выполнять полнотекстовый поиск и читать форматированные документы.
Использование Apache Solr
Поскольку он может индексировать и искать документы и вложения электронной почты, а также индексировать и искать несколько веб-сайтов, он является популярным инструментом как для веб-сайтов, так и для корпоративного поиска.
Это поисковая платформа с открытым исходным кодом, которая используется для создания поисковых приложений. Он основан на популярной системе полнотекстового поиска Lucene . Solr — это облачная, очень гибкая платформа, готовая к корпоративным операциям. Параллельные запросы были включены в самой последней версии Solr, Solr 6.0, которая была выпущена в 2016 году. Платформа Solr позволяет нам масштабировать, распределять и управлять индексами для крупномасштабных приложений (больших данных). При работе с Solr вам не нужно быть программистом со знанием Java. Вместо Lucene он предоставляет очень простой и удобный сервис для создания окна поиска с автозаполнением.
Множество преимуществ Apache Sol
Поисковая система Apache Solr — популярная поисковая система как среди малых, так и среди крупных организаций. Это программное обеспечение очень универсально, что позволяет использовать его в различных ситуациях, включая анализ и поиск данных. Solr — это служба, предлагающая возможности корпоративного поиска, что делает ее идеальным выбором для управления большими объемами данных.
Полезное решение для базы данных Nosql
Сегодня доступно множество полезных решений для баз данных NoSQL . Базы данных NoSQL часто более масштабируемы и производительны, чем традиционные реляционные базы данных. Кроме того, они обычно более гибкие, что упрощает моделирование данных и эволюцию схемы. Некоторые популярные базы данных NoSQL включают MongoDB, Cassandra и HBase.
Базы данных NoSQL больше не будут использоваться разработчиками в будущем. Будущее наступило, когда эти базы данных станут обычным инструментом для поддержки популярных приложений. Возможно, вы не знаете, что некоторые популярные приложения работают с базами данных NoSQL, и почему NoSQL идеально подходит для этих приложений. В 1996 году Forbes стал первым деловым изданием, запустившим веб-сайт. Forbes переносит свой сервис на MongoDB Atlas, чтобы удовлетворить потребности 140 миллионов онлайн-пользователей. Из-за влияния пандемии COVID-19 издание перешло на облачную инфраструктуру и смогло справиться с трудными временами. Компания Accenture выбрала BangDB в качестве базы данных NoSQL для своего приложения для оценки лидов.
Facebook Messenger работает на базе данных Cassandra NoSQL без единой точки отказа, что позволяет масштабировать свои операции на нескольких платформах. Bigtable — это компонент Google Mail, который помогает Google Bigtable, онлайн-компании, поддерживающей различные транзакции Google Mail. База данных Espresso обеспечивает нормальную работу всех приложений LinkedIn. Загрузите BangDB бесплатно, чтобы узнать, подходит ли вам этот инструмент.
Преимущества баз данных Nosql
Многие базы данных NoSQL можно использовать для хранения и моделирования структурированных, полуструктурированных и неструктурированных данных в одной базе данных, что делает их идеальными для хранения и моделирования структур данных и семантики. Они могут работать лучше и быть более стабильными, чем традиционные реляционные базы данных, и их проще реализовать для разработчиков. С ростом популярности баз данных NoSQL их популярность, вероятно, будет продолжать расти.
Монгодб »
MongoDB — это мощная документно-ориентированная система баз данных. Он имеет функцию поиска на основе индекса, которая делает поиск данных быстрым и легким. MongoDB также предлагает функцию масштабируемости, позволяющую обрабатывать большие объемы данных.