
ฐานข้อมูล NoSQL: อิมพาลา
เผยแพร่แล้ว: 2023-03-03NoSQL เป็นคำที่ใช้อธิบายฐานข้อมูลที่ไม่ได้ใช้โครงสร้างฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิม ฐานข้อมูล NoSQL มักได้รับการออกแบบมาเพื่อให้โซลูชันที่เรียบง่ายและปรับขนาดได้มากขึ้น
Impala เป็นฐานข้อมูล NoSQL ที่ออกแบบมาเพื่อมอบโซลูชันที่รวดเร็วและปรับขนาดได้สำหรับการจัดการชุดข้อมูลขนาดใหญ่ Impala ใช้โมเดลข้อมูล Google Bigtable และใช้รูปแบบการจัดเก็บแบบคอลัมน์ Impala พร้อมใช้งานเป็นโครงการโอเพ่นซอร์สและสนับสนุนโดย Cloudera
Apache Impala เป็นเครื่องมือสืบค้น SQL แบบโอเพ่นซอร์สที่ติดตั้งบนคลัสเตอร์ Hadoop และดำเนินการประมวลผลแบบขนานขนาดใหญ่ (MPP) สำหรับข้อมูลที่จัดเก็บไว้ในระบบ เดิมพัฒนาในปี 2012 โครงการโอเพ่นซอร์สนี้เรียกว่า "Microsoft Formula 1"
แพลตฟอร์ม Impala ช่วยให้ผู้ใช้สามารถดำเนินการสืบค้น SQL ที่มีความหน่วงแฝงต่ำไปยัง ข้อมูล Hadoop ที่จัดเก็บไว้ใน HDFS และ Apache HBase โดยไม่ต้องย้ายหรือแปลงข้อมูล
Impala Sql ขึ้นอยู่กับหรือไม่
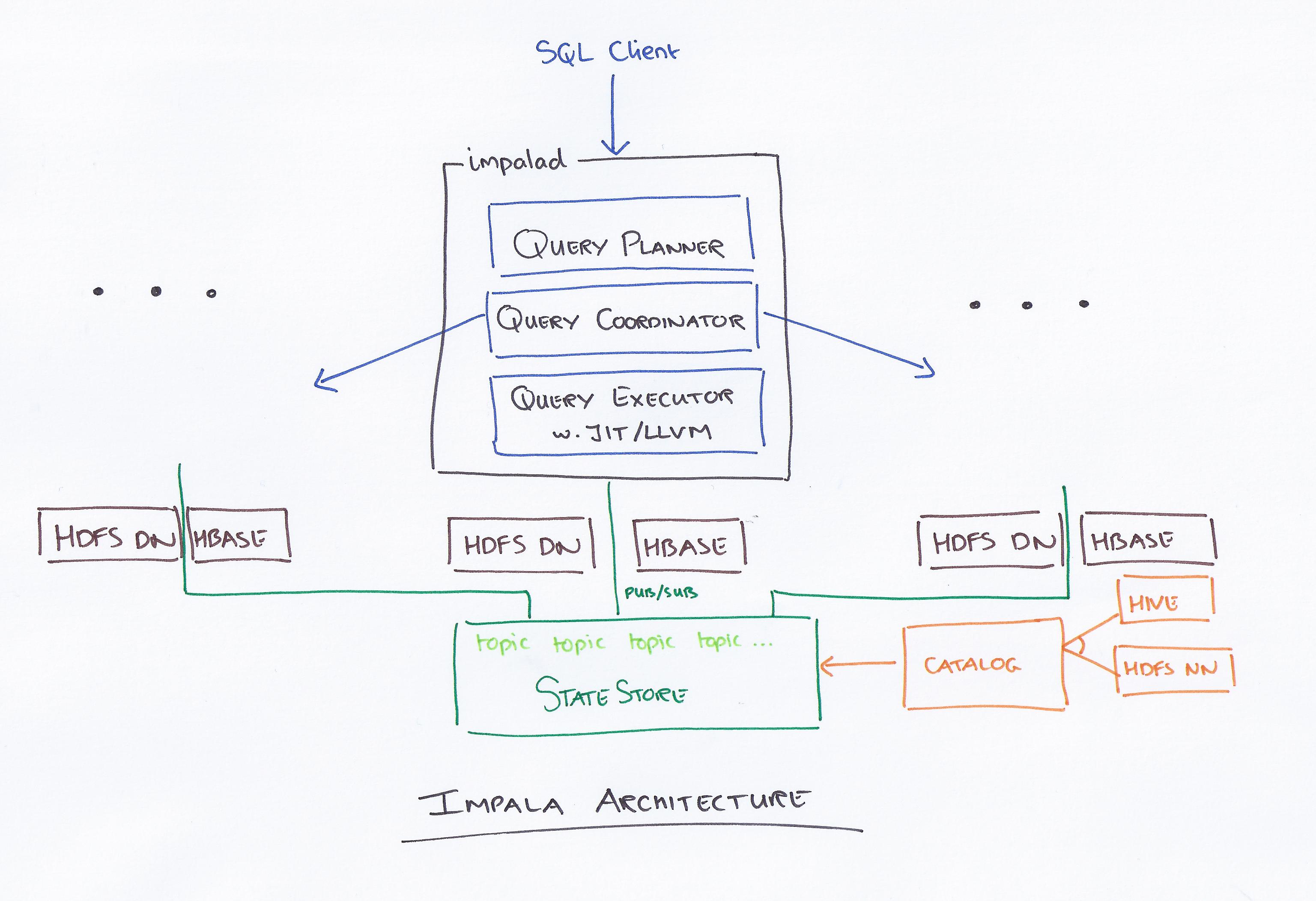
Impala เป็นเครื่องมือสืบค้นที่ใช้ SQL ซึ่งทำงานบน Apache Hadoop ช่วยให้ผู้ใช้สามารถสืบค้นข้อมูลที่จัดเก็บไว้ใน HDFS และ HBase โดยใช้ SQL Impala ให้ประสิทธิภาพสูงและเวลาแฝงต่ำเมื่อเทียบกับ เครื่องมือสืบค้น Hadoop อื่นๆ เช่น Hive และ Pig
