
Master-Slave Vs Multi-Master Replication ในฐานข้อมูล NoSQL
เผยแพร่แล้ว: 2023-01-13มีการจำลองแบบหลายประเภทที่ฐานข้อมูล NoSQL รองรับ ประเภทของการจำลองแบบที่พบบ่อยที่สุดคือการจำลองแบบมาสเตอร์-ส เลฟ ในการจำลองแบบนี้ มีเซิร์ฟเวอร์หลักหนึ่งเครื่องที่มีข้อมูลทั้งหมด จากนั้นเซิร์ฟเวอร์ทาสจะจำลองข้อมูลจากเซิร์ฟเวอร์หลัก การจำลองแบบนี้ทำได้ง่ายมากและตั้งค่าได้ง่าย นอกจากนี้ยังมีประสิทธิภาพมากและให้ประสิทธิภาพที่ดี การจำลองแบบอีกประเภทหนึ่งที่ฐานข้อมูล NoSQL รองรับคือการจำลองแบบหลายหลัก ในการจำลองแบบนี้ มีเซิร์ฟเวอร์หลักหลายตัว เซิร์ฟเวอร์หลักแต่ละเครื่องมีสำเนาของข้อมูล จากนั้นเซิร์ฟเวอร์สเลฟจะจำลองข้อมูลจากเซิร์ฟเวอร์หลักทั้งหมด การจำลองแบบนี้มีความซับซ้อนในการตั้งค่ามากกว่า แต่ให้ประสิทธิภาพที่ดีกว่าและทนทานต่อข้อผิดพลาดมากกว่า
นอกจาก NoSQL Data Replication แล้ว ยังมีคุณลักษณะที่มีประสิทธิภาพซึ่งช่วยให้คุณสามารถคัดลอกและจัดเก็บข้อมูลที่มีโครงสร้าง ไม่มีโครงสร้าง และกึ่งโครงสร้างในกรณีที่เซิร์ฟเวอร์ขัดข้อง ค้นพบวิธีใช้ฐานข้อมูล NoSQL ในกระบวนการทีละขั้นตอนง่ายๆ
การจำลองแบบข้อมูล: เนื่องจากข้อมูลถูกจำลองแบบจากเซิร์ฟเวอร์หนึ่งไปยังอีกเซิร์ฟเวอร์หนึ่ง ข้อมูลแต่ละบิตจึงสามารถพบได้ในเซิร์ฟเวอร์หลายเครื่อง กระบวนการจำลองแบบ แบ่งออกเป็นสองขั้นตอน: การจำลองแบบมาสเตอร์-สเลฟ และการจำลองแบบแบบรับรู้โดยทาส การจำลองแบบ Master-Slave กำหนดให้โหนดหนึ่งโหนดมีอำนาจในการจัดการการเขียน ขณะที่การจำลองแบบแบบ Slave-Aware ช่วยให้ Slave สามารถอ่านและซิงโครไนซ์กับต้นแบบได้
MySQL รวมการ จำลองแบบอะซิงโครนัส ทางเดียว ซึ่งเซิร์ฟเวอร์หนึ่งทำหน้าที่เป็นต้นทางและอีกเซิร์ฟเวอร์หนึ่งทำหน้าที่เป็นแบบจำลอง
Replication Factor (RF) ตามชื่อหมายถึง คือจำนวนโหนดที่ข้อมูล (แถวและพาร์ติชัน) ถูกจำลองแบบ หลายโหนด (RF=N) เชื่อมต่อกับการส่งข้อมูล RF ของหนึ่งบ่งชี้ว่ามีเพียงหนึ่งสำเนาของแถวในคลัสเตอร์ และไม่มีวิธีการกู้คืนข้อมูลหากโหนดขัดข้องหรือถูกบุกรุก
Sharding และการจำลองแบบใน Nosql คืออะไร
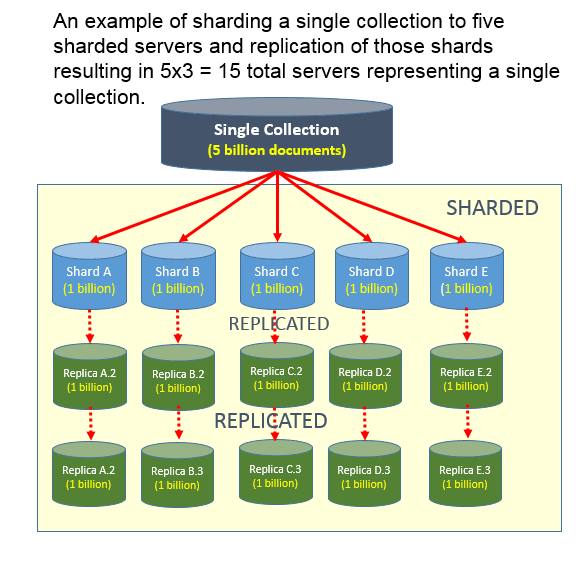
อะไรคือความแตกต่างระหว่างการแบ่งส่วนย่อยและการจำลองแบบ? การจำลองข้อมูลเกิดขึ้นเมื่อโหนดเซิร์ฟเวอร์หลักและโหนดเซิร์ฟเวอร์รองแลกเปลี่ยนข้อมูล เป็นการสำรองข้อมูลในกรณีที่เซิร์ฟเวอร์หลักล้มเหลว สิ่งนี้สามารถช่วยเพิ่มความพร้อมใช้งานของข้อมูล ความสามารถในการปรับขนาดในแนวนอนระหว่างเซิร์ฟเวอร์จะขึ้นอยู่กับการใช้คีย์ชาร์ด
