
Bigtable ของ Google: ที่เก็บข้อมูลเชิงคอลัมน์ที่ใช้กันอย่างแพร่หลายมากที่สุด
เผยแพร่แล้ว: 2022-12-19Bigtable เป็นที่เก็บข้อมูลเชิงคอลัมน์ที่สร้างโดย Google ออกแบบมาเพื่อจัดการข้อมูลจำนวนมากโดยมีความยืดหยุ่นสูง Google ใช้ Bigtable มานานกว่าทศวรรษ และเป็นพื้นฐานสำหรับบริการต่างๆ ของบริษัท เช่น Gmail, Google Maps และ YouTube แม้ว่า Bigtable จะไม่ใช่ที่เก็บข้อมูลที่เน้นคอลัมน์เป็นที่แรก แต่ก็เป็นที่เก็บข้อมูลที่ใช้กันอย่างแพร่หลายและเป็นที่รู้จักมากที่สุด
ในบทความนี้ เราจะตรวจสอบโมเดลพื้นที่เก็บข้อมูล NoSQL สามมิติที่พัฒนาโดย Bigtable ในการตรวจสอบว่ามีโครงสร้างถูกต้อง ก่อนอื่นเราจะดูวิธีการนำไปใช้ในแง่ทฤษฎี จากนั้นจึงใช้ไคลเอนต์ Node.js เพื่อดำเนินการดังกล่าว โมเดลพื้นที่เก็บข้อมูลใน Bigtable แตกต่างจากวิธีที่คุณอาจพบในฐานข้อมูลที่คล้ายกัน สามารถเรียงลำดับเซลล์หลายเซลล์ในแถว/คอลัมน์ร่วมกันได้โดยการประทับเวลาต่อเซลล์ แทนที่จะบันทึกเซลล์ตามลำดับโดยพลการ แต่ละเซลล์มีค่าและประทับเวลาเพื่อให้แน่ใจว่าเซลล์จะถูกบันทึกตามลำดับ สำหรับตัวอย่างนี้ เราจะใช้ Node.js และ JavaScript ธรรมดาเพื่อสร้าง Google Cloud Bigtable ในบทความนี้ เราจะกล่าวถึงวิธีการสร้าง อินสแตนซ์ Bigtable ใหม่ โดยใช้รหัส
เราเริ่มต้นด้วยการสร้างสภาพแวดล้อมที่สะอาด อ่านและเขียนบนนั้น จากนั้นจึงทำลายมันลง เมื่อเรียกใช้โค้ดโดยใช้ไคลเอ็นต์ Node.js Bigtable ไคลเอ็นต์ Node.js Bigtable อาจทำให้เกิดข้อผิดพลาด aPermission Denied และสร้างลิงก์เพื่อเปิดใช้ Cloud Bigtable Admin API คุณควรสร้างบัญชีบริการแยกต่างหากในโครงการ GCP เพื่อจัดการบทบาทผู้ดูแลระบบ Bigtable ในการสร้างตาราง Bigtable เราต้องสร้างอินสแตนซ์ของฐานข้อมูลและกลุ่มของตารางก่อน เพียงกำหนด ID ตารางและตระกูลคอลัมน์ในไคลเอ็นต์ Node.js เพื่อทำสิ่งนี้ คุณก็พร้อมดำเนินการ สามารถสร้างแถวอย่างง่ายได้โดยใช้ Bigtable ในฐานข้อมูล วิธีเดียวในการสืบค้นข้อมูลคือการใช้แป้นแถวเพื่อค้นหาแถวที่ต้องการหรือกลุ่มของแถว
