
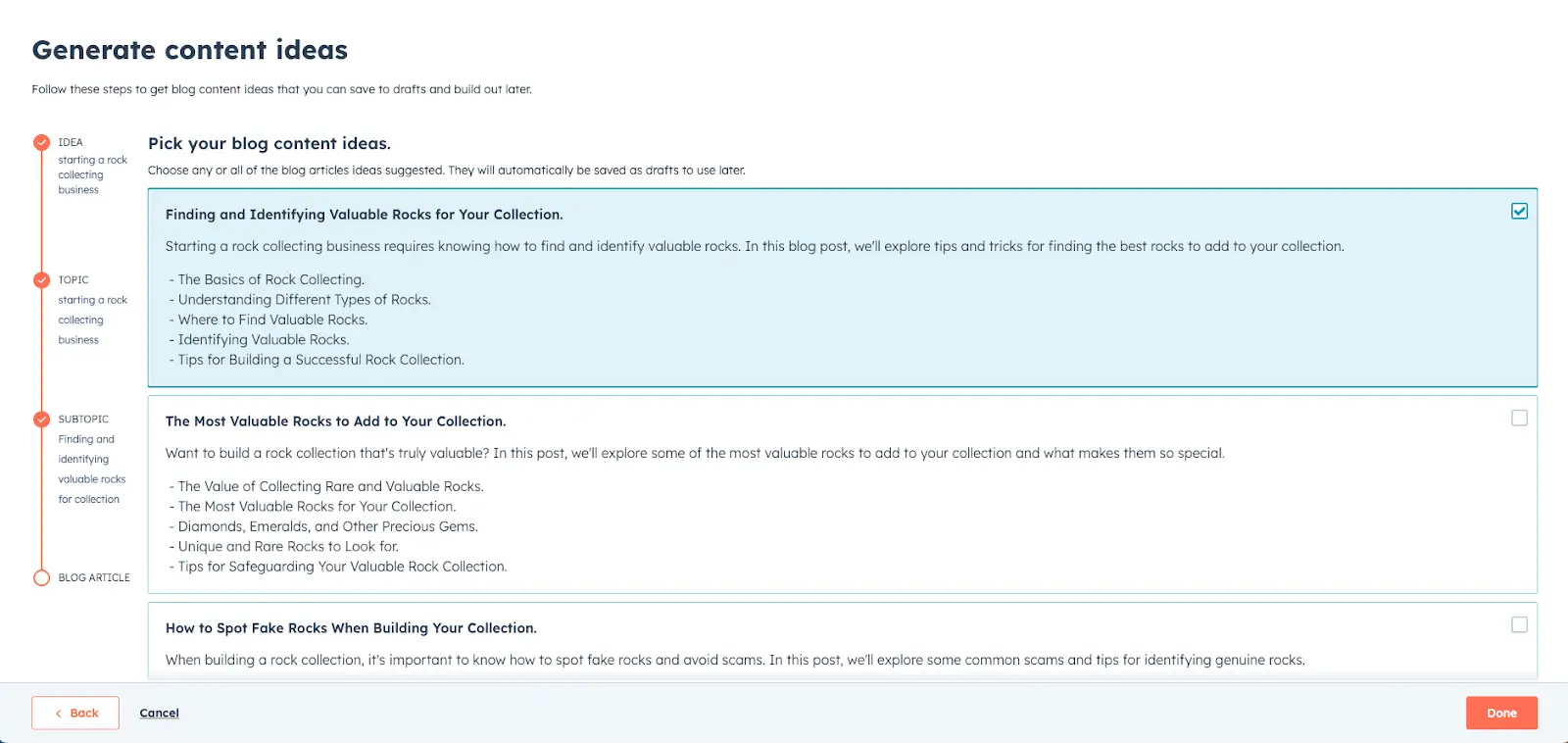
Полное руководство по алгоритмам ИИ
Опубликовано: 2023-10-25Искусственный интеллект появляется в каждой отрасли и каждом процессе, будь то производство, маркетинг, хранение или логистика. В реальном мире существует множество примеров использования ИИ.

