
วิธีแทรกข้อมูล 20 ล้านรายการลงในฐานข้อมูล NoSQL
เผยแพร่แล้ว: 2022-11-24มีหลายวิธีในการแทรกข้อมูล 20 ล้านรายการลงในฐานข้อมูล NoSQL วิธีหนึ่งคือการใช้คุณลักษณะการโหลดจำนวนมากของฐานข้อมูล สิ่งนี้ต้องการให้ข้อมูลอยู่ในรูปแบบเฉพาะที่ฐานข้อมูลสามารถเข้าใจได้ และจะเป็น วิธีที่มีประสิทธิภาพสูงสุดใน การโหลดข้อมูล อีกวิธีหนึ่งคือการใช้สคริปต์หรือแอปพลิเคชันเพื่อแทรกข้อมูลทีละระเบียน นี่จะเป็นกระบวนการที่ช้ากว่า แต่ไม่ต้องการข้อมูลให้อยู่ในรูปแบบเฉพาะ
Mongobb สามารถจัดการกับบันทึกนับล้านได้หรือไม่?
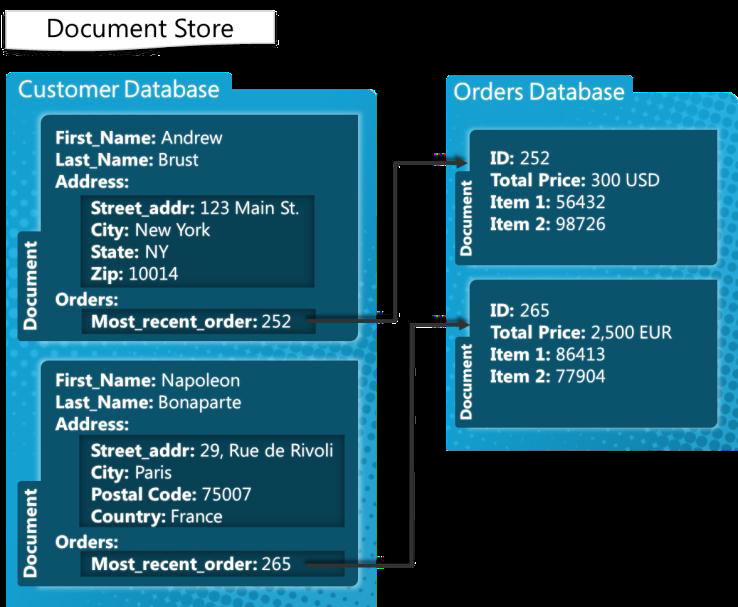
หากต้องการประมวลผลบันทึกนับล้านแบบเรียลไทม์ คุณควรใช้ MongoDB และ ElasticSearch นอกจากนี้ยังเป็นประโยชน์ในการใช้โครงสร้างและแนวคิดเหล่านี้ใน ชุดข้อมูลขนาดใหญ่
ด้วยการเพิ่มประสิทธิภาพส่วนแทรก MongoDB ขนาดใหญ่ เราสามารถโหลด 50 ล้านบันทึกได้เร็วขึ้น 33%! หน้าการตั้งค่า Github คือที่ที่คุณจะพบโค้ดสำหรับโปรแกรมเหล่านี้ทั้งหมด ฉันทดสอบ Macbook Pro ด้วยความเร็วอัปลิงค์ 25–35 Mbps และความเร็วการเชื่อมต่อ 25–35 Mbps ในการทดลองนี้ มีความเป็นไปได้ที่ผลลัพธ์จะแตกต่างจากที่ได้จาก EC2 ที่พร้อมสำหรับการผลิต แพลตฟอร์มทดสอบข้อมูล Kaggle เป็นตัวเลือกที่ยอดเยี่ยมสำหรับ การทดสอบข้อมูล เนื่องจากได้เตรียมชุดข้อมูลไว้แล้ว yelp_academic_dataset_review.json ไฟล์ขนาด 5 GB มีบันทึก 6.9 ล้านรายการ หลังจากโหนดอ่านไฟล์ Mongo ใช้เวลา 2.5 ชั่วโมงในการเขียนบันทึก 1 ล้านรายการ
เครื่องมือนี้ได้รับการแนะนำสำหรับการสร้างจุดข้อมูลไม่เกิน 2 ล้านจุด เอนทิตีบัฟเฟอร์ Node.js ไม่สามารถมีไฟล์มากกว่า 2GB เหมาะสมอย่างยิ่งที่ควรใช้สตรีมที่นี่ เราสามารถแทรกลำดับ 100k ในตัวอย่างนี้ได้โดยมีความล่าช้าเล็กน้อย ใช้เวลา 29 นาทีในการสอดแทรก เนื่องจากมีการใช้ EventEmitter บนสตรีมทั้งหมด จึงเป็นกรณีนี้ การใช้งาน CPU นี้เพิ่มขึ้นเป็น 40% มากกว่าการแทรก 100k ตามลำดับ 10%
IOPS เพิ่มขึ้นเกือบสองเท่าจาก 50 เป็น 100 และการเชื่อมต่อเพิ่มขึ้นจาก 40 เป็น 60 ควรวนซ้ำในแต่ละโฟลเดอร์ อ่านไฟล์ และบันทึกตัวนับของความยาวอาร์เรย์บทวิจารณ์ที่นั่น หากแนวทางนี้ใช้ได้ดีในอนาคต สามารถนำไปใช้กับการแทรกในภายหลังได้ ใช้เวลาของคุณเพื่อดูว่ามันทำงานอย่างไร ในส่วนนี้ เราพิจารณาว่าจะใช้เวลานานแค่ไหนในการอ่านโฟลเดอร์ 51,936 โฟลเดอร์และใส่บันทึก 63 ล้านรายการ เราต้องรู้ว่ามีกี่โฟลเดอร์ที่ถูกอ่านเพื่อที่จะไปถึงล้านระเบียนถัดไป เนื่องจาก การแทรกข้อมูล สามารถขนานกันได้ในภายหลัง ระบบใช้เวลาประมาณหนึ่งชั่วโมงครึ่งในการแทรกบันทึก 63 ล้านรายการ เราคาดการณ์ไว้ก่อนหน้านี้ว่าจะเร็วกว่านั้นถึง 33%!