แม้ว่าเวลาในการส่งผ่านข้อมูลจะไม่มีผลต่อลำดับของเวอร์ชันที่จัดเก็บ แต่ก็มีผลกับวิธีการจัดเก็บ ไม่จำเป็นต้องระบุคีย์ทั้งแถว แค่คำนำหน้าก็เพียงพอแล้ว เมื่อคุณต้องการสอบถามหลายแถวจาก Bigtable ฉันแนะนำให้ใช้การสตรีมเสมอ เมื่อใช้การสตรีม Bigtable ไม่ต้องบัฟเฟอร์ข้อมูลบนเซิร์ฟเวอร์ก่อนส่งแถว ทำให้ประสิทธิภาพเร็วขึ้น สามารถใช้ตัวกรองเพื่อจำกัดเวอร์ชันของเซลล์ โดยส่งคืนเฉพาะคอลัมน์ที่มีชื่อตระกูลเฉพาะหรือคอลัมน์ที่มีเกณฑ์คุณสมบัติเฉพาะเท่านั้น สิ่งนี้มีประโยชน์อย่างยิ่งหากคุณมีหลายเวอร์ชันที่จะเก็บไว้ แต่เฉพาะเวอร์ชันล่าสุดเท่านั้นที่จำเป็นสำหรับวัตถุประสงค์เฉพาะ โดยหลักแล้วตัวกรองจะใช้เพื่อลดปริมาณข้อมูลที่สืบค้นและส่งเพื่อปรับปรุงประสิทธิภาพการสืบค้น
กล่าวอีกนัยหนึ่ง Cloud Bigtable คือ ฐานข้อมูล NoSQL ที่ออกแบบมาสำหรับปริมาณงานด้านการวิเคราะห์และการดำเนินงาน ระบบฐานข้อมูลนี้เป็นไฮบริดข้ามแพลตฟอร์มที่ใช้ Hadoop แทน HBase ซึ่งใช้ฐานข้อมูลแบบคอลัมน์ สามารถใช้ cloud bigtable เพื่อขับเคลื่อนแอปพลิเคชันที่มีทรูพุตและความสามารถในการปรับขนาดสูง โดยมีความจุน้อยกว่า 10 MB
Apache Cassandra, ScyllaDB, Apache HBase, Google BigTable และ Microsoft Azure CosmosDB เป็นตัวอย่างของร้านค้าแบบกว้าง
ตารางไม่เหมือนกับฐานข้อมูลเชิงสัมพันธ์ในแง่ของการจัดเก็บคีย์/ค่า สามารถทำธุรกรรมได้เพียงครั้งเดียว และไม่รองรับการรวม
Google Bigtable เป็นฐานข้อมูล Nosql หรือไม่
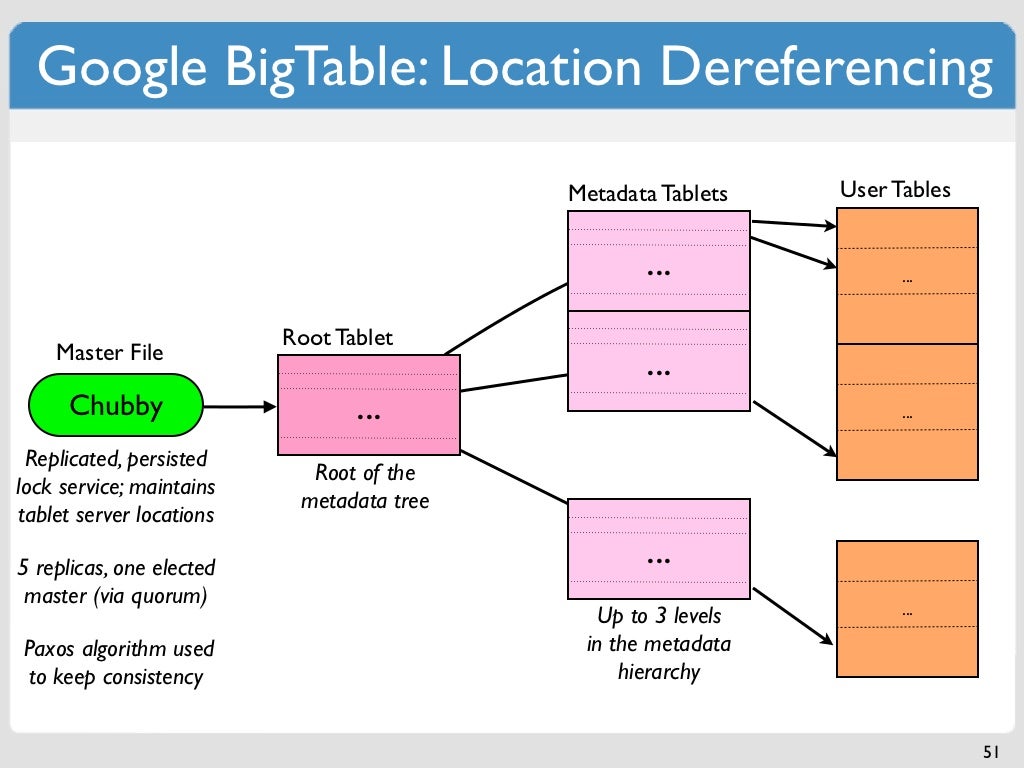
Google Bigtable เป็นฐานข้อมูล NoSQL ที่ออกแบบมาเพื่อจัดเก็บและจัดการข้อมูลจำนวนมาก Bigtable เป็นฐานข้อมูลเชิงคอลัมน์ ซึ่งหมายความว่าข้อมูลจะถูกจัดระเบียบเป็นคอลัมน์แทนที่จะเป็นแถว ทำให้เหมาะสำหรับการจัดเก็บข้อมูลที่เปลี่ยนแปลงตลอดเวลา เช่น บันทึกการใช้เว็บหรือข้อมูลโซเชียลมีเดีย นอกจากนี้ Bigtable ยังปรับขนาดได้สูง ซึ่งหมายความว่าสามารถจัดการข้อมูลจำนวนมากได้อย่างง่ายดาย
ฐานข้อมูล NoSQL นี้สามารถจัดเก็บประเภทข้อมูลได้หลากหลายและมีความเสถียรสูง นอกจากนี้ยังจัดการทั้งการแบ่งส่วนย่อยและการจำลองแบบ เพื่อให้มั่นใจว่าฐานข้อมูลมีความพร้อมใช้งานสูงและเชื่อถือได้ แอปพลิเคชันของ Google จำนวนมากใช้แอปพลิเคชันนี้ รวมถึง Google Analytics, การจัดทำดัชนีเว็บ, MapReduce และ Google Maps, Google หนังสือ, ประวัติการค้นหาของฉัน, Google Earth, Blogger.com, Google Code Hosting และ Google สำหรับแอปพลิเคชันที่ต้องการฐานข้อมูลที่สามารถจัดการข้อมูลขนาดใหญ่ จำนวนรายการข้อมูล Datastore เป็นตัวเลือกที่ดี
ข้อมูลการสั่งซื้อใดที่จัดเก็บไว้ใน Bigtable?
