
Hadoop HDFS และ NoSQL: การรวมกันที่ทรงพลังสำหรับข้อมูลขนาดใหญ่
เผยแพร่แล้ว: 2023-01-05Hadoop เป็นเฟรมเวิร์กแบบโอเพ่นซอร์สที่ช่วยให้สามารถประมวลผลชุดข้อมูลขนาดใหญ่แบบกระจายทั่วกลุ่มคอมพิวเตอร์โดยใช้โมเดลการเขียนโปรแกรมอย่างง่าย HDFS คือ Hadoop Distributed File System ที่ให้วิธีการจัดเก็บข้อมูลที่ปรับขนาดได้และทนต่อข้อผิดพลาด ฐานข้อมูล NoSQL เป็นฐานข้อมูลคลาสใหม่ที่ออกแบบมาเพื่อมอบทางเลือกที่ปรับขนาดได้ ยืดหยุ่น และมีประสิทธิภาพสูงให้กับฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิม
ความแตกต่างหลักระหว่าง Hadoop และ HDFS คือ Hadoop เป็นเฟรมเวิร์กโอเพ่นซอร์สสำหรับจัดเก็บ ประมวลผล และวิเคราะห์ข้อมูล ในขณะที่ HDFS เป็นระบบไฟล์ที่อนุญาตให้ผู้ใช้เข้าถึงข้อมูล Hadoop ด้วยเหตุนี้ HDFS จึงเป็น โมดูล Hadoop
SQL และ Hadoop สามารถจัดการข้อมูลได้หลายวิธี กรอบงาน Hadoop ใช้เพื่อประกอบส่วนประกอบซอฟต์แวร์ ในขณะที่กรอบงาน SQL ใช้เพื่อประกอบฐานข้อมูล สำหรับข้อมูลขนาดใหญ่ การพิจารณาข้อดีข้อเสียของแต่ละเครื่องมือเป็นสิ่งสำคัญ แพลตฟอร์ม Hadoop เก็บข้อมูลเพียงครั้งเดียว ในขณะที่ Hadoop จัดเก็บชุดข้อมูลจำนวนมากขึ้น
Hadoop ไม่ใช่ฐานข้อมูล แต่เป็นซอฟต์แวร์ชิ้นหนึ่งที่ช่วยให้สามารถประมวลผลแบบขนานขนาดใหญ่ได้ เทคโนโลยีนี้ช่วยให้ฐานข้อมูล NoSQL (เช่น HBase) กระจายข้อมูลไปยังเซิร์ฟเวอร์หลายพันเครื่องโดยมีประสิทธิภาพการทำงานลดลงเล็กน้อย
Hadoop ไม่ได้จัดเก็บข้อมูลในลักษณะเดียวกับที่จัดเก็บข้อมูลเชิงสัมพันธ์ เซิร์ฟเวอร์แบบกระจายเป็นหนึ่งในแอปพลิเคชันที่ใช้งานมากที่สุด แม้ว่าจะเป็น ฐานข้อมูล Hadoop แต่ก็ไม่ถือว่าเป็นฐานข้อมูลเชิงสัมพันธ์ เนื่องจากจัดเก็บไฟล์ใน HDFS (ระบบไฟล์แบบกระจาย)
Nosql กับ Hdfs ต่างกันอย่างไร?