เราโหลดข้อมูลเกือบ 45GB ภายในหนึ่งชั่วโมงครึ่ง IOPS อยู่ที่ 125 ตลอดระยะเวลา และการเชื่อมต่ออยู่ที่ประมาณ 100 ตลอดเวลา ตอนนี้ผลลัพธ์ออกมาแล้ว ฉันเดาว่าฉันสามารถเริ่มวางแผนสำหรับอนาคตได้ InsertMany ช่วยให้คุณสามารถแทรก 1 ล้านบันทึกในเวลาน้อยกว่าหนึ่งนาที สำหรับการโหลดระหว่าง 1 ถึง 10 เมตร มีแนวโน้มว่า Stream API จะต้องทำการแทรกแบบขนาน เนื่องจากคลัสเตอร์ CPU และ IOPS มีน้ำหนักมาก ประสิทธิภาพของแอปจึงอาจลดลงอย่างมาก เรียกใช้สคริปต์กำหนดเวลาเพื่อกำหนดจำนวนการดำเนินการ/กระบวนการที่สามารถดำเนินการพร้อมกันได้
MongoDB มีข้อได้เปรียบหลายประการเหนือระบบจัดเก็บไฟล์อื่นๆ นอกเหนือจากการเป็นตัวเลือกที่ยอดเยี่ยมสำหรับไฟล์ขนาดใหญ่ ในการเริ่มต้น ไฟล์ขนาดใหญ่สามารถจัดเก็บในฐานข้อมูลได้อย่างง่ายดาย นอกจากนี้ ฐานข้อมูลยังมีความสามารถในการประมวลผลวัตถุจำนวนมาก ประการสุดท้าย ฐานข้อมูลสามารถปรับขนาดได้ในแนวนอน ทำให้สามารถจัดการกับข้อมูลจำนวนมากขึ้นโดยไม่ล้นหลาม หากคุณต้องการเก็บ ไฟล์ขนาดใหญ่ไว้ ในฐานข้อมูล MongoDB เป็นตัวเลือกที่ยอดเยี่ยม มีข้อดีมากมายในการใช้เหนือพื้นที่เก็บข้อมูลและตัวเลือกการปรับขยายอื่นๆ

ขนาดสูงสุดของเอกสาร Mongodb คืออะไร?