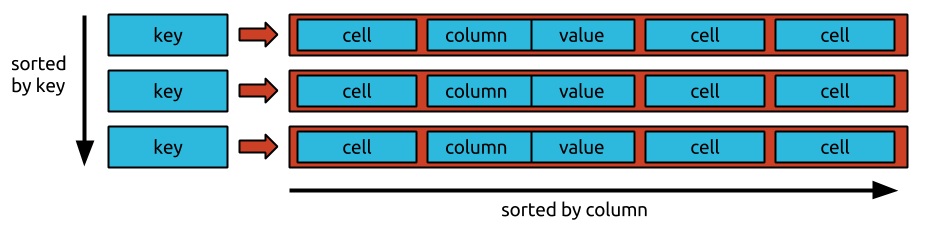
ไม่มีลำดับเฉพาะในการจัดเก็บข้อมูลในตารางขนาดใหญ่ ข้อมูลจะถูกจัดเก็บไว้ในลำดับแบบสุ่ม ซึ่งทำให้ยากต่อการเข้าถึงข้อมูลเฉพาะ
Bigtable ของ Google: ไม่ใช่แค่การจัดเก็บข้อมูลเท่านั้น
ไม่สามารถวางข้อมูลในลำดับเฉพาะใดๆ ภายใน igtable เนื่องจาก Bigtable เป็นฐานข้อมูลเชิงแถว ข้อมูลทั้งหมดภายในแถวจึงถูกจัดระเบียบเป็นคอลัมน์ ตามด้วยคอลัมน์ เนื่องจากข้อมูลถูกจัดเก็บตามลำดับเวลาย้อนกลับ การขอค่าล่าสุดจึงง่ายและรวดเร็ว แต่การขอค่าที่เก่าที่สุดทำได้ยากและใช้เวลานาน
ข้อมูลของคุณจะถูกเก็บไว้ใน Colossus ซึ่งเป็นระบบไฟล์ภายในที่ใช้งานได้ยาวนานของ Google ซึ่งอยู่ภายในศูนย์ข้อมูลของ Google อันเป็นผลจากการใช้ Colossus ของ Bigtable Bigtable ใช้งานได้ฟรี และคุณไม่จำเป็นต้องใช้คลัสเตอร์ HDFS หรือระบบไฟล์อื่นใด
แบบสอบถามไปยังแหล่งข้อมูลภายนอกสามารถดำเนินการได้โดยไม่ต้องสร้างตารางถาวรด้วยคำสั่งรวม: ไฟล์ข้อกำหนดตารางที่มีแบบสอบถาม มีข้อกำหนดสคีมาแบบอินไลน์และแบบสอบถาม ไฟล์ข้อกำหนดสคีมา JSON พร้อมคำค้นหา
Bigtable Vs Datastore
มีความแตกต่างที่สำคัญบางประการระหว่าง Bigtable และ Datastore อย่างแรก Bigtable เป็นที่เก็บข้อมูลแบบคอลัมน์ ในขณะที่ Datastore เป็นแบบแถว ซึ่งหมายความว่าใน Bigtable ข้อมูลจะถูกจัดระเบียบเป็นคอลัมน์ ในขณะที่ Datastore จะถูกจัดระเบียบเป็นแถว ประการที่สอง Bigtable ไม่มีแนวคิดของการทำธุรกรรม ในขณะที่ Datastore มี ซึ่งหมายความว่าใน Bigtable คุณไม่สามารถย้อนกลับการเปลี่ยนแปลงไปยังสถานะก่อนหน้าได้ ในขณะที่ใน Datastore คุณทำได้ ประการสุดท้าย Bigtable ได้รับการออกแบบมาสำหรับปริมาณงานสูงและเวลาแฝงต่ำ ในขณะที่ Datastore ได้รับการออกแบบมาสำหรับความพร้อมใช้งานสูงและความสามารถในการปรับขนาด
ที่เก็บข้อมูลบนคลาวด์ใดที่สามารถใช้สร้างฐานข้อมูลบนคลาวด์ของ Google เนื่องจาก Bigtable รองรับปริมาณงานขนาดใหญ่ที่มีภาระงานส่วนหลังที่ซับซ้อน จึงเหมาะสำหรับองค์กรและองค์กรขนาดใหญ่ ตรงกันข้ามกับ SQL ซึ่งใช้ภาษาคิวรี GQL ที่มีข้อจำกัดมากกว่า ที่เก็บข้อมูลจะทำธุรกรรมกรดในชุดย่อยของข้อมูลที่เรียกว่ากลุ่มเอนทิตี (แม้ว่าภาษาคิวรี GQL จะเป็นแบบปลายเปิดมากกว่า) Google Cloud Datastore และ Google Cloud Bigtable เป็นสองบริการที่แตกต่างกันซึ่งมีคุณลักษณะที่แตกต่างกันหลายประการ นอกจากนี้ ข้อมูลในภาพด้านล่างสามารถช่วยคุณในการเลือกผู้ให้บริการที่เหมาะสมสำหรับคุณ คำตอบข้างต้นรวมถึงสิ่งที่กล่าวถึงในหนังสือเรียน Coursea Google Cloud Platform Big Data และ Machine Learning Fundamentals จะทำหน้าที่เป็นแนวทางสำหรับบทความนี้