ฐานข้อมูล MPP สำหรับการวิเคราะห์ของ Impala ให้ข้อมูลเชิงลึกเกี่ยวกับเวลาที่รวดเร็วที่สุดในอุตสาหกรรม มีการรวมเข้ากับ CDH และสามารถเข้าถึงได้ผ่าน Cloudera Enterprise ฐานข้อมูล MPP สำหรับ Apache Hadoop เช่น Impala ใช้ HDFS เพื่อให้ข้อมูลเชิงลึกเร็วขึ้น
อิมพาลาเป็นฐานข้อมูล
เป็นฐานข้อมูลที่ผมเชื่อว่า
Impala เป็นเครื่องมือ Etl หรือไม่?
Impala ไม่ใช่เครื่องมือ ETL แต่เป็นเครื่องมือสืบค้น SQL ที่สามารถใช้ทำการสืบค้น SQL หลังจากล้างข้อมูลผ่านกระบวนการแล้ว
Apache Impala ใช้สำหรับอะไร?
เราสามารถอ่านข้อมูลจากแหล่งต่างๆ โดยใช้อิมพาลาโดยใช้การสืบค้นที่คล้ายกับ SQL Apache Impala ทำงานได้ดีกว่า Hive และเอ็นจิ้น SQL อื่นๆ เมื่อพูดถึงการเข้าถึงข้อมูลที่จัดเก็บไว้ใน Hadoop Distributed File System เราใช้ Impala เพื่อจัดเก็บข้อมูลใน Hadoop HBase, HDFS และ Amazon S3
19 บริษัทที่ใช้ Apache Impala ใน Tech Stacks ของพวกเขา
Apache Impala เป็น เครื่องมือประมวลผลข้อมูลยอดนิยม สำหรับธุรกิจขนาดใหญ่หลายแห่ง ตามรายงาน บริษัทเทคโนโลยี 19 แห่ง รวมถึง Stripe, Agoda และ Expedia.com ใช้ Apache Impala แพลตฟอร์ม Impala มีความยืดหยุ่นและมีประสิทธิภาพ สามารถจัดการชุดข้อมูลขนาดใหญ่ได้อย่างรวดเร็วและมีประสิทธิภาพ การใช้อย่างแพร่หลายของเครื่องมือนี้แสดงให้เห็นว่าเครื่องมือนี้มีประโยชน์อย่างไร และมีประโยชน์อย่างไรในการประมวลผลข้อมูล
อะไรคือความแตกต่างระหว่าง sql Hive และ Impala?