ฐานข้อมูล SQL ช่วยให้คุณสามารถแบ่งชุดข้อมูลออกเป็นตาราง แล้วสร้างพาร์ติชันสำหรับแต่ละตาราง ฐานข้อมูล NoSQL เช่น MongoDB ไม่มีตาราง แต่มีชุดเอกสารแทน คำสั่ง mongo shard ใช้เพื่อแยกคอลเลกชัน MongoDB คุณสามารถกระจายโหลดไปยังเซิร์ฟเวอร์หลายเครื่องในสภาพแวดล้อมการแบ่งส่วนข้อมูลเดียว ซึ่งส่งผลให้ประสิทธิภาพการทำงานดีขึ้น เมื่อพูดถึงชุดข้อมูลขนาดใหญ่ นี่เป็นเรื่องจริงโดยเฉพาะอย่างยิ่ง นอกจากนี้ การแบ่งส่วนข้อมูลยังช่วยในการจัดการและรักษาความปลอดภัยชุดข้อมูลขนาดใหญ่โดยการให้ความสมบูรณ์ของข้อมูล นอกเหนือจากการปรับขนาดข้อมูลของคุณแล้ว Sharding ยังเป็นเครื่องมือที่ยอดเยี่ยมสำหรับการจัดการข้อมูลอย่างมีประสิทธิภาพ รูปแบบนี้ใช้กันอย่างแพร่หลายในฐานข้อมูล NoSQL เนื่องจากง่ายต่อการใช้งานและการสนับสนุนในวงกว้าง
เหตุใด Sharding จึงดีกว่าสำหรับการเขียนข้อมูล
โดยทั่วไป การจำลองแบบอนุญาตให้ปรับขนาดการอ่านในแนวนอนได้ แต่ไม่อนุญาตให้ปรับขนาดข้อมูลข้ามเซิร์ฟเวอร์หลายเครื่องด้วยคีย์เดียว ในขณะที่การแบ่งส่วนทำได้
Nosql รองรับข้อมูลประเภทใด
ฐานข้อมูล NoSQL ได้รับความนิยมเพิ่มขึ้นเนื่องจากรองรับประเภทข้อมูลที่หลากหลาย ซึ่งรวมถึงประเภทข้อมูลแบบดั้งเดิม เช่น ตัวเลขและสตริง ตลอดจนประเภทข้อมูลที่ใหม่กว่า เช่น JSON และ XML ฐานข้อมูล NoSQL ยังรองรับภาษาการเขียนโปรแกรมที่หลากหลาย ทำให้เป็นตัวเลือกที่ดีสำหรับบริษัทที่ใช้หลายภาษา
ในฐานข้อมูล NoSQL มีสี่ประเภท: คู่คีย์-ค่า คอลัมน์ กราฟ และเอกสาร ทุกหมวดหมู่มีลักษณะเฉพาะและข้อจำกัดของตัวเอง ฐานข้อมูล MongoDB เป็น ฐานข้อมูล NoSQL ที่ได้รับความนิยม นี่คือฐานข้อมูลคู่คีย์-ค่าที่เก็บทั้งสองคู่ แอปพลิเคชันนี้ใช้งานง่าย ปรับขยายได้ และรวดเร็ว ฐานข้อมูลเชิงเอกสารเป็นจุดสนใจของ CouchDB แอปพลิเคชั่นนี้ใช้งานง่ายและยืดหยุ่นเพียงพอที่จะรองรับผู้ใช้หลายคน ฐานข้อมูล CouchBase เป็นแบบคอลัมน์และเน้นการทำธุรกรรม ฐานข้อมูลของ Cassandra ใช้สถาปัตยกรรมที่เน้นคอลัมน์เป็นหลัก ระบบจัดเก็บข้อมูล HBase เป็นโซลูชันการจัดเก็บข้อมูลที่ปรับขนาดได้ กระจาย และระดับเพตะไบต์สำหรับชุดข้อมูลขนาดใหญ่ เป็นฐานข้อมูลหน่วยความจำแบบกระจายที่ทำงานบน Redis การใช้ Riak เป็นที่เก็บข้อมูล คุณสามารถสร้างระบบโอเพ่นซอร์สที่มีประสิทธิภาพสูงได้ Neo4J เป็นฐานข้อมูลกราฟที่สร้างขึ้นบนแพลตฟอร์ม Java