ความแตกต่างระหว่าง Bigtable และ Datastore คืออะไร?
ความแตกต่างระหว่าง datastore และฐานข้อมูลคืออะไร? ทั้ง bigtable และ datastore ได้รับการออกแบบมาสำหรับการประมวลผลและการวิเคราะห์ข้อมูลปริมาณมาก ตามลำดับ ในขณะที่ datastore ได้รับการออกแบบมาสำหรับข้อมูลธุรกรรมที่มีมูลค่าสูง Datastore เรียกอีกอย่างว่าฐานข้อมูล NoSQL เนื่องจากไม่เป็นไปตามมาตรฐาน SQL แบบดั้งเดิม ทำให้สามารถเก็บข้อมูลในลักษณะที่ยืดหยุ่นและปรับขนาดได้มากขึ้น Google Bigtable เป็นที่เก็บข้อมูลประเภทใด โมเดลพื้นที่เก็บข้อมูล Bigtable เก็บข้อมูล ในตารางที่ปรับขนาดได้จำนวนมากซึ่งจัดเรียงตามคีย์และแมปค่า ตารางประกอบด้วยแถว ซึ่งแต่ละแถวจะอธิบายถึงเอนทิตีเดียว และแต่ละคอลัมน์ก็มีค่าของตัวเอง ที่เก็บข้อมูลเลิกใช้แล้วหรือไม่ เนื่องจากมีการเปิดตัว Cloud Datastore API v1beta3 จึงไม่สามารถใช้งานได้อีกต่อไป อย่างไรก็ตาม ผลิตภัณฑ์ Cloud Datastore ทำงานได้อย่างสมบูรณ์และรองรับ
ฐานข้อมูล Bigtable
Bigtable เป็นระบบจัดเก็บข้อมูลแบบกระจายสำหรับการจัดการข้อมูลที่มีโครงสร้างซึ่งได้รับการออกแบบให้ปรับขนาดเป็นขนาดใหญ่มาก: ข้อมูลระดับเพตะไบต์ในเซิร์ฟเวอร์สินค้าโภคภัณฑ์หลายพันรายการ Bigtable เป็นฐานข้อมูลแบบคอลัมน์ ซึ่งหมายความว่าข้อมูลจะถูกจัดเก็บตามคอลัมน์แทนที่จะเป็นแถว
ตารางเป็นโครงสร้างแบบเบาบางที่มีประชากรหนาแน่น โดยมีแถวและคอลัมน์ที่ยาวได้ถึงพันล้านแถว ตารางขนาดใหญ่เป็นตัวเลือกที่ยอดเยี่ยมสำหรับการจัดเก็บข้อมูลจำนวนมากโดยมีเวลาแฝงต่ำ เนื่องจากรองรับทรูพุตการอ่านและเขียนสูงที่เวลาแฝงต่ำ จึงเป็นแหล่งข้อมูลที่เหมาะสมสำหรับการดำเนินการ MapReduce เมื่อใช้ตาราง Bigtable จะมีการแบ่งพาร์ติชันเป็นบล็อกของแถวที่อยู่ติดกันซึ่งเรียกว่าแท็บเล็ต เพื่อให้การสืบค้นง่ายขึ้น ในระบบไฟล์ที่เรียกว่า Colossus ซึ่ง Google ใช้ แท็บเล็ตจะถูกจัดเก็บในรูปแบบ SSTable โหนด Bigtable เป็นชุดย่อยของแต่ละแท็บเล็ต ซึ่งเป็นส่วนหนึ่งของอินสแตนซ์ Bigtable การเพิ่มโหนดในคลัสเตอร์สามารถเพิ่มจำนวนคำขอพร้อมกันที่สามารถจัดการได้