เป้าหมายของ Hive คือจัดการกับการสืบค้นที่ใช้เวลานานซึ่งต้องการการแปลงและการรวมหลายรายการ เนื่องจากมีเวลาแฝงต่ำและความสามารถในการจัดการข้อความค้นหาที่มีขนาดเล็ก เครื่องมือประมวลผลข้อความค้นหาของ Impala จึงเหมาะอย่างยิ่งสำหรับการประมวลผลแบบโต้ตอบ Spark รองรับทั้งข้อความค้นหาระยะสั้นและระยะยาวนอกเหนือจากข้อความค้นหาระยะสั้นและระยะยาว
Hive เหมาะกว่าสำหรับงานแบทช์ที่ใช้เวลานาน
วัตถุประสงค์หลักของเครื่องมือไม่ใช่เพื่อประมวลผลเป็นชุด Hive เหมาะกับการทำงานเป็นชุดระยะยาวมากกว่า Impulsa ซึ่งสามารถจัดการชุดข้อมูลที่มีขนาดเล็กกว่าได้
เป็นฐานข้อมูล Impala A
อิมพาลาเป็นฐานข้อมูลที่เก็บข้อมูลในรูปแบบคอลัมน์ ได้รับการออกแบบมาให้ปรับขนาดได้และให้ประสิทธิภาพสูงสำหรับชุดข้อมูลขนาดใหญ่
ในรุ่นแรกของ Impala รองรับประเภทข้อมูลคอลัมน์หลักต่อไปนี้: STRING, VARCHAR, VARCHAr2, INT และ FLOAT แทนที่จะเป็นตัวเลข และไม่รองรับประเภท BLOB Impala SQL-92 มีการปรับปรุงมาตรฐานมาตรฐาน SQL บางส่วน แต่ไม่ได้รวมทั้งหมด เมื่อข้อมูลมีขนาดใหญ่เกินกว่าจะผลิต จัดการ และวิเคราะห์บนเซิร์ฟเวอร์เครื่องเดียว Impala ทำงานได้ดีกว่า คลังข้อมูล อื่นๆ และรองรับการปรับขยายได้มากขึ้น ไม่จำเป็นต้องลบตำแหน่งเดิมของไฟล์ข้อมูลเมื่อโหลด Impala เนื่องจากมีน้ำหนักเบา ขั้นตอนแรกในการเรียนรู้เกี่ยวกับการทดสอบประสิทธิภาพ ความสามารถในการปรับขนาด และการกำหนดค่าคลัสเตอร์แบบหลายโหนดมักจะเป็นการรวบรวมข้อมูลจำนวนมหาศาล Cloudera Impala ได้รับการปรับให้เหมาะสมสำหรับการโหลดข้อมูลและการอ่านจำนวนมากในชุดข้อมูลขนาดใหญ่ ช่วยให้คุณทำอะไรได้มากขึ้นโดยใช้เวลาน้อยลง ขนาดบล็อกหลายเมกะไบต์ของ HDFS ช่วยให้ Impala ประมวลผลข้อมูลจำนวนมหาศาลแบบขนานในเซิร์ฟเวอร์เครือข่ายหลายเครื่อง
แทนที่จะต้องวางแผนสำหรับดัชนีมาตรฐานและเวลาและความพยายามในการสร้างดัชนี คุณจะทำในอิมพาลา เครื่องมือสืบค้นของ Impala สามารถจัดการข้อมูลจำนวนมากที่มาจากคลังข้อมูล โดยจะวิเคราะห์คลัสเตอร์และกระจายงานระหว่างโหนดเพื่อลดจำนวนทรัพยากรที่ใช้ การแบ่งพาร์ติชันของคลังข้อมูลเป็นแนวคิดที่คุ้นเคยในอิมพาลา การแบ่งพาร์ติชันช่วยลด I/O ของดิสก์และเพิ่มความสามารถในการปรับขนาดของคิวรีใน Impala จำเป็นต้องใช้ไฟล์ข้อมูลเนื่องจากคุณจะไม่สามารถเข้าถึงตารางที่มีอยู่แล้วภายในอิมพาลาได้ INSERT เป็นหนึ่งในตัวเลือกที่มีอยู่
