
Различные типы компьютерных кластеров
Опубликовано: 2023-02-16В вычислительной технике кластер представляет собой группу независимых компьютерных систем, которые работают вместе, так что во многих отношениях их можно рассматривать как единую систему. Кластеры обычно развертываются для повышения производительности и доступности по сравнению с одним компьютером, при этом они обычно гораздо более рентабельны, чем отдельные компьютеры с сопоставимой скоростью или доступностью. Существуют различные типы компьютерных кластеров, в том числе высокопроизводительные вычислительные кластеры, компьютерные кластеры, используемые в коммерческих целях, и кластеры хранения. В каждом типе кластера компоненты системы работают вместе для выполнения общей задачи или задач. Кластеры высокопроизводительных вычислений (HPC) используются для научных и инженерных приложений, требующих большой вычислительной мощности и/или хранения данных. Эти кластеры обычно состоят из группы стандартных компьютеров, соединенных быстрой локальной сетью (LAN). Компьютеры в кластере HPC обычно работают под управлением одной и той же или похожей операционной системы (ОС) и имеют одинаковые или похожие аппаратные компоненты. Коммерческие кластеры используются для запуска бизнес-приложений, требующих высокой степени доступности и/или масштабируемости. Эти кластеры часто состоят из серверов, работающих под управлением различных операционных систем и имеющих различные аппаратные компоненты. Во многих случаях серверы в коммерческом кластере также подключены к сети хранения данных (SAN), чтобы иметь доступ к общим хранилищам данных. Кластеры хранения используются для предоставления централизованного репозитория хранения, доступ к которому может получить группа компьютеров. Кластеры хранения обычно состоят из группы серверов хранения, подключенных к SAN. Серверы в кластере хранения обычно работают под управлением различных операционных систем и имеют различные аппаратные компоненты.
Что такое сегментированный кластер mongodb и какой смысл подключаться к нему в MongoDB? Как мне подключиться к одному или просто подключиться к локальному хосту? Золотая медаль присуждается на значке Noob 7461. Было выпущено десять серебряных и 23 бронзовых знака. Реплицированный кластер состоит из десяти серверов, по одному для интерфейса mongos, по три для каждого набора реплик и по одному для каждого набора реплик сервера конфигурации. В системе репликации компонент дублируется, чтобы всегда была резервная копия, если что-то пойдет не так. Все осколки должны быть репликами, чтобы их можно было изготовить.
Кластер mongodb, например, обычно используется для описания сегментированного кластера в MongoDB. Сегментированный mongodb выполняет следующие функции: Масштабирование читает и записывает с нескольких узлов. Поскольку каждый узел не обрабатывает весь набор данных, вы можете разделить данные только на регионы в сегменте.
Кластер баз данных , как следует из названия, представляет собой набор баз данных, которые могут запускаться одним экземпляром работающего сервера баз данных. Postgres, что означает «база данных по умолчанию» в PostgreSQL, будет включена в качестве базы данных по умолчанию в кластер баз данных после его создания.
Кластер MongoDB также может называться «набором реплик» или «сегментированным кластером». В наборе реплик несколько серверов несут копии одних и тех же данных. Узлов в наборе реплик обычно три. Когда клиентское приложение выполняет какие-либо операции на узле, все операции чтения и записи отправляются на этот узел; если что-то пойдет не так, его защитят два вторичных узла.
Кластер и база данных — это одно и то же?
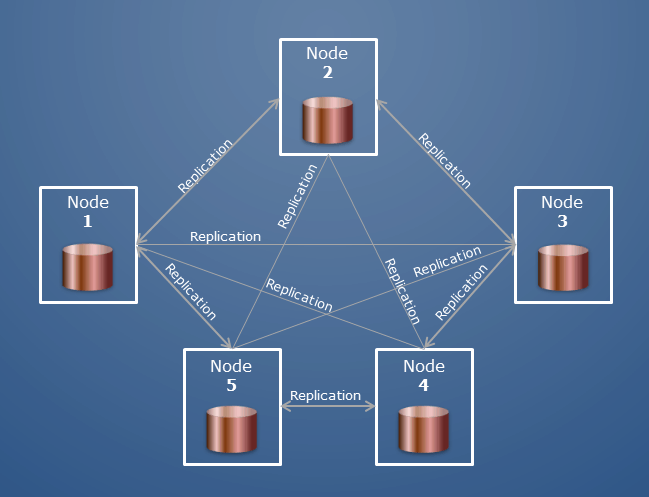
Есть несколько кластеров хостов, которые составляют кластер. Узлы сегментированного кластера классифицируются по разным ролям. База данных — это набор коллекций; в Oracle это было бы эквивалентно базе данных и асхеме.