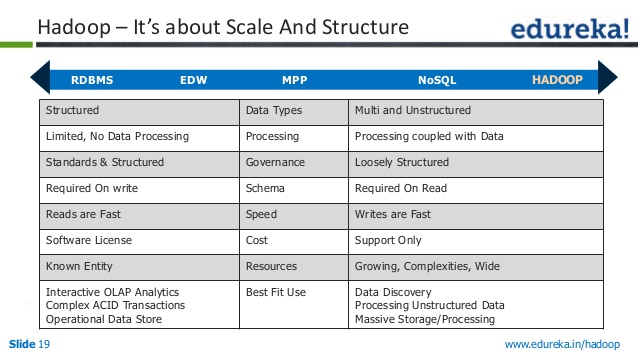
เป็นระบบไฟล์และเรียกอีกอย่างว่าระบบไฟล์ เป็นที่ชัดเจนอยู่แล้วว่าแอปนี้มีคุณสมบัติมากมาย คุณได้รับสิ่ง NOSQL นี้ที่ไหน เราจะสามารถประมวลผลข้อมูลจำนวนมากแบบเรียลไทม์ได้โดยใช้ข้อมูลนั้น เนื่องจากไม่จำเป็นต้องใช้ฐานข้อมูลเชิงสัมพันธ์หรือคุณสมบัติอื่นๆ
ตัวจัดการพื้นที่เก็บข้อมูล HBase ซึ่งทำงานใน Hadoop ให้การอ่านและเขียนแบบสุ่มที่มีเวลาแฝงต่ำ ระบบ HBase ใช้คุณลักษณะ auto-sharding ซึ่งมีการกระจายตารางขนาดใหญ่แบบไดนามิก เซิร์ฟเวอร์ภูมิภาคแต่ละแห่งมีหน้าที่รับผิดชอบในการให้บริการชุดของภูมิภาค และมีเซิร์ฟเวอร์ภูมิภาคเพียงเซิร์ฟเวอร์เดียวที่สามารถให้บริการหนึ่งภูมิภาคได้ (เช่น HMaster และ HRegion เป็นบริการหลักสองบริการที่จัดทำโดย HBase ส่วนประกอบ HRegion ของตาราง HBase มีหน้าที่รับผิดชอบในการจัดการ ส่วนย่อยของข้อมูลในตาราง เมื่อเปิด Region Server เซิร์ฟเวอร์จะถูกกำหนดให้กับแต่ละ Region ด้วยเหตุนี้ มาสเตอร์จะไม่เกี่ยวข้องกับการดำเนินการอ่านและเขียน
เมื่อต้องจัดการกับข้อมูลที่ไม่มีโครงสร้างและมีปริมาณมาก ฐานข้อมูล NoSQL เช่น MongoDB และ Cassandra โดดเด่นเหนือฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิม ธุรกิจที่มีเวิร์กโหลดข้อมูลจำนวนมาก เช่น Big Data นิยมใช้เครื่องมือเหล่านี้เพื่อประมวลผลและวิเคราะห์ข้อมูลที่หลากหลายและไม่มีโครงสร้างจำนวนมหาศาลอย่างรวดเร็ว MongoDB เก็บข้อมูลในคอลเลกชัน ในขณะที่ hadoop เก็บข้อมูล ในระบบไฟล์อื่นที่เรียกว่า HDFS เป็นข้อได้เปรียบที่จะมีสถาปัตยกรรมที่แตกต่างกันอันเป็นผลมาจากความแตกต่างนี้ การสืบค้นข้อมูลใน MongoDB ยังเร็วกว่าการค้นหาทีละไฟล์ นอกจากนี้ เนื่องจาก mongodb ได้รับการออกแบบมาสำหรับสภาพแวดล้อมที่มีปริมาณมาก จึงเหมาะสมอย่างยิ่งในการจัดการข้อมูลปริมาณมากด้วยต้นทุนที่ค่อนข้างต่ำ ขอแนะนำให้ธุรกิจที่ต้องการโซลูชัน Big Data ใช้ฐานข้อมูล NoSQL พวกเขามีข้อได้เปรียบมากมายเหนือฐานข้อมูลแบบดั้งเดิมในแง่ของความเร็วในการประมวลผลและการวิเคราะห์ และเหมาะสำหรับการวิเคราะห์และจัดการข้อมูลขนาดใหญ่
Hadoop เป็นฐานข้อมูล Nosql หรือไม่
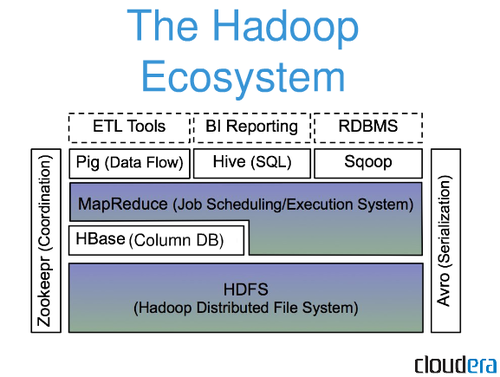
Hadoop ไม่ใช่ระบบจัดการฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิม เป็นระบบไฟล์แบบกระจายที่ช่วยในการจัดเก็บและประมวลผลชุดข้อมูลขนาดใหญ่ทั่วทั้งคลัสเตอร์ของเซิร์ฟเวอร์สินค้า Hadoop ได้รับการออกแบบมาเพื่อเพิ่มขนาดจากเซิร์ฟเวอร์เครื่องเดียวไปจนถึงเครื่องหลายพันเครื่อง โดยแต่ละเครื่องมีการคำนวณและการจัดเก็บภายในเครื่อง