แถวประกอบด้วยชุดของรายการคีย์หรือค่า ซึ่งเป็นชุดของตระกูลคอลัมน์ การประทับเวลาของคอลัมน์ และคีย์ Bigtable ปฏิบัติต่อข้อมูลทั้งหมดในลักษณะเดียวกัน: เป็นสตริงไบต์ดิบ เนื่องจาก Bigtable จัดเก็บการกลายพันธุ์ ตามลำดับและกระชับเป็นประจำ จำนวนการกลายพันธุ์ที่สามารถจัดเก็บได้ในเวลาที่กำหนดจึงจำเป็นต้องใช้พื้นที่จัดเก็บมากขึ้น Bigtable บีบอัดข้อมูลของคุณโดยใช้อัลกอริธึมที่ซับซ้อนซึ่งเป็นแบบอัตโนมัติ เนื่องจากการลบเป็นการกลายพันธุ์รูปแบบใหม่ จึงต้องการพื้นที่จัดเก็บเพิ่มขึ้นในระยะสั้น วิธีการจัดเก็บข้อมูลที่เป็นกรรมสิทธิ์ของ Google ช่วยให้ได้รับความทนทานของข้อมูลที่สูงกว่าการจำลองแบบสามทางมาตรฐาน HDFS นอกจากการจัดการการเข้าถึงตาราง Bigtable แล้ว คุณยังสามารถจัดการการเข้าถึงบริการ Google Cloud อื่นๆ ได้ด้วยการกำหนดบทบาทให้กับผู้ใช้ในส่วน Identity and Access Management (IAM) ของโครงการ Google Cloud ตามนโยบายการเข้ารหัสเริ่มต้นของ Google Cloud ข้อมูลทั้งหมดในระบบคลาวด์จะถูกเข้ารหัสเมื่อไม่มีการใช้งานโดยใช้ระบบการจัดการคีย์แบบแข็งแบบเดียวกับที่เราใช้สำหรับข้อมูลที่เข้ารหัสของเรา เมื่อใช้การสำรองข้อมูล คุณสามารถบันทึกสำเนาสคีมาและข้อมูลของตาราง จากนั้นกู้คืนสำเนาข้อมูลนั้นไปยังตารางใหม่ในอนาคต
บิ๊กเทเบิล VS แคสแซนดรา
Cassandra และ Bigtable ใช้วิธีการต่างๆ เพื่อพิจารณาว่าโหนดการประมวลผลใดควรดำเนินการอ่านและเขียน ใน Cassandra พาร์ติชันคีย์จะเรียกว่าคีย์ ในขณะที่ Bigtable จะเรียกว่าคีย์แถวเป็นคีย์ ลูกค้าต้องตรวจสอบนโยบายการจัดสรรภาระงานสำหรับ Cassandra ซึ่งเป็นส่วนหนึ่งของกระบวนการ
ฐานข้อมูลแบบกระจายคือฐานข้อมูลที่ใช้ร่วมกันโดยบุคคลหลายคน บริษัทนี้รวมที่เก็บคีย์-ค่าหลายมิติไว้ในระบบ ทำให้สามารถประมวลผลข้อความค้นหาหลายหมื่นรายการต่อวินาที (QPS) เป้าหมายของเอกสารนี้คือเพื่อเปรียบเทียบความแตกต่างระหว่างระบบฐานข้อมูลสองระบบ คุณสมบัติที่สำคัญของ Bigtable ได้แก่: ระบบจัดเก็บข้อมูลแบบกระจายสำหรับกระดาษข้อมูลที่มีโครงสร้างถูกสร้างขึ้น ถ้า Bigtable ระบุว่าจำเป็นต้องมีการปรับสมดุลช่วงสำหรับชุดข้อมูล โหนดการประมวลผลจะเปลี่ยนแปลงช่วงข้อมูลได้ง่าย เนื่องจากเลเยอร์การจัดเก็บแยกจากเลเยอร์การประมวลผล นอกจากนี้ยังสามารถใช้ Bigtable เพื่อสนับสนุนการจำลองแบบอะซิงโครนัสข้ามคลัสเตอร์ที่กระจายตามภูมิศาสตร์ได้ถึงสี่คลัสเตอร์ในโทโพโลยี ความทนทานต่อความผิดพลาดของ Cassandra เชื่อมโยงกับระดับความสอดคล้องที่ปรับได้
