
MapReduce: โมเดลการเขียนโปรแกรมสำหรับชุดข้อมูลขนาดใหญ่
เผยแพร่แล้ว: 2023-01-08MapReduce เป็นรูปแบบการเขียนโปรแกรมและการใช้งานที่เกี่ยวข้องสำหรับการประมวลผลและสร้างชุดข้อมูลขนาดใหญ่ด้วยอัลกอริทึมแบบกระจายแบบขนานบนคลัสเตอร์
เรากำลังเปลี่ยนแปลงวิธีการทำงานกับข้อมูลจำนวนมหาศาลโดยใช้เทคโนโลยีใหม่ๆ คลังข้อมูล เช่น Hadoop, NoSQL และ Spark เป็นผู้เล่นที่โดดเด่นที่สุดในแวดวงนี้ DBA และวิศวกร/นักพัฒนาโครงสร้างพื้นฐานเป็นหนึ่งในมืออาชีพสายพันธุ์ใหม่ที่เชี่ยวชาญในการจัดการระบบด้วยความซับซ้อนในระดับสูง แทนที่จะเป็นฐานข้อมูล Hadoop เป็นระบบนิเวศซอฟต์แวร์ที่ช่วยให้สามารถประมวลผลแบบขนานในรูปแบบของไฟล์ขนาดใหญ่ได้ เทคโนโลยีนี้ให้ประโยชน์อย่างมากในแง่ของการรองรับความต้องการการประมวลผลขนาดใหญ่ของข้อมูลขนาดใหญ่ สำหรับธุรกรรมข้อมูลขนาดใหญ่ คลัสเตอร์ Hadoop โดยเฉลี่ยอาจใช้เวลาเพียงสามนาทีในการประมวลผลธุรกรรมขนาดใหญ่ ซึ่งโดยทั่วไปจะใช้เวลา 20 ชั่วโมงในระบบฐานข้อมูลเชิงสัมพันธ์แบบรวมศูนย์
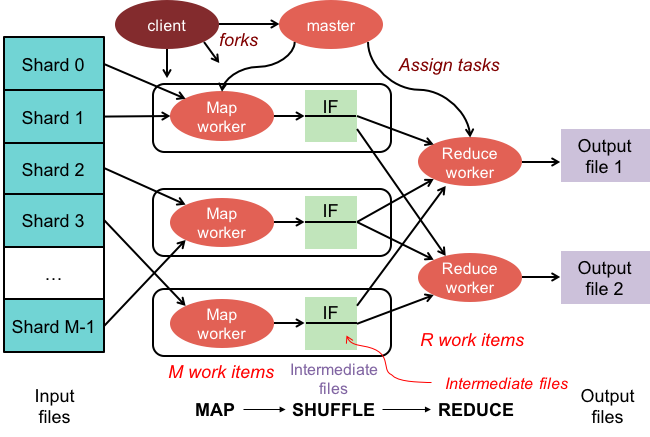
คลัสเตอร์ mapreduce คือคลัสเตอร์ที่มีอัลกอริทึมแบบขนานและโมเดลโปรแกรมมิงที่ประมวลผลและสร้างชุดข้อมูลขนาดใหญ่ในลักษณะเดียวกับคลัสเตอร์ปกติ
ระบบนิเวศของ Apache Hadoop ได้รับการออกแบบมาเพื่อรองรับการประมวลผลแบบกระจายและจัดเตรียมสภาพแวดล้อมที่เชื่อถือได้ ปรับขยายได้ และพร้อมใช้งาน โมดูล MapReduce ของโครงการนี้เป็นรูปแบบการเขียนโปรแกรมที่ใช้ในการประมวลผลชุดข้อมูลขนาดใหญ่ที่อยู่ใน Hadoop (ระบบไฟล์แบบกระจาย)
โมดูลนี้เป็นส่วนประกอบของระบบนิเวศโอเพ่นซอร์ส Apache Hadoop และใช้เพื่อสอบถามและเลือกข้อมูลใน ระบบไฟล์แบบกระจาย Hadoop (HDFS) สามารถเลือกข้อมูลสำหรับการสืบค้นที่หลากหลายโดยใช้อัลกอริทึม MapReduce ที่พร้อมใช้งานสำหรับวัตถุประสงค์ในการเลือกดังกล่าว
การใช้ MapReduce ทำให้สามารถเรียกใช้งานการประมวลผลข้อมูลขนาดใหญ่ได้ คุณสามารถสร้างโปรแกรม MapReduce ในภาษาโปรแกรมใดก็ได้ รวมถึง C, Ruby, Java, Python และอื่นๆ โปรแกรมเหล่านี้สามารถใช้พร้อมกันเพื่อรันโปรแกรม MapReduce ทำให้มีประโยชน์มากในการวิเคราะห์ข้อมูลขนาดใหญ่
Mapreduce ใช้สำหรับอะไรใน Mongob?