เหตุใด Nosql จึงเป็นตัวเลือกที่ดีที่สุดสำหรับบริษัทที่ต้องการปรับขนาดอย่างรวดเร็ว
สำหรับธุรกิจที่ต้องการปรับขนาดอย่างรวดเร็ว NoSQL เป็นตัวเลือกที่ดีเพราะมีสถาปัตยกรรมที่ยืดหยุ่นกว่าและสามารถปรับขนาดในแนวนอนได้ นอกจากนี้ ฐานข้อมูล NoSQL ไม่ไวต่อการเปลี่ยนแปลงสคีมาเท่ากับฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิม
การจำลองข้อมูล Nosql คือ
การจำลองข้อมูล Nosql เป็นกระบวนการคัดลอกข้อมูลจากฐานข้อมูล nosql ไปยังฐานข้อมูล nosql อื่น สิ่งนี้ทำเพื่อรักษาข้อมูลให้ปลอดภัยและเพื่อให้แน่ใจว่าข้อมูลนั้นพร้อมใช้งานเสมอในกรณีที่เกิดความล้มเหลว
Nosql เทียบกับ Rdbms: ประสิทธิภาพไหนดีกว่ากัน?
มีงานวิจัยจำนวนมากขึ้นเรื่อยๆ ที่แสดงให้เห็นว่าฐานข้อมูล NoSQL เช่น MongoDB มีประสิทธิภาพดีกว่า RDBMS แบบดั้งเดิม เทคโนโลยีนี้ช่วยให้ข้อมูลสามารถแยกย่อยและทำซ้ำได้ ทำให้เหมาะสำหรับแอปพลิเคชันที่ต้องการปริมาณงานสูงและเข้าถึงข้อมูลได้อย่างรวดเร็ว แม้ว่าบางครั้งข้อมูลสามารถทำซ้ำได้ แต่ก็ไม่สามารถทำได้เสมอไป
การจำลองแบบ Master-Slave ใน Nosql
การจำลองแบบมาสเตอร์-สเลฟเป็นการจำลองแบบประเภทหนึ่งที่ข้อมูลถูกคัดลอกจากเซิร์ฟเวอร์หลัก (“มาสเตอร์”) ไปยังเซิร์ฟเวอร์รอง (“ทาส”) หนึ่งเซิร์ฟเวอร์หรือมากกว่า เซิร์ฟเวอร์สเลฟสามารถใช้สำหรับการดำเนินการอ่านได้ แต่ต้องส่งการดำเนินการเขียนทั้งหมดไปยังมาสเตอร์ การจำลองแบบนี้มักใช้ในฐานข้อมูล Nosql เนื่องจากมีความพร้อมใช้งานสูงและสามารถปรับขยายได้ ตัวอย่างเช่น หากเซิร์ฟเวอร์หลักหยุดทำงาน ทาสยังคงสามารถใช้เพื่อให้บริการคำขออ่านได้ และหากต้องการความสามารถในการอ่านมากขึ้น ก็สามารถเพิ่มเซิร์ฟเวอร์สเลฟเพิ่มเติมได้
ความท้าทายของการจำลองแบบนาย-ทาส
อาจเป็นเรื่องยากที่จะรักษาข้อมูลบนโหนดสเลฟทั้งหมดในโมเดลการจำลองแบบมาสเตอร์-สเลฟ หากโหนดสเลฟตัวใดตัวหนึ่งหยุดทำงาน ข้อมูลบนโหนดสเลฟนั้นจะสูญหาย
โมเดลจำลองแบบใดที่รองรับการอ่านและเขียนฐานข้อมูลในทุกโหนด
โมเดลการจำลองแบบที่รองรับการดำเนินการอ่านและเขียนฐานข้อมูลในโหนดทั้งหมดคือ แบบจำลองการจำลองแบบมาสเตอร์ -มาสเตอร์ โมเดลนี้อนุญาตให้แต่ละโหนดทำหน้าที่เป็นมาสเตอร์ หมายความว่าแต่ละโหนดสามารถอ่านและเขียนลงในฐานข้อมูลได้ สิ่งนี้มีประโยชน์สำหรับองค์กรที่ต้องการความพร้อมใช้งานสูงและความซ้ำซ้อน เนื่องจากโหนดทั้งหมดสามารถทำงานต่อไปได้แม้ว่าโหนดหนึ่งจะหยุดทำงาน