Сюда входят как технические варианты использования, такие как автоматизация человеческой рабочей силы и роботизированных процессов, так и базовые приложения. Вы увидите ИИ в поисковых системах, картах и навигации, текстовых редакторах и многом другом.
Но задумывались ли вы когда-нибудь о том, как работают эти машины?
Системы ИИ работают на основе алгоритмов, но не все алгоритмы ИИ одинаковы . Если вы понимаете, как работают алгоритмы ИИ, вы можете упростить свои бизнес-процессы, сэкономив часы ручной работы.
В этой статье будут обсуждаться типы алгоритмов ИИ, как они работают и как обучать ИИ для получения наилучших результатов.
Что такое алгоритмы ИИ?
Как работают алгоритмы ИИ?
Типы алгоритмов ИИ
Советы по тренировке вашего ИИ

Алгоритмы ИИ — это инструкции, которые позволяют машинам анализировать данные, выполнять задачи и принимать решения. Это разновидность машинного обучения, которая заставляет компьютеры учиться и работать независимо.
Все задачи, которые выполняет ИИ, работают по конкретным алгоритмам. Алгоритмы искусственного интеллекта работают с другими алгоритмами машинного обучения, начиная с момента включения системы и заканчивая просмотром страниц в Интернете для выполнения каждой задачи.
Алгоритмы искусственного интеллекта и машинного обучения позволяют компьютерам прогнозировать закономерности, оценивать тенденции, рассчитывать точность и оптимизировать процессы.
В этом видео объясняется работа алгоритмов искусственного интеллекта и функции, которые они могут выполнять:
Если вам нужна более подробная информация об ИИ, загрузите эту бесплатную электронную книгу о генеративном ИИ. Вы также можете обнаружить разницу между работой искусственного интеллекта и машинным обучением.
Как работают алгоритмы ИИ?Алгоритмы ИИ работают следующим образом: они выявляют закономерности, распознают поведение и дают машинам возможность принимать решения.
Допустим, вы приказываете своему голосовому помощнику, например Alexa или Google Home, транслировать вашу любимую музыку.
Алгоритм искусственного интеллекта, на котором он основан, сначала распознает и запомнит ваш голос, ознакомится с выбранной вами музыкой, а затем запомнит и воспроизведет вашу самую популярную музыку, просто подтвердив ее.
Аналогичным образом, инструменты редактирования контента ИИ работают с такими алгоритмами, как модели генерации естественного языка (NLG) и обработки естественного языка (NLP), которые следуют определенным правилам и шаблонам для достижения желаемых результатов.
Это не ракетостроение, а простая формула: «Чем больше ты учишься, тем больше ты растешь». Когда вы обслуживаете компьютерные системы богатыми данными, алгоритмы используют их для получения знаний и более эффективного выполнения задач.
На самом базовом уровне алгоритм ИИ собирает данные для обучения, а затем использует их для модификации своих знаний. Далее он использует эти знания для выполнения задач и повышения точности.
Совет для профессионалов: ознакомьтесь с нашим новым интегрированным AI-инструментом ChatSpot для пользователей HubSpot. Наш последний помощник по контенту использует генеративный искусственный интеллект для оптимизации создания, генерации, творчества, управления данными, задач SEO и многого другого.
Типы алгоритмов ИИТочно так же, как математические вычисления имеют различные формулы с одним и тем же результатом, так и алгоритмы ИИ.
Различные варианты использования в бизнесе имеют разные алгоритмы и категории. Например, алгоритм, используемый в различных чат-ботах, отличается от алгоритма, используемого при проектировании беспилотных автомобилей.
Существует три основные категории алгоритмов ИИ, под которые подпадают сотни других алгоритмов: контролируемое, неконтролируемое и обучение с подкреплением. Разница в том, как они обучены и как они функционируют.