หากต้องการสร้างโต๊ะของเล่น 2 โต๊ะ ให้ใช้คำสั่งมูลค่า หากคุณเคยใช้ซอฟต์แวร์แบบกลุ่ม คุณสามารถลองดูได้ คุณสามารถรวม เทคโนโลยี SQL-on-hadoop เข้ากับการกำหนดค่า Apache Hive ของคุณได้ ตารางไฮฟ์ในอิมพาลาไม่ได้ถูกโหลดหรือแปลงด้วยวิธีที่ใช้เวลานาน
Impala: เครื่องมือจัดการข้อมูลที่มีประสิทธิภาพสำหรับ Hadoop
ไวยากรณ์ SQL เป็นที่คุ้นเคยสำหรับผู้ใช้ Impala ซึ่งสามารถสืบค้นข้อมูลที่จัดเก็บไว้ใน HDFS และ Apache HBase ด้วยวิธีนี้ คุณสามารถใช้ Hadoop และ Impulsa แทน ฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิม นอกจากนี้ยังเป็นเครื่องมือจัดการข้อมูลที่ทรงพลังด้วยคุณสมบัติของมัน นอกจากนี้ ความสามารถของมันสำหรับชุดข้อมูลขนาดใหญ่นั้นน่าประทับใจ และสามารถจัดการกับมันได้อย่างง่ายดายมาก
อิมพาลาในข้อมูลขนาดใหญ่
Impala เป็นโอเพ่นซอร์ส เครื่องมือสืบค้น MPP SQL ที่ทำงานบน Apache Hadoop มีการสืบค้น SQL แบบโต้ตอบที่รวดเร็วบนข้อมูลที่จัดเก็บไว้ใน HDFS และ HBase Impala ได้รับการออกแบบมาเพื่อปรับปรุงประสิทธิภาพของ Apache Hadoop โดยจัดเตรียมอินเตอร์เฟส SQL แบบโต้ตอบที่รวดเร็วสำหรับข้อมูลที่จัดเก็บไว้ใน HDFS และ HBase

Impala นำโดย Cloudera เป็นระบบแบบสอบถามใหม่ Hadoop มี HDFS และ HBase จึงสามารถค้นหาข้อมูลขนาดใหญ่ระดับ PB ที่จัดเก็บไว้ที่นั่นได้ เทคโนโลยีนี้ใช้รังผึ้งและหน่วยความจำในการคำนวณ รวมทั้งคำนึงถึงคลังข้อมูล และให้การประมวลผลเป็นชุดตามเวลาจริงและการประมวลผลพร้อมกันหลายรายการ ไคลเอนต์ส่งคำขอแบบสอบถามไปยังโหนดภายในเครือข่ายอิมพาลาด ซึ่งรหัสแบบสอบถามจะถูกส่งกลับสำหรับการดำเนินการไคลเอนต์ที่ตามมา ในระหว่างขั้นตอนแรกของกระบวนการสร้างตัววิเคราะห์ แผนการดำเนินการแบบสแตนด์อโลน (แผนเครื่องเดี่ยว แผนการดำเนินการแบบกระจาย) จะถูกสร้างขึ้น และ SQL จะถูกดำเนินการด้วย เช่น การเปลี่ยนแปลงคำสั่งรวม การกดลงของเพรดิเคต และอื่นๆ โหนดทั้งหมดจะเก็บสำเนาของข้อมูลเมตาดาต้าล่าสุดเพื่อให้แน่ใจว่าคุณจะไม่ถูกละทิ้งจากลูป ก่อนใช้ Hadoop, Hive หรือ Impurbia คุณต้องติดตั้งซอฟต์แวร์ประมวลผลข้อมูลที่จำเป็นก่อน
ไฟล์การกำหนดค่าของ Impala สามารถเปลี่ยนแปลงได้ ทุกโหนดทำการเปลี่ยนแปลงการกำหนดค่าใน Impala โหนดทั้งหมดมีหน้าที่เชื่อมต่อแพ็คเกจไดรเวอร์ MySQL กับฐานข้อมูล โหนดเปลี่ยนเส้นทาง Java ของ Bigtop
การเปรียบเทียบไฮฟ์กับอิมพาลา
ยังมีข้อแตกต่างเล็กๆ น้อยๆ นอกเหนือจากข้อสำคัญสามประการนี้อีกด้วย ใน Hive มีชุดย่อยของ HiveQL ในขณะที่ใน Implicit มีชุดย่อยของ HiveQL Hive และ Impala ใช้สำหรับคลังข้อมูลและการสืบค้นแบบโต้ตอบตามลำดับ Hive ตรงกันข้ามกับ Impala ไม่ได้มีไว้สำหรับการคำนวณเชิงโต้ตอบ
