
Отличительные факторы Hadoop: масштабируемость с открытым исходным кодом и отказоустойчивость
Опубликовано: 2022-11-18Hadoop — это программная платформа с открытым исходным кодом для распределенного хранения и обработки больших наборов данных в кластерах компьютеров. Он предназначен для масштабирования от одного сервера до тысяч машин, каждая из которых предлагает локальные вычисления и хранилище. Вместо того, чтобы полагаться на аппаратное обеспечение для обеспечения высокой доступности, платформа предназначена для обнаружения и обработки сбоев на уровне приложений. Hadoop — это база данных nosql, поскольку она использует совершенно другую архитектуру, чем традиционная реляционная база данных. Hadoop предназначен для горизонтального масштабирования, что означает, что он может масштабироваться для размещения большего количества данных за счет добавления в кластер большего количества стандартных серверов. Hadoop также разработан с учетом отказоустойчивости, а это означает, что если сервер в кластере выходит из строя, система может продолжать функционировать без этого сервера.
Hadoop не используется для хранения данных и не требует использования реляционного хранилища; скорее, он используется для хранения огромных объемов данных на распределенных серверах. База данных Hadoop — это тип данных, а не программная система, которая обеспечивает массовые параллельные вычисления. Это тип привязки базы данных NoSQL (например, HBase), который позволяет пользователям запрашивать и искать базы данных в связанном разнообразии. РСУБД в ее нынешнем виде не сможет конкурировать с Hadoop, поскольку она способна управлять как относительными, так и транзакционными данными. Hadoop может обрабатывать любые типы данных, будь то структурированные, полуструктурированные или неструктурированные, и поддерживает широкий спектр методов. Аналитика больших данных дает предприятиям реальное конкурентное преимущество, обеспечивая более глубокое понимание. Hadoop как услуга поддерживает использование онлайн-аналитической обработки (OLAP) при обработке данных. Важно помнить, что скорость обработки данных определяется количеством запросов данных. Вы можете использовать Hadoop, например, если вам не нужны ACID-транзакции или поддержка OLAP.
Hadoop и базы данных в памяти — это две совершенно разные технологии, которые пересекаются. Они разные, но в чем-то сходятся.
Аналитические приложения, использующие SQL-on-Hadoop, сочетают устоявшиеся методы запросов в стиле SQL с более новыми элементами инфраструктуры данных Hadoop . SQL-on-Hadoop позволяет корпоративным разработчикам и бизнес-аналитикам совместно работать над кластерами Hadoop с помощью привычных SQL-запросов.
Это база данных NoSQL, которая предоставляет средства для хранения и извлечения данных. Нереляционный/не-SQL — это один из терминов, который обычно используется в этой области.
Hadoop и SQL управляют данными различными способами. SQL — это язык программирования, тогда как Hadoop — это структура компонентов в программном обеспечении. Оба инструмента полезны для больших данных, но у них есть недостатки. Платформа Hadoop может обрабатывать гораздо больший набор данных, но записывает данные только один раз.
В чем разница между Hadoop и Nosql?
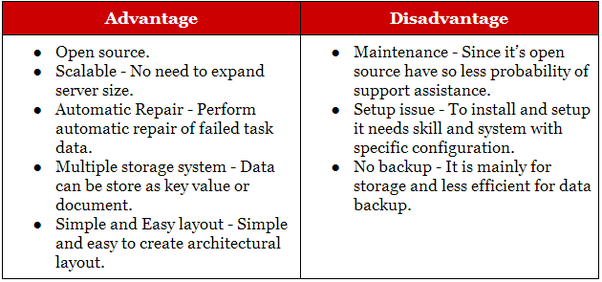
Hadoop подходит для приложений аналитического и исторического архивирования, тогда как NoSQL идеально подходит для операционных рабочих нагрузок, которые дополняют их реляционные аналоги. Базы данных NoSQL начинались как базы данных хранилища ключей и значений, но позже к ним присоединились базы данных document/json и graph.
Обработка в реальном времени, большие объемы данных и неструктурированные данные — это лишь некоторые из сценариев, в которых можно использовать технологию NoSQL. В результате некоторые из этих проблем, такие как масштабируемость и доступность, могут быть решены. База данных NoSQL имеет ряд преимуществ по сравнению с традиционной реляционной базой данных. Они могут обрабатывать наборы данных гораздо быстрее и масштабируемее, чем раньше. Системы администрирования баз данных также требуют меньше знаний и опыта, чем традиционные базы данных , что упрощает их использование. База данных NoSQL имеет ряд преимуществ по сравнению с традиционной реляционной базой данных. Самое важное, что нужно учитывать, это то, нужны ли они вам для обработки в реальном времени и больших наборов данных.