1. Алгоритмы обучения с учителем
Первой наиболее популярной формой алгоритма является алгоритм контролируемого обучения. Он включает в себя обучение модели на помеченных данных, чтобы делать прогнозы или классифицировать новые и невидимые данные.
Название «контролируемый» означает работу под наблюдением обучающих наборов. Он работает просто за счет использования желаемого результата для перекрестной проверки с заданными входными данными и обучения его обучению с течением времени.
Этот алгоритм обучения создан под руководством группы преданных своему делу экспертов и специалистов по данным для тестирования и проверки на наличие ошибок.
Разработчики обучают данные для достижения максимальной производительности, а затем выбирают модель с наивысшей производительностью.
Алгоритмы контролируемого обучения чаще всего решают задачи классификации и регрессии. Примеры этого включают нейронные сети, деревья решений, линейную регрессию случайного леса, регрессию временных рядов и логистическую регрессию.
Варианты использования: маркетологи используют этот алгоритм искусственного интеллекта для прогнозирования продаж с течением времени, определения настроений клиентов, отслеживания цен на акции и многого другого. Другие варианты использования контролируемых алгоритмов включают распознавание текста, категоризацию объектов и обнаружение спама.
Что нам нравится: контролируемое обучение создает и обучает алгоритм масштабируемым образом. Для организаций это экономит ручную работу сотрудников и создает персонализированный опыт.
Хорошая особенность этого алгоритма — его простой процесс, который обеспечивает высокие результаты и дает точную информацию.
2. Алгоритмы обучения без учителя
Обучение без учителя использует немаркированные данные для подачи и обучения алгоритмов. В то время как обучение с учителем имеет заранее определенные классы, классы без учителя обучаются и растут, выявляя закономерности и формируя кластеры в пределах заданного набора данных.
Проще говоря, обучение с учителем осуществляется под наблюдением человека, тогда как обучение без учителя — нет. Алгоритм неконтролируемого обучения использует необработанные данные для выявления закономерностей и выявления корреляций, извлекая наиболее релевантную информацию.
Наиболее яркими примерами обучения без учителя являются уменьшение размерностей и кластеризация, целью которых является создание кластеров определенных объектов.
Сценарии использования. Кластеризация и сокращение данных имеют более широкое применение в биологии, химии и интеллектуальном анализе данных.
В маркетинге и бизнесе обучение без учителя лучше всего использовать для сегментации клиентов — понимания групп клиентов и их поведения.
Обучение без учителя находит применение в генетике и ДНК, обнаружении аномалий, визуализации и выделении признаков в медицине.
Даже Google использует обучение без присмотра, чтобы классифицировать и отображать персонализированные новости для читателей. Во-первых, он собирает миллионы новостей на различные темы.
Затем поисковая система использует кластерный анализ, чтобы установить параметры и классифицировать их на основе частоты, типов, предложений и количества слов.
Генеративный ИИ рисует шаблоны и структуры, используя шаблоны нейронных сетей. Однако дело не ограничивается использованием только этого подхода.
Он использует различные модели обучения (а именно обучение без учителя и полуконтроля) для обучения и преобразования неструктурированных данных в базовые модели.
Что нам нравится: Алгоритмы обучения без учителя обнаруживают скрытые закономерности и структуры в данных, облегчая обучение функций без учителя и обнаружение аномалий.

Самое приятное то, что для этого не нужны никакие размеченные данные, что, в свою очередь, оказывается более экономичным.
3. Обучение с подкреплением
Обучение с подкреплением работает так же, как и люди. Алгоритм обучается и учится у окружающей среды, а также получает обратную связь в виде вознаграждений или штрафов, чтобы наконец скорректировать свои действия на основе обратной связи.

Источник изображения
Обучение с подкреплением — это непрерывный цикл обратной связи и происходящих действий. Цифровой агент помещается в среду для обучения, получая обратную связь в качестве награды или наказания.
На протяжении всего процесса агент пытается принять решение и получить желаемый результат, который является основой обратной связи. Если обратная связь получена в качестве награды, агент повторяет и использует ту же тактику в следующем цикле, улучшая свое поведение.
Примеры обучения с подкреплением включают Q-обучение, глубокие состязательные сети, поиск в дереве Монте-Карло (MCTS) и асинхронные агенты-критики (A3C).
Случаи использования. Обучение с подкреплением — это широко используемый алгоритм, который находит применение в маркетинге, здравоохранении, игровых системах, управлении дорожным движением и обработке изображений.
Даже Netflix использует обучение с подкреплением, чтобы рекомендовать сериал своим пользователям и персонализировать его. Amazon получает 35% покупок потребителей благодаря рекомендациям, полученным с помощью обучения с подкреплением.
Что нам нравится: Принцип обучения с подкреплением заключается в принятии решений. Благодаря системе вознаграждений и штрафов алгоритм допускает меньше ошибок на более поздних этапах.
После этого он следует шаблону, основанному на награде или количественном балле, который он получает.
Советы по тренировке вашего ИИУспех ваших алгоритмов ИИ зависит главным образом от процесса обучения, который он проводит, и от того, как часто он обучается. Есть причина, по которой гигантские технологические компании тратят миллионы на подготовку своих алгоритмов искусственного интеллекта.
Однако стоимость обучения ИИ значительна. Например, обучение большой модели ИИ, такой как GPT-3 составила $4 млн, сообщает CNBC.
Даже алгоритм, на котором основана система рекомендаций Netflix, оценивается примерно в 1 миллион долларов.
В конце концов, это наиболее существенная часть жизненного цикла вашей системы искусственного интеллекта. Процессы и рекомендации по обучению вашего алгоритма ИИ могут незначительно отличаться для разных алгоритмов.