การใช้ข้อมูลในระดับมหาศาลกำลังถูกปฏิวัติด้วยเทคโนโลยีใหม่ โครงสร้างพื้นฐานของข้อมูลขนาดใหญ่มีผู้เล่นมากมาย รวมถึง Hadoop, NoSQL และ Spark ขณะนี้ DBA และวิศวกร/นักพัฒนาโครงสร้างพื้นฐานทำงานให้พวกเขาเพื่อจัดการระบบที่ซับซ้อนใน DBA และวิศวกรโครงสร้างพื้นฐานสายพันธุ์ใหม่ เนื่องจาก Hadoop เป็นระบบนิเวศซอฟต์แวร์มากกว่าฐานข้อมูล จึงช่วยให้สามารถคำนวณข้อมูลจำนวนมหาศาลในอัตราที่มีประสิทธิภาพและประสิทธิผล ประโยชน์ที่ได้รับจากข้อมูลจำนวนมหาศาลที่จัดการได้เป็นตัวเปลี่ยนเกมสำหรับการประมวลผลข้อมูลขนาดใหญ่ ธุรกรรมข้อมูลขนาดใหญ่ เช่น ธุรกรรมที่ใช้เวลา 20 ชั่วโมงในการดำเนินการให้เสร็จสมบูรณ์บนระบบฐานข้อมูลเชิงสัมพันธ์แบบรวมศูนย์ สามารถทำได้ในเวลาเพียงสามนาทีบนคลัสเตอร์ Hadoop
มีภาษา SQL ให้เลือกมากกว่าหนึ่งภาษา MongoDB ซึ่งเป็นฐานข้อมูลเอกสารล้วนเป็นฐานข้อมูล NoSQL ประเภทหนึ่ง; แคสแซนดราซึ่งเป็นฐานข้อมูลแบบคอลัมน์กว้างเป็นอีกฐานข้อมูลหนึ่ง และ Neo4j ซึ่งเป็นฐานข้อมูลกราฟก็เป็นอีกอันหนึ่ง คุณลักษณะนี้สร้างขึ้นโดย SQL- on- Hadoop SQL-on-Hadoop เป็นเครื่องมือวิเคราะห์ประเภทใหม่ที่รวมการสืบค้น SQL ที่สร้างไว้แล้วเข้ากับเฟรมเวิร์กข้อมูล Hadoop SQL-on- Hadoop ช่วยให้นักพัฒนาองค์กรและนักวิเคราะห์ธุรกิจสามารถทำงานร่วมกับ Hadoop ในคลัสเตอร์คอมพิวเตอร์โภคภัณฑ์โดยอนุญาตให้เรียกใช้คำสั่ง SQL ที่คุ้นเคย ข้อดีของ SQL-on-hadoop ข้อดีมากมายของ SQL-on- Hadoop นอกเหนือจากการใช้งานง่าย ยังคุ้มค่ากับเวลาและทรัพยากรของนักพัฒนาข้อมูลองค์กรและนักวิเคราะห์ ในการเริ่มต้น พวกเขาสามารถทำงานร่วมกับ Hadoop บนคลัสเตอร์การประมวลผลสินค้าโภคภัณฑ์ ซึ่งจะช่วยให้เริ่มต้นใช้งานการวิเคราะห์ข้อมูลขนาดใหญ่ได้อย่างรวดเร็วและง่ายดาย SQL-on-Hadoop ยังช่วยให้พวกเขาใช้ประโยชน์จากการสืบค้น SQL ที่คุ้นเคย ทำให้เรียนรู้การวิเคราะห์ข้อมูลขนาดใหญ่ได้ง่ายขึ้น นอกจากนี้ SQL-on-Hadoop ยังมีฟังก์ชัน map/reduce ของ Hadoop ตลอดจนความสามารถในการวิเคราะห์ข้อมูลที่มีให้
ฐานข้อมูล Nosql เพิ่มขึ้น
ด้วยเหตุนี้ ฐานข้อมูล NoSQL จึงได้รับความนิยมมากขึ้นเนื่องจากความสามารถในการปรับขนาด ประสิทธิภาพการอ่าน/เขียน และความยืดหยุ่นของข้อมูล มีตัวอย่างที่ดีมากมายของฐานข้อมูล NoSQL ในตลาด เช่น DynamoDB, Riak และ Redis
Hive เป็นฐานข้อมูล NoSQL แบบโมดูลาร์ที่มีน้ำหนักเบาพร้อมเมตริกประสิทธิภาพที่ยอดเยี่ยม มันเขียนด้วยภาษาโปรแกรม Dart ล้วนๆ และเป็นที่นิยมในหมู่นักพัฒนาเนื่องจากความเรียบง่าย
อะไรคือความแตกต่างระหว่าง Hadoop และฐานข้อมูล?