Кластер базы данных — это набор серверов или экземпляров, которые соединяют одну базу данных с другой. Кластеризация базы данных используется серверами по разным причинам, основными из которых являются избыточность данных, балансировка нагрузки, высокая доступность, а также мониторинг и автоматизация. В результате, если компьютер выйдет из строя, все наши данные будут доступны другим, что дает нам преимущество избыточности данных. Кластеризация дает возможность автоматизировать многие процессы базы данных, а также создавать правила для выявления потенциальных проблем. В кластерной архитектуре все запросы направляются на несколько компьютеров, каждый из которых способен обрабатывать запрос и создавать его для пользователя. Отказоустойчивый кластер или кластер высокой доступности реплицирует серверы и перенастраивает оборудование для обеспечения доступности службы. Эти типы кластеров выгодны для пользователей компьютеров, которые полностью полагаются на свои системы. Целью высокопроизводительных кластеров является увеличение пропускной способности сети при одновременном повышении производительности.
В распределенной системе Hadoop узлы действуют как центры хранения и обработки данных. Основное различие между кластером и сервером заключается в том, что в кластере используется несколько узлов, которые взаимодействуют друг с другом для выполнения набора операций. Кластер содержит ряд узлов, которые будут выполнять набор операций. Распределенная система Hadoop может поддерживать до 10 000 баз данных. Аналогичные результаты запроса можно получить, когда данные из нескольких таблиц одной базы данных объединяются в запрос из нескольких баз данных в одном кластере.
Преимущества кластера
Используя кластер, вы можете легко управлять несколькими базами данных, предоставляя единообразное хранилище таблиц и столбцов для всех из них. Это повышает производительность и целостность данных и, таким образом, делает систему более эффективной.
Где находится имя кластера в MongoDB?
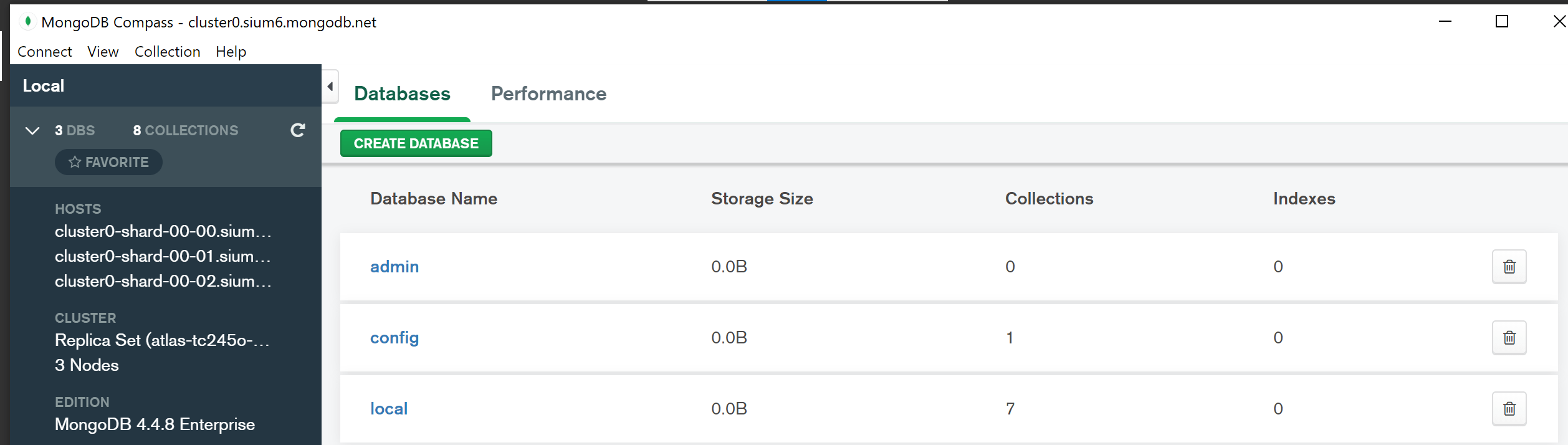
На этот вопрос нет определенного ответа, поскольку имя кластера можно найти в разных местах в зависимости от типа используемого кластера MongoDB. Например, в наборе реплик имя кластера обычно хранится в коллекции local.system.replset, а в сегментированном кластере оно обычно находится в коллекции config.shards.
