
Почему Apache HBase — лучший выбор для вашего следующего проекта по работе с большими данными
Опубликовано: 2022-11-16Apache HBase — это нереляционная распределенная база данных с открытым исходным кодом, созданная по образцу Google Bigtable и написанная на Java. Он разработан как часть проекта Apache Hadoop Apache Software Foundation и работает поверх HDFS (распределенная файловая система Hadoop), предоставляя возможности, подобные Bigtable для Hadoop. Как и Bigtable, HBase предназначен для обработки больших объемов данных с высокой пропускной способностью и подходит для приложений, которым требуется доступ к данным с малой задержкой.
HBase, база данных NoSQL, используется для хранения и извлечения данных с произвольным доступом. Модель данных в нем динамичная и гибкая, что позволяет хранить данные любого типа без ограничений. HBase можно интегрировать с MapReduce Apache Hadoop для выполнения массовых операций (например, индексации, аналитики и т. д.). HBase — это разреженная, многомерная, отсортированная база данных на основе карты с несколькими версиями одной записи. Благодаря встроенной поддержке Hadoop MapReduce он может молниеносно и параллельно обрабатывать большие объемы данных. Архитектура HBase состоит из четырех основных компонентов: HMaster, HRegion, Hlog и HBase. ZooKeeper — это проект с открытым исходным кодом, который предоставляет несколько важных сервисов в дополнение к нескольким важным функциям.
ZooKeeper включает функцию, позволяющую выполнять распределенную синхронизацию данных конфигурации. Когда узел выходит из строя в HBase, zkQuorum генерирует сообщения об ошибках и начинает его восстанавливать. Нефть и нефть, маркетинг и реклама, банковское дело и фондовый рынок — вот лишь некоторые из областей, в которых используется HBase.
В качестве распределенной файловой системы использование HDFS в HBase имеет некоторые преимущества. Таким образом, база данных может хранить большие наборы данных, даже миллиарды строк, за короткий период времени, что позволяет проводить быстрый анализ.
Он использует нереляционный подход к управлению базой данных, ориентированный на столбцы. Информация хранится в отдельных столбцах и индексируется с использованием уникального ключа строки, уникального для каждого столбца. Эта архитектура обеспечивает быстрый и эффективный поиск отдельных строк и столбцов, а также эффективный процесс сканирования отдельных столбцов в таблице.
Apache HbaseНазвание компанииВеб-сайтДоходFacebookwww.Facebook.com117 миллиардов долларовHortonworks Incwww.hortonworks.com75 миллионовJP Morgan Chasewww.JPMorganChase.com130 миллиардов Palo Alto Networks Incwww.palo Alto
В MongoDB есть несколько типов проекций, функций фильтрации и агрегирования на выбор. В отличие от Hbase, который связывает данные со значениями ключей, значения ключей можно использовать совместно с другими приложениями. MongoDB позволяет выполнять текстовый поиск, предоставляя собственные текстовые индексы, а также репликацию данных HBase .
Является ли Hadoop базой данных Nosql?

Hadoop — это программная среда с открытым исходным кодом для хранения и обработки больших данных. Он использует распределенную файловую систему (HDFS) и MapReduce для обработки и анализа данных. Hadoop не является традиционной реляционной базой данных, но ее можно использовать для хранения и обработки данных аналогичным образом.
В MongoDB нет необходимости в документах, поскольку база данных основана на модели данных JavaScript Object Notation (JSON). Он должен быть быстрым и простым в использовании, а также иметь четко определенный индекс и возможности поиска. Алгоритм map/reduce используется для обработки массивных наборов данных в распределенной системе хранения Hadoop. Этот продукт разработан как экономичное решение для анализа и архивирования данных.
Использует ли Hbase Sql?