แม้ว่า RDBMS จะไม่จัดเก็บและประมวลผลข้อมูล แต่ Hadoop จะจัดเก็บและประมวลผลข้อมูลเป็นระบบไฟล์แบบกระจายแทน ในทางกลับกัน RDBMS เป็นฐานข้อมูลที่มีโครงสร้างที่เก็บข้อมูลในแถวและคอลัมน์และสามารถอัปเดตด้วย SQL และแสดงในตารางต่างๆ
การใช้เทคโนโลยีและเครื่องมือข้อมูลขนาดใหญ่ได้เติบโตขึ้นอย่างรวดเร็ว การกระจาย Hadoop แบบโอเพ่นซอร์สทำงานบนระบบไฟล์แบบกระจาย และอนุญาตให้มีการแลกเปลี่ยนและประมวลผลชุดข้อมูลขนาดใหญ่ RDB เป็นระบบจัดการฐานข้อมูลพื้นฐานที่ใช้ในรูปแบบที่ง่ายที่สุดโดยระบบจัดการฐานข้อมูลทั้งหมด เช่น Microsoft SQL Server, Oracle และ MySQL แม้จะถูกจัดประเภทเป็นวิวัฒนาการ แต่ RDBMS ก็เหมือนกับฐานข้อมูลมาตรฐานอื่น ๆ แทนที่จะเป็นงานหลัก ไม่ใช่ฐานข้อมูล แต่เป็นระบบไฟล์แบบกระจายที่สามารถจัดเก็บและประมวลผลไฟล์ข้อมูลขนาดใหญ่ได้ แม้ว่าระบบอย่าง Hadoop จะให้ประสิทธิภาพที่ดีกว่า แต่ก็มีข้อบกพร่องบางประการที่ไม่ค่อยได้กล่าวถึง คุณต้องคิดถึงวิธีจัดการคลัสเตอร์ Hadoop, ความปลอดภัย, Presto หรืออินเทอร์เฟซอื่นๆ ที่คุณใช้
ระบบฐานข้อมูลเชิงสัมพันธ์ส่วนใหญ่ เช่น SQL Server และ Oracle นั้นใช้งานง่ายกว่ามาก องค์กรส่วนใหญ่ประสบปัญหาหลักในการไม่มีบุคลากรที่มีทักษะเพียงพอที่จะใช้งาน Hadoop ได้อย่างมีประสิทธิภาพ รวมถึงค่าใช้จ่ายด้านบุคลากรที่มีจำนวนมาก หากคุณมีพนักงาน 10,000 คน คุณจะต้องใช้ข้อมูลจำนวนมากเพื่อติดตามพนักงานทั้งหมด ข้อมูลนี้สามารถจัดเก็บได้หลายวิธีด้วย Presto สามารถใช้การแบ่งวันที่เพื่อจัดเก็บตำแหน่งของบุคคลทุกวัน ในทางกลับกัน RDBMS สามารถใช้เป็นตัวอย่างของแบบจำลองข้อมูลได้ วิธีเดียวที่จะใช้วิธีนี้คือถ้าคุณมีสิทธิ์เข้าถึงข้อมูลของวันก่อนหน้าแล้ว
อะไรคือความแตกต่างที่สำคัญระหว่างฐานข้อมูลเชิงสัมพันธ์และข้อมูลขนาดใหญ่
ความแตกต่างหลักระหว่างฐานข้อมูลเชิงสัมพันธ์และข้อมูลขนาดใหญ่คือ ฐานข้อมูลเชิงสัมพันธ์ได้รับการปรับให้เหมาะสมสำหรับการจัดเก็บข้อมูลที่มีโครงสร้าง ในขณะที่ข้อมูลขนาดใหญ่ได้รับการปรับให้เหมาะสมสำหรับการจัดเก็บข้อมูลที่ไม่มีโครงสร้างและกึ่งโครงสร้าง ฐานข้อมูลเชิงสัมพันธ์ถูกสร้างโมเดลตามโมเดลเชิงสัมพันธ์ ในขณะที่ฐานข้อมูลบิ๊กดาต้าสร้างโมเดลตามโมเดลแบบกระจาย ข้อมูลที่มีโครงสร้างสามารถจัดเก็บและประมวลผลในฐานข้อมูลเชิงสัมพันธ์ได้อย่างมีประสิทธิภาพ ตารางประกอบด้วยข้อมูลและเปิดใช้งานการเข้าถึงและเรียกค้นภาษาคิวรีที่มีโครงสร้าง (SQL) ข้อมูลขนาดใหญ่หมายถึงข้อมูลใด ๆ ที่ไม่มีโครงสร้างหรือกึ่งโครงสร้าง

อะไรคือความแตกต่างระหว่าง Hadoop และ Mongodb?