แอปพลิเคชันรุ่นใดที่รองรับการดำเนินการอ่านและเขียนฐานข้อมูลในโน้ตทั้งหมด
โดยทั่วไปแล้ว RDBMS จะใช้โมเดล schema-on-write ซึ่งมีการกำหนดโครงสร้างข้อมูลล่วงหน้า และการดำเนินการอ่านและเขียนทั้งหมดจะขึ้นอยู่กับโครงสร้างนั้น
การเปลี่ยนแปลงฐานข้อมูลและการอัปเดตสามารถเกิดขึ้นได้ในโหมดอ่าน-เขียน
การเปลี่ยนแปลงและการอัปเดตสามารถเกิดขึ้นได้ในโหมดอ่าน/เขียน เมื่อเปิดฐานข้อมูลในโหมดอ่าน/เขียน ซึ่งควบคุมโดย OpenReadWrite() หรือ OpenWrite DatabaseReader เป็นคลาสที่สามารถใช้เพื่ออ่านและเขียนข้อมูลลงในฐานข้อมูล ข้อมูลสามารถเขียนลงในฐานข้อมูลได้โดยใช้วัตถุ DatabaseWriter
ฐานข้อมูลประเภทใดที่สนับสนุนโหนดที่เชื่อมต่อกันด้วยความสัมพันธ์
ความสัมพันธ์สามารถจัดเก็บและเข้าถึงได้ในฐานข้อมูลกราฟโดยใช้ความสัมพันธ์ที่มีโครงสร้าง ความสัมพันธ์เป็นแง่มุมที่มีค่าที่สุดของฐานข้อมูลกราฟ เนื่องจากเป็นข้อมูลพลเมืองที่มีค่าที่สุด โหนดใช้ในฐานข้อมูลกราฟเพื่อจัดเก็บเอนทิตีข้อมูลและเอดจ์ใช้เพื่อเชื่อมต่อเอนทิตี
Mongodb และ Node.js: การจับคู่ที่สมบูรณ์แบบสำหรับการทำงานกับกราฟใน Javascript
หากคุณต้องการใช้กราฟใน JavaScript คุณควรใช้ MongoDB MongoDB เป็นฐานข้อมูล NoSQL ที่ได้รับความนิยมสูงสุด ในขณะที่ Node.js ยังเป็นภาษาโปรแกรม JavaScript ที่ได้รับความนิยมอีกด้วย
การจำลองแบบฐานข้อมูลที่ไม่ใช่เชิงสัมพันธ์ทำงานอย่างไร
ใน อินสแตนซ์ Peer-to- Peer NoSQL Data Replication ข้อมูลจะถูกจำลองจากฐานข้อมูลหนึ่งไปยังอีกฐานข้อมูลหนึ่งตามแนวคิดที่ว่าแต่ละสำเนาจะต้องอัปเดตสำเนาของตนเองอยู่เสมอ ครั้งเดียวที่สามารถใช้งานได้คือหากแต่ละสำเนาของสคีมาจัดเก็บข้อมูลประเภทเดียวกันในรูปแบบเดียวกัน ลักษณะสำคัญอื่น ๆ ของวิธีการจำลองข้อมูลนี้คือการกู้คืนฐานข้อมูล
การจำลองแบบประเภทต่างๆ
*br *Storage replication *br เป็นการจำลองประเภทที่เก็บการเปลี่ยนแปลงข้อมูลในลักษณะที่สอดคล้องกัน เซิร์ฟเวอร์แบบจำลองต้นทางสร้างสแน็ปช็อตของฐานข้อมูลพร้อมข้อมูลสถานะปัจจุบันหลังจากสร้าง จากนั้น สแน็ปช็อตจะถูกส่งไปยังเซิร์ฟเวอร์จำลองปลายทาง หลังจากสแน็ปช็อต เซิร์ฟเวอร์จำลองปลายทางจะสร้างสำเนาใหม่ของฐานข้อมูล การอ้างอิงการจำลองแบบของธุรกรรมในข้อมูล ธุรกรรมจะถูกจัดเก็บไว้ในข้อมูลที่เปลี่ยนแปลงบ่อยและสามารถจำลองได้โดยใช้การจำลองแบบของธุรกรรม ธุรกรรมถูกแบทช์เข้าด้วยกันและทำซ้ำในชุดเดียว