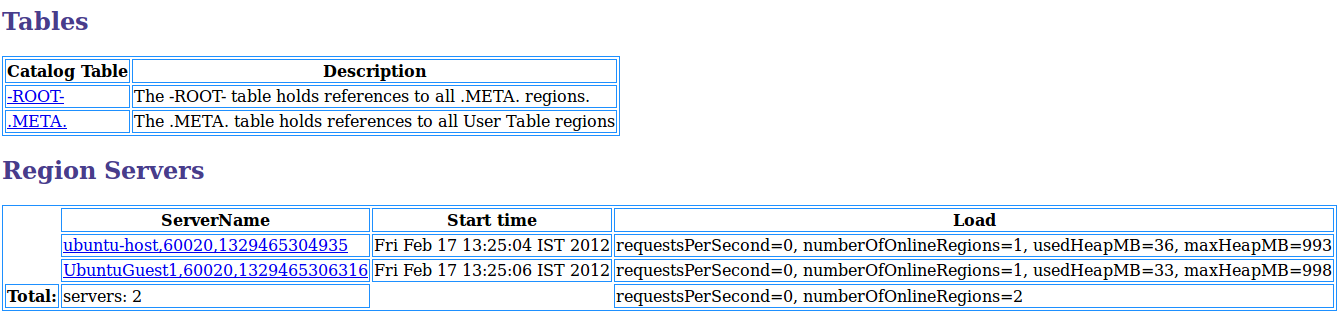
HBase не является реляционной базой данных и не использует SQL для запроса данных. HBase использует дизайн хранилища ключей и значений, оптимизированный для быстрого доступа для чтения и записи к большим наборам данных.
Благодаря своей высокой масштабируемости, поддержке программирования с уменьшением карты Hadoop и реализации известного официального документа Google BigTable, HBase является отличным выбором для хранения неструктурированных данных. Простота использования HBase является основным преимуществом для приложений хранилища, которым необходимо быстро обрабатывать большие объемы данных.
Что такое язык запросов Hbase?
Язык запросов Jaspersoft HBase, который является декларативным языком в стиле JSON, позволяет вам указать, какие данные извлекать из HBase. При использовании интерфейса HBase REST Server коннектор преобразует запрос в подходящий вызов API, который затем выполняется на экземпляре HBase .
Преимущества использования таблицы Hbase
Что такое семейство столбцов? Семейство столбцов может относиться к набору столбцов с общим именем и типом данных. Имена сотрудников могут включать столбцы идентификатора, имени, нанятого_на, уволенного_на. Каковы преимущества использования таблиц HBase ? Таблица HBase обеспечивает следующие преимущества: Структура HBase, ориентированная на столбцы, упрощает хранение разреженных или неструктурированных данных и доступ к ним. Благодаря своей отказоустойчивости HBase может противостоять случайной потере или повреждению данных. Поскольку HBase очень прост в использовании, вы можете быстро приступить к работе с хранилищем больших данных. Поскольку HBase — это масштабируемость, вы можете добавить в свой кластер больше серверов для обработки больших наборов данных.
Для чего не подходит Hbase?
Такие функции, как SQL, нельзя выполнять с помощью HBase HBase . Поскольку он не поддерживает структуру SQL, оптимизация запросов отсутствует. HBase интенсивно использует ЦП и память, с большим последовательным доступом к вводу или выводу, тогда как задания Map Reduce обычно связаны вводом или выводом с фиксированной памятью и интенсивно используют ЦП и память.
Hbase: лучшее решение для хранения данных для операций случайного чтения и записи
Он идеально подходит для приложений, выполняющих как операции произвольного чтения, так и операции произвольной записи, а также для тех, которые используют операции произвольного чтения и записи. HBase также является хорошим выбором для приложений, которым требуется доступ к данным в реальном времени.
Hbase похожа на Кассандру?

В отличие от Cassandra, которая работает на нескольких серверах и версиях одного и того же файла, Hbase работает на одном сервере данных. В результате доступ к чтению Hbase проще, чем к чтению Cassandra. Данные Hbase хранятся в HDFS, где они имеют фильтры Блума и кэши блоков, которые позволяют выполнять более быстрое чтение.