เนื่องจาก MongoDB ทำงานใน C จึงจัดการหน่วยความจำได้ดีกว่าฐานข้อมูลอื่นๆ Hadoop เป็นชุดซอฟต์แวร์ที่ใช้ Java ซึ่งมีเฟรมเวิร์กสำหรับจัดเก็บ ดึงข้อมูล และประมวลผลข้อมูล Hadoop เพิ่มประสิทธิภาพพื้นที่ได้อย่างมีประสิทธิภาพมากกว่า MongoDB
MongoDB เป็นฐานข้อมูล NoSQL (ไม่ใช่แค่ SQL) ที่สร้างขึ้นใน C. Hadoop เป็นแพลตฟอร์มซอฟต์แวร์โอเพ่นซอร์สที่ประกอบด้วย Java เป็นหลัก ซึ่งช่วยให้สามารถประมวลผลข้อมูลจำนวนมากได้ นอกจากนี้ MongoDB Atlas ยังมีการค้นหาข้อความแบบเต็ม การวิเคราะห์ขั้นสูง และภาษาสืบค้นที่ใช้งานง่าย Hadoop มีประสิทธิภาพในการจัดเก็บและประมวลผลข้อมูลจำนวนมาก แต่ทำได้ในชุดเล็กๆ MongoDB มีเครื่องมือประมวลผลข้อมูลแบบเรียลไทม์ในตัวที่หลากหลาย เนื่องจากตัวเชื่อมต่อสำหรับเครื่องมือภายนอกเช่น Kafka และ Spark ทำให้ MongoDB ทำให้การรับข้อมูลและการประมวลผลเป็นเรื่องง่าย ข้อดีของ Hadoop และ MongoDB ที่เหนือกว่าฐานข้อมูลแบบดั้งเดิมในด้านข้อมูลขนาดใหญ่นั้นมีมากมาย Hadoop ซึ่งเป็นระบบไฟล์แบบกระจายสามารถใช้เพื่อจัดการกับไฟล์ขนาดมหึมา MongoDB เป็นฐานข้อมูลเดียวที่สามารถแทนที่ฐานข้อมูลแบบดั้งเดิมในแง่ของประสิทธิภาพ
Rdbms กับ Nosql กับ Hadoop
ที่เก็บข้อมูลมีสามประเภทหลัก ได้แก่ RDBMS, NoSQL และ Hadoop พวกเขาแต่ละคนมีจุดแข็งและจุดอ่อนของตัวเอง ดังนั้นการเลือกสิ่งที่ถูกต้องสำหรับความต้องการของคุณจึงเป็นสิ่งสำคัญ
RDBMS (ระบบจัดการฐานข้อมูลเชิงสัมพันธ์) เป็นที่เก็บข้อมูลประเภทที่พบมากที่สุด ใช้งานง่ายและปรับขนาดได้ง่าย อย่างไรก็ตาม มันไม่ยืดหยุ่นเท่า NoSQL หรือ Hadoop และค่าบำรุงรักษาอาจแพงกว่า
NoSQL (ไม่ใช่แค่ SQL) เป็นที่เก็บข้อมูลประเภทใหม่ที่กำลังเป็นที่นิยมมากขึ้น มีความยืดหยุ่นมากกว่า RDBMS และสามารถปรับขนาดได้มากกว่า อย่างไรก็ตาม มันไม่ง่ายที่จะใช้และอาจมีราคาแพงกว่าในการบำรุงรักษา
Hadoop เป็นที่เก็บข้อมูลประเภทหนึ่งที่ออกแบบมาสำหรับข้อมูลขนาดใหญ่ ปรับขนาดได้มากและสามารถจัดการข้อมูลจำนวนมากได้ อย่างไรก็ตาม การใช้งานไม่ง่ายเหมือน RDBMS หรือ NoSQL และอาจมีราคาแพงกว่าในการบำรุงรักษา