Базы данных Nosql — лучший выбор для предприятий, работающих с большими данными
Если ваши рабочие нагрузки с данными больше ориентированы на анализ и обработку больших объемов разнообразных и неструктурированных данных, таких как большие данные, базы данных NoSQL — лучший выбор. В отличие от реляционных баз данных , базы данных NoSQL не полагаются на фиксированную модель схемы. СУРБД является более гибкой, чем традиционные СУРБД, с точки зрения хранения, обработки и управления данными, что делает ее лучшим вариантом для предприятий, которым требуется возможность быстрого доступа к большим объемам данных и необходимость их хранения на неопределенный срок.
Большие данные Sql или Nosql?

Если ваши рабочие нагрузки в первую очередь связаны с быстрой обработкой и анализом больших объемов различных и неструктурированных данных, таких как большие данные, вам лучше всего подойдет NoSQL. Модель базы данных NoSQL уникальна тем, что она не использует ту же структуру схемы, что и реляционная база данных.
Вопрос больше не в том, улучшат ли большие данные производство; это вопрос времени. В больших данных доступны обширные, разнообразные и сложные объемы структурированных и неструктурированных данных. Датчики, камеры на производстве и потребительские устройства могут использоваться для сбора больших данных на производстве. Поскольку большая часть данных в производстве неструктурирована, архитектуры NoSQL не могут конкурировать с жесткими подходами, такими как SQL. База данных NoSQL не требует схем для хранения данных в одной и той же таблице базы данных, что позволяет пользователям хранить данные в различных структурах. Линия разделения компании может быть определена тем, сколько данных она намерена использовать. Транзакции должны соответствовать четырем основным принципам работы, чтобы считаться транзакцией реляционной базы данных.
Поскольку системы NoSQL и облачные системы могут быть интегрированы, рекомендуется использовать платформы облачных вычислений для поддержки систем NoSQL. Оптимизация производственного процесса в режиме реального времени с помощью NoSQL может быть достигнута за счет интеграции с системами управления производством (MES). Этот успех стал возможен благодаря использованию аналитики больших данных для более быстрого реагирования на изменяющиеся условия. MongoDB — хорошая база данных NoSQL, поскольку она проста в настройке и может использоваться для аналитики. Использование быстродействующих архитектур баз данных, таких как NoSQL, позволяет руководству лучше моделировать, что позволяет им принимать более обоснованные решения о продуктах в реальном мире. Базы данных B2B уязвимы для межсайтовых атак, а также для атак путем внедрения и атак методом грубой силы. Атака путем внедрения происходит, когда злоумышленник добавляет данные в команды запросов NoSQL или операторы хранилища.

Производственный сектор особенно обеспокоен безопасностью архитектуры NoSQL. Если атака типа «отказ в обслуживании» или атака путем внедрения успешно проведена, производитель может изменить спецификации. Благодаря этому конкуренты могут получить преимущество на высококонкурентном рынке.
Бизнес-процессы, основанные на данных в режиме реального времени, становятся все более распространенными, поскольку компании ищут способы повысить свою эффективность и способность реагировать на потребности клиентов. Облачные базы данных NoSQL, такие как Cloud Bigtable, обеспечивают быстрый и эффективный способ хранения и доступа к большим наборам данных, что делает их отличным решением для приложений такого типа.
Cloud Bigtable — это служба базы данных NoSQL, которая полностью управляема и обеспечивает безотказную работу в течение 99,999 %. Он идеально подходит для аналитических и операционных рабочих нагрузок, поскольку обеспечивает высокую скорость передачи данных и простоту масштабирования. В результате это отличный выбор для обработки данных в режиме реального времени в таких приложениях, как мобильные игры и розничная аналитика.
Является ли Nosql лучшей базой данных для больших данных?