แผนที่ใน MongoDB เป็นรูปแบบการเขียนโปรแกรมการประมวลผลข้อมูลที่ช่วยให้ผู้ใช้สามารถดำเนินการชุดข้อมูลขนาดใหญ่และสร้างผลลัพธ์รวมจากชุดข้อมูลเหล่านั้น MapReduce เป็นวิธีที่ MongoDB ใช้เพื่อลดขนาดแผนที่ ฟังก์ชันนี้แบ่งออกเป็นสองส่วน: ฟังก์ชันแผนที่และฟังก์ชันลดขนาด
การใช้ เครื่องมือ MapReduce ของ MongoDB ทำให้สามารถจัดระเบียบและรวมชุดข้อมูลขนาดใหญ่ได้ คำสั่งนี้ใน MongoDB ใช้อินพุตหลักสองอินพุตใน MongoDB: ฟังก์ชันแมปและฟังก์ชันรีดิวซ์ เพื่อประมวลผลข้อมูลจำนวนมาก สำหรับการกำหนดตัวอย่าง ให้ทำตามขั้นตอนด้านล่าง เราจะกำหนดฟังก์ชันแผนที่ ฟังก์ชันลด และตัวอย่าง
MapReduce จะเปรียบเทียบสตริงเพื่อจัดเรียงผลลัพธ์โดยใช้วิธีการจัดเรียงเริ่มต้น ไม่ว่าคุณจะใช้วิธีเริ่มต้นหรือไม่ก็ตาม หากต้องการเปลี่ยนวิธีการจัดเรียงข้อมูล คุณต้องสร้างอัลกอริทึมการเรียงลำดับก่อนแล้วจึงนำไปใช้โดยใช้คลาสแมปเปอร์
SpiderMonkey เป็นเครื่องมือ JavaScript ที่ใช้กันอย่างแพร่หลาย เหมาะสำหรับการใช้งานขนาดเล็ก แต่ก็มีข้อจำกัดบางประการ ตัวอย่างเช่น SpiderMonkey ไม่มีอัลกอริทึมการเรียงลำดับ ดังนั้น ถ้าคุณต้องการใช้ Mapmapper เพื่อจัดเรียงข้อมูล ก่อนอื่นคุณต้องสร้างอัลกอริทึมการเรียงลำดับของคุณเองและใช้งานในคลาส Reduce
แม้จะได้รับความนิยม SpiderMonkey ไม่ได้ใช้อัลกอริทึมการเรียงลำดับ SpiderMonkey มีข้อ จำกัด อื่น ๆ แต่ข้อ จำกัด นี้มีความโดดเด่น ตัวอย่างเช่น SpiderMonkey ไม่มีตัวเก็บขยะที่ดี ดังนั้นหากโปรแกรมของคุณเริ่มทำงานช้าลง คุณอาจต้องใช้มาตรการบางอย่างเพื่อทำให้เร็วขึ้น
เหตุใดจึงต้องใช้ฟังก์ชัน Mapreduce
ฟังก์ชัน MapReduce มีประโยชน์ในหลายสถานการณ์ วิธีนี้สามารถใช้สำหรับการประมวลผลข้อมูลเป็นชุดได้ในบางกรณี นอกจากนี้ยังมีประโยชน์หากคุณต้องการจัดการข้อมูลจำนวนมากโดยแอปพลิเคชันหรือกระบวนการเดียว นอกจากนี้ยังสามารถใช้ฟังก์ชัน MapReduce เพื่อประมวลผลข้อมูลที่กระจายออกไปหลายโหนดในระบบแบบกระจาย ด้วยการใช้ฟังก์ชัน MapReduce ข้อมูลจากโหนดสามารถรวมกันเป็นเอาต์พุตเดียวได้ โดยทั่วไปแล้ว แอปพลิเคชัน MapReduce ใช้เพื่อประมวลผลข้อมูลจำนวนมาก แม้ว่าอาจต้องจัดการกับข้อมูลจำนวนมาก
ทำไมถึงเรียกว่า Mapreduce?