MongoDB Atlas — это предложение MongoDB как услуга NoSQL «База данных как услуга», которое доступно в общедоступных облаках Microsoft Azure, Google Cloud Platform и Amazon Web Services. Вы можете создать работающий кластер MongoDB за считанные минуты, используя свой любимый веб-браузер, щелкнув ссылку для его настройки. Нет необходимости устанавливать программное обеспечение на вашу рабочую станцию, чтобы подключаться через нее к сети, и вы можете использовать для этого веб-интерфейс. Когда наборы реплик MongoDB используются в сочетании с несколькими серверами MongoDB, гарантируется избыточность данных и высокая доступность. Кластер MongoDB имеет дополнительные возможности операций чтения, что позволяет направлять клиентов на дополнительные серверы. При репликации один или несколько элементов набора реплик асинхронно реплицируются из oplog основного узла на вторичные, что позволяет набору реплик функционировать, несмотря на любые потенциальные сбои его элементов. В MongoDB вы можете выполнять дополнительные операции чтения и записи в дополнение к стандартным командам ввода и вывода.
В большинстве случаев первичный узел является источником всех операций чтения, но можно настроить маршрутизацию на вторичные узлы. Риск потенциально устаревших данных выше, если ближайший узел является вторичным узлом. Чтобы запись успешно распространялась по кластеру, вам необходимо включить параметры для записи данных в набор реплик MongoDB. В рамках этого процесса к вставке должно быть добавлено свойство записи. Когда запрос на запись получен, кластеру предлагается подтвердить, что он был успешным на подавляющем большинстве узлов, несущих данные. Конфигурация сегментированного кластера также позволяет настроить его как набор реплик. Набор реплик содержит как первичные, так и вторичные процессы mongod. Если мастер выходит из строя, рекомендуется, чтобы общее количество этих процессов было нечетным, чтобы обеспечить выполнение большинства.
Кластеры MongoDB , как следует из названия, представляют собой кластеры узлов, которые работают вместе для хранения и управления данными. При создании кластера MongoDB вы указываете, сколько узлов включить и для чего они должны быть настроены. Вы можете подключить свое приложение к кластеру MongoDB с помощью Node после его создания. MongoDB Compass можно рассматривать как драйвер для JS-библиотеки MongoDB или драйвер PyMongo для MongoDB. Основное преимущество подключения вашего приложения к кластеру заключается в том, что оно может читать и записывать в него данные. С MongoDB Compass вы можете исследовать, изменять и визуализировать свои данные различными способами. Пример того, как вы можете просматривать свои данные, можно найти в сетке, которая позволяет вам наблюдать, как данные меняются с течением времени и кто распространяет данные в вашем кластере.
Где находится кластер в MongoDB Atlas?
На этот вопрос нет однозначного ответа, поскольку расположение кластера в MongoDB Atlas может варьироваться в зависимости от ряда факторов, включая географический регион, в котором он расположен, и конкретные потребности приложения, которое он поддерживает. Однако в целом кластер в MongoDB Atlas можно найти в разделе «Кластеры» консоли MongoDB Atlas.
Кластер может быть набором реплик или сегментированным набором. Общее количество узлов каждого проекта ограничивается конкретным ограничением, основанным на диапазоне их функций в разных регионах. В каждом проекте Atlas можно развернуть до 25 баз данных. Если у вас возникнут вопросы об ограничении развертывания базы данных, обращайтесь к администраторам базы данных. Версия TLS 1.2 — это версия TLS по умолчанию для кластеров, созданных после 1 июля 2020 года.

Что такое кластер в MongoDB
В MongoDB кластер — это группа серверов баз данных, на которых хранятся копии одних и тех же данных. Каждый сервер в кластере называется узлом. Кластер может иметь один или несколько узлов.
