
เป็น Spark สำหรับ Nosql
เผยแพร่แล้ว: 2023-02-05Spark เป็นเครื่องมืออันทรงพลังสำหรับการทำงานกับข้อมูล โดยเฉพาะชุดข้อมูลขนาดใหญ่ ได้รับการออกแบบให้รวดเร็วและมีประสิทธิภาพ และรองรับรูปแบบข้อมูลที่หลากหลาย รวมถึง ฐานข้อมูล NoSQL ฐานข้อมูล NoSQL กำลังเป็นที่นิยมมากขึ้น เนื่องจากเหมาะสำหรับการจัดการข้อมูลจำนวนมาก Spark สามารถช่วยคุณค้นหาและจัดการข้อมูล NoSQL ได้อย่างมีประสิทธิภาพ
เพื่อให้ทำงานได้อย่างมีประสิทธิภาพ สิ่งสำคัญคือต้องจัดการฐานข้อมูลของแอปพลิเคชันของคุณโดยใช้ Apache Spark และ NoSQL ( Apache Cassandra และ MongoDB) เป้าหมายของบล็อกนี้คือการให้เคล็ดลับในการพัฒนาแอปพลิเคชัน Apache Spark โดยใช้แบ็กเอนด์ NoSQL เป็นสวนสนุก และ TCP/IP sPark มีเครื่องเล่นทั้งใน CassandraLand และ MongoLand เมื่อเราพยายามสืบค้นข้อมูล DOE แอปพลิเคชัน Spark ของเราเริ่มหมุนตัวออกจากแกนของมัน บทเรียนที่นี่คือเมื่อคุณสอบถาม Cassandra ลำดับคีย์มีความสำคัญ CassandraLand ยังมีรถไฟเหาะ Partitioner ซึ่งเป็นหนึ่งในสถานที่ท่องเที่ยวที่ได้รับความนิยมมากที่สุด ในขณะที่ลูกค้าเพลิดเพลินกับการนั่งรถไฟเหาะ ผู้ควบคุมเครื่องเล่นสามารถติดตามว่าใครเคยขี่บ้างในแต่ละวันโดยเก็บข้อมูลไว้
ในบทที่หนึ่ง เราจะพูดถึงการจัดการการเชื่อมต่อ MongoDB เมื่อคุณจำเป็นต้องอัปเดตข้อมูลเกี่ยวกับอุทยาน เช่น สถานะสมาชิกใหม่ของกรมพลังงาน คุณสามารถใช้ ดัชนี mongo ควรใช้ MongoDB และ Spark เพื่อให้แน่ใจว่าการเชื่อมต่อของคุณได้รับการจัดการอย่างเหมาะสม เช่นเดียวกับดัชนีในกรณีเฉพาะ
Apache Spark เป็นระบบประมวลผลแบบกระจายยอดนิยมที่เป็นโอเพ่นซอร์สและสร้างขึ้นเพื่อใช้ในเวิร์กโหลดข้อมูลขนาดใหญ่ คุณสมบัตินี้ นอกเหนือจากการแคชในหน่วยความจำและการดำเนินการค้นหาที่ปรับให้เหมาะสมแล้ว ยังช่วยให้สามารถสืบค้นข้อมูลเชิงวิเคราะห์ได้อย่างรวดเร็วกับข้อมูลจำนวนมาก