มีทฤษฎีสองสามข้อเกี่ยวกับสาเหตุที่ชื่อ MapReduce หนึ่งคือมันเป็นการเล่นคำ เนื่องจากอัลกอริทึมการลดแผนที่เกี่ยวข้องกับการแบ่งปัญหาออกเป็นชิ้นเล็ก ๆ (การแมป) จากนั้นแก้ไขชิ้นส่วนเหล่านั้นและนำกลับมารวมกัน (ลด) อีกทฤษฎีหนึ่งคือการอ้างอิงถึงกระดาษที่เขียนโดยพนักงานของ Google ในปี 2547 ที่ชื่อว่า “MapReduce: Simplified Data Processing on Large Clusters” ในบทความนี้ ผู้เขียนใช้คำว่า "map" และ "reduce" เพื่ออธิบายขั้นตอนหลักสองขั้นตอนของรูปแบบการประมวลผลที่เสนอ
อย่างไรก็ตาม สิ่งสำคัญคือต้องทราบว่าโมเดล MapReduce ใช้ในเกณฑ์ที่จำกัดเท่านั้น ไม่เหมาะกับชุดข้อมูลขนาดใหญ่และต้องขนานกันเพื่อให้ทำงานได้อย่างถูกต้อง เมื่อต้องจัดการกับปัญหาเหล่านี้ Apache Spark มีทางเลือกที่มีประสิทธิภาพนอกเหนือจาก MapReduce ระบบคอมพิวเตอร์คลัสเตอร์ Spark ใช้ Hadoop และทำงานเป็นแพลตฟอร์มคอมพิวเตอร์อเนกประสงค์ เครื่องมือนี้สามารถใช้เพื่อเพิ่มความเร็วให้กับงานวิเคราะห์ข้อมูลแบบดั้งเดิม เช่น การทำเหมืองข้อมูลและการเรียนรู้ของเครื่อง ตลอดจนงานประมวลผลข้อมูลที่ซับซ้อนมากขึ้น เช่น คลังข้อมูลและการวิเคราะห์ข้อมูลขนาดใหญ่ ซอฟต์แวร์นี้สร้างขึ้นโดยใช้ Erlang ซึ่งเป็นภาษาโปรแกรมที่ทั้งปรับขนาดได้และทนทานต่อข้อผิดพลาด สามารถจัดการข้อมูลจำนวนมากและรันได้หลายเครื่องพร้อมกัน นอกจากนี้ Spark ยังใช้ระบบการทำงานแบบคู่ขนาน ทำให้หลายโหนดสามารถทำงานเดียวกันได้ในเวลาเดียวกัน โดยรวมแล้วมีศักยภาพในการทำงานวิเคราะห์ข้อมูลขนาดใหญ่โดยอัตโนมัติและทำให้ปรับขนาดได้มากขึ้น หากคุณต้องการประมวลผลแบบขนานและจัดการชุดข้อมูลขนาดใหญ่ มันเป็นทางเลือกที่ยอดเยี่ยมสำหรับ MapReduce
ความแตกต่างระหว่าง Mapreduce และการรวมคืออะไร?