การเปลี่ยนแปลงข้อมูลจะถูกทำซ้ำโดยกระบวนการที่เรียกว่าการจำลองแบบ การจำลองแบบเพียร์ทูเพียร์สามารถทำได้ผ่านการใช้เซิร์ฟเวอร์ การจำลองแบบข้อมูลแบบ Peer-to-Peer เป็นการจำลองข้อมูลประเภทหนึ่งที่มีจุดประสงค์เพื่อทำซ้ำข้อมูลที่ไม่มีการเปลี่ยนแปลงบ่อยครั้ง ในการจำลองข้อมูลแบบเพียร์ทูเพียร์ กลุ่มของโหนดจะจำลองข้อมูล แต่ละโหนดในคลัสเตอร์มีโมเดลข้อมูลของตัวเอง โหนดคลัสเตอร์ไม่รู้จักซึ่งกันและกัน
การจำลองฐานข้อมูลเอกสาร Nosql
ฐานข้อมูลเอกสาร Nosql ได้รับการออกแบบมาเพื่อให้มีความพร้อมใช้งานสูงและปรับขนาดได้โดยการจำลองข้อมูลข้ามเซิร์ฟเวอร์หลายเครื่อง สิ่งนี้ทำให้ฐานข้อมูลสามารถดำเนินการต่อไปได้แม้ว่าเซิร์ฟเวอร์อย่างน้อยหนึ่งเซิร์ฟเวอร์จะล้มเหลว
ฐานข้อมูล Nosql ขนาดใหญ่
ไม่มีคำตอบที่ชัดเจนสำหรับคำถามนี้ เนื่องจากขึ้นอยู่กับความต้องการเฉพาะของผู้ใช้ อย่างไรก็ตาม ฐานข้อมูล nosql ขนาดใหญ่ที่ได้รับความนิยม มากที่สุด ได้แก่ MongoDB, Cassandra และ Hadoop ฐานข้อมูลเหล่านี้ได้รับการออกแบบมาเพื่อให้สามารถปรับขนาดได้และมีประสิทธิภาพสูง ทำให้เหมาะสำหรับการประมวลผลข้อมูลขนาดใหญ่
ตัวอย่างเช่น ฐานข้อมูล NoSQL เช่น MongoDB เหมาะสำหรับข้อมูลขนาดใหญ่เนื่องจากสามารถจัดการข้อมูลจำนวนมากได้อย่างรวดเร็วและง่ายดาย เนื่องจาก MongoDB เป็น MongoDB ที่เน้นเอกสาร จึงสามารถจัดการข้อมูลจำนวนมหาศาลได้ กล่าวอีกนัยหนึ่ง MongoDB สามารถจัดการข้อมูลในรูปแบบต่างๆ รวมถึง JSON, BSON และ JavaScript Object Notation (JSON) นอกจากนี้ยังทำให้เข้าถึงและจัดเก็บข้อมูลได้ง่าย นอกจากนี้ MongoDB ยังปรับขนาดได้ ซึ่งหมายความว่าสามารถประมวลผลข้อมูลจำนวนมากได้
ฐานข้อมูล Nosql ใดที่ดีที่สุดสำหรับข้อมูลขนาดใหญ่
พวกเขาสร้างรูปแบบที่เครื่องมือวิเคราะห์สามารถใช้เพื่อแปลงข้อมูลที่ไม่มีโครงสร้างและกึ่งโครงสร้างเป็นรูปแบบที่สามารถใช้ในแอปพลิเคชันได้ ข้อกำหนดเฉพาะสำหรับการจัดเก็บข้อมูลขนาดใหญ่ทำให้ฐานข้อมูล NoSQL (ไม่ใช่เชิงสัมพันธ์) เช่น MongoDB เป็นตัวเลือกที่ยอดเยี่ยม
ทำไม Mongodb จึงเป็นตัวเลือกที่ดีที่สุดสำหรับการจัดเก็บข้อมูลขนาดใหญ่
MongoDB เป็นตัวเลือกที่ยอดเยี่ยมสำหรับการจัดเก็บและจัดการข้อมูลจำนวนมาก การดำเนินการ CRUD (สร้าง อ่าน อัปเดต ลบ) กรอบการรวม การค้นหาข้อความ และคุณสมบัติลดขนาดแผนที่ทำให้ผู้ใช้เข้าถึง จัดการ และวิเคราะห์ข้อมูลได้ง่าย
Big Data Nosql คืออะไร?