Для чего нужна кластеризация баз данных? Процесс подключения нескольких серверов или экземпляров к одной базе данных называется подключением SQL. В MongoDB кластер представляет собой либо набор реплик, либо сегментированный кластер, в зависимости от типа MongoDB. В следующих абзацах я более подробно рассмотрю отдельные аспекты каждого из этих кластеров. Благодаря балансировке нагрузки и количеству машин MongoDB имеет высокий уровень доступности. Кластер можно использовать для автоматизации многих процессов базы данных, а также для создания правил для оповещения о потенциальных проблемах. Базу данных MongoDB можно разделить на два типа: наборы реплик и сегментированные кластеры.
Данные хранятся на нескольких машинах в шарде. На этом основан метод MongoDB по обеспечению масштабируемости данных. Это сокращает время, необходимое для управления большими объемами данных. Из-за объема данных, которые предоставляют реплики, распределенные приложения также могут извлечь из них выгоду.
Проблемы с производительностью и конфликты данных могут возникнуть, если в одном кластере развернуто несколько проектов Atlas. Atlas рекомендует использовать только один бесплатный кластер для каждого проекта Atlas. Хороший инструмент кластеризации данных требуется в широком спектре приложений для анализа и интеллектуального анализа данных. Чтобы избежать потенциальных проблем с производительностью и конфликтов данных в проектах Atlas, Atlas рекомендует использовать только один свободный кластер для каждого проекта.
Архитектура кластера MongoDB
Кластер MongoDB — это группа серверов MongoDB, которые работают вместе для хранения ваших данных. Каждый сервер в кластере называется узлом. Кластер может иметь любое количество узлов. Кластер состоит из набора реплик, который представляет собой группу узлов, каждый из которых имеет копию ваших данных. В наборе реплик есть как минимум три узла, так что если один узел выйдет из строя, ваши данные все еще будут доступны.
Архитектура наборов реплик является важным фактором емкости и возможностей MongoDB. Кластеры MongoDB обычно распределяются по трем репликам узлов. Восстановление базы данных после аварии должно быть постоянно стабильным, особенно после нее. Один из лучших способов развертывания сегментированного кластера — использование стратегии репликации. Данные, содержащиеся в осколочных ключах, должны распространяться таким же образом. Вам следует масштабировать базу данных по горизонтали и уменьшить количество операций, которые можно выполнять на одном экземпляре. При небольшом количестве сегментов операции чтения и записи могут замедляться из-за того, что количество сегментов ограничивает количество операций.
Каждая часть данных в сегменте состоит из подмножества этой части на основе определенного набора критериев. Как правило, минимальное количество сегментов, необходимое для достижения значимости сегментирования, равно двум. Запросы Scatter-gather следует использовать только в том случае, если их можно использовать одновременно друг с другом на всех осколках. При выборе кластера очень важно иметь не менее семи членов с правом голоса, чтобы процесс выборов был максимально простым. Если у вас есть только семь или меньше членов с правом голоса, но равное количество членов, необходимо использовать арбитра. Арбитры не хранят копии данных, поэтому для обработки данных требуется меньше ресурсов. Использование логического DNS-имени хоста, а не IP-адреса, предпочтительнее при настройке элементов набора реплик или сегментированных элементов кластера. Поскольку некоторые соединения наборов реплик группы драйверов осуществляются по именам наборов реплик, эти имена следует использовать отдельно для наборов. Географическое распределение узлов набора реплик идеально подходит для решения проблемы избыточной избыточности и обеспечения отказоустойчивости в случае отсутствия одного из центров обработки данных.
Имя кластера MongoDB
Кластер MongoDB — это группа серверов MongoDB, которые работают вместе для обеспечения высокой доступности и масштабируемости. Кластер обычно имеет первичный сервер, который действует как главный сервер, и один или несколько вторичных серверов, которые действуют как подчиненные. Первичный сервер содержит данные, а вторичные серверы копируют данные с первичного сервера.
Программы баз данных, ориентированные на документы, создаются для хранения больших объемов с помощью кроссплатформенной программы MongoDB. MongoDB, программа базы данных NoSQL, классифицируется как таковая, потому что она использует документы в стиле JSON с необязательными схемами. Вы можете повысить производительность, установив свою базу данных в том же центре обработки данных, что и другие ресурсы DigitalOcean. В регионе есть один или несколько центров обработки данных, и у каждого есть своя сеть VPC. Можно выбрать тип машины, количество и размер узлов базы данных. Другими словами, вы можете добавить в свой кластер до двух резервных узлов. Добавьте имя проекта, завершите его и используйте любые теги, которые вы хотите использовать при его создании. Создание кластера может занять до пяти минут.