เมื่อทำงานกับข้อมูลขนาดใหญ่ mapreduce เป็นวิธีการสำคัญในการดึงข้อมูลจากข้อมูลจำนวนมาก MongoDB 2.2 ณ ตอนนี้ มีเฟรมเวิร์กการรวมใหม่ ในแง่ของการทำงาน การรวมจะคล้ายกับ mapreduce แต่บนกระดาษ ดูเหมือนจะเร็วกว่า
ในสถานการณ์สมมตินี้ MongoDB Aggregation และ MapReduce จะทำงานบนคอนเทนเนอร์ Docker ในการตั้งค่า Sharded ประสิทธิภาพของไปป์ไลน์ Aggregator นั้นเหนือกว่า mapreduce เนื่องจากช่วยให้นำทางได้เร็วและง่ายขึ้น นี่คือวิธีการทำงานของปัญหา: ทวีตนับคำสรรพนามภาษาสวีเดน เช่น “den” “denne” “denna” “det” “han” “hon” และ “hen” (ตัวพิมพ์เล็กและใหญ่) ในแฮชแท็ก Twitter ผู้ใช้มีแฮนเดิลทวิตเตอร์กี่อัน? ทวีตมากกว่า 4 ล้านทวีตถูกส่งออกไป ในการทดลองนี้ ก่อนอื่นเราจะสร้างฐานข้อมูล MongoDB และเปิดใช้งานการแบ่งส่วน สตรีม Twitter ถูกนำเข้าไปยังฐานข้อมูล และดำเนินการค้นหาโดยใช้ MapReduce และ Aggregation Pipeline
Mapreduce: สุดยอดเครื่องมือรวมข้อมูล
โปรแกรม mapReduce อ่านรายการเอกสารจากคอลเลกชันและประมวลผลโดยใช้ชุดของฟังก์ชันที่กำหนดไว้ล่วงหน้า การดำเนินการ mapReduce สร้างสตรีมของเอกสารที่พร้อมดำเนินการซึ่งจะถูกประมวลผลในขั้นตอนการลด เป็นไปได้ที่จะรวมการลดแผนที่และการรวมเข้าด้วยกันในสถานการณ์ต่างๆ ตัวดำเนินการรวม $group เป็นเครื่องมือที่สามารถใช้เพื่อจัดกลุ่มเอกสารในฟิลด์เดียว เมื่อรวมเอกสารหลายฉบับเข้าด้วยกันโดยใช้ตัวดำเนินการรวม $merge จะสามารถสร้างเอกสารใหม่ได้ ตัวดำเนินการการรวม $accumulator สามารถใช้เพื่อแสดงผลลัพธ์ของการดำเนินการลดขนาดแผนที่หลายรายการในเอกสารเดียว
Mapreduce ใน Mongodb
Mongodb mapreduce เป็นเทคโนโลยีการประมวลผลข้อมูลสำหรับชุดข้อมูลขนาดใหญ่ เป็นเครื่องมือที่มีประสิทธิภาพสำหรับการวิเคราะห์ข้อมูลและมีวิธีการประมวลผลและรวมข้อมูลในลักษณะแบบขนานและแบบกระจาย MapReduce ถูกนำมาใช้อย่างกว้างขวางสำหรับการวิเคราะห์ข้อมูลในโดเมนต่างๆ รวมถึงการวิเคราะห์ปริมาณการใช้งานเว็บ การวิเคราะห์บันทึก และการวิเคราะห์เครือข่ายสังคม

เมื่อใช้ คำสั่ง mapReduce คุณสามารถเรียกใช้การดำเนินการรวมลดแผนที่ในคอลเล็กชันได้ ฟังก์ชันแผนที่สามารถแปลงเอกสารใด ๆ ให้เป็นศูนย์หรืออื่น ๆ อีกมากมาย ใน MongoDB เวอร์ชันตั้งแต่ 4.2 ไปจนถึงเวอร์ชันก่อนหน้า แต่ละไฟล์ที่ปล่อยสามารถเก็บได้เพียงครึ่งหนึ่งของขนาดเอกสาร BSON สูงสุด ไม่รองรับโค้ด JavaScript ประเภท BSON ที่ใช้ใน MapReduce อีกต่อไป และไม่สามารถใช้โค้ดสำหรับฟังก์ชันต่างๆ ได้อีกต่อไป MongoDB 4.4 ตอนนี้ไม่มีโค้ด JavaScript ประเภท BSON ที่เลิกใช้แล้วพร้อมขอบเขต (BSON ประเภท 15) พารามิเตอร์ขอบเขตระบุว่าตัวแปรใดบ้างที่อนุญาตให้เข้าถึงได้โดยฟังก์ชันลด เพื่อลดอินพุต MongoDB จำกัดขนาดเอกสาร BSON ไว้ที่ครึ่งหนึ่งของขนาดสูงสุด