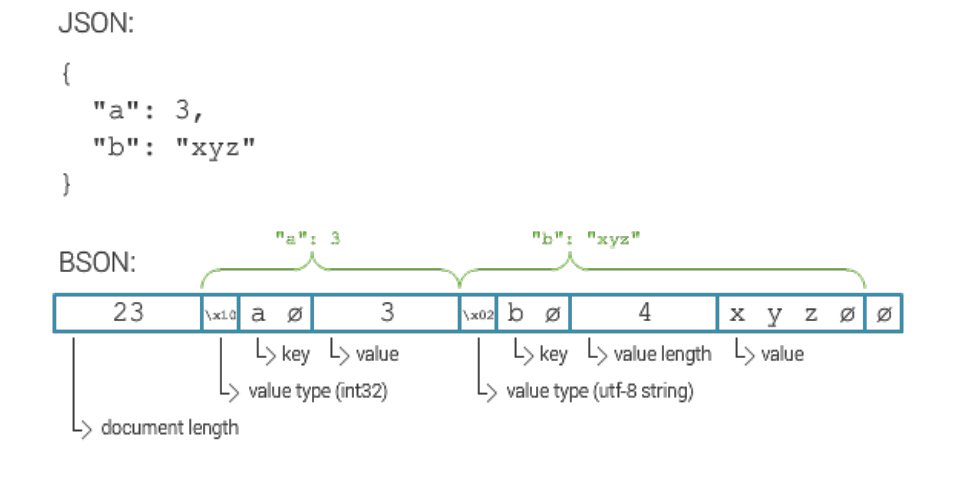
ขนาดสูงสุดสำหรับเอกสาร MongoDB คือ 16 เมกะไบต์
วิธีแทรกบันทึกนับล้านใน Mongodb
สมมติว่าคุณมีเซิร์ฟเวอร์ MongoDB ทำงานอยู่และมีการสร้างฐานข้อมูลและคอลเลกชัน คุณสามารถแทรกระเบียนโดยใช้เมธอด insert() วิธีนี้สามารถใช้ทั้งอาร์เรย์ของเอกสารหรือเอกสารเดียว
ในการแทรกเอกสารเดียว ให้ใช้ไวยากรณ์ต่อไปนี้:
db.collection.insert(
{
ชื่อ: “จอห์น โด”
}
)
ในการแทรกเอกสารหลายฉบับ ให้ใช้ไวยากรณ์ต่อไปนี้:
db.collection.insert([
{
ชื่อ: “จอห์น โด”
},
{
ชื่อ: “เจน โด”
}
])
คุณมีตัวเลือกน้อย คุณสามารถสร้างคอลเล็กชันแยกต่างหากสำหรับแต่ละรหัสอุปกรณ์ แล้วค้นหารหัสนั้นแยกกัน หากคุณมีอุปกรณ์จำนวนมาก อาจมีราคาแพง หากคุณต้องการค้นหาเอกสารทั้งหมดในคอลเลกชั่น คุณก็สามารถทำเช่นเดียวกันกับคอลเลกชั่นเดียวกันสำหรับอุปกรณ์ทั้งหมดได้ ค่าบริการนี้อาจมีราคาแพงหากคุณมีอุปกรณ์จำนวนมาก ตัวเลือกที่สามคือการสร้างคอลเลกชันที่แยกส่วน โหลดจะกระจายไปทั่ว Mongo ส่งผลให้ การประมวลผลคิวรี่เร็วขึ้น หากคุณต้องการสร้างคอลเลกชั่นโดยใช้ตัวเลือกคอลเลกชั่นที่แยกส่วน ตรวจสอบให้แน่ใจว่าได้ตั้งค่าตัวเลือกเศษเป็น true
Mongodb: ระบบจัดการฐานข้อมูล Nosql
MongoDB เป็นระบบจัดการฐานข้อมูล NoSQL ที่สร้างขึ้นเพื่อจัดการเอกสาร สามารถจัดการไฟล์ข้อมูลได้หลากหลาย โดยจำกัดค่าเริ่มต้นไว้ที่ 100,000 คีย์ดัชนีต่อเอกสาร ดังนั้นแพลตฟอร์ม MongoDB จึงสามารถจัดเก็บข้อมูล จำนวนมาก ได้โดยไม่เป็นภาระมากเกินไป การแทรกจำนวนมากเป็นคุณสมบัติที่สะดวกใน MongoDB ซึ่งจะมีประโยชน์หากคุณมีข้อมูลจำนวนมากที่จะเพิ่ม เนื่องจากสามารถแทรกเอกสารหลายชุดพร้อมกันได้
ขีด จำกัด การแทรกจำนวนมากของ Mongodb
เวอร์ชัน MongoDB 3.6 ปัจจุบันให้ผลตอบแทน 100,000
วิธีการแทรกจำนวนมากช่วยให้สามารถแทรกเอกสารหลายชุดพร้อมกันใน MongoDB ในฐานะที่เป็นพารามิเตอร์ วิธีการแทรกจะสร้างอาร์เรย์ของเอกสาร ผู้ใช้ไม่จำเป็นต้องใส่ฟิลด์ทั้งหมดในแบบสอบถาม ในตัวอย่างนี้ ลองใช้บรรทัดคำสั่งเพื่อแทรกเอกสารหลายชุดโดยใช้การแทรกจำนวนมากของ MongoDB การแทรกตัวเลขจำนวนมากสามารถทำได้โดยใช้เมธอด Bulk.insert() วิธีนี้ซึ่งนำมาใช้หลังจากเวอร์ชัน 2.6 คล้ายกับการแทรกจำนวนมากที่ไม่มีลำดับ ก่อนอื่นเราสร้างรายการรถยนต์ที่สั่งซื้อด้วยชื่อ carbulk1 จากนั้นใส่เอกสารโดยดำเนินการตามวิธีการดำเนินการ โปรแกรม Java นี้สาธิตวิธีรันการ ดำเนินการจำนวนมาก โดยใช้คำสั่งเชลล์เป็นครั้งแรก
Mongobb มีขีด จำกัด หรือไม่?
MongoDB รองรับความลึกที่ซ้อนกัน 100 ระดับ ดังนั้นเอกสารอาจมีขนาดใหญ่ถึง 16MB ฐานข้อมูล MongoDB สามารถบรรจุข้อมูลได้สูงสุด 20GB เท่านั้น