Эти базы данных NoSQL, которые могут обрабатывать большие наборы данных, были созданы Cassandra и HBase. Они имеют много общих характеристик, в том числе общие черты. На первый взгляд, они оба различны. В этой статье мы рассмотрим, чем HBase и Cassandra отличаются с точки зрения задействованных факторов. У Cassandra, как и у HBase, есть инфраструктура Hadoop , но при этом разные СУБД и инфраструктура. Cassandra не требует дополнительных вычислительных мощностей. Индексирование с помощью фильтров Блума — это то, что делает HBase.
Используя Cassandra, можно реплицировать несколько строк с одного адреса WAN со случайными разделами. Предпочтительнее иметь один источник данных, а не несколько источников данных о Cassandra. Кроме того, установка Cassandra Cluster проще, чем установка HBase Cluster .
Hbase против Cassandra: что лучше?
И Cassandra, и HBase можно читать и записывать одновременно, но Cassandra работает быстрее. Кроме того, Cassandra быстрее, чем HBase.
Hbase против Mongodb
При сравнении HBase и MongoDB нет явного победителя. Обе системы имеют свои сильные и слабые стороны. HBase лучше подходит для обработки больших объемов данных, а MongoDB более гибкий и простой в использовании.
После 4 лет работы с Couchbase мы перешли на MongoDB, и переход прошел гладко. Несмотря на получение корпоративной поддержки, у нас был ужасный опыт работы с Couchbase. При полнотекстовом поиске часто возвращаются результаты нескольких типов, если вы выполняете множество запросов. В Windows нет возможности правильно настроить индексы. Рабочий сервер может поддерживать до шести пользователей. Помимо обработки кэша в памяти, в Couchbase включен меньший экземпляр Memcached. Каждый из 5000 документов занимает 8 ГБ оперативной памяти. В этом нет никаких сомнений! В экземпляре Couchbase было менее 5000 документов, менее 20 индексов, а потребление оперативной памяти всегда превышало 8 ГБ.
Основное различие между Amazon DynamoDB и Apache HBase заключается в том, что Amazon DynamoDB построен на основе HDFS, которая обеспечивает быстрый поиск (и обновление) записей для больших таблиц. Распределенная файловая система, такая как HDFS, идеально подходит для хранения больших файлов. HBase, с другой стороны, построен на основе HDFS и может легко выполнять поиск записей (и обновление) для больших таблиц.
Кроме того, Amazon DynamoDB представляет собой хранилище ключей и значений и документов, в отличие от Apache HBase, который представляет собой хранилище ключей и значений и документов. Для более полного сравнения Amazon DynamoDB и Apache HBase в качестве хранилищ данных NoSQL рассмотрим модель данных «ключ-значение» для Amazon DynamoDB.

Hbase против Mongodb: какая база данных лучше?
С HBase легко хранить и запрашивать большие объемы данных. Эта облачная система адаптируема, надежна и обладает рядом уникальных функций, которые делают ее идеальным выбором для широкого круга предприятий. MongoDB — отличная база данных NoSQL для приложений, интенсивно использующих память, но Hadoop обеспечивает лучшее управление пространством.
Hbase против Кассандры
Платформа Hbase используется для хранения данных в больших базах данных, тогда как платформа Cassandra может использоваться для приема и хранения больших объемов данных. В режиме реального времени лучше всего использовать Cassandra для интерактивной обработки данных и транзакций.
(Хранилище) Cassandra и Hbase — в чем разница? Apache Cassandra считается системным классом NoSQL, поскольку он предназначен для создания наиболее стабильных и масштабируемых репозиториев массивов данных. Пользователи Cassandra могли внести свой вклад в сообщество, используя его компонент с открытым исходным кодом, что позволило им обсудить все проблемы и вопросы. Система управления базами данных Cassandra чрезвычайно эффективна. Разработчики смогут воспользоваться возможностями нескольких многоядерных машин. Столбец Cassandra содержит вес предпочтения пользователя в строках. Инфраструктура Hadoop, включающая Zookeeper, мастер Hbase, узлы данных и узлы имен, используется для запуска Hbase.