เอกสารขนาดใหญ่ที่ส่งคืนไปยังเซิร์ฟเวอร์อาจถูกส่งคืนแล้วรวมเข้าด้วยกันในภายหลัง ซึ่งอาจทำลายข้อกำหนด MongoDB 4.2 เป็นเวอร์ชันล่าสุด ตัวเลือกนี้สามารถใช้เพื่อสร้างคอลเล็กชันที่แยกส่วนใหม่ รวมถึงลดขนาดแผนที่เพื่อสร้างคอลเล็กชันใหม่ที่มีชื่อคอลเล็กชันเดียวกัน ฟังก์ชันสรุปได้รับค่าคีย์และค่าที่ลดลงจากฟังก์ชันลดเป็นอาร์กิวเมนต์ มีสามตัวเลือกในการกำหนดค่าพารามิเตอร์ขาออก ตัวเลือกนี้นอกเหนือจากการสร้างคอลเล็กชันใหม่แล้ว ไม่สามารถใช้กับสมาชิกรองของชุดเรพพลิกาได้ สามารถระบุอ็อพชัน NonAtomic: false ได้ก็ต่อเมื่อคอลเล็กชันที่มีอยู่แล้วที่จะผ่านมีข้อกำหนดที่ชัดเจน
การใช้ฟังก์ชันลดขนาดกับผลลัพธ์ของเอกสารใหม่และที่มีอยู่ หากคีย์ในเอกสารใหม่เหมือนกับคีย์ในเอกสารที่มีอยู่ การลดขนาดแผนที่ไม่ทำงานเมื่อ collectionName เป็นคอลเล็กชัน unharded ที่มีอยู่ซึ่งได้รับการตั้งค่า ในกรณีนี้ MongoDB จะถูกป้องกันไม่ให้ล็อกฐานข้อมูลหาก nonAtomic เป็นจริง เฉพาะสมาชิกรองของชุดแบบจำลองที่ใช้ตัวเลือกนี้เท่านั้นที่สามารถออกจากชุดได้ ไม่จำเป็นต้องมีฟังก์ชันแบบกำหนดเองเพื่อเขียนการดำเนินการลดขนาดแผนที่ใหม่ cust_id ใช้เพื่อคำนวณฟิลด์ค่าของกลุ่มระยะ $group โดยใช้วิธี cust_id ขั้นตอน $merge รวมผลลัพธ์ของขั้นตอนการ $merge ลงในคอลเลกชันเอาต์พุตโดยใช้ตัวดำเนินการไปป์ไลน์การรวมที่มีอยู่
ตัวอย่างเช่น สามารถใช้ $out stage เพื่อเขียนเอาต์พุตของคอลเล็กชัน agg_alternative_1 เอกสารอินพุตแต่ละรายการสามารถประมวลผลได้ด้วยฟังก์ชันแผนที่ แต่ละรายการในคำสั่งซื้อจะเชื่อมโยงกับค่าออบเจกต์ใหม่ที่มีทั้งจำนวน 1 และจำนวนรายการในคำสั่งซื้อ ในreducedVal ฟิลด์นับแสดงผลรวมของฟิลด์นับที่สร้างโดยองค์ประกอบอาร์เรย์ ถ้าฟังก์ชันสุดท้ายแก้ไขวัตถุที่ลดค่าให้รวมฟิลด์ที่คำนวณชื่อ avg วัตถุที่แก้ไขจะถูกส่งกลับไปยังผู้ใช้ ขั้นตอน $unwind จะแบ่งเอกสารออกเป็นเอกสารสำหรับแต่ละองค์ประกอบอาร์เรย์โดยใช้ฟิลด์อาร์เรย์รายการ ขั้นตอน $project จะปรับรูปร่างเอกสารเอาต์พุตใหม่เพื่อสะท้อนเอาต์พุตของ mapreduce โดยรวมฟิลด์ -id และค่าสองฟิลด์
มันถูกเขียนทับเอกสารที่มีอยู่หากไม่มีเอกสารที่มีอยู่ด้วยคีย์เดียวกันกับผลลัพธ์ใหม่ หากคุณระบุพารามิเตอร์ out ไว้ mapReduce จะส่งคืนเอกสารเป็นเอาต์พุตในรูปแบบต่อไปนี้ หากคุณต้องการเขียนผลลัพธ์ไปยังคอลเล็กชัน อาร์เรย์ของเอกสารที่เป็นผลลัพธ์จะถูกส่งกลับหากเอาต์พุตถูกเขียนแบบอินไลน์ แต่ละเอกสารประกอบด้วยสองช่อง: ชื่อของเอกสารต้นทางและชื่อของเอกสารผู้รับ เมื่อป้อนค่าคีย์ในฟิลด์ -id ฟิลด์ค่าจะถูกสร้างขึ้นเพื่อลดหรือสรุปค่าคีย์
สิ่งที่ปล่อยออกมาใน Mongodb?