ด้วยการกำหนดค่ากลยุทธ์โทโพโลยีการจำลองแบบข้อมูล คุณสามารถกำหนดการจำลองแบบทางภูมิศาสตร์ได้ โดยทั่วไป จะใช้การตั้งค่า aQUORUM (หรือ LOCAL_QUORUM ในศูนย์ข้อมูลบางแห่ง) เพื่อให้ถือว่าประสบความสำเร็จ การตั้งค่าระดับความสอดคล้องของการดำเนินการต้องตรงกับโหนดจำลองส่วนใหญ่ที่ตอบสนองต่อโหนดผู้ประสานงาน ด้วยการใช้การกำหนดค่าศูนย์ข้อมูลและชั้นวาง แบบจำลองของ Cassandra สามารถทนต่อความเครียดได้มากกว่าเมื่อเทียบกับแบบจำลองแบบดั้งเดิม เมื่อดำเนินการอ่านและเขียน โทโพโลยีจะกำหนดว่าโหนดใดที่จำเป็นในการรับประกันความสอดคล้องกัน อินสแตนซ์ Bigtable สามารถมีคลัสเตอร์เดียวหรือกลุ่มที่มีตัวจำลองขนาดใหญ่ได้สูงสุดสี่ตัว Bigtable และ Cassandra เป็น ที่เก็บข้อมูล NoSQL ที่ จัดเก็บคอลัมน์กว้าง
ปุ่มแถวของ Bigtable ใช้เพื่อจัดเรียงข้อมูลส่วนกลางในตารางตามลำดับ โหนดของ Bigtable จะปรับสมดุลความรับผิดชอบของโหนดโดยอัตโนมัติสำหรับช่วงคีย์ หรือที่เรียกว่าแท็บเล็ต ซึ่งเป็นส่วนหนึ่งของฟีเจอร์โหนดของ Bigtable บริการ Bigtable ของลูกค้าไม่บังคับใช้ประเภทข้อมูลคอลัมน์ที่ส่ง ใน Bigtable แต่ละคอลัมน์ในตารางจะได้รับชื่อสกุล แม้ว่าข้อเท็จจริงที่ว่าตารางมักมีตระกูลคอลัมน์มากกว่า (จำนวนคอลัมน์สูงสุดต่อตารางคือ 100) แต่ละตารางต้องมีตระกูลคอลัมน์อย่างน้อยหนึ่งตระกูล การตัดกันของแป้นแถวประกอบด้วยเซลล์สองเซลล์ (ตระกูลคอลัมน์รวมกับตัวระบุคอลัมน์) ใน Cassandra และ Bigtable มีวิธีการเลือกโหนดประมวลผลสำหรับการดำเนินการอ่านและเขียน
ใน Cassandra คีย์พาร์ติชันจะถูกระบุ ในขณะที่ Bigtable จะใช้คีย์แถว นโยบายการทำโหลดบาลานซ์ที่รับรู้ถึงศูนย์ข้อมูล เช่น นโยบายแบบหลายคลัสเตอร์ ทำให้มีโอกาสเกิดข้อผิดพลาดได้ ฐานข้อมูลทั้งสองใช้วิธีที่คล้ายกันในการเขียนให้เสร็จ และได้รับการปรับให้เหมาะสมสำหรับความเร็ว ข้อมูลถูกจัดเก็บไว้ในฐานข้อมูลทั้งสองผ่านไฟล์ SSTable ที่ไม่เปลี่ยนรูป ใน Cassandra ผู้ประสานงานต้องแจ้งลูกค้าว่าการเขียนเสร็จสมบูรณ์ก่อนที่ตัวจำลองหลายตัวจะตอบสนอง การเขียนที่สำเร็จใน Bigtable สามารถยืนยันได้โดยการตอบกลับจากโหนดเดียว เนื่องจากแต่ละคีย์ของแถวถูกกำหนดให้กับโหนดเดียวเท่านั้น เซลล์ในฐานข้อมูลทั้งสองอาจไม่รวมอยู่ใน SSTable ที่ผสาน