MongoDB, например, — отличный выбор для хранения больших объемов данных. Они обеспечивают широкий спектр высокопроизводительных и гибких сценариев обработки. Кроме того, неструктурированные данные хранятся в базах данных NoSQL на нескольких узлах обработки и на нескольких серверах. В результате базы данных NoSQL стали выбором по умолчанию для некоторых крупнейших мировых хранилищ данных . Какая база данных лучше всего подходит для больших данных? Когда дело доходит до этого вопроса, невозможно предсказать, какая база данных лучше всего подходит для больших данных из-за различных потребностей организации. Amazon Redshift, Azure Synapse Analytics, Microsoft SQL Server, Oracle Database, MySQL, IBM DB2 и многие другие базы данных являются одними из самых популярных вариантов хранения больших данных.
Является ли Hadoop базой данных
Hadoop — это распределенная файловая система и платформа для запуска приложений на больших кластерах общедоступного оборудования. Hadoop — это не база данных.
Hadoop, платформа с открытым исходным кодом, позволяет эффективно хранить и обрабатывать массивные наборы данных. Таблицы Hive и Imperative можно создавать с помощью текстовых файлов в HDFS. Он поддерживает три основных формата файлов: файлы последовательности, файлы данных Avro и файлы Parquet. Последовательность байтов представлена сериализацией данных как единица памяти. Avro, эффективная структура сериализации данных, широко поддерживается Hadoop и его экосистемой.
Использование текстовых файлов в качестве формата хранения для таблиц Hive и Implicit упрощает управление данными и манипулирование ими. В результате это хороший выбор для пакетной обработки или хранения данных в различных форматах. Кроме того, сериализация данных через Avro обеспечивает эффективное и удобное хранение и извлечение данных. В результате это хороший вариант для хранения данных в различных форматах или выполнения параллельной обработки.
Hadoop против Nosql
Hadoop обрабатывает большие данные для кластера стандартного оборудования. Если функциональность не соответствует вашим потребностям или не работает, ее можно изменить. Это называется NoSQL и представляет собой тип системы управления базами данных, в которой хранятся структурированные, полуструктурированные и неструктурированные данные.
MongoDB как база данных NoSQL (не только SQL) была создана в 2007 году в результате разработки C++. Hadoop — это набор программ с открытым исходным кодом, которые в основном написаны на Java для обработки больших данных. Эта платформа также включает в себя полнотекстовый поиск, инструменты расширенной аналитики и простой в использовании язык запросов. Хотя Hadoop наиболее известен своей способностью хранить и обрабатывать большие объемы данных, он также делает это небольшими партиями. MongoDB предоставляет множество инструментов для обработки данных в реальном времени. Коннекторы MongoDB для внешних инструментов, таких как Kafka и Spark, упрощают получение и обработку данных. Когда дело доходит до обработки данных, Hadoop и MongoDB предоставляют широкий спектр преимуществ по сравнению с традиционными базами данных. Hadoop — отличный инструмент для работы с большими структурами данных благодаря своей распределенной файловой системе. MongoDB — единственная база данных, которую можно использовать вместо традиционных баз данных.
Является ли Spark базой данных Nosql
В документации указано, что NoSQL DataFrame — это Spark DataFrame, основанный на формате Spark для хранения данных. В отличие от предыдущих источников данных, этот поддерживает сокращение и фильтрацию данных (проталкивание предикатов), что позволяет запросам Spark запрашивать меньше данных и загружать только необходимые данные по мере необходимости.
При совместном использовании в приложении баз данных Apache Spark и NoSQL ( Apache Cassandra и MongoDB) крайне важно сохранять тактическую осведомленность. Этот блог посвящен тому, как использовать Apache Spark в приложении NoSQL. CassandraLand и MongoLand в TCP/IP sPark — два самых популярных аттракциона, и это отличное место для посещения, если вам нравятся тематические парки. При поиске данных Министерства энергетики наше приложение Spark начало крутиться. Вот краткий урок о том, насколько важна последовательность клавиш Cassandra, когда дело доходит до запросов. В CassandraLand также есть американские горки Partitioner. Клиенты, которым нравятся американские горки, могут поделиться своей информацией с операторами аттракционов, чтобы они могли отслеживать, кто катался на них ежедневно.
Первый урок в MongoDB Lesson 1 — это правильное управление соединениями MongoDB. Когда вам нужно обновить информацию о новом статусе членства в парке Министерства энергетики, чрезвычайно полезны индексы Mongo. Как клиент MongoDB или Spark, вы должны поддерживать правильное соединение и индексы в случае обновлений системы.