ในฐานะที่เป็นฟังก์ชันแผนที่ ฟังก์ชันแผนที่สามารถเรียก emits (คีย์, ค่า) ได้ตลอดเวลาเพื่อสร้างเอกสารเอาต์พุตที่มีคีย์และค่า การปล่อยไฟล์เดียวใน MongoDB 4.2 และรุ่นก่อนหน้าสามารถเก็บไฟล์ BSON ของ MongoDB ได้เพียงครึ่งหนึ่งของขนาดสูงสุด ตั้งแต่เวอร์ชัน 4.4 ของ MongoDB ข้อจำกัดจะถูกลบออก
เหตุใด Mongodb จึงเป็นตัวเลือกที่ดีที่สุดสำหรับข้อมูลที่ยืดหยุ่นและปรับขนาดได้
เนื่องจากไม่มีสคีมาที่แข็งแกร่ง MongoDB จึงมักเชื่อมโยงกับ NoSQL เนื่องจากไม่มีสคีมาที่แข็งแกร่ง ข้อมูลสามารถจัดเก็บในรูปแบบใดก็ได้ที่สะดวกสำหรับแอปพลิเคชัน ความยืดหยุ่นของฐานข้อมูลให้ข้อได้เปรียบที่สำคัญเมื่อขยายขนาดขึ้นหรือลง เนื่องจากหมายความว่าสามารถจัดเก็บข้อมูลในลักษณะที่ปรับให้เหมาะกับความต้องการของแอปพลิเคชัน
สามารถใช้ไดอะแกรมข้อมูลที่มีไดอะแกรม ER เพื่อแสดงภาพความสัมพันธ์ระหว่างส่วนต่างๆ ของข้อมูล แผนภาพ ER แสดงชุดของโหนดที่เป็นตัวแทนของชุดข้อมูล และการเชื่อมต่อระหว่างโหนดเหล่านี้ทำหน้าที่เป็นตัวระบุ
ไม่มีการบังคับใช้ความสัมพันธ์ใน MongoDB เนื่องจากไม่ใช่ฐานข้อมูลเชิงสัมพันธ์ แผนภาพ ER แสดงความสัมพันธ์ที่มีอยู่ภายในข้อมูล และยังช่วยในการแสดงภาพข้อมูลเหล่านั้นด้วย
MongoDB เป็นตัวเลือกที่ยอดเยี่ยมสำหรับข้อมูลที่ยืดหยุ่นและปรับขนาดได้ ความยืดหยุ่นช่วยให้สามารถจัดเก็บข้อมูลในลักษณะที่เหมาะสมสำหรับแอปพลิเคชัน และความสามารถในการปรับขนาดช่วยให้สามารถจัดการชุดข้อมูลขนาดใหญ่ได้อย่างรวดเร็วและง่ายดาย
แผนที่ลดตัวอย่าง Mongodb
ใน MongoDB map-reduce เป็นกระบวนทัศน์การประมวลผลข้อมูลสำหรับการรวมข้อมูลจากคอลเล็กชัน คล้ายกับแผนที่และลดฟังก์ชันในการเขียนโปรแกรมเชิงฟังก์ชัน
การดำเนินการลดแผนที่มีสองขั้นตอน:
1. ขั้นตอนแผนที่ใช้ฟังก์ชันการทำแผนที่กับเอกสารแต่ละฉบับในคอลเลกชัน ฟังก์ชันการแมปปล่อยหนึ่งหรือหลายออบเจกต์สำหรับแต่ละเอกสารอินพุต
2. เฟสการลดใช้ฟังก์ชันลดขนาดกับเอกสารที่เผยแพร่โดยเฟสแผนที่ ฟังก์ชันลดรวมวัตถุและสร้างวัตถุเดียวเป็นเอาต์พุต
ตัวอย่างเช่น พิจารณาชุดของบทความ เราสามารถใช้ map-reduce เพื่อคำนวณจำนวนคำในแต่ละบทความ
ขั้นแรก เรากำหนดฟังก์ชันการแมปที่ให้คู่คีย์-ค่าสำหรับแต่ละเอกสาร โดยที่คีย์คือรหัสบทความ และค่าคือจำนวนคำในบทความ
ต่อไป เรากำหนดฟังก์ชันลดที่รวมค่าสำหรับแต่ละคีย์
สุดท้าย เราดำเนินการลดแผนที่ในคอลเลกชัน ผลลัพธ์คือเอกสารที่มีข้อมูลรวม
