
Формат данных HDF5: привлекательный вариант для хранения больших коллекций данных и управления ими
Опубликовано: 2023-02-13HDF5 — это формат данных, предназначенный для хранения больших и сложных коллекций данных и управления ими. Он часто используется в научных и инженерных приложениях, и в последние годы его популярность растет. HDF5 не является базой данных, но его можно использовать для хранения данных в иерархическом формате , похожем на файловую систему. Это делает HDF5 привлекательным вариантом для приложений, которым необходимо хранить и управлять большими объемами данных.
Вы можете извлекать метаданные и необработанные данные из файлов HDF5 и netCDF4 и использовать потоковую передачу Hadoop для анализа данных Hadoop с помощью виртуального файлового драйвера HDF5 Connector распределенной файловой системы Hadoop (HDFS) HDF5 (VFD).
Является ли Hdf5 базой данных?
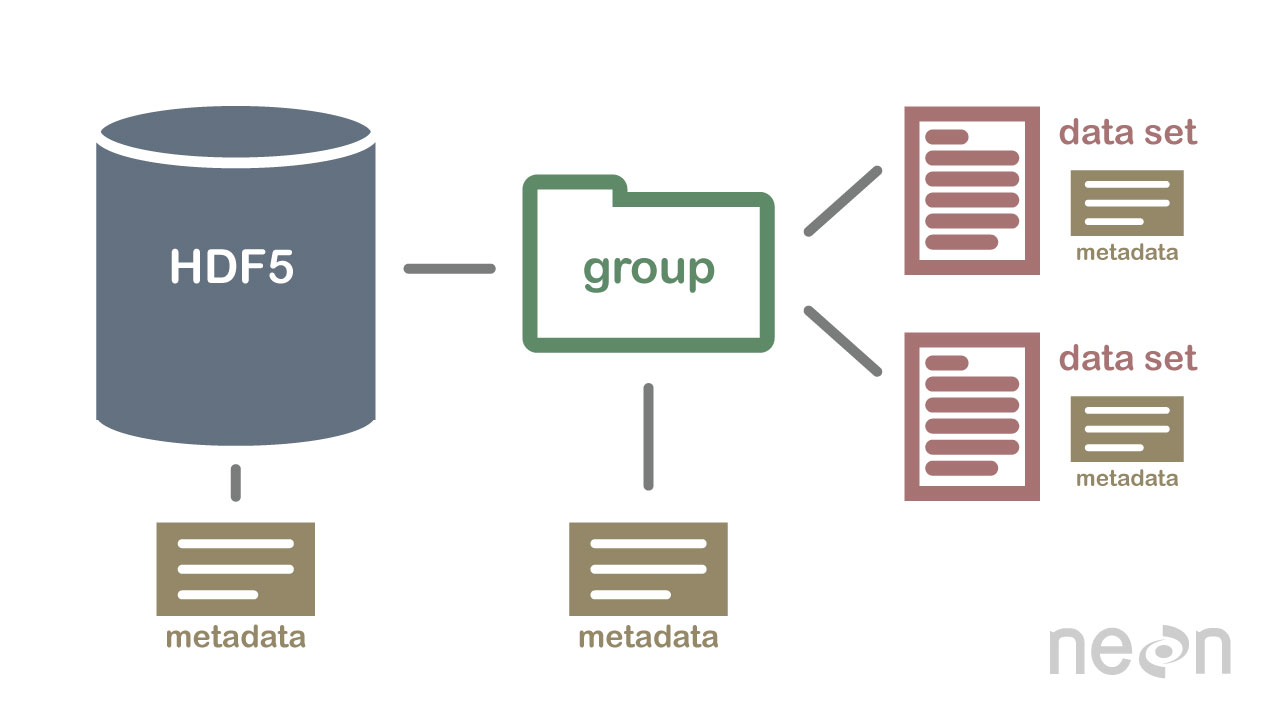
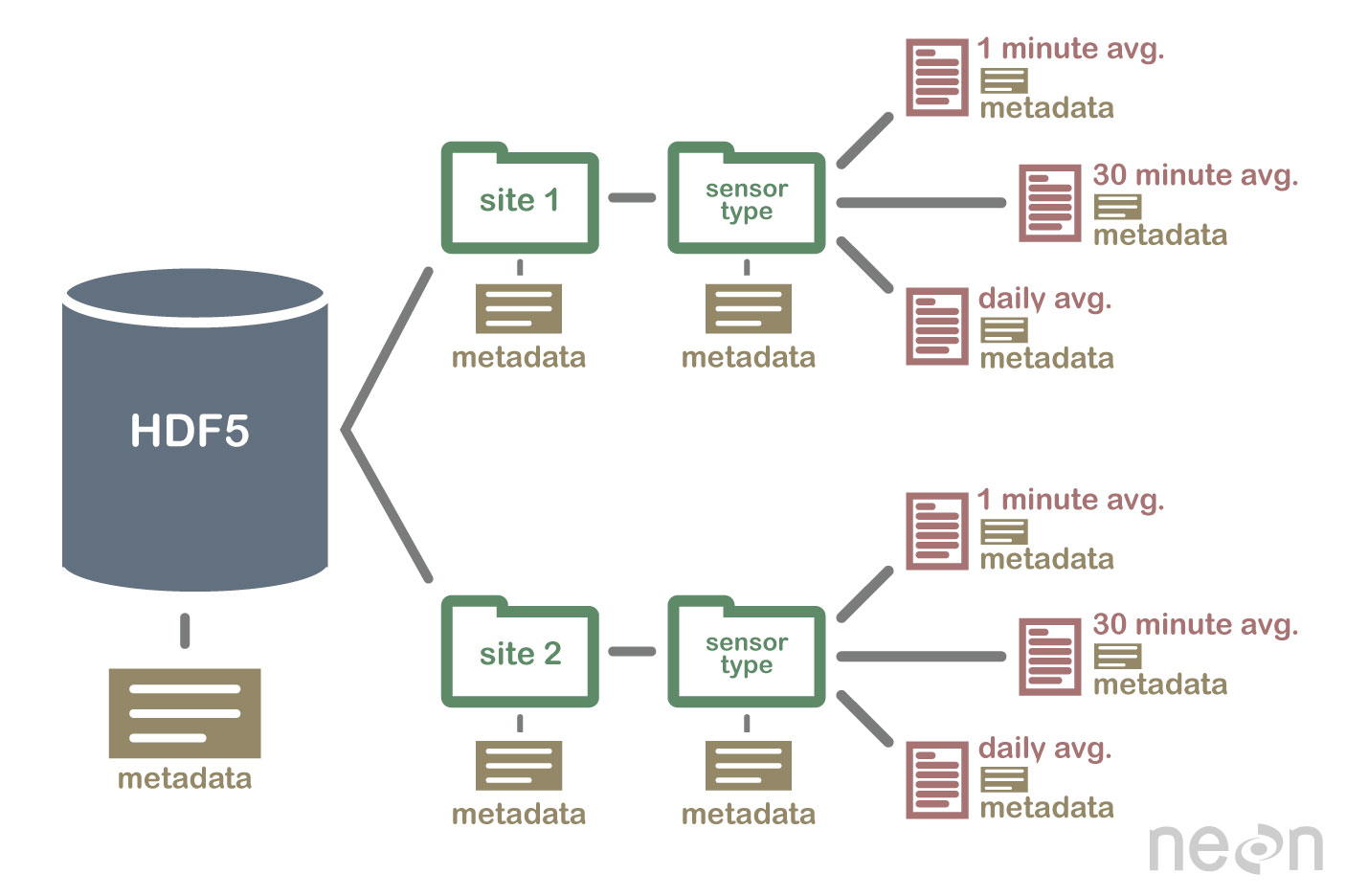
HDF5 не является базой данных, но может использоваться для хранения данных в иерархической структуре, аналогичной файловой системе. HDF5 можно использовать для хранения данных в различных форматах, включая текст, изображения и двоичные данные .
Данные в иерархическом формате (HDF5) чрезвычайно полезны в научных исследованиях. Файловая система HDF5, поскольку она похожа на файловую систему в том смысле, что она очень эффективна, является отличным форматом. Когда дело доходит до закодированных данных в этом формате, доступ к ним может быть затруднен. В этом руководстве вы узнаете, как Apache Drill может помочь вам легко получать доступ к наборам данных HDf5 и запрашивать их. У Drill есть доступ к отдельным файлам HDF5 через опцию defaultPath. Это достигается либо прямым выполнением функции table() во время запроса, либо через конфигурацию. Результаты этого запроса можно найти в таблице ниже. Затем Drill может выбрать столбцы и отфильтровать их по отдельности, отфильтровать, агрегировать или объединить с другими данными, которые он может запрашивать.