ด้วยรหัสที่เกือบเหมือนกัน จึงมีประสิทธิภาพและหลากหลายมากขึ้น ทำให้สามารถประมวลผลข้อมูลแบบกลุ่มและข้อมูลแบบเรียลไทม์ได้ในเวลาเดียวกัน ด้วยเหตุนี้ เครื่องมือ Big Data รุ่นเก่า จึงล้าสมัยมากขึ้นเนื่องจากไม่มีฟังก์ชันนี้
Spark ฐานข้อมูลประเภทใด
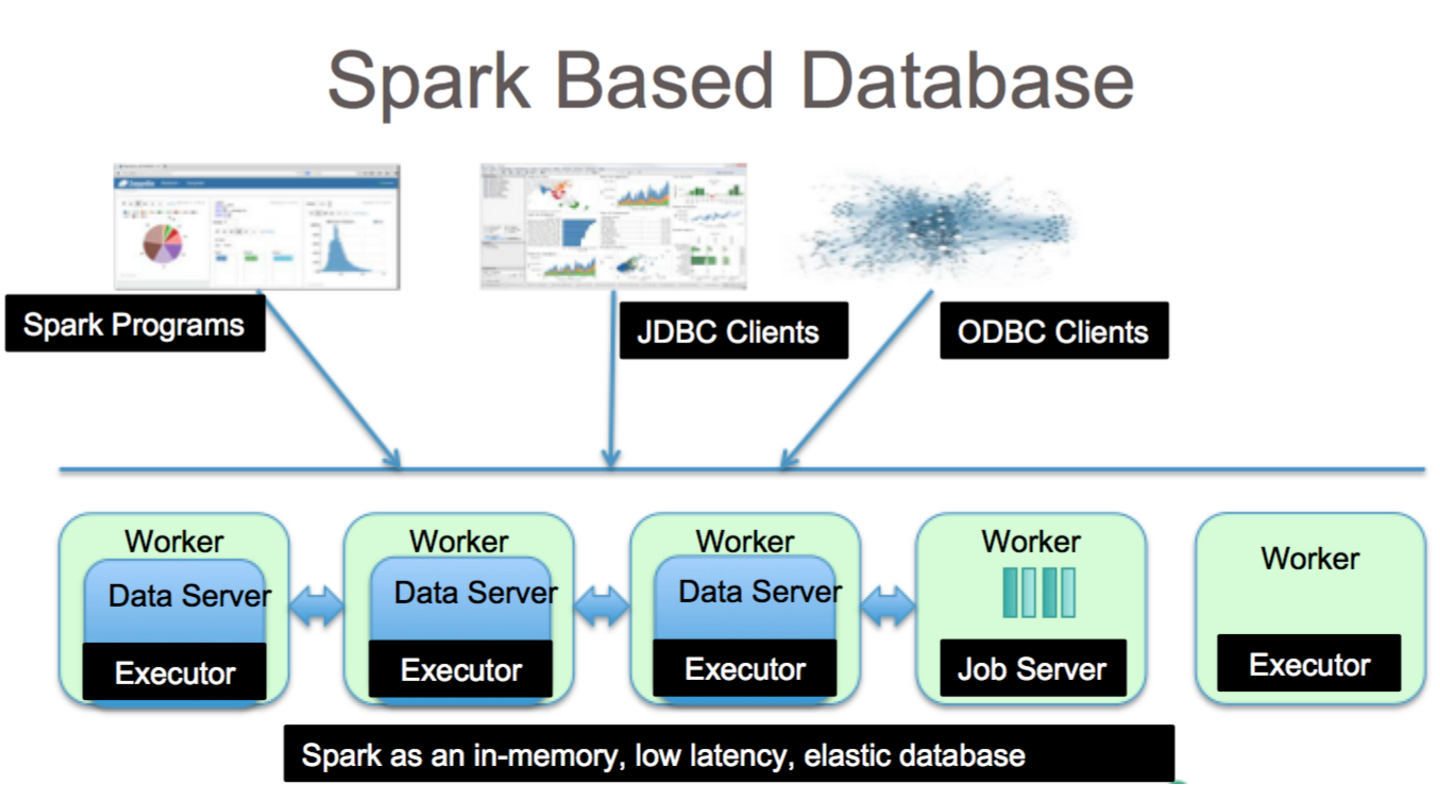
Apache Spark เป็นเฟรมเวิร์กการประมวลผลข้อมูลที่สามารถจัดการข้อมูลจากที่เก็บข้อมูลที่หลากหลาย รวมถึง (HDFS) ฐานข้อมูล NoSQL และฐานข้อมูลเชิงสัมพันธ์
แม้ว่าฐานข้อมูลเชิงสัมพันธ์จะมีวงจรโฆษณามากมาย แต่จะยังคงได้รับความนิยมต่อไป โดยไม่คำนึงถึงความก้าวหน้าล่าสุดและการเพิ่มขึ้นของฐานข้อมูล NoSQL เมื่อเวลาผ่านไป การจัดเก็บข้อมูลในฐานข้อมูลเชิงสัมพันธ์ทำได้ยากขึ้น ในบทความนี้ เราจะพิจารณาความก้าวหน้าที่สำคัญในการใช้ประโยชน์จากพลังของฐานข้อมูลเชิงสัมพันธ์ในระดับโลก เมื่อเปิดตัวครั้งแรก อินเทอร์เฟซระหว่าง Spark และการวิเคราะห์ข้อมูลขนาดใหญ่มีน้อยมาก หลายคนเขียนโค้ดจำนวนมากเพื่อเรียกใช้โปรแกรมนี้ ซึ่งมีประสิทธิภาพแต่ค่อนข้างช้า ผู้ใช้จะสามารถรวมโมเดลทั้งสองนี้ในฐานข้อมูล Spark SQL ได้อย่างง่ายดาย นอกจากนี้ยังยอมรับรูปแบบข้อมูลที่หลากหลายจากแหล่งต่างๆ
โครงการโอเพ่นซอร์ส Apache Spark เป็นโครงการที่มีการใช้งานมากที่สุด โดยมีผู้ร่วมให้ข้อมูลหลายร้อยรายที่ร่วมสนับสนุน นอกเหนือจากการเป็นโครงการโอเพ่นซอร์สฟรีแล้ว Spark SQL ยังเริ่มได้รับความนิยมในอุตสาหกรรมกระแสหลัก นอกเหนือจาก Spark SQL แล้ว ประมาณสองในสามของลูกค้า Databricks Cloud (บริการโฮสต์ที่รัน Spark) ใช้ภาษาโปรแกรมอื่นๆ หลังจากสรุปกรณีศึกษาแรกของเราแล้ว เราจะสาธิตวิธีนำ databricks ไปใช้กับกรณีศึกษานี้ Spark DataFrame คือชุดของแถว (ประเภทแถว) ที่กระจายด้วยสคีมาเดียวกัน แต่ละคอลัมน์ในชุดข้อมูลจะมีป้ายกำกับชื่อ API ของ DataFrame ช่วยให้นักพัฒนาสามารถรวมรหัสเชิงขั้นตอนและเชิงสัมพันธ์ได้