ในมองโกชมีฐานข้อมูล เมธอด mapReduce() เป็นตัวตัดรอบคำสั่ง mapReduce มีตัวอย่างมากมายในส่วนนี้ เช่น ทางเลือกไปป์ไลน์การรวมที่ไม่มีนิพจน์การรวมแบบกำหนดเอง สามารถแปลแผนที่ด้วยนิพจน์ที่กำหนดเองได้โดยใช้ Map-Reduce to Aggregation Pipeline Translation Examples การดำเนินการลดขนาดแผนที่สามารถเปลี่ยนแปลงได้โดยไม่ต้องกำหนดฟังก์ชันแบบกำหนดเองโดยใช้ตัวดำเนินการไปป์ไลน์การรวมที่มีอยู่ สามารถใช้ฟังก์ชันแผนที่เพื่อประมวลผลเอกสารแต่ละรายการในอินพุตได้ แต่ละรายการมีค่าอ็อบเจกต์ของตัวเองที่เชื่อมโยงกับค่าใหม่ที่มีหมายเลข 1 หมายเลขจำนวนสำหรับคำสั่งซื้อ และรายการของรายการ
ถ้าคีย์ในเอกสารปัจจุบันเหมือนกับคีย์ในเอกสารใหม่ การดำเนินการจะเขียนทับเอกสารนั้น คุณสามารถเขียนการดำเนินการลดขนาดแผนที่ใหม่ได้โดยใช้ตัวดำเนินการไปป์ไลน์การรวม แทนที่จะกำหนดฟังก์ชันแบบกำหนดเอง ขั้นตอน $unwind แบ่งเอกสารตามฟิลด์อาร์เรย์ items ส่งผลให้เอกสารสำหรับแต่ละองค์ประกอบอาร์เรย์ เมื่อขั้นตอน $project ปรับเปลี่ยนรูปร่างของเอกสารเอาต์พุต เอาต์พุตของ map-reduce จะถูกทำมิเรอร์ การดำเนินการเขียนทับเอกสารที่มีอยู่ซึ่งมีคีย์เดียวกันกับผลลัพธ์ใหม่
ฟังก์ชัน Mapper ใน Hadoop คืออะไร
ในฐานะที่เป็นตัวลด คุณต้องรวมข้อมูลจากตัวทำแผนที่เพื่อสร้างคำตอบที่เป็นหนึ่งเดียว เอาต์พุตแบบลดขนาดจะเกิดขึ้นเมื่อชุดของเอาต์พุตแผนที่ได้รับการยอมรับเป็นอินพุต ซึ่งแต่ละชุดจะแทนเซ็ตย่อยของผลลัพธ์ที่สร้างขึ้น
Mapper ใช้เพื่อแบ่งข้อมูลออกเป็นส่วนๆ ที่สามารถจัดการได้ จากนั้นกำหนดแต่ละส่วนให้กับงานตามขนาดของมัน ฟังก์ชัน mapper ได้รับข้อมูลอินพุตซึ่งมีพารามิเตอร์ที่ระบุงานที่ต้องดำเนินการ
ชุดของรายการสอดคล้องกับกลุ่มข้อมูลที่แมปโดยแมปในเอาต์พุต เป็นผลให้เอาต์พุตแผนที่ถูกส่งต่อไปยังตัวลด ซึ่งจะแปลงเป็นเอาต์พุตตัวลด
ข้อผิดพลาดยังได้รับการจัดการโดยฟังก์ชัน mapper ตัวทำแผนที่จะส่งคืนเอาต์พุตข้อผิดพลาดในกรณีนี้ ซึ่งไม่ใช่เอาต์พุตแผนที่ เนื่องจากตัวลดไม่สามารถประมวลผลข้อมูลนี้ได้ ตัวทำแผนที่จะส่งกลับข้อความแสดงข้อผิดพลาด
ระบบนิเวศ Hadoop
ระบบนิเวศ Hadoop เป็นแพลตฟอร์มสำหรับการประมวลผลและจัดเก็บข้อมูลขนาดใหญ่ ประกอบด้วยองค์ประกอบต่างๆ มากมาย ซึ่งแต่ละองค์ประกอบมีบทบาทเฉพาะในการประมวลผลและจัดเก็บข้อมูล ส่วนประกอบที่สำคัญที่สุดของระบบนิเวศคือ Hadoop Distributed File System (HDFS), MapReduce framework และ Hadoop Common library