แนวทางขององค์กรในการจัดเก็บ ประมวลผล และวิเคราะห์ข้อมูลสามารถปรับปรุงได้อย่างมากด้วยแพลตฟอร์ม Apache Hadoop Data Lake สามารถเรียกใช้ปริมาณงานวิเคราะห์หลายประเภทบนฮาร์ดแวร์และซอฟต์แวร์เดียวกัน ตลอดจนจัดการปริมาณข้อมูลขนาดใหญ่ ขณะนี้นักวิเคราะห์สามารถโต้ตอบกับข้อมูลได้อย่างมีประสิทธิภาพในขณะเดินทางโดยใช้เครื่องมืออย่าง Apache Impala และ Apache Spark Hadoop ซึ่งแตกต่างจาก Relational Database Management System (RDBMS) คือไม่มีความสามารถเหมือนกับฐานข้อมูล แต่เป็นระบบไฟล์แบบกระจายที่สามารถประมวลผลข้อมูลจำนวนมหาศาลแทน จำนวนข้อมูลที่สามารถประมวลผลได้ง่ายและมีประสิทธิภาพเรียกว่า Data Volume Volume กล่าวคือ เป็นกระบวนการปริมาณข้อมูลทั้งหมดในช่วงเวลาหนึ่งๆ ที่สามารถเพิ่มประสิทธิภาพได้ มีความสามารถในการจัดเก็บและประมวลผลข้อมูลจากแหล่งข้อมูลที่หลากหลายและเตรียมพร้อมสำหรับการวิเคราะห์
ในจำนวนเล็กน้อย RDBMS สามารถจัดการข้อมูลที่มีโครงสร้างและกึ่งโครงสร้างเท่านั้น Hadoop ไม่สามารถจัดการข้อมูลจากแหล่งต่างๆ หรือโครงสร้างที่มีโครงสร้างใดๆ ได้ เวลาตอบสนอง ความสามารถในการปรับขนาด และต้นทุนเป็นปัจจัยสำคัญอื่นๆ ที่ควรพิจารณา
ทำไม Rdbms ถึงยังคงเป็นระบบจัดการฐานข้อมูลที่ได้รับความนิยมสูงสุด
ระบบจัดการฐานข้อมูลที่ใช้กันอย่างแพร่หลายมากที่สุดในโลกคือ RDBMS มันมีคุณสมบัติที่หลากหลายและเชื่อถือได้อย่างมาก ฐานข้อมูลเชิงสัมพันธ์เหมาะสมที่สุดในการจัดเก็บข้อมูลที่จำเป็นสำหรับผู้ใช้หลายคนในการเข้าถึง
ฐานข้อมูล NoSQL กำลังได้รับความนิยมส่วนหนึ่งเนื่องจากข้อดีด้านประสิทธิภาพที่เหนือกว่าฐานข้อมูลเชิงสัมพันธ์ นอกจากนี้ยังช่วยให้คุณสามารถจัดเก็บข้อมูลจำนวนมากที่คุณไม่จำเป็นต้องแชร์กับผู้ใช้หลายคน
Hadoop Nosql
Hadoop เก็บข้อมูลขนาดใหญ่ไว้ในคลัสเตอร์ฮาร์ดแวร์สินค้าโภคภัณฑ์ คุณมีตัวเลือกในการเปลี่ยนฟังก์ชันที่ไม่ทำงานหรือตรงตามความต้องการของคุณหากจำเป็น ในทางตรงกันข้าม ระบบจัดการฐานข้อมูล NoSQL เป็นระบบจัดการฐานข้อมูล ประเภทหนึ่งที่ใช้ในการจัดเก็บข้อมูลที่มีโครงสร้าง กึ่งโครงสร้าง และไม่มีโครงสร้าง
เป็นฐานข้อมูล Hdfs
ระบบไฟล์ HDFS เป็นระบบไฟล์แบบกระจายที่ทำงานบนฮาร์ดแวร์สินค้าโภคภัณฑ์ สามารถกำหนดค่า คลัสเตอร์ Apache Hadoop เดียว ให้รองรับโหนดหลายร้อย (หรือแม้แต่พัน) โดยใช้คุณลักษณะนี้ Apache Hadoop ซึ่งรวมถึง MapReduce และ YARN ประกอบด้วยองค์ประกอบหลักหลายส่วน