Spark ยังสามารถจัดการฟังก์ชันขั้นสูง เช่น UDF ตารางในฐานข้อมูลเชิงสัมพันธ์มีความคล้ายคลึงกับดาต้าเฟรมในฐานข้อมูลดาต้าเฟรม แต่มีการเพิ่มประสิทธิภาพที่เกี่ยวข้องมากขึ้น สามารถจัดการได้ในลักษณะเดียวกับคอลเลกชันแบบกระจายดั้งเดิม (RDD) ของ Spark โดยทั่วไป แบบสอบถาม Spark SQL เร็วกว่าแบบสอบถาม Shark และสามารถแข่งขันกับ Impulsa ได้มากกว่า ใน Query 3a ซึ่งการเลือกใช้การค้นหาทำให้ตารางใดตารางหนึ่งมีขนาดเล็กมาก มีความแตกต่างที่สำคัญระหว่าง Impala และ Impala

เป็นเครื่องมือที่ยอดเยี่ยมสำหรับการวิเคราะห์ข้อมูลด้วย Spark SQL ไวยากรณ์ HiveQL, Hive SerDes และ HiveDFs สามารถเข้าถึงได้ผ่านไวยากรณ์ HiveQL เช่นเดียวกับ Hive SerDes และ HiveDFs Hive metastores , SerDes และ UDF ได้ถูกนำมาใช้แล้ว แม้ว่า Spark จะเป็นฐานข้อมูล แต่ก็เป็นฐานข้อมูล NoSQL ด้วยเหตุนี้ เมื่อคุณสร้างตารางที่มีการจัดการใน Spark คุณจะสามารถใช้เครื่องมือต่างๆ ที่สอดคล้องกับ SQL เพื่อจัดเก็บข้อมูลของคุณได้ สามารถใช้นิพจน์ SQL เพื่อเข้าถึงตารางใน Spark โดยเชื่อมต่อกับ JDBC ผ่านตัวเชื่อมต่อจาก jdbc.org ด้วยเหตุนี้ คุณยังสามารถใช้เครื่องมือของบุคคลที่สาม เช่น Tableau, Talend และ Power BI ความสามารถในการใช้ Spark เหมาะอย่างยิ่งสำหรับการวิเคราะห์ข้อมูล และเป็นเครื่องมือที่มีประโยชน์สำหรับอุตสาหกรรมหลากหลายประเภท
Spark Sql: สิ่งที่ดีที่สุดของทั้งสองโลก
มันเชื่อมช่องว่างระหว่างสองโมเดลที่กล่าวถึงก่อนหน้านี้ โมเดลเชิงขั้นตอนและเชิงสัมพันธ์ โดยรวมองค์ประกอบหลักสองส่วนเข้าด้วยกัน ด้วยเหตุนี้ คุณจึงเรียกใช้การดำเนินการเชิงสัมพันธ์ขนาดใหญ่บนแหล่งข้อมูลภายนอกและคอลเล็กชันแบบกระจายในตัวของ Spark ได้โดยใช้ DataFrame API