อิมพาลาใน Hadoop คืออะไร
Impala เป็นเครื่องมือสืบค้น SQL แบบโอเพ่นซอร์สสำหรับข้อมูลที่จัดเก็บไว้ในคลัสเตอร์ Hadoop ได้รับการออกแบบมาเพื่อให้การสืบค้น SQL แบบโต้ตอบที่รวดเร็วบนข้อมูลที่จัดเก็บไว้ใน HDFS, HBase หรือ แหล่งข้อมูล Hadoop อื่นๆ
Impala ใช้ ส่วนประกอบ Hadoop ที่คุ้นเคย หลากหลายประเภท INSERT สามารถเขียนข้อมูลประเภทที่ Impala อ่านได้เท่านั้น ในขณะที่ SELECT สามารถอ่านข้อมูลประเภทที่ Impala อ่านได้ เมื่อใช้รูปแบบไฟล์ Avro, RCFile หรือ SequenceFile ข้อมูลจะถูกโหลดลงใน Hive สามารถใช้สถิติตารางและสถิติคอลัมน์นอกเหนือจากสถิติตารางและคอลัมน์ได้ คำสั่ง DDL และ DML ทั้งหมดจะได้รับการอัปเดตโดยอัตโนมัติโดยใช้แค็ตตาล็อก daemon ใน Impala 1.2 และสูงกว่าหากส่งผ่านแค็ตตาล็อก daemon เมธอด METADATA ที่ไม่ถูกต้องส่งคืนข้อมูลเมตาสำหรับตารางทั้งหมดใน metastore ที่เข้าถึงได้ ไฟล์ข้อมูลถูกจัดเก็บไว้ในไดเร็กทอรีสำหรับตารางใหม่ และอ่านโดยไม่คำนึงถึงชื่อไฟล์เมื่อ Impala ทำงาน
โดยรวมแล้ว Apache Hive ทำงานได้ดีในฐานะแพลตฟอร์มคลังข้อมูล ในขณะที่ Impala เหมาะกับการประมวลผลแบบขนานมากกว่า Hive นั้นทนทานต่อความผิดพลาดในขณะที่ Impulsa ไม่ใช่
อาปาเช่ อิมพาลา
Apache Impala เป็นเครื่องมือสืบค้น SQL แบบโต้ตอบที่รวดเร็วสำหรับ Apache Hadoop ช่วยให้ผู้ใช้สามารถออกคำสั่ง SQL ที่มีความหน่วงแฝงต่ำไปยังข้อมูลที่จัดเก็บไว้ใน HDFS และ Apache HBase โดยไม่ต้องมีการเคลื่อนย้ายหรือแปลงข้อมูล
แนวคิดสถาปัตยกรรมของ Impala ช่วยให้สามารถจัดการกับข้อความค้นหาแบบโต้ตอบโดยใช้ HDFS ได้อย่างมีประสิทธิภาพมากกว่าเครื่องมือสืบค้นอื่นๆ Hive นั้นช้ากว่ามากเนื่องจากการทำงานของ I/O ของดิสก์ แต่ Apache นั้นเร็วกว่ามากเพราะเป็นเอนจิ้นที่แตกต่างไปจากเดิมอย่างสิ้นเชิง ไม่มีความแตกต่างระหว่าง Impulsa และ Presto เนื่องจาก Impulsa ใช้เทคโนโลยีที่เร็วกว่ามาก และ Presto ใช้สถาปัตยกรรมที่คล้ายคลึงกัน เมื่อพูดถึงไฟล์ Parquet แล้ว Impala จะทำงานได้ดีที่สุด กำหนดว่าคุณควรแบ่งพาร์ติชันข้อมูลใดตามคำถามของนักวิเคราะห์ ด้วย Compute Stats สถิติ การสืบค้นของคุณจะง่ายขึ้นมาก โดยเฉพาะอย่างยิ่งหากเกี่ยวข้องกับมากกว่าหนึ่งตาราง (รวม) เรามีเซิร์ฟเวอร์แคตตาล็อกของ Impala ขัดข้องสี่ครั้งต่อสัปดาห์ และการสืบค้นของเราใช้เวลานานเกินกว่าจะเสร็จสิ้น