การเข้าถึงข้อมูลที่มีประสิทธิภาพสูงมีให้โดย Hadoop Distributed File System (HDFS) ซึ่งเป็นส่วนประกอบของ ระบบปฏิบัติการ Hadoop โหนดชื่อหลักของคลัสเตอร์มีหน้าที่ติดตามตำแหน่งที่จัดเก็บข้อมูลไฟล์ของคลัสเตอร์ นอกจากการจัดการการเข้าถึงไฟล์แล้ว โหนด Name ยังจัดการการเข้าถึงไฟล์ เช่น อ่าน เขียน สร้าง ลบ และอื่นๆ Yahoo เปิดตัว Hadoop Distributed File System ซึ่งเป็นส่วนหนึ่งของข้อกำหนดตำแหน่งโฆษณาออนไลน์และเครื่องมือค้นหา โปรโตคอล HDFS เปิดเผยเนมสเปซระบบไฟล์เพื่อเก็บข้อมูลผู้ใช้ DataNodes สามารถสื่อสารระหว่างการดำเนินการกับไฟล์ปกติได้ เนื่องจากโหนดเหล่านี้สื่อสารกันเอง Hadoop Distributed File System (HDFS) เป็นส่วนประกอบของ Data Lake แบบโอเพ่นซอร์สจำนวนมาก HDFS ถูกใช้โดย eBay, Facebook, LinkedIn และ Twitter เพื่อวิเคราะห์ข้อมูลจำนวนมาก ในกรณีที่โหนดหรือฮาร์ดแวร์ล้มเหลว จำเป็นต้องมีการจำลองข้อมูลเพื่อให้ HDFS ทำงานได้อย่างถูกต้อง
ตัวอย่างฐานข้อมูล Hadoop
ฐานข้อมูล Hadoop คือฐานข้อมูลที่ใช้ Hadoop Distributed File System (HDFS) สำหรับการจัดเก็บพื้นฐาน โดยทั่วไปแล้ว ฐานข้อมูล Hadoop ใช้สำหรับจัดเก็บข้อมูลจำนวนมากที่ใหญ่เกินกว่าจะบรรจุลงในเซิร์ฟเวอร์เครื่องเดียวได้
กรอบงานโอเพ่นซอร์สสำหรับการจัดเก็บและประมวลผลชุดข้อมูลขนาดใหญ่ในรูปแบบกระจายบนฮาร์ดแวร์สินค้า Apache Hadoop ใช้ในแอพพลิเคชั่นที่หลากหลาย เป็นกระบวนทัศน์ของ Google เวอร์ชันโอเพ่นซอร์สที่ใช้ใน MapReduce ในปี 2547 เราจะพูดถึงคำถามที่พบบ่อยโดยผู้เริ่มต้นในระบบนิเวศของ Big Data ในบทความนี้ แพลตฟอร์ม Apache Hadoop มุ่งเน้นไปที่การประมวลผลข้อมูลแบบกระจายมากกว่าการจัดเก็บฐานข้อมูลหรือการจัดเก็บเชิงสัมพันธ์ แม้จะมีส่วนประกอบของหน่วยเก็บข้อมูลที่เรียกว่า HDFS (Hadoop Distributed File System) ซึ่งจัดเก็บไฟล์ที่ใช้สำหรับการประมวลผล แต่ HDFS ก็จัดอยู่ในหมวดหมู่ของฐานข้อมูลเชิงสัมพันธ์ สามารถใช้ Hive และ HiveQL เพื่อค้นหา พื้นที่จัดเก็บ HDFS ของ HDFS ซึ่งสร้างขึ้นใน HDFS
ตัวอย่างของ Hadoop คืออะไร?