Сила кластера Mongodb Atlas
MongoDB Atlas Cluster — это решение NoSQL «база данных как услуга» в общедоступном облаке, работающее в MongoDB. Это надежная масштабируемая платформа данных, позволяющая быстро создавать и развертывать приложения. Используя MongoDB Atlas Cluster, вы можете безопасно подключаться к MongoDB из любой точки мира.
Как создать кластер в MongoDB
Используйте следующие шаги для создания кластера в MongoDB:
1. Выберите топологию развертывания.
2. Выберите тип набора реплик, который вы хотите развернуть.
3. Выберите количество наборов реплик, которые вы хотите развернуть.
4. Настройте наборы реплик.
5. Подключитесь к маршрутизатору mongos.
6. Настройте ключ сегмента.
7. Добавляет шарды в кластер.
8. Убедитесь, что кластер работает.
MongoDB Atlas — это бесплатный уровень MongoDB, который представляет собой полностью управляемую службу облачных баз данных MongoDB. Сервис предназначен для корпоративных рабочих нагрузок, а также для глобальных кластеров . Вам не нужно создавать учетную запись в Amazon Web Services (AWS), Google Cloud Platform или Microsoft Azure. Он попросит вас создать учетную запись администратора для доступа к службе. Для доступа к сервису кластер должен быть связан с IP-адресом. Настройки безопасности MongoDB Atlas по умолчанию запрещают все внешние подключения. Ваш пароль не должен содержать специальных символов и содержать только буквенно-цифровые символы, чтобы упростить подключение к Studio 3T. При создании строки подключения для MongoDB необходимо кодировать специальные символы. На шаге 1 выберите Java из раскрывающегося списка ДРАЙВЕР, а затем из раскрывающегося списка ВЕРСИЯ. Если вы выберете драйвер и версию, служба автоматически обновит строку подключения на шаге 2.
Кластеризация MongoDB: отличный вариант для высокой пропускной способности
Используя кластеризацию MongoDB , вы можете удовлетворить высокие требования к пропускной способности, доступности и пропускной способности для больших сред. Кластеры MongoDB можно настроить для поддержки широкого спектра типов наборов реплик MongoDB, от простых установок с одним узлом до высокодоступных многоузловых конфигураций.
Учебное пособие по кластеру MongoDB
Кластер MongoDB — это группа серверов MongoDB, которые работают вместе для хранения ваших данных. Кластер MongoDB может состоять как из одного сервера, так и из сотен серверов. Когда вы создаете кластер MongoDB, вы указываете количество серверов (узлов), которое вы хотите в кластере. Каждый узел в кластере MongoDB хранит подмножество ваших данных. Кластеры MongoDB предназначены для масштабирования и обеспечения высокой доступности. Вы можете в любой момент добавить узлы в кластер, чтобы увеличить его емкость или заменить отказавший узел. Когда вы удаляете узел из кластера, другие узлы перераспределяют данные из удаленного узла, чтобы данные по-прежнему равномерно распределялись по кластеру.
Простое руководство Hevo по кластеризации MongoDB — это первый шаг. Когда база данных слишком мала или слишком медленна для работы системы, операции организации продолжаются. MongoDB имеет множество расширенных функций, разработанных для облака, таких как сегментирование и репликация. MongoDB позволяет хранить несколько копий одних и тех же данных, что делает их чрезвычайно доступными. Если один сервер выходит из строя, данные с другого могут быть получены немедленно. Вы можете автоматизировать, упростить и обогатить процесс репликации данных с помощью Hevo Data. Репликация данных проста и удобна в использовании, если у вас есть доступ к нашей 14-дневной бесплатной пробной версии.
Чтобы настроить кластеры MongoDB, вы должны сначала установить все три необходимых компонента. С автоматизированной платформой Hevo без кода вы можете отслеживать все, что вам нужно сделать для бесперебойной репликации данных. Для обеспечения максимальной доступности необходимо наличие нескольких серверов конфигурации или маршрутизаторов. Когда маршрутизатор определяет, в каком сегменте находятся данные, он отправляет запросы в соответствующий кластер. В процессе создания кластеров MongoDB потребуются следующие шаги для добавления к ним осколков. В кластерной конфигурации порт 27018 используется по умолчанию для серверов сегментов. Это означает, что это шард-сервер, а не сервер конфигурации.