เนื่องจากส่วนคำสั่ง WHERE ในแบบสอบถาม CQL จึงเป็นไปไม่ได้ที่จะส่งคืนมากกว่าหนึ่งแถวใน Cassandra จำเป็นต้องปรึกษาเฉพาะโหนดที่รับผิดชอบช่วงคีย์ใน Bigtable ที่โหนดการประมวลผล เป็นไปได้ที่จะจำกัดจำนวนข้อมูลที่อ่านได้ ในระหว่างขั้นตอนการบีบอัด SSTables จะถูกรวมเป็นประจำ และข้อมูลที่จัดเก็บไว้ใน Bigtable และ Cassandra จะถูกจัดเก็บไว้ในนั้น ไม่มีกฎควบคุมจำนวนเวอร์ชันการประทับเวลาสำหรับแต่ละเซลล์ แต่อาจมีขีดจำกัดขนาดแถวอื่นๆ รับประกันความคงทนของข้อมูลโดยระบบการจำลองแบบของ Colossus Bigtable เช่น Cassandra มีอินเทอร์เฟซบรรทัดคำสั่งและไคลเอนต์ไลบรารีสำหรับภาษาโปรแกรมทั่วไปหลายภาษา
แต่ละโหนดถูกกำหนด SSTable ใน Bigtable และข้อมูลที่จัดเก็บในโหนดนั้นจะให้บริการโดยโหนดนั้น เมื่อคุณปรับขนาดคลัสเตอร์ Cassandra คุณไม่จำเป็นต้องคำนึงถึงแบบจำลองพื้นที่เก็บข้อมูลเหมือนที่คุณทำกับ Bigtable ไดรฟ์โซลิดสเทต (SSD) หรือไดรฟ์ฮาร์ดดิสก์ (HDD) เป็นประเภทพื้นที่เก็บข้อมูลที่ใช้บ่อยที่สุดสำหรับ อินสแตนซ์ Bigtable ดังที่แสดงโดย Cassandra ไม่มีการสูญเสียความหนาแน่นของการจัดเก็บเพื่อให้ได้มาซึ่งความทนทานต่อความผิดพลาด เป็นไปได้ที่จะปรับขนาดอินสแตนซ์ Bigtable ให้ตรงตามข้อกำหนดปริมาณงานโดยใช้ความพยายามน้อยที่สุดและเวลาหยุดทำงานน้อยที่สุด แม้ว่าจะมีคลัสเตอร์เพียงสี่คลัสเตอร์ แต่แต่ละคลัสเตอร์สามารถสร้างขึ้นในพื้นที่คลาวด์ที่รองรับทั่วโลก Google ขอแนะนำให้คุณทดสอบประสิทธิภาพของ Bigtable ด้วยข้อมูลตัวแทนและการสืบค้นเพื่อสร้างเมตริก QPS ต่อโหนด
Cassandra ทำหน้าที่ดูแลระบบจำนวนมากโดยใช้ส่วนประกอบที่มีการจัดการของ Bigtable การสำรองข้อมูลตารางขนาดใหญ่จะสร้างสำเนาของตารางที่สามารถกู้คืนได้ ซึ่งจัดเก็บเป็นวัตถุในคลัสเตอร์ การสำรองข้อมูลใช้ทรัพยากรของโหนดน้อยกว่าและมีค่าใช้จ่ายน้อยกว่าที่เก็บข้อมูลบนคลาวด์ อีกวิธีในการสำรองข้อมูล Bigtable คือการใช้การส่งออกข้อมูลที่มีการจัดการไปยัง Cloud Storage งานบำรุงรักษาภายใน เช่น การแพตช์ระบบปฏิบัติการ การกู้คืนโหนด การซ่อมแซมโหนด การตรวจสอบการบีบอัดพื้นที่เก็บข้อมูล และการหมุนใบรับรอง SSL ล้วนได้รับการจัดการอย่างราบรื่นโดยบริการ Bigtable มีแดชบอร์ดสำหรับตรวจสอบปริมาณงานและเมตริกการใช้งานที่อินสแตนซ์ คลัสเตอร์ และระดับตารางในหน้า Bigtable Google Cloud Console คุณสามารถใช้แดชบอร์ดการตรวจสอบเพื่อดำเนินการปรับแต่งประสิทธิภาพขั้นสูง