Hadoop สามารถใช้โดยบริษัทที่ให้บริการทางการเงินเพื่อประเมินความเสี่ยง สร้างแบบจำลองการลงทุน และสร้างอัลกอริทึมการซื้อขาย Hadoop ยังถูกใช้เพื่อช่วยในการสร้างและจัดการแอปพลิเคชันเหล่านั้น ผู้ค้าปลีกใช้เทคโนโลยีนี้เพื่อช่วยให้พวกเขาเข้าใจและให้บริการลูกค้าได้ดียิ่งขึ้นโดยการวิเคราะห์ข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง
ประโยชน์มากมายของ Hadoop
Hadoop สามารถใช้เพื่อจัดการข้อมูลในแอปพลิเคชันข้อมูลขนาดใหญ่ เช่น การวิเคราะห์ข้อมูลขนาดใหญ่ การวิเคราะห์ข้อมูลแบบเรียลไทม์ การวิจัยทางวิทยาศาสตร์ และคลังข้อมูล ด้วยเหตุนี้ จึงเป็นแพลตฟอร์มอเนกประสงค์และปรับเปลี่ยนได้ซึ่งเหมาะสำหรับการใช้งานที่หลากหลาย
เป็นฐานข้อมูล Spark A Nosql
ตามเอกสารประกอบ NoSQL DataFrame เป็นรูปแบบแหล่งข้อมูลสำหรับ Spark DataFrame DataPruning และการกรอง (เพรดิเคตพุชดาวน์) มีอยู่ในแหล่งข้อมูลนี้ ซึ่งช่วยให้การสืบค้น Spark สามารถเรียกใช้ข้อมูลจำนวนน้อยลงได้ และโหลดเฉพาะข้อมูลที่จำเป็นสำหรับงานที่ใช้งานอยู่เท่านั้น
ต้องใช้ความพยายามอย่างมากในการเชื่อมต่อฐานข้อมูล Apache Spark และ NoSQL (Apache Cassandra และ MongoDB) เข้าด้วยกัน บล็อกนี้เกี่ยวกับวิธีสร้างแอปพลิเคชัน Apache Spark บนแบ็กเอนด์ NoSQL TCP/IP sPark เป็นจุดหมายปลายทางของสวนสนุกยอดนิยมที่มีเครื่องเล่นมากมายในส่วน CassandraLand และ MongoLand ที่มีชื่อเสียง เมื่อแอปพลิเคชัน Spark ของเราค้นหาข้อมูลจาก DOE มันก็หมุนวงล้อและหงุดหงิด บทเรียนในที่นี้คือลำดับคีย์ของ Cassandra มีความสำคัญอย่างยิ่งในกระบวนการดึงข้อมูล CassandraLand ยังมีรถไฟเหาะยอดนิยมที่เรียกว่า Partitioner ลูกค้าที่ใช้รถไฟเหาะควรติดตามประวัติการขี่ของตน เพื่อให้ผู้ควบคุมรถติดตามได้ว่าใครเคยขี่บ้างในแต่ละวัน Mongo บทที่ 1 – จัดการการเชื่อมต่อ MongoDB อย่างถูกต้อง เมื่ออัปเดตข้อมูล เช่น สถานะสมาชิกใหม่ของอุทยานแห่งกระทรวงพลังงาน ดัชนี Mongo จะมีประโยชน์มาก ในกรณีของการอัปเดตเฉพาะ MongoDB และ Spark ควรตรวจสอบให้แน่ใจว่ามีการจัดการการเชื่อมต่อและการจัดทำดัชนีที่เหมาะสม
จุดประกาย: อนาคตของข้อมูลขนาดใหญ่
Apache Spark คือระบบประมวลผลแบบกระจายที่พัฒนาร่วมกับ Apache Software Foundation เป็นระบบประมวลผลข้อมูลขนาดใหญ่บน Hadoop กรอบงานโอเพ่นซอร์สที่สามารถใช้เพื่อเพิ่มประสิทธิภาพชุดข้อมูลขนาดใหญ่และเชื่อมช่องว่างระหว่างแบบจำลองเชิงขั้นตอนและเชิงสัมพันธ์ นอกจากนี้ Spark ยังรองรับ MongoDB ทำให้สามารถใช้สำหรับการวิเคราะห์แบบเรียลไทม์และการเรียนรู้ของเครื่อง