Cassandra использует специальный язык запросов и язык CQL, созданный по образцу SQL. Протокол Zookeeper используется для сбора данных другими узлами. Cassandra, с другой стороны, лучше подходит для крупномасштабного приема и хранения данных, чем Hbase, который используется для хранения небольшой информации в больших базах данных.
Почему Cassandra — лучшее решение Nosql для Netflix
В мире Cassandra и HBase они сильно отличаются. Архитектура HBase предназначена только для поддержки управления данными, тогда как архитектура Cassandra предназначена для поддержки хранения данных и управления ими, не полагаясь на какую-либо другую систему.
В настоящее время HBase используется несколькими организациями и всеми для внутреннего использования. Когда нам нужен магазин NoSQL, он может решить широкий спектр проблем и предоставить множество уникальных решений. Решения для хранения NoSQL от HBase — лучшие на рынке.
Cassandra, помимо того, что является компонентом инфраструктуры для глобально распределенного потокового сервиса Netflix, также доступна на веб-сервисах Amazon.
База данных Apache
HBase — это распределенное хранилище с открытым исходным кодом, ориентированное на столбцы, созданное по образцу Google Bigtable. Подобно тому, как Bigtable использует распределенное хранилище данных, предоставляемое файловой системой Google, HBase предоставляет возможности, подобные Bigtable, поверх Hadoop и HDFS. Функции HBase включают линейную и модульную масштабируемость, стабильные операции чтения и записи с малой задержкой, а также автоматическое и настраиваемое сегментирование таблиц.
Hadoop хранит и обрабатывает огромные объемы данных, используя распределенную файловую систему и MapReduce. HBase, распределенная база данных, ориентированная на столбцы, построена поверх Hadoop. Проект имеет открытый исходный код и горизонтально масштабируется. Большая таблица Google, похожая на Google, обеспечивает произвольный доступ к структурированным данным. HBase, с другой стороны, расположен поверх файловой системы Hadoop и обеспечивает доступ для чтения и записи к файловой системе. Файловая система HDFS может использоваться для хранения данных либо напрямую, либо через HBase. HBase, столбцовая база данных, структурирована таким образом, что строки сортируются. В таблице может быть несколько семейств столбцов, и в каждом семействе столбцов может быть несколько столбцов.
Хадуп против. Hbase
Hadoop более эффективно обрабатывает большие разреженные наборы данных. Когда данные обрабатываются в режиме реального времени, возможности обработки HBase превосходят возможности других платформ.
Hbase против улья
Hive и HBase — это две разные технологии, которые работают в Hadoop. Hive — это SQL-подобный движок, который запускает задания MapReduce, а HBase — это база данных типа «ключ-значение» NoSQL. Hive — это надежный механизм запросов, который позволяет выполнять запросы в режиме реального времени, тогда как HBase — это надежный механизм запросов, который позволяет выполнять запросы в режиме реального времени.
Apache Hadoop и Apache HBase — это две разные технологии работы с большими данными, которые практически во всех случаях могут служить различным целям. Каждая технология, с точки зрения систем больших данных, должна сочетаться друг с другом. В чем разница между Hive и HBase? Apache Hadoop MapReduce и HBase можно комбинировать для создания базы данных NoSQL. Одной из самых больших лазеек в HBase является отсутствие сервисов, что допускает возможность произвольного доступа. Также известно горизонтальное масштабирование с использованием готовых региональных серверов, высокая доступность, согласованность и только низкая задержка в спектре базы данных No SQL. Hadoop используется двумя разными способами: Hive и HBase. Hive — это механизм, похожий на SQL, который запускает задания MapReduce, тогда как HBase — это база данных NoSQL с ключами и значениями. Вместо того, чтобы иметь конкурента, эти две технологии должны сотрудничать.
Hive или Hbase для вашего следующего проекта данных?