เอกสาร Bigtable อธิบายระบบจัดเก็บข้อมูลที่รองรับการขยายขนาดจำนวนมาก แต่ละตารางในข้อมูลแบ่งออกเป็นพาร์ติชันจำนวนหนึ่ง คุณสามารถสอบถามตารางโดยใช้แป้นแถวหรือโดยใช้ช่วงของแป้นแถว กระดาษ Bigtable ยังอธิบายวิธีการกระจายงานของตารางข้ามคลัสเตอร์ของโหนด Apache Cassandra ซึ่งเป็นฐานข้อมูลแบบโอเพ่นซอร์ส ใช้แนวคิดบางอย่างจากเอกสาร Bigtable ศูนย์ข้อมูลใช้สถาปัตยกรรมโหนดแบบกระจาย ซึ่งใช้ที่เก็บข้อมูลร่วมกันระหว่างเซิร์ฟเวอร์ที่ให้บริการข้อมูล การเข้าถึงระบบการจัดเก็บข้อมูลของ Bigtable มีให้โดยใช้อินเทอร์เฟซบรรทัดคำสั่ง cbt และไลบรารีของไคลเอนต์ Bigtable มีภาษาโปรแกรมจำนวนหนึ่งนอกเหนือจาก Python ทำให้ง่ายต่อการรวมเข้ากับแอปพลิเคชัน
Datastax Astra Cassandra ของ Google เป็นบริการ: ปรับใช้และปรับขนาดได้ง่าย
DataStax Astra Cassandra as a Service ของ Google เป็นตัวเลือกที่ยอดเยี่ยมสำหรับการเรียนรู้เกี่ยวกับ Cassandra อินเทอร์เฟซผู้ใช้ของ Kubernetes Operator ทำให้การกำหนดค่า จัดการ และปรับขนาดการปรับใช้ Cassandra ของคุณเป็นเรื่องง่าย
เอกสาร Bigtable
เอกสารประกอบ Bigtable เป็นแหล่งข้อมูลที่ยอดเยี่ยมสำหรับการเรียนรู้เกี่ยวกับเครื่องมืออันทรงพลังนี้ ให้ภาพรวมของคุณสมบัติและความสามารถของ Bigtable ตลอดจนข้อมูลโดยละเอียดเกี่ยวกับวิธีใช้งาน เอกสารได้รับการจัดระเบียบอย่างดีและง่ายต่อการติดตาม ทำให้เป็นแหล่งข้อมูลที่มีค่าสำหรับทุกคนที่สนใจเรียนรู้เกี่ยวกับเครื่องมืออันทรงพลังนี้
Google Cloud Platform มีหน้าที่รับผิดชอบในการโฮสต์ ฐานข้อมูล Bigtable ของ Google ใช้งานง่าย OpenTSDB 2.1 และใหม่กว่าเมื่อใช้ร่วมกับแบ็กเอนด์ของ Google สิ่งที่คุณต้องทำคือสร้างอินสแตนซ์ Bigtable ตั้งค่าตาราง TSDB ของคุณโดยใช้เชลล์ Bigtable HBase และเริ่มต้น TSD ขณะนี้ลูกค้าของ Bigtable อยู่ในรุ่นเบต้าและอยู่ระหว่างการเปลี่ยนแปลงหลายอย่าง
เค้าโครงข้อมูลที่มีประสิทธิภาพของ Bigtable
Bigtable ยังเหมาะสำหรับการดำเนินการของ MapReduce เนื่องจากการจัดวางข้อมูลที่มีประสิทธิภาพ MapReduce จึงสามารถจัดการกับข้อมูลปริมาณมากในช่วงเวลาสั้นๆ