Источник изображения
Вот лучшие советы по обучению и реализации алгоритмов ИИ.
Определите варианты использования.
Основой для создания и обучения вашей модели ИИ является проблема, которую вы хотите решить. Учитывая ситуацию, вы можете легко определить, какой тип данных нужен этой модели ИИ.
Пищевому гиганту McDonald's требовалось решение для создания цифровых меню с изменяющимися ценами в режиме реального времени. Когда клиент размещает заказ, цена каждого продукта будет зависеть от погодных условий, спроса и расстояния.
Еще один вариант использования, в котором они использовали ИИ, — это рекомендации на основе заказов. Допустим, кто-то заказал салат. Модель искусственного интеллекта обнаруживает и предлагает включить во время еды полезный напиток.
Крайне важно увидеть, как ваши коллеги или конкуренты используют алгоритмы ИИ для решения проблем, чтобы лучше понять, как вы тоже можете это сделать.
Соберите и подготовьте данные.
Для процветания и роста системам искусственного интеллекта нужны данные так же, как людям нужен воздух.
Предпосылкой для обучения алгоритмам ИИ является сбор и подготовка данных. Под данными мы подразумеваем необработанные данные, которые будут использоваться в качестве основы для обучения вашего алгоритма ИИ.
Большинство организаций, внедряющих алгоритмы искусственного интеллекта, полагаются на эти необработанные данные для поддержки своих цифровых систем. Компании применяют такие методы сбора данных, как парсинг веб-страниц и краудсорсинг, а затем используют API для извлечения и использования этих данных.
Но простого сбора данных недостаточно. Следующим важным шагом является предварительная обработка и подготовка данных, которая включает в себя очистку и форматирование необработанных данных.
Instagram использует процесс интеллектуального анализа данных, предварительно обрабатывая данные на основе поведения пользователя и отправляя рекомендации на основе отформатированных данных.
Выберите свою модель ИИ.
Разработчикам приходится выбирать свою модель в зависимости от типа доступных данных — модель, которая может эффективно решить их проблемы из первых рук. По словам Оберло, около 83% компаний уделяют особое внимание пониманию алгоритмов ИИ.
Выбор модели зависит от того, есть ли у вас помеченные, немаркированные данные или данные, которые вы можете использовать для получения обратной связи от среды.
Однако другие факторы определяют архитектуру модели ИИ. Выбор модели ИИ также зависит от:
- Размер и структура данных.
- Сложность доступного набора данных.
- Желаемый уровень точности.
В зависимости от этих факторов и типа решаемой проблемы существуют различные модели ИИ, такие как линейная регрессия, деревья решений ИИ, наивный Байес, случайный лес, нейронные сети и другие.
Итак, если проблема связана с решением обработки изображений и идентификацией объектов, лучшим выбором модели ИИ будут сверточные нейронные сети (CNN).
Обучите свою модель ИИ.
В основе вашего алгоритма ИИ лежит обучение, тестирование и проверка набора данных. Следовательно, это самый важный шаг в обучении вашего алгоритма ИИ.
Первым шагом является начальный процесс обучения. Подготовленные данные вводятся в модель для проверки на наличие отклонений и обнаружения потенциальных ошибок.
Основная ошибка в модели ИИ — переобучение. Это означает, что ошибка возникает, когда конкретный обученный набор данных становится слишком предвзятым.
Один из примеров переоснащения можно увидеть на беспилотных автомобилях с определенным набором данных. Транспортные средства работают лучше в ясную погоду и на дорогах, поскольку они прошли дополнительное обучение на этом наборе данных.
В результате транспортные средства не могут работать в экстремальных погодных условиях и местах массового скопления людей. При загрузке нового набора данных модель ИИ не сможет распознать набор данных.
Последующими этапами процесса обучения являются валидация и тестирование.
В то время как при проверке повторно проверяются и оцениваются данные перед их передачей на финальный этап, на этапе тестирования наборы данных и их функциональные возможности реализуются в реальных приложениях.
Этап тестирования — это когда тренировочные колеса отрываются, и модель анализируется на предмет того, как она работает в реальном мире, с использованием неструктурированных данных.
Если ему не удается выполнить работу и вернуть желаемые результаты, алгоритм ИИ отправляется обратно на этап обучения, и процесс повторяется до тех пор, пока он не даст удовлетворительные результаты.
Измеряйте и отслеживайте результаты.
Финальный тест является основой отслеживания вашей модели ИИ. Алгоритмы ИИ измеряются с использованием конкретных показателей для получения результатов.
Рассчитайте соответствующие показатели оценки, такие как точность, точность, отзыв, показатель F1 или среднеквадратическая ошибка, в зависимости от типа вашей проблемы.
Установите цель или пороговое значение для каждой метрики, чтобы определить результаты. Если результаты неудовлетворительны, повторите и уточните свой алгоритм на основе данных, полученных в результате мониторинга и анализа.
Всегда тестируйте свой алгоритм в различных средах и тренируйте его до совершенства.

Начиная
Ожидается, что к 2030 году объем искусственного интеллекта увеличится в двадцать раз — со 100 миллиардов долларов до 2 триллионов долларов. Каждому бизнесу, независимо от его размера, необходим алгоритм искусственного интеллекта для повышения операционной эффективности и использования преимуществ технологий.