จุดประกายในฐานข้อมูลคืออะไร? เป็นเฟรมเวิร์กแบบโอเพ่นซอร์สที่ใช้การเรียนรู้ของเครื่อง การประมวลผลแบบสอบถามแบบโต้ตอบ และปริมาณงานตามเวลาจริง บริษัทนี้ไม่มีระบบจัดเก็บข้อมูลของตนเอง แต่จะใช้การวิเคราะห์บนระบบจัดเก็บข้อมูลอื่นๆ เช่น HDFS, Amazon Redshift, Amazon S3, Couchbase และอื่นๆ นอกเหนือจากระบบของตัวเอง เมื่อพูดถึงการประมวลผลข้อมูลที่มีโครงสร้าง Spark SQL ไม่ใช่แค่ฐานข้อมูล มันยังเป็นโมดูล ส่วนใหญ่เขียนบน DataFrames ซึ่งเป็นนามธรรมของการเขียนโปรแกรมที่ทำงานร่วมกับแบบสอบถาม SQL
ประเภทของ SQL sql สำหรับ "sparksql" คืออะไร? Hive SQL รองรับไวยากรณ์ HiveQL เช่นเดียวกับ Hive SerDes และ UDF ช่วยให้คุณเข้าถึงคลังสินค้า Hive ที่สร้างไว้ก่อนหน้านี้ได้ การใช้ Hive metastores, SerDes และ UDF ที่มีอยู่ใน Spark SQL ไม่ใช่เรื่องยาก
Mongob สามารถเรียกใช้ Spark ได้หรือไม่?
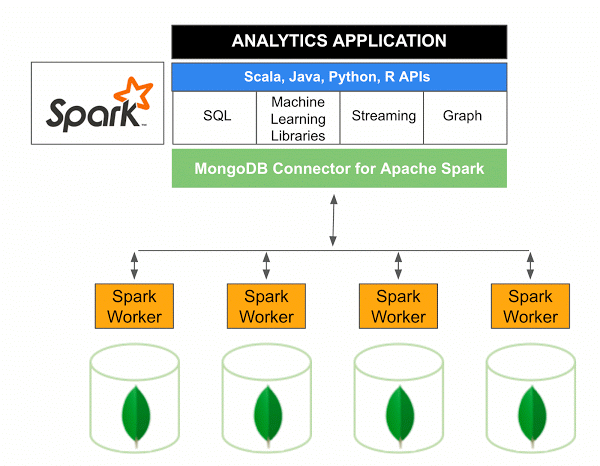
MongoDB Connector เวอร์ชัน 10.0 สำหรับ Apache Spark รวมถึงการสนับสนุน Spark Structured Streaming ผ่าน Spark Data Sources API V2 ใหม่ ตลอดจนการใช้งาน Spark Data Sources API V2 ใหม่
ตัวเชื่อมต่อ MongoDB สำหรับ Spark เป็นโครงการโอเพ่นซอร์สที่ให้คุณเขียนข้อมูลจาก MongoDB และอ่านจาก MongoDB โดยใช้ Scala เนื่องจากวิธียูทิลิตี้ของตัวเชื่อมต่อ การโต้ตอบระหว่าง Spark และ MongoDB จึงง่ายขึ้น ทำให้เป็นการผสมผสานที่ทรงพลังสำหรับการสร้างแอปพลิเคชันการวิเคราะห์ที่ซับซ้อน ด้วยการใช้คุณสมบัติการจำลองแบบในตัวและการแบ่งกลุ่ม Spark สามารถนำไปใช้กับปริมาณงานที่หลากหลายที่ใช้ ฐานข้อมูล MongoDB
Spark: วิธีที่รวดเร็วในการสร้างแอปพลิเคชันที่อุดมด้วยข้อมูล
ด้วยความช่วยเหลือของ Spark ซึ่งเป็นเครื่องมืออันทรงพลัง คุณสามารถพัฒนาแอปพลิเคชันที่ใช้งานได้หลากหลายขึ้นอย่างรวดเร็ว ด้วยการรวม MongoDB เข้าด้วยกัน นักพัฒนาสามารถเร่งกระบวนการพัฒนาได้โดยใช้เทคโนโลยีฐานข้อมูลเดียว นอกจากนี้ Spark ยังใช้ระบบคลาวด์และรองรับ ที่เก็บข้อมูล NoSQL ทำให้เหมาะสำหรับแอปพลิเคชันที่ต้องใช้ข้อมูลมาก