นอกจากนี้ จำนวนไฟล์ที่เราสร้างมีผลอย่างมากต่อประสิทธิภาพการค้นหาของเรา เป็นผลให้เราเริ่มจัดการพาร์ติชันของเราและรวมเข้าด้วยกันเป็นขนาดไฟล์ที่เหมาะสมที่สุดประมาณ 256MB มีการระบุไว้ว่าแต่ละพาร์ติชันมีไฟล์เดียวเท่านั้น (เว้นแต่ขนาดจะเป็น > 256MB) ควรเลือกประเภทคอลัมน์ที่เหมาะสมที่สุดจากประเภทข้อมูลทั้งหมดที่รองรับโดย Implicit หากต้องการจำกัดจำนวนการสืบค้นพร้อมกันหรือหน่วยความจำ Y ที่ผู้ใช้เข้าถึงได้ ให้ใช้ Impala Admission Control หากข้อความค้นหาใช้เวลานานกว่า 30 นาที จะถือว่าไม่มีผล
เครื่องมือที่ดีที่สุดสำหรับข้อมูลขนาดใหญ่: Impala
เครื่องยนต์ Impala เป็น เครื่องมือประมวลผลข้อมูล Hadoop ที่ออกแบบมาโดยเฉพาะสำหรับคลัสเตอร์ขนาดใหญ่ ใช้พลังงานน้อยกว่ามากและใช้ทรัพยากรน้อยกว่ากลไก MapReduce มาตรฐานของ Hadoop Implicit ใช้ระบบไฟล์แบบกระจาย HDFS เป็นสื่อกลางในการจัดเก็บข้อมูลหลัก อาศัยความซ้ำซ้อนของ HDFS เพื่อป้องกันฮาร์ดแวร์หรือเครือข่ายหยุดทำงานแบบโหนดต่อโหนด ไฟล์ข้อมูลที่แสดงถึงข้อมูลตารางจะถูกแทนด้วยรูปแบบไฟล์ HDFS ที่คุ้นเคยและตัวแปลงสัญญาณการบีบอัด
เครื่องมือสืบค้นการประมวลผลแบบขนาน
เอ็นจินคิวรีการประมวลผลแบบขนาน คือเอ็นจิ้นฐานข้อมูลประเภทหนึ่งที่ออกแบบมาเพื่อประมวลผลคิวรีแบบขนาน ซึ่งสามารถทำได้โดยใช้โปรเซสเซอร์หลายตัว หลายคอร์ หรือหลายเครื่อง การประมวลผลแบบขนานสามารถปรับปรุงประสิทธิภาพของกลไกการสืบค้นได้อย่างมาก โดยเฉพาะอย่างยิ่งสำหรับการสืบค้นที่ซับซ้อน
คอมพิวเตอร์หลายตัวประมวลผลใช้เพื่อแปลงข้อความค้นหาที่ซับซ้อนให้เป็นแผนการดำเนินการที่สามารถดำเนินการได้พร้อมกัน ทำให้สามารถประมวลผลข้อมูลจำนวนมากได้ในคราวเดียว การดำเนินการที่มีประสิทธิภาพ เช่น เวลาตอบสนองการสืบค้นที่ดีหรือปริมาณงานการสืบค้นสูง เป็นสิ่งจำเป็นสำหรับประสิทธิภาพการทำงานที่สูง ทำได้โดยใช้เทคนิคการดำเนินการแบบขนานที่มีประสิทธิภาพและการปรับคิวรีให้เหมาะสม
การประมวลผลแบบขนาน: อนาคตของ Etl?
แบบสอบถามระดับสูงสามารถแปลงเป็นแผนการดำเนินการที่สามารถดำเนินการได้อย่างมีประสิทธิภาพโดยคอมพิวเตอร์หลายตัวประมวลผลโดยใช้การประมวลผลแบบสอบถามแบบขนาน การประมวลผลแบบขนานใช้เทคนิคของการรวมข้อมูลแบบขนานและแบบกระจาย ตลอดจนเทคนิคการดำเนินการต่างๆ ที่จัดทำโดย ระบบฐานข้อมูลแบบขนาน การประมวลผลคิวรีแบบขนานถูกนำมาใช้ใน ETL โดยแบ่งชุดของเรคคอร์ดในแต่ละตารางต้นทางที่กำหนดให้ถ่ายโอนเป็นกลุ่มที่มีขนาดเท่ากัน จากนั้นทำกระบวนการแปลงข้อมูลสำหรับแต่ละตารางต้นทางเป็นรอบ เลือกข้อมูลตามลำดับทีละก้อน .