Спецификация HDF5 определяет формат файла для хранения массивов данных. Массив данных может состоять из данных любого типа, включая строковые, плавающие, комплексные и целочисленные данные. Массив может содержать данные любого размера и любой формы. В HDF5 необходимо сначала создать файл заголовка, чтобы создать набор данных. Файл заголовка включает информацию о наборе данных, а также метаданные. Файл заголовка содержит две важные части информации: имя набора данных и номер версии набора данных. Массив данных используется для хранения данных набора данных. Блоки состоят из данных в массиве данных. В массиве данных каждый блок данных содержит непрерывный набор данных. Количество блоков набора данных определяется количеством байтов в нем. Доступ к данным можно получить несколькими способами в соответствии со спецификацией HDF5. методы индексирования чаще всего используются для получения данных в наборе данных. Используя эти методы, вы можете получить доступ к данным, введя имя блока в массиве данных, к которому вы хотите получить доступ. Метод структуры можно использовать для доступа к данным в наборе данных. Когда вы используете эти методы, вы можете получить доступ к данным, используя структуру массива данных. В следующем примере вы можете получить доступ к данным в массиве данных, используя значения смещения и длины метода структуры. Другой способ получить данные из набора данных — использовать методы функций. Получить данные можно одним из способов, выбрав функцию в заголовочном файле для данных. Метод доступа к массиву данных можно использовать, определяя значение в заголовочном файле как элемент массива данных массива. Наконец, вы можете получить доступ к данным в наборе данных, используя метод доступа. Используя эти методы, вы можете получить доступ к данным, используя привилегии доступа, установленные в заголовочном файле. Другими словами, используя привилегию чтения, можно получить доступ к данным в массиве данных с помощью метода доступа. Данные можно создавать и использовать различными способами, используя спецификацию HDF5. Метод create является наиболее распространенным методом создания набора данных. Используя метод create, вы можете создать набор данных, введя имя набора данных и номер версии набора данных. Помимо спецификации HDF5, наборы данных можно использовать различными способами. Наиболее часто используемый метод.

Является ли Hdf5 реляционной базой данных?
HDF5 не является реляционной базой данных.
Graphql — Nosql или SQL?
Основная цель GraphQL — использовать систему типов для более быстрого и эффективного возврата данных. SQL (язык структурированных запросов) — более старый, более широко используемый язык для хранения данных в табличных или реляционных системах баз данных . Если вы хотите, чтобы ваш API был построен поверх базы данных NoSQL, было бы неплохо работать с GraphQL.
Несоответствие типов — это база данных GraphQL и NoSQL, созданная Германом Камареной и Роджером Кокраном. Использование GraphQL может привести к внедрению системы типов, а не системы NoSQL, что устраняет гибкость, создаваемую системами NoSQL. Коллекция GraphQL содержит большое количество документов, согласованных по структуре и содержащих несколько исключений. Поскольку GraphQL имеет встроенный набор типов данных , соответствующих типам бэкендов, разработчики могут выбирать, какие типы данных создавать. GraphQL должен решить проблему несоответствия типов, чтобы полностью реализовать свой потенциал. Что касается его функций, он обеспечивает решение несоответствия более низкого уровня благодаря своим многочисленным преимуществам. Работа становится все более и более автоматизированной с помощью таких инструментов, как JSON2SDL от StepZen.
Это мощный инструмент, который можно использовать для создания более отказоустойчивых и эффективных приложений, но SQL не заменяет его. С точки зрения обслуживания это может иметь негативные последствия, поскольку усложняет некоторые задачи.
Graphql: язык запросов для любой базы данных
Язык запросов GraphQL позволяет клиентам и серверам взаимодействовать друг с другом. Экземпляр GraphQL может извлекать и сохранять изменения либо из источника данных, либо из постоянного состояния. Преобразователь — это набор произвольных функций, которые используются для доступа к данным и управления ими. API доступен в различных базах данных, и GraphQL можно использовать с любой из них. База данных MongoDB — это популярный источник данных , который не зависит от различных типов данных.
Использует ли Nosql B-деревья?
Базы данных NOSQL не используют B-деревья, поскольку они не основаны на реляционной модели. Базы данных NOSQL часто основаны на парах ключ-значение, хранилищах документов или базах данных графов.
B-деревья — это структура индексации по умолчанию в MongoDB. В хранении данных более эффективным методом является B-дерево. Данные могут быть организованы с помощью целых чисел и строк, если они используются вместе. В результате базы данных с большим объемом данных должны рассмотреть возможность его использования. Поскольку B-деревья могут занимать много места, они являются эффективной моделью. Это полезно для баз данных, которым необходимо хранить большой объем данных. B-деревья также являются хорошим выбором для баз данных, которым необходимо организовать данные особым образом.
Какая база данных использует B-дерево?
Он существует уже давно и может использоваться в самых разных базах данных. Базы данных NoSQL могут быть построены поверх механизмов B-дерева в дополнение к механизмам B-дерева. MongoDB, например, индексирует данные в B-деревьях. Алгоритм для СУБД такой же, как и для реляционной базы данных, хотя существуют некоторые исключения. Строки и целые числа могут использоваться для организации данных в B-дереве.
Какая база данных использует B-дерево? В следующей статье Mysql использует как Btree, так и B+tree. SQL Server хранит индексы на основе сохраненных данных на основе ключей в форме BTree. В результате каждый узел в таком дереве отображается как отдельная страница.