หากปริมาณงานข้อมูลของคุณเน้นที่การประมวลผลอย่างรวดเร็วและการวิเคราะห์ข้อมูลที่หลากหลายและไม่มีโครงสร้างจำนวนมาก เช่น Big Data NoSQL เป็นตัวเลือกที่ดีกว่า ฐานข้อมูล NoSQL ไม่มีข้อจำกัดประเภทข้อมูลเหมือนกับฐานข้อมูลเชิงสัมพันธ์
เหตุใดฐานข้อมูล Nosql จึงเป็นอนาคตของการจัดการข้อมูล
ฐานข้อมูล NoSQL กำลังเป็นที่นิยมมากขึ้น อันเป็นผลจากข้อได้เปรียบด้านประสิทธิภาพที่สำคัญเหนือฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิม เป็นตัวเปิดใช้งานฐานข้อมูล NoSQL ที่เปิดใช้งานฐานข้อมูล NoSQL บางประเภท เช่น HBase ทำให้สามารถกระจายข้อมูลผ่านเซิร์ฟเวอร์หลายพันเครื่องโดยไม่ลดประสิทธิภาพ แพลตฟอร์มระบบคลาวด์ (GCP) ของ Google ให้บริการฐานข้อมูลที่หลากหลาย ซึ่งมีความสามารถพิเศษในการประมวลผลชุดข้อมูลไดนามิกขนาดใหญ่มากโดยไม่จำเป็นต้องใช้สคีมา
บริษัทใหญ่ ๆ ใช้ Nosql หรือไม่?
เทคโนโลยีฐานข้อมูลที่อิงกับ Cloud Computing, เว็บ, Big Data และ Big Users ด้วยการเสนอ NoSQL เป็นทางเลือกแทน RDBMS แบบดั้งเดิม NoSQL จึงกลายเป็นตัวเลือกที่ใช้งานได้สำหรับบริษัทอินเทอร์เน็ตยอดนิยมหลายแห่ง เช่น LinkedIn, Google, Amazon และ Facebook
Nosql คืออนาคตสำหรับฐานข้อมูลแบ็กเอนด์ของ Instagram หรือไม่
ณ จุดนี้ Instagram ดูเหมือนจะชอบ PostgreSQL เป็นฐานข้อมูลหลักเป็นแบ็กเอนด์หลัก แม้ว่าสิ่งนี้อาจเปลี่ยนแปลงได้ Cassandra ซึ่งเป็นฐานข้อมูล NoSQL ยอดนิยม อาจเหมาะสมที่สุดสำหรับ Instagram หรือไม่ก็ได้ Cassandra เป็นเครื่องมือที่ยอดเยี่ยมสำหรับการจัดเก็บข้อมูลจำนวนมาก แต่มีประวัติการทำงานที่ย่ำแย่
ในขณะนี้ เป็นเรื่องยากที่จะคาดเดาว่า Instagram จะใช้ฐานข้อมูล NoSQL เป็นฐานข้อมูลแบ็กเอนด์หลักหรือไม่ PostgreSQL และ Cassandra เป็นตัวเลือกที่ยอดเยี่ยม แต่ไม่สามารถแข่งขันกับ SQL ในแง่ของประสิทธิภาพได้