Улей существует уже давно. Есть некоторые преимущества использования HBase по сравнению с другими хранилищами данных на рынке, но он все еще находится в зачаточном состоянии. Hive — популярный выбор для развертывания хранилища данных во многих организациях. Это отличный выбор для ситуаций, когда вам не нужны все функции базы данных NoSQL, но все же требуется хранилище NoSQL. Решения для хранения NoSQL от HBase — лучшие на рынке.
Кассандра Носкль
Cassandra — это мощная база данных NoSQL, которая идеально подходит для приложений, требующих высокой доступности и горизонтальной масштабируемости. Cassandra проста в использовании и предоставляет надежный набор функций, которые делают ее идеальным выбором для самых разных приложений.
Apache Cassandra — это широко доступный проект сообщества Apache, который находится в свободном доступе. Apache Cassandra обеспечивает хранение и управление высокоскоростными структурированными и неструктурированными данными на нескольких обычных серверах. Cassandra, работающая совместно с Google Bigtable и Amazon Dynamo, позволяет пользователям управлять базами данных из любого места. Он предлагает высокий уровень доступности и лишен каких-либо серьезных проблем. Cassandra была развернута некоторыми из крупнейших ИТ-компаний. Каждый день Instagram загружает в базу данных Cassandra около 80 миллионов фотографий. Он состоит из Apache Cassandra и MongoDB. Многоузловой кластер Cassandra — это очень простой способ легко масштабировать Cassandra для удовлетворения внезапного роста спроса.
Кассандра - это Nosql?
База данных NoSQL, такая как Cassandra, может быть распространена. Базы данных NoSQL легкие, с открытым исходным кодом, нереляционные и достаточно распределенные по своей структуре. Их отличает возможность горизонтального масштабирования, а также возможность гибкого определения схем.
MongoDB Nosql
Модели документов в MongoDB не являются реляционными, что делает их базой данных. Она отличается от традиционных реляционных баз данных, таких как Oracle, MySQL и Microsoft SQL Server, тем, что является так называемой базой данных NoSQL (NoSQL = Not-only-SQL).
MongoDB — одна из наиболее широко используемых баз данных NoSQL, которая может хранить данные в формате JSON. Производительность, масштабируемость и доступность MongoDB аналогичны другим языкам сценариев/аналитики баз данных, таким как SQL, Oracle и Oracle. Цель этой главы — объяснить основные концепции и типы NoSQL.
Какой тип Nosql представляет собой MongoDB?
База данных документов состоит из нескольких ключей, связанных между собой сложной структурой данных. Документ может быть вложенным, а также содержать различные пары ключ-значение, пары ключ-массив и т. д. MongoDB как база данных документов очень похожа на Google Docs.
Является ли MongoDB лучшим Nosql?
Третьей лучшей базой данных NoSQL является MongoDB, которая предназначена для использования в качестве базы данных документов общего назначения. Поскольку он ориентирован на документы, он может организовать всю вашу информацию в одном месте, упрощая доступ ко всей информации по одной теме.
Какая база данных лучше для вас?
В конце концов, нет явного победителя между двумя базами данных, каждая из которых имеет сильные и слабые стороны. База данных должна быть адаптирована к вашим конкретным потребностям и предпочтениям.
Как работает MongoDB Nosql?
MongoDB — это бесплатная база данных NoSQL. Будучи нереляционной базой данных, она может обрабатывать структурированные, полуструктурированные и неструктурированные данные, а также файлы любого формата. Используются документно-ориентированная модель данных и неструктурированный язык запросов. Чрезвычайно гибкая MongoDB может хранить и комбинировать несколько типов данных.
MongoDB: лучший выбор для больших и малых компаний
MongoDB — отличный выбор для критически важных приложений, поскольку она может масштабироваться и обладает отличной производительностью. В результате Netflix, Uber и Airbnb входят в число компаний, которые годами используют его для поддержки своих самых ресурсоемких и крупных приложений.
Платформа MongoDB упрощает использование для стартапов и малого бизнеса. Кроме того, он хорошо подходит для облачного хранилища, позволяя компаниям увеличивать или уменьшать масштаб по мере необходимости.